
古诗词图谱的构建及分析研究
2020-06-23 09:21刘昱彤
计算机研究与发展 2020年6期
刘昱彤 吴 斌 白 婷
(北京市智能通信软件与多媒体重点实验室(北京邮电大学) 北京 100876)(北京邮电大学计算机学院 北京 100876)
古诗词在中国古典文学中占有极其重要的地位.随着数字人文的发展,使用计算语言学和统计学的方法辅助诗词的研究已成为一种普遍趋势.如今,关于诗词的知识是碎片化的,原因是互联网上可得到的诗词知识,一方面来自诗词本身,另一方面来自诗词的解读资料,比如诗词的注释、译文、鉴赏等.将古诗词中的词语通过语义的关联,以知识的形式联系在一起,是一种比较合理的将诗词的碎片化知识联系在一起的方式.因此,古诗词领域的知识图谱是将诗词的碎片化知识进行关联、整合的必要手段.
现有的诗词知识图谱,如“唐诗别苑”[1]和“宋代学术传承知识图谱”[2].前者仅涉及到诗人社交网络、诗人迁徙游历、作品热点地图这3个方面,而后者仅涉及宋朝人物师承关系.它们仅仅从几个特殊的方面来构建诗词知识图谱,但是忽略了各个部分之间的内部联系.显然,这些诗词知识图谱在内容完整性、结构合理性、条理分明性有所欠缺.关于诗词的分析工作,如唐宋文学编年地图[3]将诗人的时空轨迹可视化,也只停留在诗词写作地点和写作时间的人工整理以及对人物轨迹简单的统计分析上,并未涉及到诗词中实体的识别和实体之间语义关联的判定.为了解决以上问题,本文构建了一个内容覆盖全面且层次结构分明的古诗词图谱,通过从文本中挖掘词语的语义关联,将古诗中的词语用知识的形式组织起来.
现有的通用领域的中文知识图谱,如《大词林》、HowNet、CN-DBpedia等,对古诗中涉及到的词汇覆盖率极低,不能采用抽取子集的方式直接构建古诗词领域的知识图谱.而常规的知识图谱构建过程对古诗词领域并不完全适用,由于诗句不遵循语法规则,无法用实体识别、实体关系抽取等常用自然语言处理技术构建.同时也无法将诗词中的词汇链接到现有百科,因为现有百科几乎没有收录古诗词的词语.
为了构建古诗词知识图谱,我们该如何找到古诗中的词语,又该如何将词语的语义之间建立联系.这项工作面临2个挑战:1)如何界定古诗词的词语,又如何准确地挑选出古诗词中出现的词语.由于词语构成古诗词图谱的节点,准确地将古诗词中出现的词语抽取出来是整个工作的基础.2)如何利用和融合互联网的多种诗词知识源来准确地获取词语之间的关联.针对第1个挑战,为了保证诗词词语抽取的准确性,一般采用人工标注的方式,但人工标注过于费时费力.因此,我们的解决方案是模拟人工标注时参考诗词注释和词典中词语解释的过程来自动获得诗词中的词语.一方面,我们利用诗词的注释,因为注释正是对不可再分的语义单元的解释,获取注释条目就精准地获取了诗词中的词语;另一方面,我们利用古汉语的新词发现方法[4-5]产生诗词中的候选词,然后在诗词注释条目和中文词典中查找,若出现,则该候选词是诗词中的词语,否则该候选词不是诗词中的词语.针对第2个挑战,我们融合诗词注释和中文词典中的词语解释,找到词语与词语之间的联系,再利用人工构建的古诗词分类体系建立语义之间的联系.
本文的主要贡献有3个方面:
1) 提出了一种古诗词图谱的构建方法,并利用该方法构建了一个内容覆盖全面、包含多层词语语义联系的古诗词图谱.该图谱刻画了词语的多个层级,以合理的结构覆盖了诗词的各个方面;该图谱从诗词的注释和词语的词典解释入手,挖掘出词语的语义关联.
2) 古诗词图谱可以对诗词进行各种不同维度的分析.相比于基于字的浅层数据分析,利用古诗词图谱可以从语义的角度从真正的意义上辅助文学研究.以唐诗为例,展示了古诗词图谱在诗词分析上的应用,证明了古诗词图谱在诗词分析中的必要性.
3) 古诗词图谱适用于诗词的各种推理和分析任务.以判定诗词的题材、分析诗词的情感2个任务为例,说明了古诗词图谱的应用价值.
1 相关工作
1.1 数字人文及其在诗词中的研究进展
近年来,随着数字技术和数字媒体的不断发展,人文学科结合数字技术的研究应运而生.2011年Michel等人[6]在《科学》杂志上发表了基于百万电子化图书对文化进行量化分析的论文,挖掘出1800—2000年的英文语言中所反映出的语言学和文化现象;2014年Schich等人[7]在《科学》杂志上发表了量化分析文化中心变迁的论文,他们利用超过15万的名人的出生地点和死亡地点的信息,建立了跨度2000年的迁徙网络,用网络科学的手段分析了欧洲文化中心的变迁.这些工作为数字人文这一新兴的交叉领域学科提供了一个良好的开端.
数字人文在中国诗词上的研究,近年来涌现出大量的工作.王兆鹏[3]搭建了唐宋文学编年地图平台,将诗人的时空轨迹分布信息可视化.新华网联合浙江大学发布的“宋词缱绻,何处画人间”[8]平台,对宋词进行可视化展示,包括宋代词人游历路线、宋代词人生平及所处年代图谱、《全宋词》常见意象统计等.清华大学自然语言处理与社会人文计算实验室搭建了计算机诗词创作系统“九歌”[9],结合seq2seq神经网络结构和诗词韵律实现了古诗自动生成算法[10-11].但是,以上关于诗词分析的工作都是简单地对词频进行统计,尚未涉及到诗词中词语与词语之间的语义关联.
1.2 中文通用及诗词领域知识图谱的研究进展
中文通用领域的知识图谱主要有《大词林》、HowNet、CN-DBpedia,接下来分别介绍.《大词林》[12]是自动构建的基于上下位关系的大规模开放域中文知识图谱.HowNet[13]是人工标注的语言知识库.在HowNet中,最小的语义单位被称为“义原”.HowNet中的“义原”大约有2 000个.HowNet 基于“义原”体系,共标注了数十万词汇的语义信息.CN-DBpedia[14]是复旦大学知识工厂实验室研发并维护的大规模通用领域结构化百科.CN-DBpedia主要是从中文百科类网站(如百度百科、互动百科、中文维基百科等)的纯文本页面中提取信息,经过滤、融合、推断等操作后,最终形成高质量的结构化数据,供机器和人使用.
然而,通用领域的中文知识图谱对古诗词中涉及到的词汇覆盖率极低,不能够直接用来分析诗词的词语语义之间的联系.
关于知识图谱的构建方法,刘峤等人[15]在《知识图谱构建技术综述》一文中总结,知识图谱的构建过程包括信息抽取、知识融合、知识加工共3个阶段.其中,信息抽取包括实体抽取[16-18]、关系抽取[19-21]、属性抽取[22-23];知识融合包括实体链接[24-25]、知识合并[26];知识加工包括本体构建[27]、知识推理[28]、质量评估[29].可见,常规的知识图谱都是从抽取实体和关系、构建“实体-关系-实体”三元组开始的.
然而,常规的知识图谱构建过程无法适用于古诗词知识图谱的构建.原因是,诗句不遵循主谓宾的语法结构,可以从诗词中抽取出词语,但是利用现有的关系抽取方法无法提取出词语之间的关系,也无法确定词语之间表达的语义是否相关.而且,无法利用各种百科中的实体信息,因为现有的中文百科尚未收录古诗词中的词语.
诗词领域的知识图谱方面,主要的工作有:“唐诗别苑”[1],是关于全唐诗语义检索的可视化平台,实现了唐诗的语义检索功能和知识图谱的可视化(包括诗人社交网络、诗人迁徙游历、作品热点地图、诗人属性4个方面).“宋代学术传承知识图谱”[2],从“中国历代人物传记数据库”[30](China biographical database project, CBDB)中抽取宋代人物之间的学术传承关系和部分亲属关系,用知识图谱来探究宋代士人的师承关系.周莉娜等人[31]设计了基于唐诗知识图谱的智能知识服务平台KnowPoetry,提供唐诗领域的知识探索、时空轨迹、语义查询等智能化知识服务.
以上提到的诗词领域的知识图谱,是以诗人、诗歌为单位的,并未从词语的角度对诗词的知识进行建模和分析.而诗词语义的基本组成单元是词语,若要对诗词进行更深层次的语义研究,对诗词词语的语义进行知识上的关联是无法避开的一步.此外,以上工作构建的诗词知识图谱仅从多个角度包含了诗词知识,图谱涉及到的内容不够全面,图谱的组织不够有条理.
2 古诗词图谱
2.1 古诗词图谱的形式化定义
古诗词图谱G=(V,E),由点的集合V和边的集合E组成.点的集合V={Vhier,Vdesc,Vanno},包含3种类型的词节点,分别是古诗词分类体系中的词Vhier、描述词Vdesc、注释条目的词Vanno.边的集合E={Ehier-hier,Ehier-desc,Edesc-desc,Edesc-anno},包含4种类型的边,分别是Vhier与Vhier之间的边、Vhier与Vdesc之间的边、Vdesc与Vdesc之间的边、Vdesc与Vanno之间的边.
2.2 古诗词图谱的构建
古诗词图谱的构建过程如图1所示,分为节点的构建、边的构建2部分.
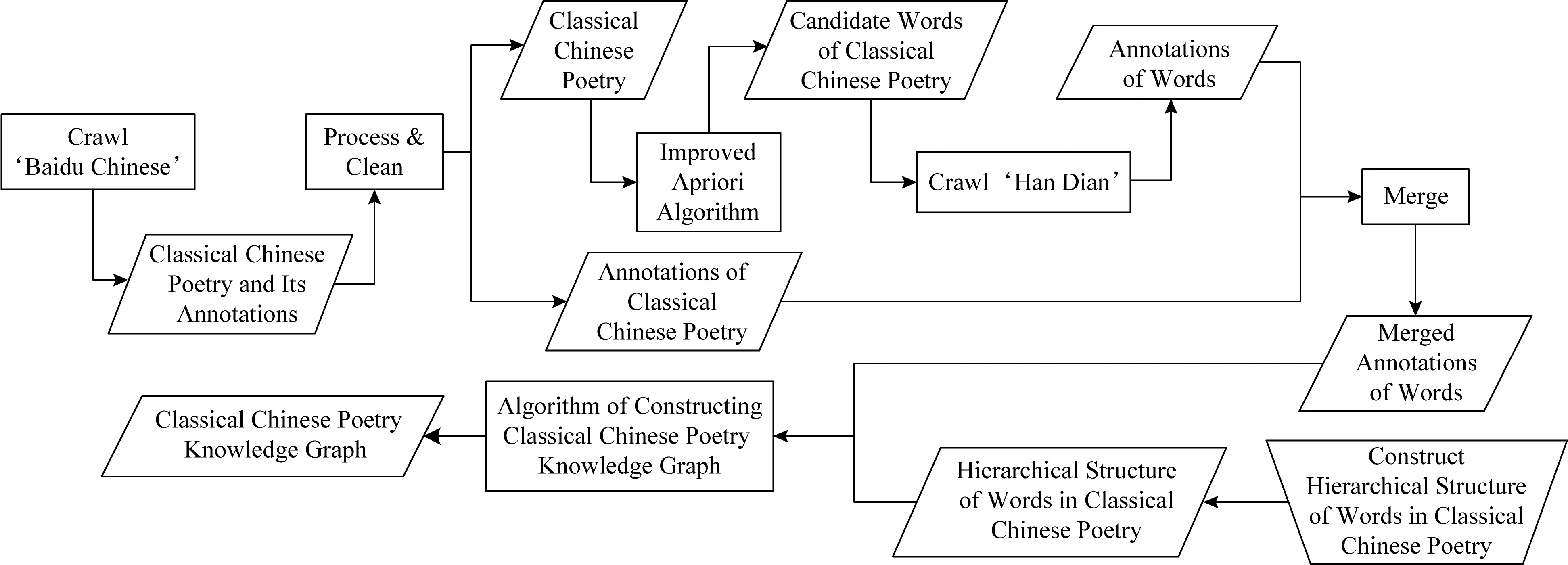
Fig.1 The process of constructing classical Chinese poetry knowledge graph图1 古诗词图谱构建流程图
2.2.1 古诗词图谱——节点的构建
诗词中出现的词语构成古诗词图谱的节点,所以准确地抽取出诗词中的词语非常关键.若人工标注诗词中的词语,当判断某个字串是否是词语时,参考的资料一般有2个来源:1)查看诗词的注释,若某个字串包含注释信息,那么该字串就是词语,因为注释是对不可再分的语义单元的解释.2)根据常识、使用平时的积累来判断某个字串是否是词语,其本质就是判断该字串是否是现代汉语的词语,这个过程可以用查询中文词典的方式完成.人工标注的方式过于费时费力,所以本文模仿人工标注的方式来自动获取诗词中的词语.首先利用古汉语新词发现算法中改进的Apriori算法[4-5]产生候选词,该算法可以不遗漏地挖掘出长度在2~K之间的所有可能词语;然后搜索候选词是否出现在诗词注释条目和中文词典中,若出现则判定该候选词为诗词中的词语,这一步模拟了人工标注的过程.总的来说,这种方式全自动地、准确地得到了诗词中的词语,即图谱的节点.接下来对改进的Apriori算法[4-5]进行详细说明.
算法1.改进的Apriori算法.
输入:原始语料D;
输出:候选新词的集合.
/*产生1-频繁项集*/
① 1-候选项集C1={c1,c2,…};
② 统计原始语料中单个字的出现频次,得到(字,频次)的二元组集合S1={(c1,f1),(c2,f2),…};
③ for (ci,fi) inS1
④ iffi>支持度
⑤ 把ci加入1-频繁项集L1;
⑥ end if
⑦ end for
⑧ 得到1-频繁项集L1;
/*产生2-频繁项集*/
⑨ forciinL1
⑩ forcjinL1
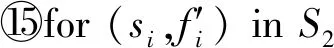
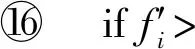
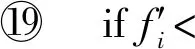
其次,要求在小型水电站工作机组的运行过程之中,随时对进行发电和电力传输的设备进行安全检修和检查工作,务必保证小型水电站发电机组的正常工作运行。具体的来说,在小型水电站发电机组的运行过程之中,有着很多的关键设备组份发挥着为发电设备传输电流并传输电力的作用,为了有效的保证小型水电站发电机组的正常工作运行,就需要保证这些设备可以有效的运行。针对这样的情况,就需要对这些设备进行随时随地的检查,一旦出现油污或者损毁情况,就需要及时的采取有效的清污处理亦或者是采取相应的打磨处理,务必保证这些设备处于正常的工作状态当中。

2.2.2 古诗词图谱——边的构建
古诗词图谱的边刻画了古诗词中词语的语义联系,所以利用互联网存在的多种知识源来准确地获取词语之间的关联非常重要.现阶段关于诗词词语语义相似度的工作[32-33]只能挖掘出频繁共现的词,并认为它们是相似的.但是,我们的目标是准确地将具有相同主题的词相关联.比如西晋名将羊祜的典故有多种表达:“羊公碑”、“岘山”、“征南”、“泪碑”,“羊公”,这些词语之间是具有语义联系的.利用完全无监督的方法很难获取到这样的语义联系,而诗词的注释和词典的词语解释是对语义的权威释义,利用词语的权威解释可以准确有效地挖掘出词语的语义联系.因此,本文基于诗词注释和中文词典中的词语解释,在相互关联的词语之间建立了联系,但是,语义和语义之间仍然是不相关的.为了进一步在不同的语义之间建立联系,我们设计了古诗词分类体系,以多层分类结构将不同的语义有条理地组织在一起,从而形成完整的古诗词图谱.
如图1所示,构建古诗词图谱的边可大致分为3个步骤:
1) 获取和处理注释信息.爬取“百度汉语”网站,获取诗词注释.爬取“汉典”网站,获取诗词候选词的注释.然后将2部分注释信息分别处理清洗,之后合并.
2) 构建古诗词分类体系.构建关于古诗词的分层体系,得到4棵根节点分别是“时间”、“地点”、“景物”、“人”的树.
3) 构建古诗词图谱.将注释条目的词通过描述词关联到诗词分类体系的词,得到古诗词图谱.
2.2.2.1 获取和处理注释信息
关于诗词的注释,我们爬取“百度汉语”[注]https://hanyu.baidu.com/网站来获取.百度汉语的注释示例如图2(a)所示.在该例中,“黄鹤楼”、“孟浩然”、“广陵”、“故人”、“烟花”、“唯见”是所需要的词语,而“碧空尽”、“天际流”这样的词并不是我们所需要的.“碧空尽”中的“碧空”,“天际流”中的“天际”也是所需要的.因此,首先,我们用正则表达式把所有的注释处理成(词,解释)的二元组形式,图2(a)的例子就包含了14个这样的二元组(除了图2(a)展示的11个,还包含“尽”、“碧空”、“天际”).然后把所有诗的相同词的注释合并,以特殊符号“|”分隔.
关于候选词的解释,我们爬取“汉典”[注]https://www.zdic.net/网站来获取.汉典中的词语解释示例如图2(b),对于每个词,我们爬取的是“解释”和“国语辞典”2个部分.
最后,将百度汉语和汉典这2个渠道获得的词语解释合并.
2.2.2.2 构建古诗词分类体系
董乃斌在《中国文学叙事传统论稿》一书中提到“诗歌和其他各种文学作品一样,都是要通过‘叙述’来表达的.时间、地点、景物、人物、事件,包括作者内心的感情,统统都得由作者或口头或书面地叙述出来.抒情其实也是一种叙述,不过所叙的是感情或情绪,且主要是作者本人的感情或情绪而已.”[34]
具体而言,人处于特定的时间、地点,受到眼前景物的触发,再结合自身的背景和经历,会产生不同的心情、抒发不同的感情和人生感悟.所以本文设计的古诗词分类体系是围绕时间、地点、景物、人这4个方面展开的,如表1所示,受篇幅限制,只展示了部分分类体系.古诗词分类体系是由我们邀请的3位古汉语文学专业的专家利用3天时间手工构建的.由于构建古诗词分类体系涉及到诗词的常识知识,且没有现成的古诗词领域常识图谱,因此构建过程必须人工参与.构建完成古诗词分类体系,就创建了Vhier和Ehier-hier.
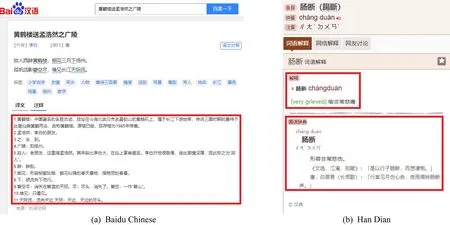
Fig.2 Example of annotations in Baidu Chinese and Han Dian图2 “百度汉语”和“汉典”的注释示例
Table 1 Hierarchical Structure of Words in Classical Chinese Poetry
表1 古诗词分类体系
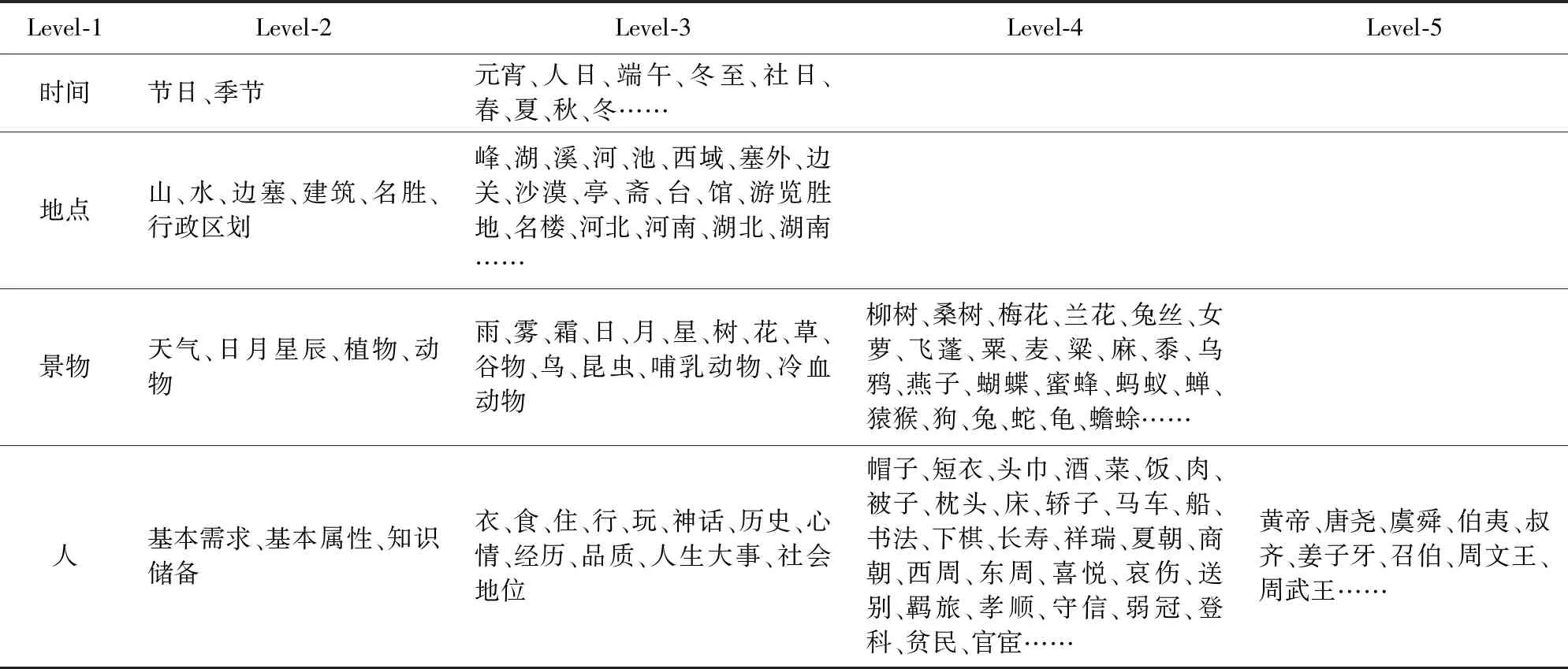
Level-1Level-2Level-3Level-4Level-5时间节日、季节元宵、人日、端午、冬至、社日、春、夏、秋、冬……地点山、水、边塞、建筑、名胜、行政区划峰、湖、溪、河、池、西域、塞外、边关、沙漠、亭、斋、台、馆、游览胜地、名楼、河北、河南、湖北、湖南……景物天气、日月星辰、植物、动物雨、雾、霜、日、月、星、树、花、草、谷物、鸟、昆虫、哺乳动物、冷血动物柳树、桑树、梅花、兰花、兔丝、女萝、飞蓬、粟、麦、粱、麻、黍、乌鸦、燕子、蝴蝶、蜜蜂、蚂蚁、蝉、猿猴、狗、兔、蛇、龟、蟾蜍……人基本需求、基本属性、知识储备衣、食、住、行、玩、神话、历史、心情、经历、品质、人生大事、社会地位帽子、短衣、头巾、酒、菜、饭、肉、被子、枕头、床、轿子、马车、船、书法、下棋、长寿、祥瑞、夏朝、商朝、西周、东周、喜悦、哀伤、送别、羁旅、孝顺、守信、弱冠、登科、贫民、官宦……黄帝、唐尧、虞舜、伯夷、叔齐、姜子牙、召伯、周文王、周武王……
2.2.2.3 构建古诗词图谱
古诗词分类体系是古诗词图谱的一部分,本节讲述如何将注释条目加入古诗词分类体系中,构成最终的古诗词图谱.算法2描述了该过程.算法2的主要思路是:找到与古诗词分类体系的叶子节点相关的若干个描述词,在叶子节点和描述词之间建立联系,在描述词之间建立联系.对某个描述词遍历所有的注释条目,若该描述词出现在某注释内容中,则在该描述词与该注释条目之间建立联系.
算法2.构建古诗词图谱算法.
输入:古诗词分类体系Trees={Tree1,Tree2,Tree3,Tree4}、词语解释集合word_anno_set={(word1,anno_list1),(word2,anno_list2),…,(wordn,anno_listn)};
输出:古诗词图谱G.
①G=Trees;
② fortreeinTrees
③ fornodeintree.leave_nodes/*node有多个描述词:desc1,desc2,…,descm*/
④ foriinrange(m) /*对每个描述词*/
⑤node′=Add_node(desci);
/*将desci作为节点加入图G*/
⑥Add_edge(node,node′); /*在node
和node′之间构建连边*/
⑦ for (word,anno_list) inword_anno_set
⑧ ifdesciin ‘’.join(anno_list)
⑨Add_edge(node′,word);
⑩ end if
/*在两两描述词之间构建连边*/
下面通过例子来解释这一过程.如图3所示,“风”是诗词分类体系中根节点为“景物”的树的一个叶子节点,它的父亲节点是“天气”.与“风”这一节点有关的描述词有“狂风”、“刮风”、“大风”.步骤1,在“风”与“刮风”,“风”与“大风”,“风”与“狂风”之间构建1条边.这一步骤的含义是同一事物有多个描述词.步骤2,在“刮风”、“大风”、“狂风”两两之间构建1条边.这一步骤的含义是事物的不同描述词是等价的、地位相同的.步骤3,遍历所有的注释条目,分别找到这3个描述词出现在注释内容中的注释条目.比如,“狂风”分别出现在了“冲风”、“惊飙”、“惊风”这3个词的注释中,那么,就将“狂风”与“冲风”,“狂风”与“惊飙”,“狂风”与“惊风”之间各构建1条连边.这一步骤的含义是如果某个词出现在了某条注释中,就说明该注释条目与该词内容相关.
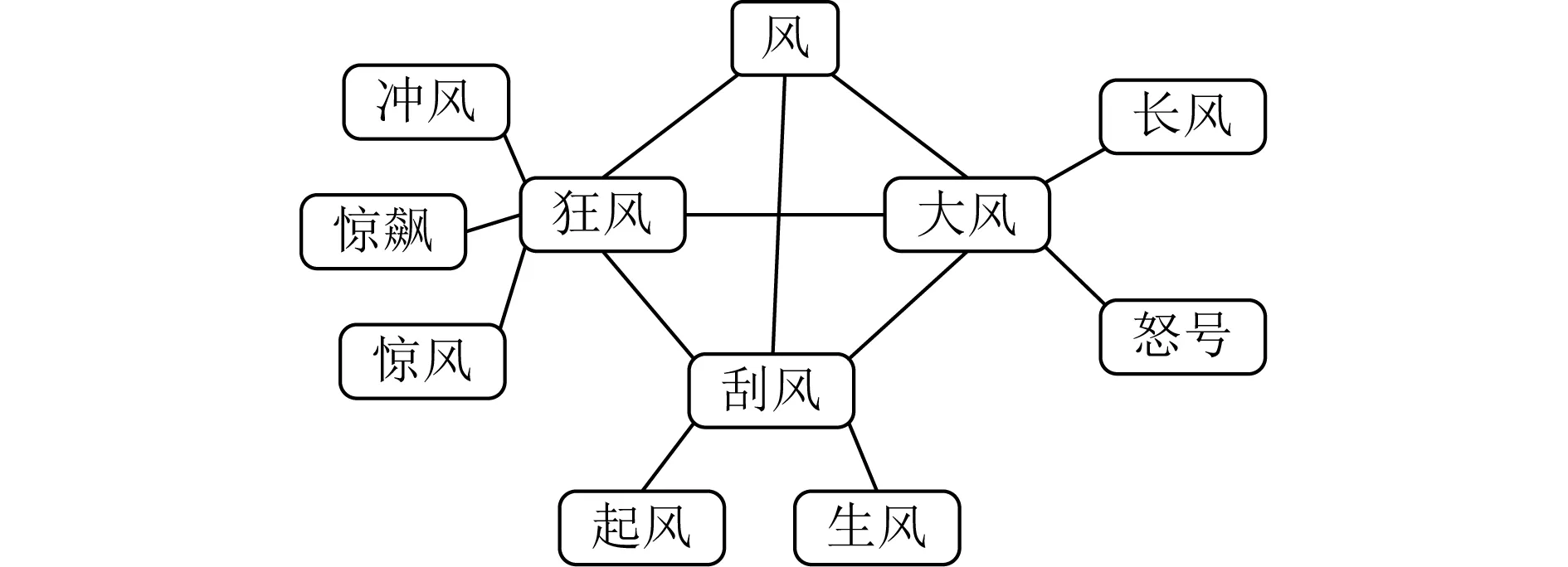
Fig.3 Example of the process of constructing classical Chinese poetry knowledge graph图3 古诗词图谱构建过程举例
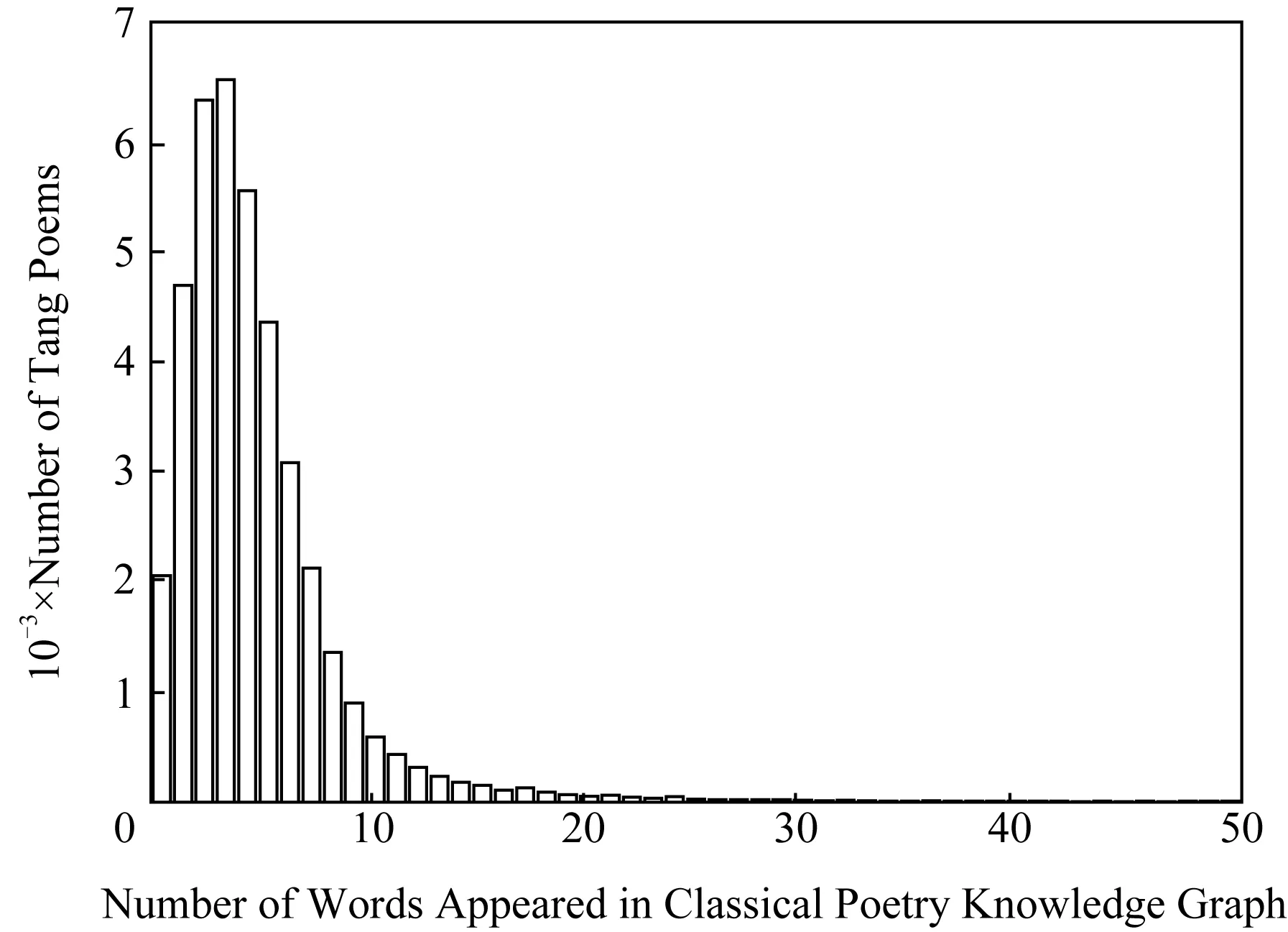
Fig.4 Statistics of number of poems’ words in classical Chinese poetry knowledge graph图4 诗词涉及的古诗词图谱的词语数量统计
2.3 古诗词图谱构建的评测
以唐诗为例,构建古诗词图谱.在古诗词图谱的节点的构建过程中,关于改进的Apriori算法,K设置为3,支持度设置为5,低频阈值设置为2.在古诗词图谱的边的构建过程中,“百度汉语”中可以检索到的唐诗共40 531首,包含注释信息的共1 330首,通过处理、清洗、合并后共得到7 668条注释信息.通过改进的Apriori算法产生的候选词,在“汉典”中能够找到解释的共有18 589个.将“百度汉语”和“汉典”这2个渠道获得的词语解释合并后,共得到21 907条词语和与之对应的解释.最终,构建的古诗词图谱共有6 619个节点、10 292条边.其中,单个字节点有231个,2字词节点有6 116个,3字词节点有259个,4字词节点有13个.
为了评测构建的古诗词图谱的性能,对诗词中涉及的古诗词图谱的词语个数进行统计,如图4所示.统计的范围是唐诗中的五言诗和七言诗,共40 210首,从图4中可以看到,只有大约2 000首诗没有包含古诗词图谱的词语.大部分诗词涉及的古诗词图谱的词语个数在0~10之间.而大部分唐诗是五言或七言的律诗或绝句,也就是说大部分唐诗的字数是几十个字,因此,我们构建的古诗词图谱的词语覆盖率是可观的.
3 利用古诗词图谱对诗词进行分析
本节以唐诗为例,说明古诗词图谱在诗词分析中的作用.
3.1 不同因素对诗人情感的影响
本节探究了季节、天气、地点对诗人情感的影响.利用古诗词图谱,把与季节、天气、地点、情感有关的词分别关联起来,从更广的词的范围对“季节-情感”、“天气-情感”、“地点-情感”进行全面、具体地数据分析,从而得到更深层次的结论.
3.1.1 季节对诗人情感的影响
欲探究不同的季节对诗人的情感产生什么样的影响,我们将统计描述季节的词和描述情感的词在诗中的共现关系.
对于季节Si,我们需要分别统计Si和诗人的9种情感(哀伤、失意、愁绪、喜悦、孤独、恐惧、愤怒、怨恨、惊讶)之间的共现次数,即季节Si和情感Ej共现的诗的个数(j=1,2,…,9).然后,计算情感Ej(j=1,2,…,9)对季节Si所占的比例:
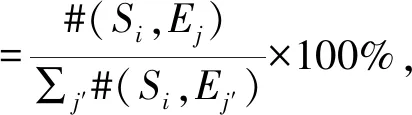
(1)
其中,#(Si,Ej)表示季节Si和情感Ej共现的诗的个数.
如果没有古诗词图谱,在统计诗词描述的季节时,我们只会检验“春”、“夏”、“秋”、“冬”这4个字是否出现在诗中.但是,有时诗中有关季节的表达却不止这4个字,比如,“霜天”、“归雁”、“玉露”、“红叶”也同样表明是秋天.在古诗词图谱中,“春”、“夏”、“秋”、“冬”是较为抽象的词语,属于古诗词分类体系中的词语,由它们向下延伸可以拓展出很多相关词语.描述情感的词同理,在古诗词图谱中,“哀伤”、“失意”、“愁绪”等也属于古诗词分类体系中的词语.利用古诗词图谱对季节和情感共现次数进行统计,可以得到更加全面、真实的结果.
图5展示了4种季节中每一种情感所占的比例.从图5可以看出,春、夏、秋、冬4种季节占比最高的情感分别是喜悦、哀伤、哀伤、哀伤.关于春天和秋天,这是符合常识的,春天万物复苏、生机勃勃,容易使人心情愉悦并产生积极向上的情绪;而秋天萧索悲凉,万物枯败,容易使人联想到自己的衰老和不济,产生悲伤的情绪.关于夏天和冬天,我们发现,这2个季节的主要情感也是哀伤.而且,这4个季节中,哀伤、失意、愁绪、孤独这4种负面情感占据了非常大的比例,而恐惧、愤怒、怨恨、惊讶占据比例很小.因此,我们可以得出结论,大部分诗词表达的情感都是负面的,但是春天是容易让诗人的情感转变为积极的一个重要因素.
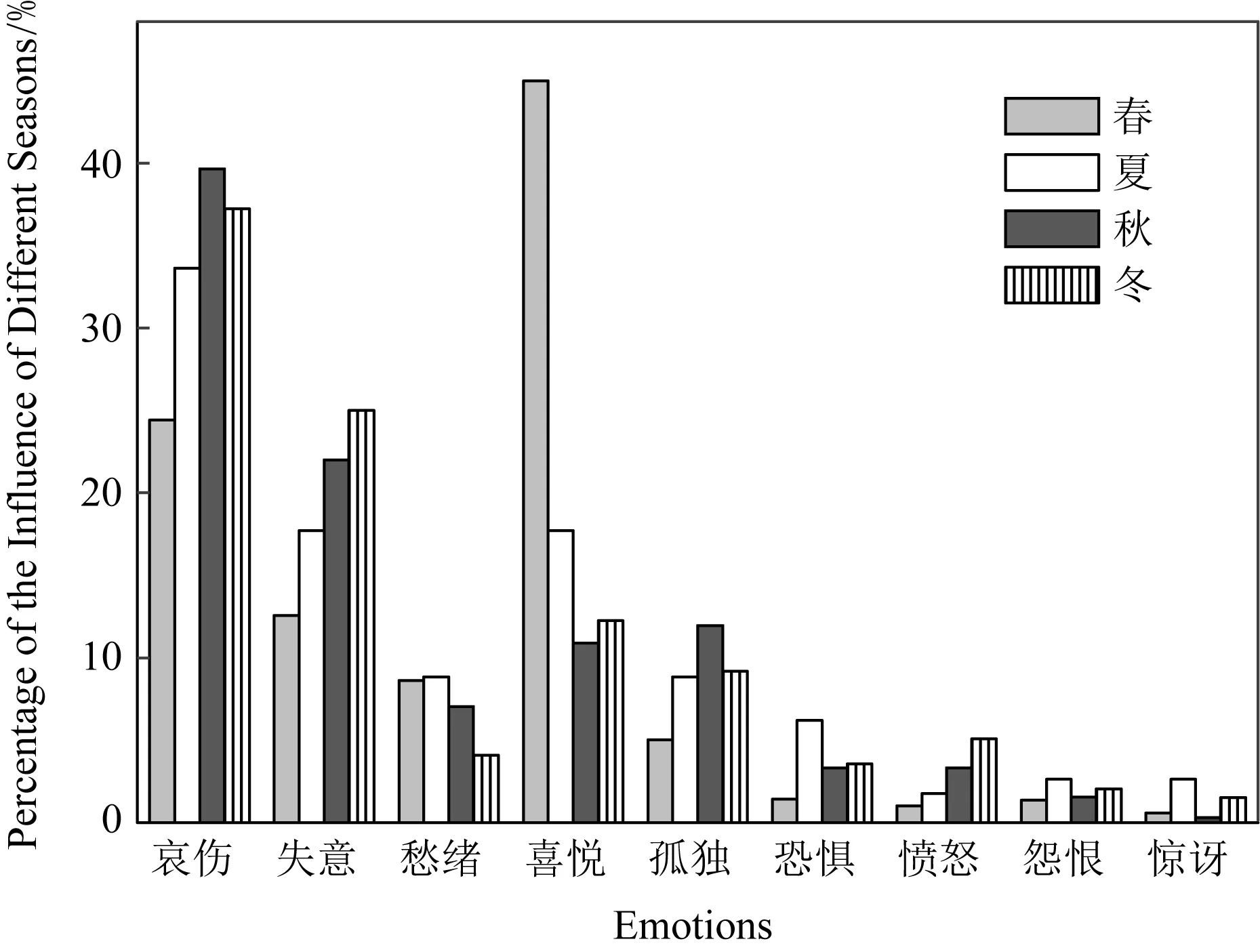
Fig.5 The histogram of the influence of different seasons on poets’ emotions图5 不同季节对诗人情感的影响柱形图
3.1.2 天气对诗人情感的影响
欲探究不同的天气对诗人的情感产生什么样的影响,我们将统计描述天气的词和描述情感的词在诗中的共现关系.
类似地,计算情感Ej(j=1,2,…,9)对天气Wi所占的比例:
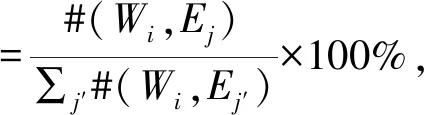
(2)
其中,#(Wi,Ej)表示天气Wi和情感Ej共现的诗的个数.
利用古诗词图谱可以发现,描述“雪”的词还有“飘素”、“玉蕊”、“天花”、“玉英”、“玉花”等.描述“雨”的词还有“蹄涔”、“丁丁”等.描述“风”的词还有“摧折”、“长条”等.利用古诗词图谱进行统计,比仅仅对诗词统计“雪”、“雨”、“风”、“露”、“云”这5个字更加全面.
图6展示了5种天气中每一种情感所占的比例.从图6可以看出,哀伤、失意、愁绪、喜悦、孤独仍然占比很大,恐惧、愤怒、怨恨、惊讶仍然占比很小,结合3.1.1节可以说明,前5种情感在整个唐诗集合中占比很大,后4种情感在整个唐诗集合中占比很小.接下来,通过比较在特定情感下5个代表天气柱的相对高度来解析不同天气对诗人情感的影响.
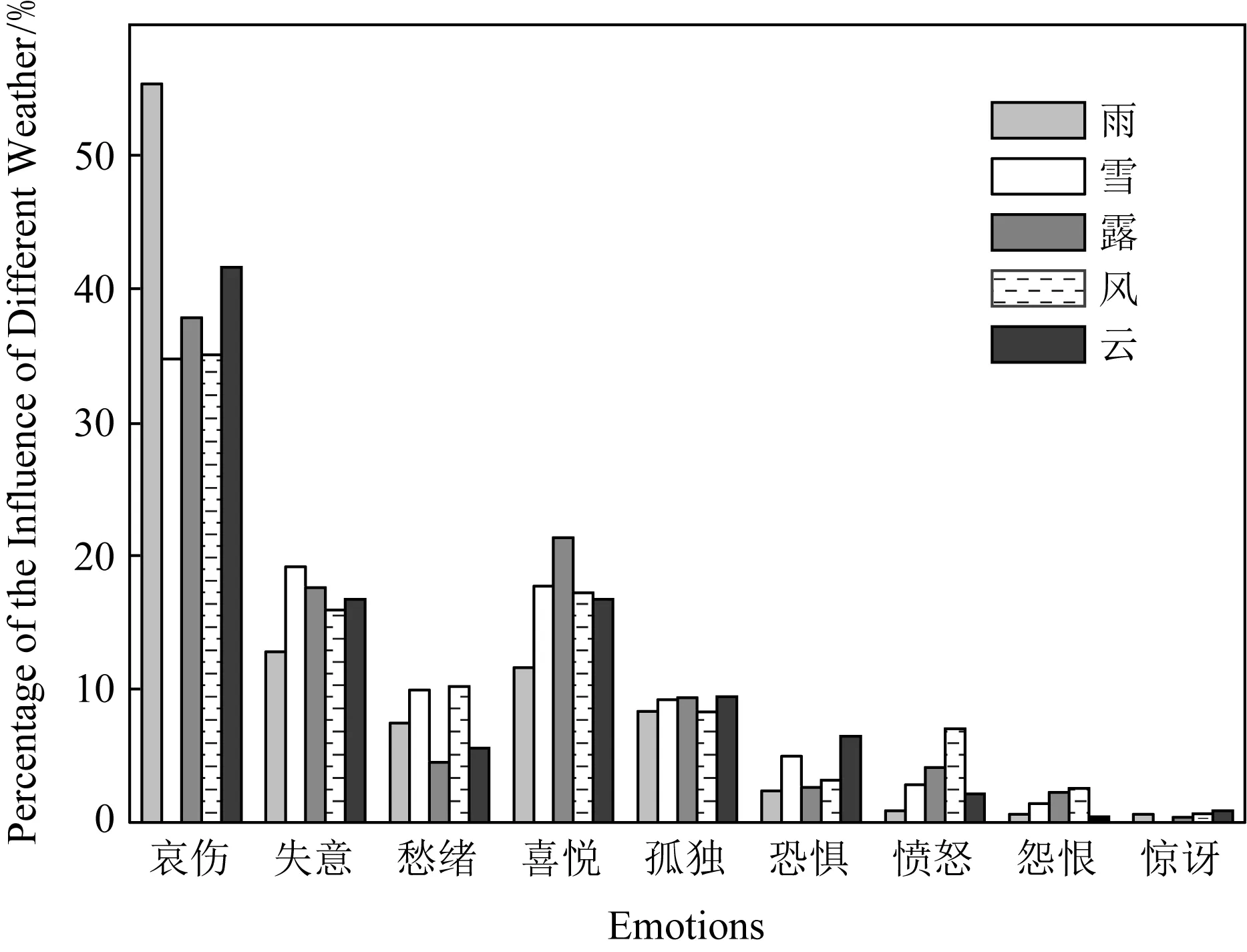
Fig.6 The histogram of the influence of different weather on poets’ emotions图6 不同天气对诗人情感的影响柱形图
在图6中,“哀伤”在“雨”这种天气中的占比显著高于“哀伤”在其他天气中的占比,“喜悦”在“雨”这种天气中的占比显著低于“喜悦”在其他天气中的占比.这说明了“雨”这种天气相比于其他天气,更加倾向于带给人哀伤的情绪,换句话说,诗人更愿意用“雨”来渲染诗歌的悲伤氛围.此外,“恐惧”在“云”中的比例显著高于“恐惧”在其他天气中的比例.“愤怒”在“风”中的比例显著高于“愤怒”在其他天气中的比例.这说明了诗人更倾向于使用“云”这样的天气来表达“恐惧”的情绪,更倾向于使用“风”这样的天气来表达“愤怒”的情绪.
3.1.3 地点对诗人情感的影响
欲探究不同的地点对诗人的情感产生什么样的影响,我们将统计描述地点的词和描述情感的词在诗中的共现关系.
类似地,计算情感Ej(j=1,2,…,9)对地点Pi所占的比例:
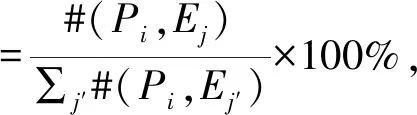
(3)
其中,#(Pi,Ej)表示地点Pi和情感Ej共现的诗的个数.
诗词中关于地点的描述十分复杂,没有统一的规则.比如典型的描述“边塞”的词语有“轮台”、“碛西”、“楼兰”、“龙城”、“北庭”等.若要对地点进行覆盖面全的统计,利用古诗词图谱是必要的.在古诗词图谱中,“边塞”属于古诗词分类体系中的词语,由“边塞”可以拓展到“西域”、“塞外”、“新疆”、“边关”、“塞北”、“沙漠”等,然后可以进一步拓展直到底层节点为止.通过这样的层级结构,完整而有条理地覆盖了所有地点词汇.对于“山”、“水”、“建筑”、“名胜”也是如此.
图7展示了5种地点中每一种情感所占的比例.在图7中,“哀伤”在“边塞”中所占比例相比于“哀伤”在其他地点中所占比例是最高的,这说明了边塞更容易让人产生悲伤的情绪,原因是边塞总是和战争、戍边联系在一起.“愁绪”在“水”中所占比例相比于“愁绪”在其他地点中所占比例是最高的,这说明古人总是将“水”和“愁绪”联系在一起,比如李白的著名诗句“抽刀断水水更流,举杯消愁愁更愁”.“孤独”在“山”中所占比例相比于“孤独”在其他地点中所占比例最高,“山”带给人的感觉确实是孤独的.
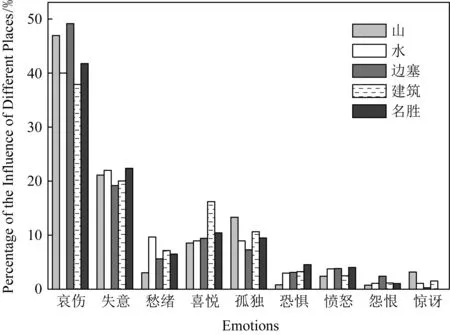
Fig.7 The histogram of the influence of different places on poets’ emotions图7 不同地点对诗人情感的影响柱形图
3.2 不同时期对诗人写作风格相似度的影响
唐朝分为初唐、盛唐、中唐、晚唐4个时期,本节将首先描述2个诗人之间写作风格相似度的度量方式,然后对同一时期诗人写作风格的相似度和相邻时期诗人写作风格的相似度进行度量,探究不同时期对诗人写作风格相似度的影响.
3.2.1 2个诗人之间写作风格相似度的度量
我们对写作风格的定义有2个维度,分别是题材和情感.关于题材,有“送别”、“羁旅”、“战争”、“田园”、“爱情”、“怀人”、“被贬”、“咏史”、“思乡”、“山水”10种类别.关于情感,有“喜悦”、“愤怒”、“哀伤”、“愁绪”、“孤独”、“恐惧”、“惊讶”、“怨恨”、“失意”9种类别.利用古诗词图谱,可以更加全面、准确地统计诗词中与题材和情感有关的词语.
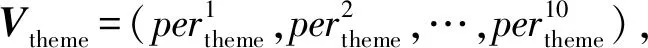
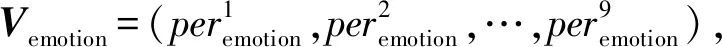
表示该诗人所写的诗中与emotioni情感有关的词语占全部与情感有关的词语的比例.
然而,得到每位诗人写作题材和情感的占比,对于分析时期的特点没有太多价值,更有价值的是将占比从大到小排序.因此,每位诗人的表示由2个向量转换成了2个有序列表,即Lpoet=(Ltheme,Lemotion),其中Ltheme=(theme1,theme2,…,theme10),Lemotion=(emotion1,emotion2,…,emotion9).通过度量2个有序列表的相似度,我们可以度量2个诗人写作风格的相似度.我们使用RBO(rank-biased overlap)[35]来度量有序列表的相似度.
3.2.2 同一时期诗人写作风格的相似度
利用古诗词图谱的信息,可以将时间和诗人写作风格这2个因素有效地联系起来.而且,古诗词知识图谱包含的信息有多种维度且非常全面,足以支撑对同一时期诗人写作风格的相似性的探究.
对同一时期的两两诗人之间计算相似度后取平均,可以得到这一时期写作风格的相似程度.初唐、盛唐、中唐、晚唐,这4个时期写作风格的相似程度如图8所示.
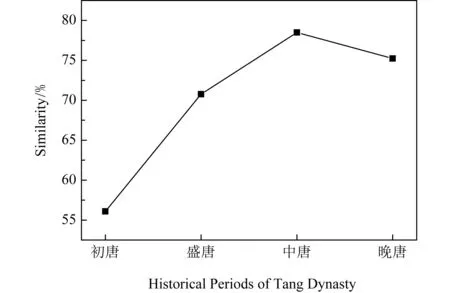
Fig.8 Trend of the similarity of writing style in different historical periods of Tang Dynasty图8 唐朝不同时期写作风格相似度的变化趋势图
图8中,这4个时期诗人写作风格的相似程度整体呈现上升趋势,究其原因,是源于对前一时期和同一时期著名诗人写作风格的效仿.而从中唐到晚唐,写作风格相似程度降低,说明诗坛的彻底没落导致对同一时期的效仿现象减少.
具体来说,初唐时期写作风格的相似程度是非常低的,也就是说,诗人的写作风格在初唐是多元化的,之后到盛唐、中唐,诗人的写作风格越来越趋于一致.晚唐时,相比于中唐时期,写作风格的相似程度有所下降.结合当时的背景来看,这个结论是比较合理的.初唐是唐诗的起步发展时期,写作风格是多元化的,而后面的时期诗人的写作就有了可参照的对象.盛唐时期是中国诗词的最高峰,在这个时期之后,很多诗人都在效仿盛唐时期诗人的写作风格.比如杜甫就是一个典型的被后世效仿和追随的对象.由于盛唐之后诗坛的没落,在同时期十分出色的诗人也会被效仿.比如中唐时期,元和新体的2个诗派分别以白居易和韩愈为首,这2位诗人就是被追随的对象.所以,从初唐到中唐,写作风格的相似程度呈现出上升的趋势.然而到了晚唐,诗坛的彻底没落,会导致诗人没有可以追随的同时期的诗人,所以写作风格的相似程度会呈现出下降的趋势.
3.2.3 相邻时期诗人写作风格的相似度
利用古诗词图谱中蕴含的信息,可以将时间和诗人写作风格这2个因素关联起来.而且,古诗词知识图谱覆盖面全、具有多种维度的特点,使得对相邻时期诗人写作风格的相似度进行分析成为可能.
对2个相邻时期的两两诗人之间计算相似度后取平均,可以得到这2个相邻时期的写作风格的相似度.图9展示了初唐-盛唐、盛唐-中唐、中唐-晚唐的相似度.
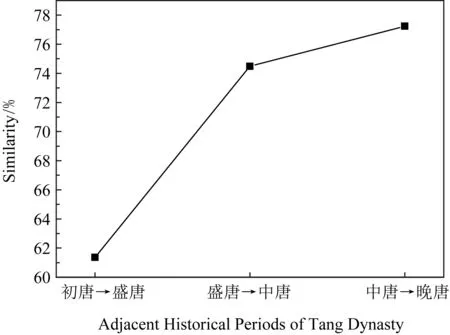
Fig.9 Trend of similarity of writing style in the adjacent historical periods of Tang Dynasty图9 唐朝相邻时期写作风格相似度的变化趋势图
从图9可以发现,随着时间的推移,相邻2个时期写作风格的相似度越来越高.这说明随着时间的推移,效仿前一个时期写作风格的现象越来越显著.
利用古诗词图谱对诗词进行数据分析,相比于只统计单字,可以得到更深层次、更有意义的结论.
4 古诗词图谱用于推理和分析任务
古诗词图谱可以适用于各种关于诗词的推理和分析任务,下面在判定诗词题材和分析诗词情感的2个任务上进行验证.
4.1 分类模型
针对判定诗词题材和分析诗词情感的2个任务,模型结构如图10所示.模型由Embedding层、CNN层/平均池化层、图注意力层、注意力层组成.首先,将诗词内容用BERT编码,然后通过CNN层/平均池化层得到诗词的更抽象的表示;将古诗词图谱用图注意力网络编码,学习到每个节点的表示,然后抽取出诗词包含的图节点,用注意力机制把它们的表示做加权和.最后,将诗词的这2部分表示拼接起来,接softmax分类器,用交叉熵损失函数来计算损失.
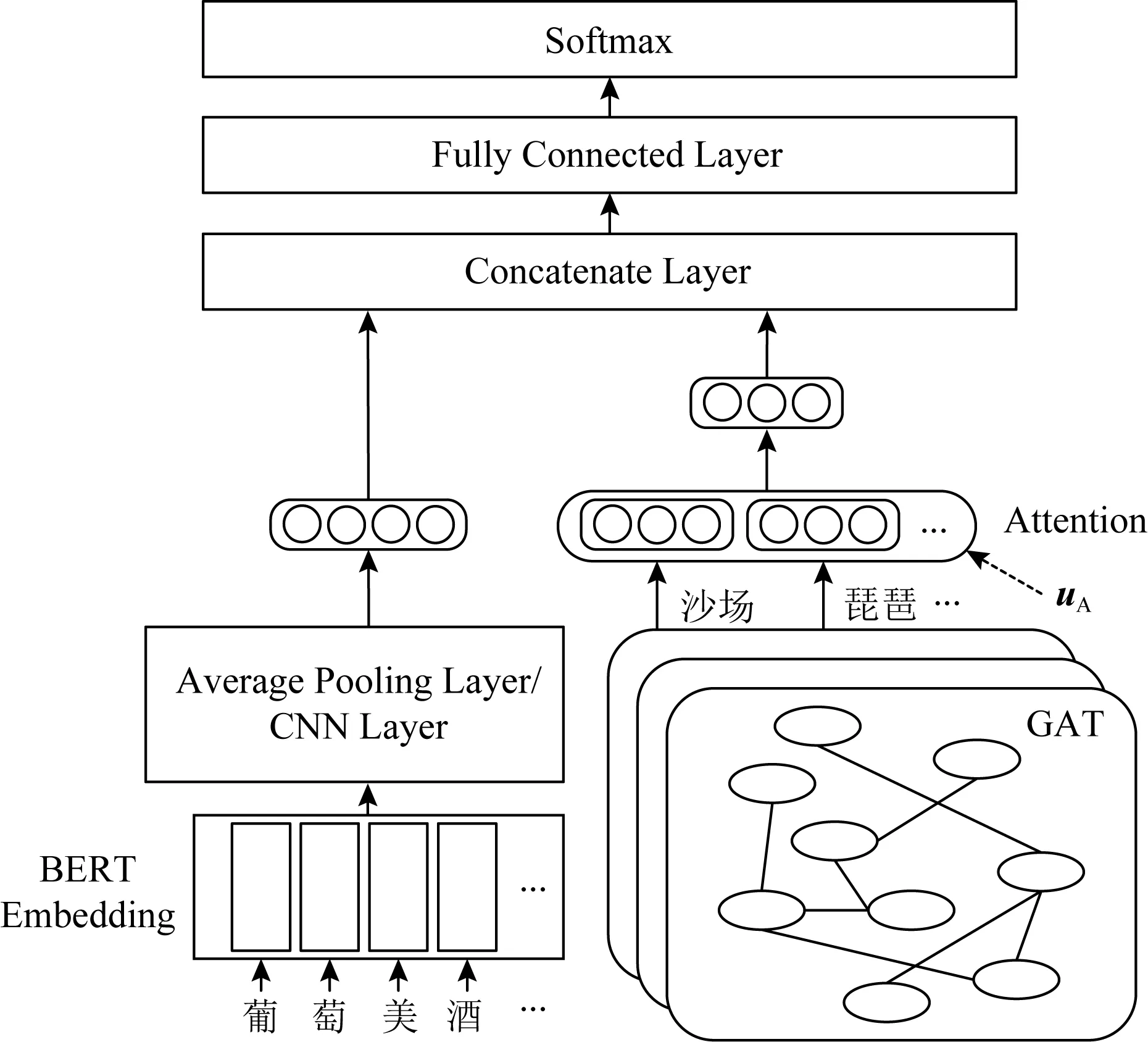
Fig.10 The model integrating classical Chinese poetry knowledge graph图10 融合古诗词图谱的模型
4.1.1 Embedding层
本文使用谷歌开源的BERT[36]中文预训练模型初始化字向量.对于每首唐诗,将标题和内容输入BERT模型,最大长度设为150.由于BERT中文预训练模型输出的字向量的维度是768,所以每首诗经过BERT预训练模型后,得到的表示的维度为(150,768).
4.1.2 CNN层/平均池化层
BERT预训练模型输出字的表示将通过CNN层或平均池化层.接下来分别描述CNN层和平均池化层.
卷积神经网络(convolutional neural network, CNN)[37]可用于捕捉文本的n-gram特征.

x1:n=x1⊕x2⊕…⊕xn,
(4)
其中,⊕表示拼接操作.更一般地,xi:i+j指的是xi,xi+1,…,xi+j的拼接.
ci=f(w·xi:i+h-1+b),
(5)
c=(c1,c2,…,cn-h+1).
(6)
对于池化层,采用最大池化,对每个特征图捕捉最重要的特征:
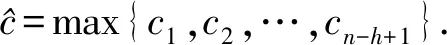
(7)
以上描述了通过1个过滤器获得1个特征的过程.在常见的CNN模型中,用不同尺寸的多个过滤器获得多个特征.
平均池化层采用bert-as-service[注]https://github.com/hanxiao/bert-as-service的平均池化策略,即每首通过BERT模型编码的诗,对第1个维度(最大序列长度)取平均,这样每首诗就表示成768维的向量,使得不同长度的诗全都编码成相同长度的向量.
4.1.3 图注意力层
图注意力网络(graph attention network, GAT)[38],能够很好地学习图结构数据的节点表示.只需要提供图结构和节点的初始特征,给予适当的监督信号,就能够自动学习其他节点对当前节点的重要程度,从而对当前节点进行更好的表示.图注意力网络的核心是图注意力层.接下来,对图注意力层的原理进行详细介绍.
然后,计算两两节点之间的注意力分数eij:
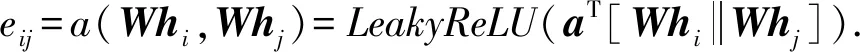
(8)
接下来,通过softmax函数将注意力分数eij进行规范化,从而得到注意力权重αij,计算过程为
(9)
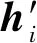
(10)
之后,还可以进一步扩展为多头图注意力层.把K个图注意力层得到的节点表示进行拼接,就得了新的节点表示:
(11)
将古诗词图谱的每个节点用BERT模型初始化特征,然后输入多层GAT,得到新的节点表示.
4.1.4 注意力层
假设一首诗包含的图节点的集合是N={n1,n2,…,nm}.从GAT层的输出取出这些节点的特征{f1,f2,…,fm},通过注意力机制,对诗中提到的不同节点的重要度进行学习,以产生合理的表示.注意力层的公式为
ui=tanh(WAfi+bA),
(12)
(13)
(14)
这一层的参数是WA,bA,uA.
4.1.5 损失函数
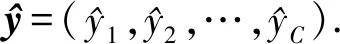
(15)
4.2 实验设置
4.2.1 数据集
为了评测判定诗词题材和分析诗词情感这2个任务的实验效果,我们设计了一些规则自动地对诗词进行类别的标注.关于判定诗词题材任务,标注了“战争”、“送别”、“闺怨”、“怀古”、“田园”、“山水”、“思乡”、“怀人”、“咏物”、“悼亡”共10种类别.关于分析诗词情感任务,标注了“悲伤”、“愁绪”、“孤独”、“怨恨”、“思念”共5种类别.关于这15种类别的标注规则,详见表2.数据集的规模详见表3.
4.2.2 评价指标
在涉及的所有分类实验中,我们使用准确率(precision,P)、召回率(recall,R)和F值(F-measure)作为每个类别的评价指标,使用宏平均值(macro-average)作为每种分类方法最终的评价指标,计算方法为
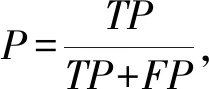
(16)
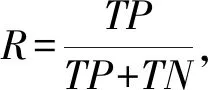
(17)
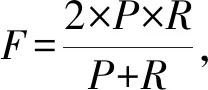
(18)
(19)
(20)

Table 2 Rules of Constructing Datasets表2 构建数据集的规则描述
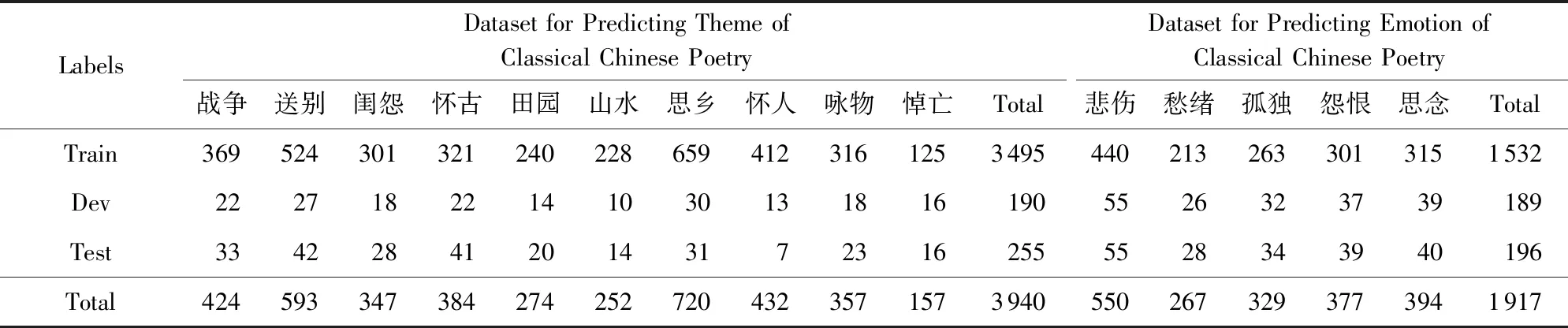
Table 3 Statistics of Datasets for Two Tasks表3 2个任务的数据集信息
其中,TP(true positive)表示将正类预测为正类的个数,TN(true negative)表示将负类预测为负类的个数,FP(false positive)表示将负类预测为正类的个数,FN(false negative)表示将正类预测为负类的个数,n是类别个数.
4.2.3 超参数设置
在验证集上对超参数进行网格搜索,确定下来的超参数如表4所示.在判定诗词题材的模型中,使用平均池化层;用2层GAT来学习古诗词图谱的节点表示.在分析诗词情感的模型中,使用CNN层;用1层GAT来学习古诗词图谱的节点表示.GAT Heads表示每一层GAT的头的个数,GAT Features表示每一层GAT输出的特征个数,Filters表示过滤器个数,Kernel Sizes表示不同卷积核的尺寸.
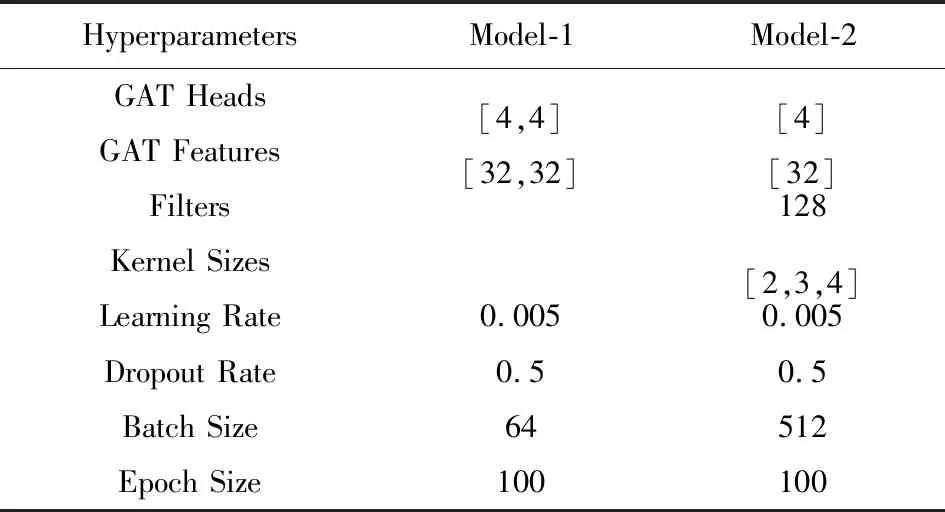
Table 4 Hyper-Parameters of the Models表4 模型的超参数
4.3 实验结果与分析
4.3.1 剥离实验
1) Rand.最基础的模型是“随机初始化字向量+平均池化层/CNN层+softmax分类器”,用“Rand”简写.
2) +BERT.为了探究BERT的影响,将随机初始化字向量替换为BERT,变成“BERT+平均池化层/CNN层+softmax分类器”,用“+BERT”简写.
3) +BERT+GAT.为了探究古诗词图谱的影响,将其加入模型,变成“BERT+平均池化层/CNN层+GAT+softmax分类器”,用“+BERT+GAT”简写.
在判定诗词题材任务上,加入BERT后,模型效果提升了14.61%,再加入GAT后,模型效果提升了5.72%.在分析诗词情感任务上,加入BERT后,模型效果降低了1.86%,加入GAT后,模型效果提升了4.13%.实验结果如表5所示,C(compare)列表示模型相比于Rand模型效果提升的大小.

Table 5 Results of Ablation Experiments表5 模型的剥离实验 %
Note: The boldfaced numbers emphasize the performance of our model.
实验结果表明:
1) BERT在判定诗词题材任务上对模型效果有极大提升,而在分析诗词情感任务上甚至起到了反作用,出现这种现象的原因是,BERT可以有效捕捉上下文的信息,包括文本的n-gram信息,在判定诗词题材任务上,若使用“随机初始化字向量+平均池化层”,无法捕捉到字与字之间的联系,而加入BERT,就加入了字的上下文信息,所以加入BERT有极大提升.而在分析诗词情感任务上,最初的模型是“随机初始化字向量+CNN层”,CNN层本身就可以捕捉文本的n-gram信息,再加入BERT,BERT中包含的上下文信息就可能变成噪声,影响模型的效果.
2) 古诗词图谱在2个任务上对模型效果均有较大提升,证明了古诗词图谱可以为诗词的推理和分析任务提供知识,对诗词的理解有帮助.
4.3.2 与其他方法的对比
本文选择的对比方法如下,实验结果如表6所示:
1) NB.胡韧奋等人[40]对唐诗题材自动分类的研究采用的方法之一.我们基于scikit-learn[注]https://scikit-learn.org/stable/,以TF-IDF作为文本特征,实现了多项式朴素贝叶斯分类器.
2) SVM.胡韧奋等人[40]对唐诗题材自动分类的研究采用的方法之一.我们基于scikit-learn,以TF-IDF作为文本特征,实现了线性核支持向量机.
3) CNN.用1层CNN自动学习文本特征[37],然后接softmax分类器.共有2个变种:CNN-rand,CNN-pretrain.对于前者,字向量被随机初始化,且在训练的过程中可被微调;对于后者,使用在4万首唐诗上预训练产生的字向量,不可微调.
4) GRU.用1层GRU自动学习文本特征[41],然后接softmax分类器.共有2个变种:GRU-rand,GRU-pretrain.对于前者,字向量被随机初始化,且在训练的过程中可被微调;对于后者,使用在4万首唐诗上预训练产生的字向量,不可微调.
5) TextGCN.TextGCN[42]模型将文本语料建模成由文档节点和词节点组成的异质图,然后利用图卷积神经网络(GCN)做半监督文本分类.
实验结果表明:
1) 我们的模型在判定诗词题材和分析诗词情感这2个任务上分别超过最好的基线模型2.64%和0.45%,证明了我们提出的模型的有效性.
2) 传统的朴素贝叶斯和支持向量机分类器在这2个任务上具有可比的效果,比一些基于神经网络的模型效果还要好.
3) CNN-pretrain的效果在这2个任务上比CNN-rand高出2.98%和1.33%,GRU-pretrain的效果在这2个任务上比GRU-rand高出3.84%和5.17%,说明字向量的初始化对模型训练非常重要,使用与训练数据相同领域的大规模语料预训练字向量,能够大幅提升模型效果.在判定诗词题材任务中,GRU-rand和GRU-pretrain的效果分别高于CNN-rand和CNN-pretrain 0.57%和1.43%;在分析诗词情感任务中,CNN-rand和CNN-pretrain的效果分别高于GRU-rand和GRU-pretrain 25.97%和22.13%.可以看出,对不同的任务和数据,CNN和RNN有不同的偏好,在判定诗词题材任务上,RNN的表现更好,在分析诗词情感任务上,CNN的表现更好.
4) TextGCN在这2个任务上是表现最差的模型,由此可以看出,TextGCN对于诗词这样特殊的短文本无法达到很好的分类效果.
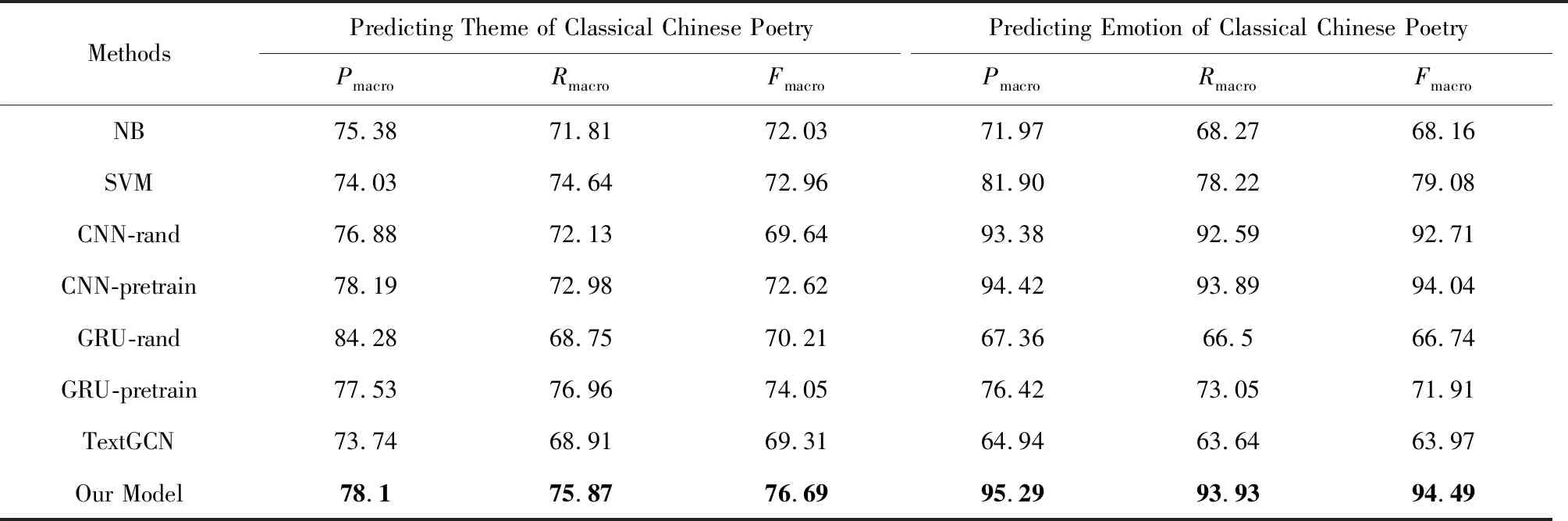
Table 6 Performance Comparison of Different Methods表6 不同方法的性能比较 %
Note: The boldfaced numbers emphasize the performance of our model.
5 总结与展望
本文提出一种古诗词知识图谱的构建方法,并使用该方法得到一个内容覆盖全面、结构层次分明、包含词语语义联系的古诗词知识图谱.利用古诗词图谱,可以从各种不同的维度上更好地分析诗词.古诗词图谱对于诗词的数据分析是不可或缺的,它能够从语义的角度有效地辅助文学研究.另外,古诗词图谱能够适用于古诗词的各种推理和分析任务上,为这些任务提供必要的知识,从而使机器更好地理解诗词.
该工作的不足之处在于构建的古诗词图谱囊括的知识仍然比较局限,目前包含的知识仅包含诗词注释和中文词典的词语解释.
未来工作中,我们将进一步优化古诗词图谱的构建过程,尽可能地降低人工参与的程度.进一步扩大古诗词图谱的规模,使其囊括更加全面的古诗词知识,比如历朝历代对著名诗人诗词的解读文字等.并且,将古诗词图谱扩展到更加广泛的应用场景,比如在诗歌生成中引入古诗词知识,使其更加符合人的意愿进行创作.再比如利用古诗词图谱中的地名信息,分析古人一生的足迹并对古代的文化中心、历史名胜进行探究等.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2022年8期)2022-08-31
计算机应用与软件(2021年10期)2021-10-15
小型微型计算机系统(2020年5期)2020-05-14
计算机与生活(2020年5期)2020-05-13
火力与指挥控制(2020年1期)2020-03-27
新城乡(2018年6期)2018-07-09
领导科学论坛(2016年9期)2016-06-05
长江学术(2016年4期)2016-03-11
长江学术(2015年1期)2015-02-27
