
基于BERT的常见作物病害问答系统问句分类
2020-06-20 12:00杨国峰
计算机应用 2020年6期
杨国峰,杨 勇*
(1.中国农业科学院农业信息研究所,北京 100081;2.农业农村部农业大数据重点实验室,北京 100081)
(∗通信作者电子邮箱wheatblue@163.com)
0 引言
农业科技是现在和未来中国农业增长的第一驱动力,农业技术推广是实现科技进步及农业和农村现代化的重要措施[1]。中国拥有国际上最大的农业技术推广人员队伍,然而研究[2]表明,中国农业技术推广体系未能为农民提供有效的技术服务。当前,一大批农业技术服务平台都在不断地用人工的方式解决农业生产者在作物种植过程中所遇到的病害问题,而依赖人工解决问题将消耗大量的人力、物力,并且很难及时地解决农业生产者的问题。随着人工智能技术的迅猛发展,构建专业领域的智能问答系统将能够为人们提供准确的诊断结果和个性化的信息服务[3]。因此,构建并应用作物病害智能问答系统将为解决以上问题提供解决方案,同时为中国作物病害识别的智能化研究与应用提供重要支撑。问答系统主要包括问题分析(问句分类)、信息检索和答案抽取三个部分,其中问句分类作为问答系统的关键模块,也是制约问答系统检索效率的关键性因素[4]。
关于问答系统中问句分类的研究,从传统的支持向量机、集成学习等[5]到基于词嵌入[6-8],再到神经网络[9-11]分类算法,均在文本分类任务的各项性能评价指标上获得了极大提升,而预训练的神经网络语言模型ELMo(Embeddings from Language Models)、OpenAI GPT(Generative Pre-trained Transformer)、BERT(Bidirectional Encoder Representations from Transformers)取得了显著进展[12]。由于农业领域一直缺乏大规模可用的语料数据库,因此关于农业问答系统问句分类的研究还较少。针对特定农业领域,少数研究者开展了语言模型在农业问答系统应用的相关研究,但仍处于起步阶段。段青玲等[13]重点研究了基于支持向量机的文本分类,实现了92.5%的资讯分类准确率。为了对饮食文本信息进行二分类,赵明等[14]建立了一种基于word2vec 和长短期记忆(Long Short-Term Memory,LSTM)网络的分类模型,其分类准确率为98.08%。赵明等[15]还构建了基于word2vec 和双向门控循环单元(Bi-Directional Gated Recurrent Unit,BIGRU)神经网络的番茄病虫害问句分类模型,对2 000条番茄病虫害用户问句进行病害和虫害的二分类,结果表明,基于BIGRU 的问句分类模型优于卷积神经网络和K最近邻等分类算法。针对传统的句子相似度算法准确率较低的问题,梁敬东等[16]通过构建基于word2vec 和LSTM 的神经网络计算问句相似度,并在水稻常问问题集中的问句上进行验证,测试集准确率为93.1%。为解决互联网农技推广社区问答数据增长过快的问题,张明岳等[17]构建了一种基于卷积神经网络的农业问答情感极性特征抽取分析模型,针对测试集的语性特征抽取准确率仅为82.7%。
上述研究为神经网络应用于常见作物病害问答系统问句分类提供了参考和依据,但是以上研究主要存在以下两个方面的问题:1)基于word2vec 等词嵌入的文本编码方式的文本表征模型还存在局限,无法准确编码同一词在不同语境下的词义;2)尽管构建的LSTM、GRU 等神经网络语言模型以及在其基础上改进的双向长短期记忆(Bidirectional-Long Short Term Memory,Bi-LSTM)网络、Transformer 等模型能够利用语境信息进行训练,但是相对于自然语言处理任务使用的大型语料,以上研究用来学习的监督数据相对较少,难以学到复杂的语境表示。当前,关于基于语境化的词嵌入[18]利用海量的无监督数据学习神经网络语言模型,即神经网络语言模型的预训练,如ELMo、OpenAI GPT、BERT 等模型相继出现,其中BERT 以及基于BERT 的改进预训练语言模型在多种自然语言任务上取得了最佳结果。
针对常见作物病害问答系统的特点与上述问题,本文研究构建基于word2vec 的双向长短期记忆自注意力(Bi-LSTM Self-Attention,Bi-LSTM Self-Attention)网络分类模型、Transformer 分类模型和基于BERT 的微调分类模型,分别进行常见作物病害问句分类实验,选取能够高效地对常见作物病害问句进行准确分类的问句分类模型作为问答系统最终采用模型。
1 材料与方法
1.1 实验数据与预处理
本研究使用Scrapy 爬虫框架,在多个百科类与农业类网站爬取44种常见作物病害相关的农业生产用户的问句,44种常见作物病害如表1所示。

表1 四十四种常见作物病害Tab.1 Forty-four common crop diseases
参考文献[19]中对作物病害的描述信息,对收集的语料进行预处理(去除重复数据,问句转换为陈述句等),从而构建常见作物病害问句数据集(Common Crop Disease Question Dataset,CCDQD)。预处理后部分样本如表2所示。

表2 部分预处理作物病害问句样本Tab.2 Some preprocessed samples of crop disease question
1.2 双向长短期记忆自注意力网络分类模型
本文使用自注意力技术来生成句子词嵌入分类模型[20],由Bi-LSTM 和一层全连接Softmax 层构成,如图1 所示。在Bi-LSTM 的基础上,模型将通过自注意力机制得到句子的表示输出到隐藏层,然后通过全连接层进行分类。
如图1所示,向模型输入一个含有n个词的句子进行词嵌入,得到S=(w1,w2,…,wn),wi表示序列中第i个标记(Token)对应的词嵌入。h1,h2,…,hn为隐藏层的对应输出,Bi-LSTM将句子嵌入为M,(m1,m2,…,mr)表示聚焦句子不同的部分,其中注意力权重为Ai1,Ai2,…,Ain。

图1 双向长短期记忆自注意力网络分类模型Fig.1 Bi-LSTM self-attention network classification model
给定训练集{(S(i),yi)|i=1,2,…,N},其中类别标签y(i)∈{1,2,…,K}(K为可能的类别数目)。为了削弱末级分类器的复杂度,强迫模型学习到更有效的表示,有助于下游问句分类任务,把从文本S(i)生成的矩阵级别表示M(i)输入Softmax层便得到离散类别标签的预测概率分布为:

其中:WS为M(i)相应的权重;bS是偏差。
本文将Cross Entropy Loss 损失函数加上Softmax 层权值矩阵的Frobenius范数约束作为训练整个网络的损失函数:

其中:θ表示网络中所有参数为p(i)的第y(i)个分量;α 是惩罚系数,用来调节惩罚项的比重,下标F 表示Frobenius范数。
1.3 Transformer分类模型
本文构建的Transformer 分类模型基于编码器(Encoder)结构[21],由于Transformer模型训练参数较多且模型较为复杂,因此仅使用了两个编码器,每个编码器包含一个多头注意力子层和一个前馈网络子层。模型中的所有子层以及嵌入层的输出尺寸为200。图2为两个编码器的Transformer分类模型。
句子的词嵌入(Sentence Embedding)与对应位置词嵌入(Position Embedding)相加后作为输入,编码器第一个子层是多头自注意力(Multi-head Attention),输出表示为sublayer(x),经过残差连接和层规范(Add&Layer Norm,LN)输出为:
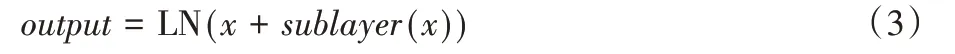
编码器第二个子层是逐项前馈网络(Feed Forward Network,FFN),由两个线性变换组成,其中每一层的参数都不同,输入和输出的维度为200,内部层的维度为2 400。

其中,W1、W2和b1、b2分别为output相应线性变换的权重和偏差。

图2 Transformer分类模型Fig.2 Transformer classification model
线性变换之后再经过残差连接和层规范,将最后一个编码器第二子层的最终输出传递进全连接层并输出分类结果。训练过程使用Cross Entropy Loss损失函数。
1.4 基于BERT的微调分类模型
借助语言模型来辅助自然语言处理任务已经得到了学术界较为广泛的探讨[22],通常有两种方式:1)基于特征,指利用语言模型的中间结果(语言模型词嵌入),将其作为额外的特征,引入到原任务的模型中,如ELMo 模型[23];2)基于微调,指利用大量语料训练语言模型,并在语言模型基础上增加少量神经网络层来完成具体任务,采用有标记的语料来有监督地训练新模型,这个过程中语言模型的参数并不固定,如OpenAI GPT[24]。上述模型的输入为从左向右输入一个文本序列,或将从左向右输入和从右向左输入的训练结合起来。然而,BERT 是一种新的预训练语言模型,即双向编码表征Transformer 的模型。相关研究[12]表明:双向训练的语言模型对语境的理解会比单向的语言模型更深刻,提取语料特征更高效。
由于BERT 可以用于各种自然语言处理的任务(如分类任务、问答任务),且仅需在核心模型的基础上进行简单修改,因此本文将构建基于BERT的微调分类模型,如图3所示。
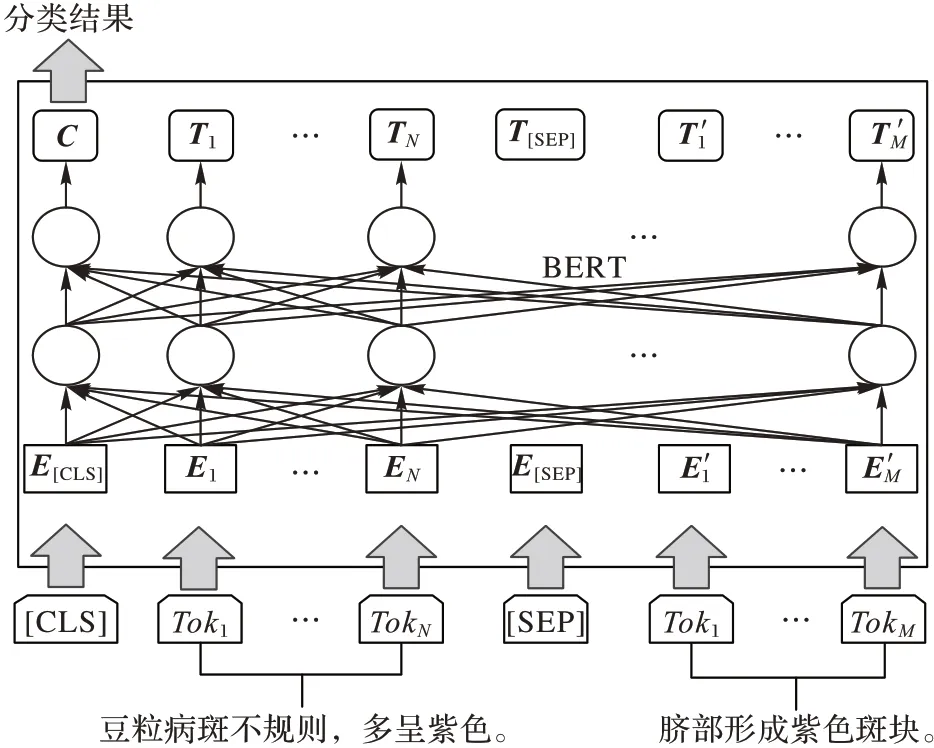
图3 基于BERT的微调分类模型Fig.3 BERT-based fine-tuning classification model
对于问答系统的问句分类任务,基于BERT 的微调分类模型在预训练BERT 模型的输出结果后增加一个分类层(全连接层)进行微调。
把作物病害问句输入模型后,将被传递到词嵌入层,包括进行标记词嵌入、句子词嵌入和位置词嵌入。在图3 和图4中:Toki表示第i个Token,随机遮挡部分字符;Ei表示第i个Token的嵌入向量;Ti表示第i个Token在经过BERT处理之后得到的特征向量。
BERT 和可学习的权值矩阵(W)所有参数都经过微调,以最大化正确分类的概率。BERT 根据[CLS]标志生成一组特征向量C,并将其与W相乘,再经过Softmax 预测各个类别的概率,其中概率最大的类别为最后输出的分类类别。
利用预训练语言模型的参数权重对模型初始化,使用Cross Entropy Loss 损失函数对基于BERT 的微调分类模型进行有监督的训练。
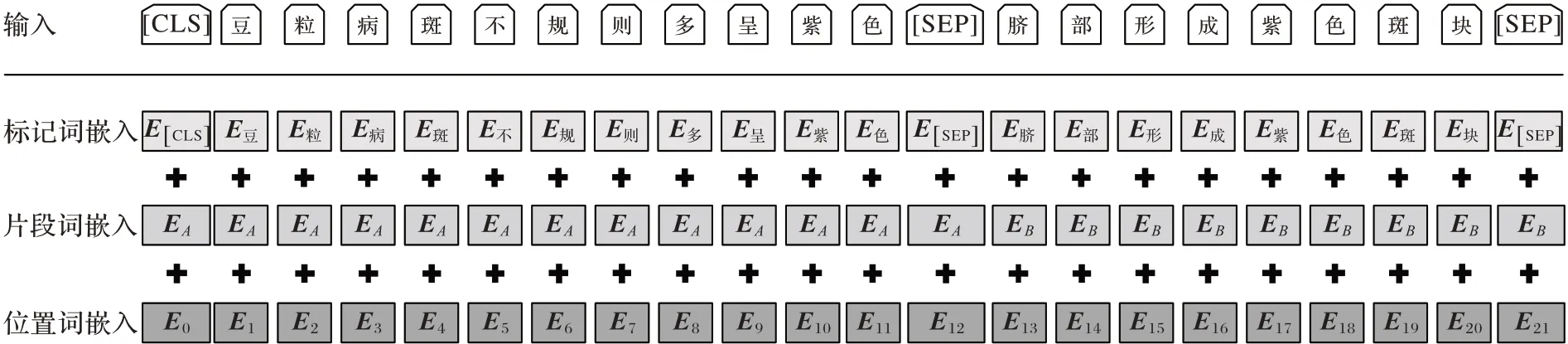
图4 BERT的输入表示Fig.4 Input representation of BERT
2 问句分类实验
2.1 实验设计
本研究收集44 种常见作物病害的问句,为防止数据集类别不平衡的影响,使每种作物病害样本数相近(60~80 条),同时将每条病害问句标注为对应所属类别,共得到有3 300条样本。利用常用的优化学习Adam 梯度下降算法[25]训练优化双向长短期记忆自注意力网络分类模型、Transformer 分类模型和基于BERT 的微调分类模型,再根据损失函数动态调整每个参数的学习率。
将超参数初始化并调优,最终设置如下:训练批量(batch)大小为16,问句词嵌入长度为200,多注意力头数(multi-head)为12,初始学习率为0.001,最小学习率为0.000 01,迭代次数(epochs)为100。为减轻三种模型在训练过程中过度参数化、过拟合,以及避免偶然出现的不良局部最小值现象,设置Dropout 参数[26]为0.1。同时,为得到可靠稳定的模型,采用十折交叉验证(10-fold cross-validation)的方法[27]进行训练。
本文研究采用准确率、精确率和召回率以及综合指标F1值作为问句分类模型的测评指标[28]。其中:准确率是指分类正确的问句数除以整个数据集的问句总数;精确率是指分类器正确判断为该类的问句数与分类器判断属于该类的问句总数之比;召回率是指分类器正确判断为该类的问句数与属于该类的问句总数之比。F1值是精确率和召回率的调和平均值,最大值为1,最小值为0:

其中:P为精确率;R为召回率。
2.2 分类实验结果及分析
对构建的双向长短期记忆自注意力(Bi-LSTM Self-Attention)网络分类模型、Transformer 分类模型和基于BERT的微调分类模型分别使用预处理后的同一数据集进行分类实验。
由表3 可知,对于不同的迭代次数,基于BERT 的微调分类模型与另外两个模型相比,其准确率、精确率和召回率均高几个百分点。当三个模型同时训练100 迭代次数时,对于F1值指标,基于BERT 的微调分类模型F1值为91.92%,比Transformer 分类模型高2.62 个百分点,比利用双向长短期记忆自注意力网络分类模型高4.46个百分点,表明:基于BERT的微调分类模型的问句分类效果最优,Transformer 分类模型居中,双向长短期记忆自注意力网络分类模型结果稍差。
本实验也证实了双向长短期记忆自注意力网络分类模型提取问句语言特征的能力弱于Transformer,尽管双向长短期记忆自注意力网络分类模型增加了自注意力机制,但是Transformer 分类模型的准确率、精确率和召回率以及F1值均超过了双向长短期记忆自注意力网络分类模型。相较于双向长短期记忆自注意力网络分类模型和Transformer 分类模型,虽然基于BERT 的微调分类模型与Transformer 分类模型的网络结构有相似的结构,但基于BERT 的微调分类模型在预训练阶段通过无监督的方法学习具有上下文语义的词嵌入特征,能更好地表达语义,在微调阶段再用监督的方法训练BERT 模型和全连接层的参数。基于BERT 的微调模型的优势在于充分利用了具有上下文语义的信息,可基于少量监督学习样本,针对不同下游任务改造模型实现目标。实验结果表明,基于BERT 的微调分类模型具有结构简单、训练参数少、训练速度快等特点,同时能够高效地对常见作物病害问句准确分类,可以作为问答系统问句分类模型。

表3 问句分类模型的分类结果Tab.3 Classification results of question classification models
使用基于BERT 的微调分类模型进行作物病害问句分类,正确分类的部分实例与对应的分类结果如表4所示。

表4 问句分类结果的部分实例Tab.4 Some examples of question classification results
基于上述实验,选择作物病害问答系统问句分类效果最优的基于BERT 的微调分类模型,对影响问句分类效果的样本数量(训练数据集规模)进行研究。在保持模型结构和初始超参数不变的情况下,改变数据集规模(1 100、2 200、3 300)进行实验,迭代次数均设置为100次,测试结果如表5所示。

表5 不同样本数量的模型分类结果Tab.5 Model classification results under different sample sizes
由表5可得,训练数据集的规模对基于BERT的微调分类模型的分类效果有较大影响。鉴于真实场景下作物病害识别分类对准确率有较高的需求,因此在对基于BERT 的微调分类模型进行训练时,大量高质量的训练数据集可以提高整个作物病害问答系统类别分类的准确率。
探究基于BERT 的微调分类模型作为作物病害问答系统问句模型的有效性,并进行相关实验。在不同样本数量的数据集下,三种模型的有效性(F1值)如图5所示。
由图5可知:BERT模型的F1值在不同数量的数据集上均保持最高;而当数据集较小时,双向长短期记忆自注意力网络分类模型F1值比Transformer分类模型的F1值高;随着数据集的增大,Transformer 分类模型的F1值反超双向长短期记忆自注意力网络分类模型F1值。BERT 模型的预训练是一个耗时的过程,通过使用预训练好的模型进行分类任务微调仍然能够实现很好的分类效果,验证了基于BERT 的微调分类模型作为作物病害问答系统问句模型的有效性。
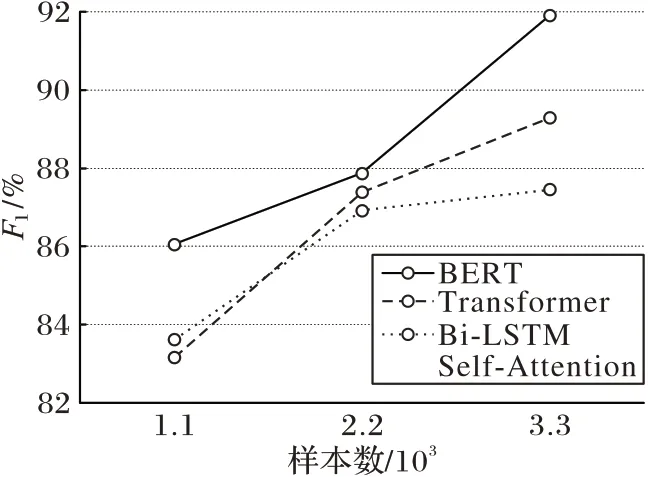
图5 不同模型的有效性结果对比Fig.5 Validity comparison of different models
3 结语
本文针对农业问答系统用户问句语义信息复杂、差异大的问题,构建了基于BERT 用于问句分类任务的作物病害问答系统的问句分类模型,证实了两阶段模型(超大规模预训练与具体任务微调)较强的表征学习能力对问句分类的影响。通过与双向长短期记忆自注意力网络分类模型和Transformer分类模型进行对比,由实验结果可知,基于BERT 的微调分类模型的准确率、精确率和召回率以及F1值均高于另外两种问句分类模型2~5 个百分点,表明基于BERT 的微调常见作物病害问句分类模型可以高效地提取问句文字的特征,用于后续的分类实验。对三种模型使用不同数量的数据集进行实验,结果表明,随着数据集规模的增加,基于BERT 的微调分类模型与另外两种模型相比F1值明显上升,表明了问句分类模型的选择和训练数据集的规模对常见作物病害问答系统问句分类效果具有较大影响。接下来将进一步扩大作物病害问句类别的覆盖范围,满足更多用户对作物病害类别识别的需求。
猜你喜欢
汽车实用技术(2022年9期)2022-05-20
今日农业(2021年19期)2021-11-27
乐器(2021年1期)2021-09-10
建材发展导向(2021年13期)2021-07-28
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
人大建设(2018年7期)2018-09-19
广西民族研究(2014年6期)2015-05-05
