
视觉类深度神经网络的自动标注
2020-06-20 12:00:48郭晨皓
计算机应用 2020年6期
李 鸣,郭晨皓,陈 星*
(1.福州大学数学与计算机科学学院,福州 350108;2.福建省网络计算与智能信息处理重点实验室(福州大学),福州 350108)
(∗通信作者电子邮箱chenxing@fzu.edu.cn)
0 引言
视觉是人类理解认识外部世界的重要途径,在人类认知的过程中,有超过80%的信息量来自视觉系统,而计算机视觉作为计算机科学领域一个重要的研究方向,目标是让计算机能够帮助或者代替人眼感知图像、视频或者多维数据,并从中获得目标的信息和数据[1]。
如今,随着对深度神经网络研究的进一步深入,它在计算机视觉领域中也有了广泛的应用,并在目标检测、目标跟踪、超分辨率、图片生成、3D 建模和人体姿态相关等方向都取得了不错的效果[2]。因此,含有更多隐藏层的复杂模型被提出,相对于传统的机器学习方法具有更强大有效的特征学习和特征表达能力。而面对着越来越多的模型,通过阅读论文文档来学习了解相关模型的开发人员也就产生了如何根据所遇到的问题快速准确地找到合适模型的需求。本文根据这一需求进行了相关的调研,发现目前已有对科学文章进行提取关键词并推荐的研究[3],但是,它不是专门针对视觉类计算机神经网络来实现自动标注。因此,本文提出了模型应用领域的自动标注系统,通过对模型进行自动标注,能够帮助开发人员更加快速准确了解该模型的应用领域,从而判断是否是自己需要的模型。
本文的主要工作如下:
1)利用词频等信息计算得到不同领域中的关键词以及其对应的权值,并据此构建了视觉类深度神经网络的架构图,方便之后的模型分类。
2)本文发现关键词作为最能体现模型所属领域特点的词组表达,往往在摘要中出现的地方具有相似性与固定性,根据这一发现,提出了能够提取文章摘要关键词组的八种提取模型。
3)在实际数据上进行实验,结果表明,与传统机器学习分类算法相比,本文的方法可实现更好的性能。
1 相关工作
1.1 关键词提取
目前,关键词提取技术主要可以分为三类:语言学方法、统计方法、机器学习方法。
1.1.1 语言学方法
语言学方法中使用了单词、句子和文档的语言属性,最常使用的语言属性是词法分析、句法分析、语义分析和语篇分析[4-6]。基于语言学方法具有不可避免的缺点,首先语法规则不可能涵盖所有语句,其次这种方法对开发者的要求极为苛刻,开发者不仅要精通计算机还要精通语言学,因此,虽然语言学方法解决了一些简单的问题,但是无法从根本上将自然语言理解实用化。
1.1.2 统计方法
统计方法基于术语内部词之间黏着度较高的假设,该方法不需要训练数据,而是利用统计特征实现关键词提取[7]。目前统计方法包括n-gram 统计信息[8]、单词词频[9]、词汇同现[10]、PAT 树(PATricia tree)[11]等。但是单纯依靠内部黏着度效果并不理想,并且互信息算法很难排除语料中超低频词和超高频词的干扰等。
1.1.3 机器学习方法
机器学习方法在关键词提取上的应用主要分为有监督和无监督学习方法。有监督的关键词提取将问题看作是二进制分类的问题,主要存在三个问题:需要昂贵的人工标注费用,不能满足某些的特定要求和无法提取面向事件的关键短语[12]。与之相反,无监督方法不需要标记的训练数据,而是探索一些外部统计信息来识别关键短语[13],目前无监督的方法主要是基于词频-逆文本频率(Term Frequency-Inverse Document Frequency,TF-IDF)、聚类和图的排序[14-16]。
1.2 文本分类
目前,文本分类主要可以分两类:基于传统机器学习的文本分类和基于深度学习的文本分类。
1.2.1 基于传统机器学习
传统的机器学习方法主要利用自然语言处理中的n-gram概念对文本进行特征提取,并且利用TF-IDF[17]对n-gram 特征权重进行调整,然后将提取到的文本输入到Logistics 回归[18]、支持向量机(Support Vector Machine,SVM)[19]等分类器中进行训练,但是,这类问题存在数据稀疏和纬度爆炸等问题。
1.2.2 基于深度学习
针对传统机器学习的高纬度高稀疏、特征表达能力弱等问题,相关领域专家将深度学习应用到文本分类中来解决这些不足。
Wang 等[20]通过应用word embedding 来改善短文文本的分类,虽然该方法在一些文本分类任务中,分类的效果甚至超过了卷积神经网络(Convolutional Neural Network,CNN)/循环神经网络(Recurrent Neural Network,RNN),但是如果一个句子如果很长,少量的重要信息会被多数的无用信息淹没。Banerjee 等[21]将CNN/RNN 应用在文本分类中,与word embedding 相比更适用于长文本的分析,其中CNN 擅长捕获更短的序列信息,RNN 擅长捕获更长的序列信息,但它们难以捕获长期的上下文信息和非连续词之间的相关性。Cheng等[22]通过引入Attention 机制,可以对输入的每个部分赋予不同的权值,抽取出更加关键及重要的信息,使模型作出更加准确的判断,同时不会给模型的计算和存储带来更大的开销。
2 方法设计
2.1 总体结构
视觉类深度神经网络自动标注的流程如图1所示。
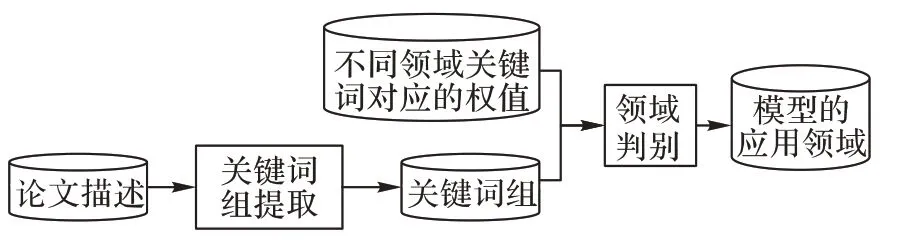
图1 总体框架Fig.1 Overall framework
首先将模型描述作为输入,根据关键词提取可以得到文章的关键词,然后依据得到的关键词以及不同领域关键词对应的权值计算得到该模型的应用领域。
2.2 模型研究领域的判别
2.2.1 视觉类深度神经网络架构图设计
目前,深度神经网络在计算机视觉中的多个领域都有着广泛的应用[23],本文主要针对其中的六个领域进行研究,从网络公开的计算机视觉类论文中,收集了这六个领域共264 篇论文作为实验的语料库。其中:目标检测48 篇,目标跟踪44篇,超分辨率54篇,图像生成43篇,3D建模相关36篇,人体姿态相关39 篇。根据语料库中264 篇论文,并通过以下的计算公式,得到不同领域对应的关键词及其对应的权值(关键词和权值会随着语料库的扩充进行相应的增加和修改)。
在对某个领域进行关键词选择和权值计算时,本文主要考虑两方面:第一,词在该领域论文摘要中出现的频率;第二,词出现的论文摘要在该领域摘要中的占比。
1)计算词在不同领域论文摘要中出现的频率,计算式如下:
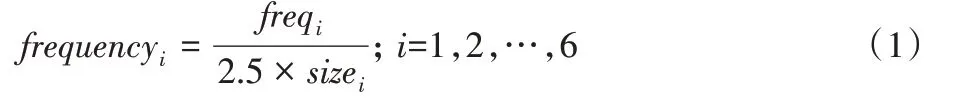
其中:freqi表示该词在i领域论文摘要出现的次数;sizei表示i领域中总的论文摘要数。通过观察发现,词在一篇文章中出现的次数一般为1~3,基本都是低频词,所以这里将sizei乘以2.5 是为了保证计算的frequencyi值不会超过1 并且又不会过小。
2)计算词出现的论文在不同领域的占比,计算式如下:
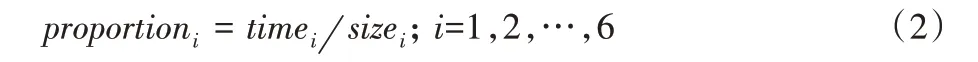
其中:timei表示i领域论文摘要中出现该词的摘要数;sizei表示i领域中总的论文摘要数。
3)计算词在不同领域的权值,计算公式定义如下:
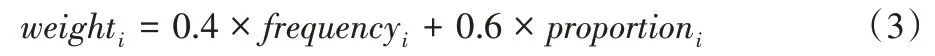
其中词频和占比以4∶6 的比例计算,最终结果保留一位有效数字。在计算过程中过滤掉proportioni低于0.2 的词,因为这些词不具有领域代表性。最后,通过人工经验筛去一些干扰词,得到领域的关键词及其对应的权值
根据实验得到的关键词和权值构建出了视觉类深度神经网络架构,如图2 所示,其中:第三层中单词字号越大代表该单词在这个领域的比重越大,而相同大小的单词代表相同的权值,第四层是第三层中每个领域对应关键词的具体权值,这里每个领域只具体列出前五个。

图2 视觉类深度神经网络架构Fig.2 Visual deep neural network architecture
2.2.2 模型关键词的提取
通过观察视觉类神经网络论文的摘要特点,发现关键词作为最能体现模型所属领域特点的词组表达,往往在文中出现的地方具有相似性与固定性。根据这一发现,本文提出了八种关键词提取模型,以下是模型的定义与示例。
1)提取模型一:首句主语。
在计算机视觉类论文的文摘中,论文试图解决的问题一般会在首句就有体现,而首句的主语一般就会有对该问题的表述,所以首句的主语对应的词组对于内容的判别来说很有参考和提取的价值。
提取模型一定义:从句子依存树的ROOT(根节点)出发,向前回溯,找到依存于该ROOT 且关系为nsubj(名词性主语)的实体词组,如未找到则取第一个找到的依存关系为dobj(直接宾语)的实体词组。
以句子s1为例:

s1对应依存树如图3所示。

图3 s1对应的依存分析树Fig.3 Dependency analysis tree corresponding to s1
根据提取模型一的定义,从ROOT 出发,即可得到关系为nsubj 的词“recognition”,再以该词为起点向前和向后寻找与该词有依存且为修饰关系的词,提取到整个实体词组:“Material recognition for real-world outdoor surfaces”。
2)提取模型二:特定名词及其修饰词。
在计算机视觉类论文的摘要中,表述文章解决的问题或涉及的领域的信息常常会包含某些特定的名词(具体如表1所示),针对这些特定的名词提取出对应的词组,也能够帮助判别模型所属的领域。
提取模型二定义:以特定名词作为实体词组的名词性主体和触发条件,向前回溯与这一名词性主体存在依存关系的修饰词,同时向后遍历,提取case(状语)关系涉及的修饰和conj(连接词)作为后缀修饰信息。
以句子s2为例:

s2对应依存树如图4所示。
根据提取模型二的定义,该句中“problems”为特定名词,向前回溯得到依存于该词的修饰词,最终提取出词组“various visual recognition problems”,由于“problems”无后缀,所以这里不需要向后遍历。
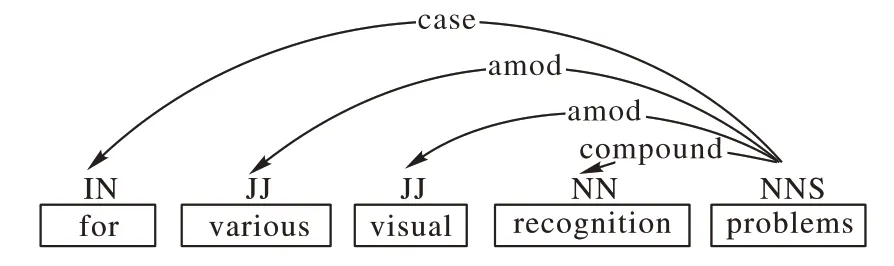
图4 s2对应的依存分析树Fig.4 Dependency analysis tree corresponding to s2
3)提取模型三:特定名词的case/mark 指向部分。
根据观察,提及论文主要工作的词组常常出现在特定名词(具体如表1 所示)的case(状语)或者mark(主要为“that”“whether”或者“because”)指向的部分。由此现象,提出了该提取模型三。
提取模型三定义:以特定的名词出发,向后查看是否存在限定场景、领域和应用范围的case/mark 关系引导,如果有,根据case和mark引导规则的不同:对于case,直接对case指向的实体词组进行提取;而对于mark,向后遍历找到依存关系是dobj(直接宾语)的词语,然后判别mark 与dobj 对应词之间的词是否依存于mark或mark指向的词,如果有则加入到最后提取出的词组的前修饰中。
以句子s3为例:

s3对应依存树如图5所示。

图5 s3对应的依存分析树Fig.5 Dependency analysis tree corresponding to s3
根据提取模型三的定义,该句中the problem of 为特定名词,而其后是mark 引导的,所以向后寻找依存于mark 的直接宾语,得到“keypoints”,然后提取整个实体词组,最终得到“estimating and tracking human body keypoints”。
4)提取模型四:特定及物动词的直接宾语。
在计算机视觉类论文的摘要中特定的及物动词(具体如表1 所示)往往直接宾语往往能够代表文章的主要工作,所以这类直接宾语即为需要提取的目标词组。针对这一规则,提出了提取模型四。
提取模型四定义:检测句子中的关键词,随后寻找该关键词的直接宾语,即依存关系为dobj(直接宾语)的词语,依据索引获取该词语对应的实体词组。
以句子s4为例:

s4对应依存树如图6所示。

图6 s4对应的依存分析树Fig.6 Dependency analysis tree corresponding to s4
根据提取模型四的定义,该句中“improve”为特定的及物动词,所以提取其直接宾语“precision”,然后根据“precision”提取实体词组,得到“precision of facial landmark detectors”。
5)提取模型五:特定动词的直接宾语对应的动词短语。
对于特定的动词(具体如表1 所示),表达主要文章工作的内容常常出现在该修饰的宾语的从句之中,而特定动词修饰的宾语在从句中通常充当主语的成分,对应的动词短语即是目标词组。
提取模型五定义:首先检测该特定动词对应的依存关系为dobj(直接宾语)的词语,如果之后有从句信息,则继续向后遍历查找依存于该直接宾语的动词,根据查找到的动词,获取动词短语作为目标词组。
以句子s5为例:

s5对应依存树如图7所示。

图7 s5对应的依存分析树Fig.7 Dependency analysis tree corresponding to s5
根据提取模型五的定义,该句中“propose”为特定动词,然后寻找得到对应的直接宾语“network”,由于之后还有从句信息,所以寻找“network”对应的动词即“reconstruct”,最终找到“reconstruct”对应的动词短语“reconstruct the high resolution image”。
6)提取模型六:for引导的短语。
在摘要之中,“For”常常在句首出现,作为句子表明解决的问题的限定,对表达论文属于哪一计算机视觉类的研究方向有着一定指示的作用,同时由于句式的不同和表达方式的不同,也存在句中使用“for”引导的情况。基于以上观察,设计和实现提取模型六。
提取模型六定义:首先判断是否句首为“For”并且依存关系为case(状语),如果满足,则根据case 这一依存关系指示的对象提取实体词组。如果句首不是“For”,则遍历句子查找“for”单词,满足上述同样的条件的情况下,提取目标短语。
以句子s6为例:

s6对应依存树如图8所示。
根据提取模型六的定义,该句满足句首为“For”并且依存关系为case 这一条件,所以找到依存于“for”且关系为case 的“modeling”,最后根据“modeling”提取实体词组得到“modeling the 3D world behind 2D images”。
7)提取模型七:特定及物动词引导的宾语。
计算机视觉类论文的摘要中,一般存在主语为“We”,且句中存在特定及物动词(具体如表1 所示)来表述关键信息的句子,基于这样的观察,设计提取模型七。
提取模型七定义:如果句子主语为“We”,则寻找句子中特定及物动词,找到特定及物动词后继续向后遍历找到与该及物动词存在依存关系的词,根据该词提取前置修饰和后缀修饰,整理组合作为目标短语。
以句子s7为例:

s7对应依存树如图9所示。

图8 s6对应的依存分析树Fig.8 Dependency analysis tree corresponding to s6

图9 s7对应的依存分析树Fig.9 Dependency analysis tree corresponding to s7
根据提取模型七的定义,该句主语为“We”,并且“propose”是特定及物动词,继续向后遍历得到依存于“propose”的词“algorithm”,然后根据“algorithm”提取前置修饰和后缀修饰,最终得到“a novel visual tracking algorithm based on the representations”为目标词组。
8)提取模型八:特定非及物动词引导的宾语。
与提取模型七同理,存在主语为“We”,且句中存在特定非及物动词(具体如表1 所示)来表述关键信息的句子,基于这样的观察,设计提取模型八。
提取模型八定义:如果句子主语为“We”,则寻找句子中特定非及物动词,找到非及物动词后继续向后遍历,寻找与该词存在依存关系的宾语,根据该宾语提取前置修饰和后缀修饰,整理组合作为目标词组。
以句子s8为例:

s8对应依存树如图10所示。
根据提取模型八的定义,该句主语为“We”,并且“focus”是特定非及物动词,继续向后遍历得到依存于“focus”的宾语“task”,然后根据“task”提取前置修饰和后缀修饰,最终得到“task of amodal 3D object detection”为目标词组。
由于抽象出的提取模型不同,所以需要结合不同的特定词完成提取目标词组,提取模型对应的特定词如表1所示。

图10 s8对应的依存分析树Fig.10 Dependency analysis tree corresponding to s8

表1 提取模型对应的特定词Tab.1 Specific words corresponding to extraction models
根据上述的八种模型,提取得到摘要的关键词组,为便于后续公式计算,进行应用领域判别,需要将提取到的目标词组转化为单词的集合,这里采用词袋模型[24]的思想。

式中:patternResult是所有提取模型结合关键词匹配提取的目标词组;wordsi由第i个模型匹配得到的词组以词为单位分解而来的词集;wordBag是所有wordsi包含的词的集合。
2.2.3 领域判别
根据上述2.2.2 节中八个模型提取到的关键词组以及2.2.1节中构建出的视觉类深度神经网络架构,通过判别公式可以计算得出模型所属的领域,这里的判别公示采用余弦相似度[25]来判断预测模型与哪种领域更加匹配,具体步骤如下:
步骤1 根据式(7)和2.2.1节构建的视觉类深度神经网络架构第四层的关键词对应的权值,计算六个领域的领域向量xi。式(7)中wij即为i领域中第j个关键词对应的权值,总共有m个关键词(m值根据所属领域的关键词数量决定),最终得到六个领域的领域向量如表2所示。

步骤2 根据式(8)以及模型通过2.2.2节中八个模型提取到的关键词集合,计算该模型在六个领域的模型领域向量yi。式(8)中,zij为i领域中第j个词的模型权值,zij的值有两种情况,如果模型提取出的关键词集合中含有i领域的第j个词,则zij与wij值一致;否则为0。
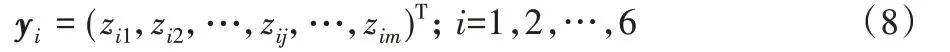
步骤3 计算模型与六个领域的匹配程度,由步骤1与步骤2 可以得到xi和yi向量,然后通过式(9)计算得到余弦相似度simi表示该模型在第i领域中的相似度,值越大越接近于1表示与这个领域越匹配。
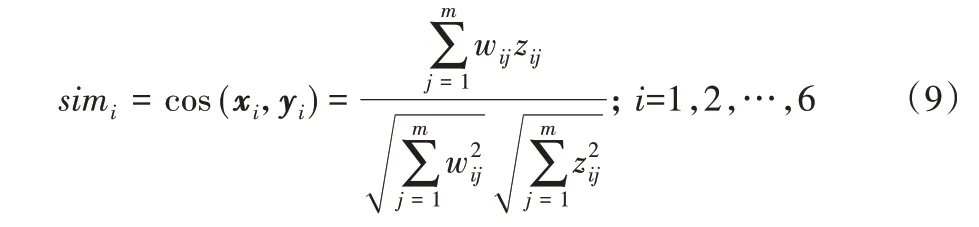
步骤4 计算模型第k匹配的领域,根据式(10)可以得到topk,即6 个领域中与模型第k接近的领域,当k为1 时即表示模型最大概率所属的应用领域。
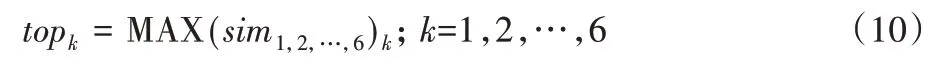

表2 六个领域对应的领域向量Tab.2 Field vectors corresponding to six fields
2.2.4 评估标准
为了正确评估实验性能,选择以下指标作为评估标准:查全率R(recall)、查准率P(precision)、均值F1、宏平均查全率Macro_R、宏平均查准率Macro_P、宏平均值Macro_F1[26]。
计算式如下:

其中:TPi表示标注结果为第i领域且结果正确的论文摘要数目;FNi表示将第i类领域错误标注成其他领域的论文摘要数目;FPij表示将第j类论文领域错误标注成i类的论文摘要数目。
3 实验与结果分析
3.1 实验数据
实验数据来自近三年计算机视觉方面的三大顶级国际会议:国际计算机视觉大会(IEEE International Conference on Computer Vision,ICCV)、IEEE 国际计算机视觉与模式识别会议(IEEE Conference on Computer Vision and Pattern Recognition,CVPR)和欧洲计算机视觉国际会议(European Conference on Computer Vision,ECCV),共收集了72 篇论文。其中,目标检测14 篇,目标跟踪11 篇,超分辨率14 篇,图片生成11篇,3D建模10篇以及人体姿态相关12篇。
3.2 实验设计
首先,对模型输入进行分句、分词和依存分析,然后得到实验所需的单词集合以及依存分析树,接着通过2.2.2 节中的八个提取模型对输入模型进行关键词的提取,最终根据2.2.3节的流程得到输入模型的应用领域判别结果。
以图11 为例,在输入模型之后,得到了模型提取的关键词、模型领域向量以及模型领域判别结果,该模型应用领域判别结果显示:最匹配的领域为人体姿态相关,随后依次是3D建模相关和目标检测,由于与另外三类相似度为0(根据模型领域向量在这三个领域值都为0 可以看出),所以这里只输出三个匹配结果。

图11 实验示例Fig.11 Experimental example
3.3 实验结果及分析
文本实验设计基于以下两个方面进行比较和验证提出的自动标注系统的优越性和有效性:1)对于相同的语料库和验证集,采用不用的传统机器学习算法进行分类,比较并验证本文提出的自动标注系统的优越性;2)对比系统分析出的top1和top2的正确率来判断自动标注系统的有效性。
1)实验1。
此次实验直接将自动标注系统输出的top1作为最终预测的结果,并和贝叶斯、Logistics回归、SVM和决策树方法进行文本分类比较。其中贝叶斯采用多项式分布朴素贝叶斯方法,SVM 采用LinearSVC(Linear Support Vector Classification)。评估标准根据2.2.4节中所定义,实验结果如图12和表3所示。

图12 实验1中不同方法的F1值对比Fig.12 F1 value comparison of different methods for experiment 1
通过图12 和表3 可以看出,虽然本文方法在目标跟踪和3D 建模上的F1 值不是最高的,但是在其他几种领域上都是最高且F1 值达到0.9 以上,尤其在目标检测上达到1,并且在Macro_R、Macro_P和Macro_F1 平均达到0.89,均远远高于其他4种方法,说明获得了较好的分类效果。
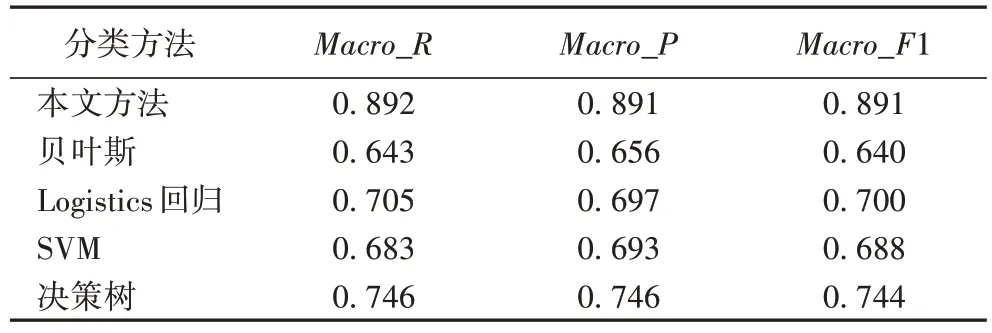
表3 五种方法的宏平均对比Tab.3 Macro average comparison of five methods
2)实验2。
为了深入了解模型自动标注的效果,本实验对模型领域预测中相似度最高的前两名计算了正确率,也就是对应自动标注系统输出结果的top1 和top2 的总正确率,结果如图13所示。
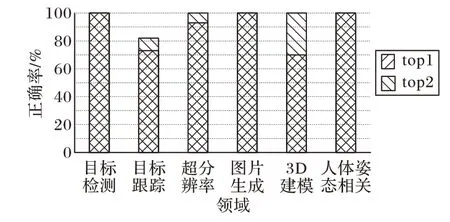
图13 实验2中top1和top2的正确率Fig.13 Accuracies of top1 and top2 for experiment 2
单看top1的正确率,目标检测、图片生成以及人体姿态相关都能达到100%,而超分辨率和目标跟踪次之,分别为93%和73%,3D 建模最低为70%。当引入了top2 的正确率后,可以明显看出,除了目标跟踪为82%的正确率,其他五个领域都能达到100%的正确率,说明该自动标注系统基本能实现对输入模型的准确判定。开发人员在使用这套系统的时候,直接通过输出的top1 和top2 的结果,基本就可以快速判断该模型是否是自己所需要的模型。
综合以上实验可以看出,本文的方法在评估标准上取得了很好的结果,各方面均优于其他的传统机器学习算法,证明了本文方法的有效性和优越性。
4 结语
本文针对开发人员难以从众多复杂的模型中选择自己所需要模型的问题,提出了对视觉类深度神经网络的模型进行自动标注的系统,建立了能够抽取关键词的八种模型,并基于这些模型对模型进行自动标注。实验结果表明,该方法相较于其他传统机器学习算法能够得到较高的宏平均。下一步,将把该自动标注系统应用于对模型的推荐系统之中,使得开发人员能够更好地获取自己需要的相关模型。
猜你喜欢
疯狂英语·初中天地(2021年4期)2021-06-09 06:50:58
疯狂英语·初中天地(2019年12期)2020-01-04 02:46:58
中学生英语(2016年11期)2016-12-01 07:04:16
高中生学习·高三版(2014年3期)2014-04-29 06:09:37
当代修辞学(2013年3期)2013-01-23 06:41:24
英语学习(2009年7期)2009-08-05 05:39:32
第二课堂(初中版)(2009年12期)2009-01-18 07:44:20
中学生英语·阅读与写作(2008年4期)2008-12-22 06:52:06
中学英语之友·中(2008年2期)2008-04-01 01:25:04
