
基于感知对抗网络的图像风格迁移方法研究
2020-06-19 00:10李君艺尧雪娟李海林
合肥工业大学学报(自然科学版) 2020年5期
李君艺,尧雪娟,李海林
(广东理工职业学院 工程技术学院,广东 广州 510091)
图像风格迁移是一种基于深度学习的图像转换方法,可广泛应用于图像处理、计算机图片合成和计算机视觉等领域。最初的图像风格迁移是由文献[1-2]提出的基于优化方法,该方法运用卷积神经网络(convolutional neural network,CNN)的反向传播,并利用逐像素对比进而得到最优的图像转换模型,因此速度非常慢。文献[3]将生成式对抗网络(generative adversarial network,GAN)引入深度学习领域,从此GAN在图像转换模型中受到了广泛的青睐。学术界基于GAN模型提出了许多改进的图像转换方法。文献[4]提出了在训练GAN时额外加入特征空间损失(Lfeat)和图像空间损失(L2);文献[5]将网络中间层的特征图差异作为感知损失函数,并利用GAN得到的风格迁移和超分图像,实现了实时风格化和4倍清晰度;文献[6]基于GAN得到了从低分辨率图像到超分辨率图像生成的SRGAN模型;文献[7]提出了感知损失与GAN相结合的感知对抗网络(perceptual adversarial network,PAN)模型,实现了多种图像转换应用。在图像风格迁移研究中,文献[5]方法被证实能获得良好的效果,但其感知损失网络是预训练好的VGG-16网络,网络中的损失不容易优化,且该网络主要是用来做分类的,对图像主体的识别能力较强,而对背景的保留能力较弱。鉴于此,本文提出一种基于PAN模型的对抗训练方法,该方法将对抗损失、内容损失和风格损失组成新的感知损失函数,能够将损失网络与图像转换网络交替更新,从而取代固定损失网络[5]。本文提出方法的实现效果与文献[1]和文献[5]方法相比,能够增强图像的背景清晰度,使其在内容和风格上更接近原图。
1 研究现状
1.1 感知对抗网络
文献[3]提出的GAN包含2个模型,即生成模型G(generatr)和判别模型D(discriminator)。其中,生成模型G的功能是一个样本生成器,即通过输入一个噪声/样本生成图片;判别模型D的功能如同一个二分类器,主要是来判断一张输入图片是否真实,输出1(真)或输出0(假)。
在训练过程中,生成模型把生成的样本和真实样本随机地传送一张(或者一个 batch)给判别模型 D。判别模型D尽可能正确地识别出真样本和生成的假样本。生成网络与判别网络的目的正好是相反的,从而两模型就组成了min-max对抗关系,在训练过程中双方都不断优化自己,直到达到平衡。
受GAN模型的启发,在已有的感知损失[5]研究基础上,文献[7]提出了PAN模型。PAN结合感知损失和生成对抗损失,在图像转换网络和判别网络之间进行对抗训练,能够持续地自动发现输出与真实图像间存在尚未被缩小的差异。因此,当在高维空间上测量到的差异很小时,判别网络模型的隐藏层会更新至更高层次,持续寻找新的输出图像和真实图像之间存在的差异。
GAN的创新在于不再需要像传统图像模型那样需要一个根据人为经验构造的复杂损失函数,该方法通过对抗网络自动学习实现从输入到输出图片的映射,并应用到图像转换问题进而实现一个泛化的模型。而PAN则在GAN的基础上,结合了感知损失进行对抗训练,增强了图像的自然和真实感。PAN可实现多种图像转换任务,如图像超分辨率、去噪、语义分割、自动补全等。
1.2 图像风格迁移过程
Johnson的图像风格迁移过程分为训练阶段和执行阶段2个阶段[5]。在训练阶段系统选定一张风格图Ys,基于每张风格图训练一个转换网络模型。内容图X的样本持续地通过迭代从训练集中获取。在每次迭代中,转换网络把内容图X转换为Y,并把X和Y随机输送到判别网络D,网络D通过对抗损失函数判断X和Y(内容)、Ys和Y(风格)之间的差异,反馈给网络T,T调整权重和参数再进入下一个迭代,同时网络D不断优化寻找更多的差异。最后目的是生成具有Y风格的图像转换网络模型。而在执行阶段,系统则把任意一张内容图输入到训练好的Y风格转换模型,并把内容图实时转换成Y风格的效果,且原本的内容和结构不变。
2 改进的图像风格迁移网络结构
尽管VGG-16损失网络能通过ImageNet数据集进行良好的训练,但VGG-16网络中的损失却不容易优化。若能在D的隐藏层加入监督项用以衡量生成的效果,使得损失能在网络T更新时随时更改,则更易得到更好的T。因此,本文对图像风格迁移网络进行了改进,具体如图1所示。
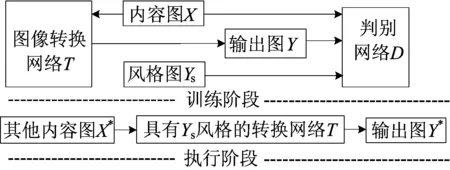
图1 图像风格迁移过程
2.1 对抗网络结构
在训练阶段,本文设计一个图像转换网络T和一个判别网络D如图1所示。转换网络T能把内容图X转换为输出图Y,并把X和Y随机输入到判别网络D,判别网络D则能辨别图片是真实图片还是转换网络T的生成图片。判别网络D能够通过参数更新不断优化,最大化判别出图片来自训练集还是转换网络生成的概率。转换网络T则希望尽可能蒙蔽损失网络,使损失函数最小化。运用Goodfellow[3]交替更新(1)式可解决对抗性的min-max问题,(1)式如下:
Ex∈X[ln(1-D(T(x))]
(1)
具体而言,判别网络D利用在隐藏层上的参数,使转换网络T训练生成的图像与真实图像具有相同的高级特征。同时,如果当前层次上的误差足够小,那么D的隐藏层将被更新上升到更高层次,发掘生成图和真实图之间存在的差异。不同于已预训练好的固定知觉损失网络[5],本文提出的感知对抗损失能在图像转换网络和判别网络之间进行对抗训练,持续进行参数更新使差异达到最小化,从而能够识别在网络的多个层次上衡量生成图和真实图之间的差异。
2.2 图像转换网络
图像转换网络T对文献[5]提出的网络进行了改进,图像转换网络结构如图2所示。整体结构沿用其深度卷积残差网络共有3个卷积层和5个残差块,如图2a所示。除了输出层使用一个缩放的tanh函数保证输出像素在[0,255]以外,其他所有非残差卷积层均使用Relu激活函数。由于不使用任何的池化层而使用步幅卷积或微步幅卷积做上采样和下采样,因此这样既减少了参数,又保持了大视野和避免图像物体过度变形[5]。

图2 图像转换网络结构
考虑到Johnson的网络中每一个非残差卷积层都跟着一个空间性的批量正则化(batch-normalization)以实现加速收敛,而文献[8]研究表明实例正则化(instant-normalization)比批量正则化能显著地提升性能,因此本文采用实例正则化替代批量正则化,如图2b所示。
由此可见,实例正则化实际上就是把batch size修改为1,把正则化用在单个图像而不是批量图像上,因此采用实例正则化改进后的网络在测试时的效果表现更好。
2.3 判别网络
判别网络D是一个多层卷积神经网络,具体如图3所示。每个隐藏层后面都加入Batch-Normality和LeakyReLU线性激活函数。第1、4、6、8层则用于衡量生成图与目标图之间的感知对抗损失。判别网络输出一个概率,即判断图片是来自于真实数据集(True)还是由转换网络生成(Fake)[7]的。
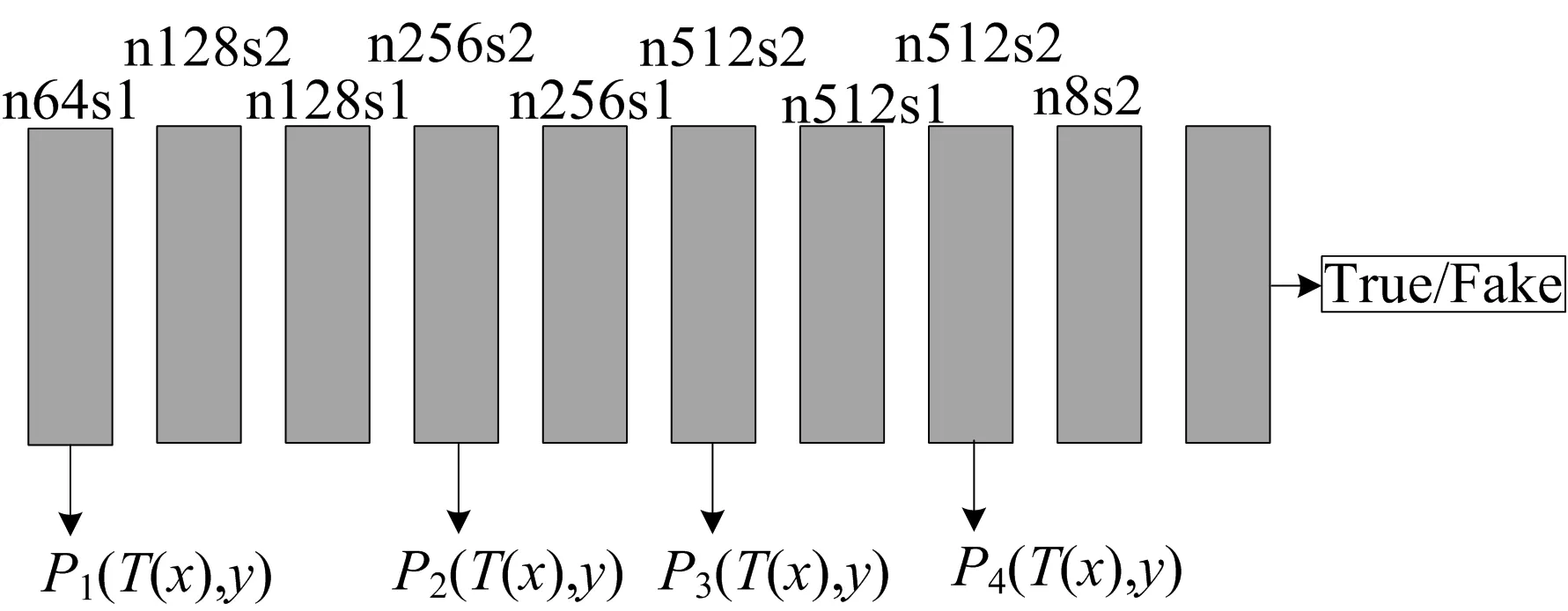
图3 判别网络结构
3 感知对抗损失
尽管感知损失网络[5]已被证实能从高维度的视觉感知层面衡量图像之间的差异,但如何通过隐藏层提取有效的特征差异仍然是一个开放性问题。问题的关键在于如何在每一个高维度层次中最小化生成图与真实图之间的差异[6]。为此本文结合PAN模型和文献[5]提出的感知损失,定义感知对抗损失由内容(特征)损失、风格损失和对抗损失组成。在N层的判别网络中把图像特征看成N个维度的特征图,若每层特征图的尺寸为Hi×Wi,则特征图谱的尺寸为Ci×Hi×Wi,其中C表示特征图的数量。由于图像的每一个网格位置都可以当作一个独立的样本,因此能抓住关键特征。感知对抗损失是内容损失和风格损失的加权和,它在判别网络的第1、4、6、8隐藏层动态更新时,能惩罚生成图与目标图之间的差异,从而使生成图具有最优的内容和风格合成效果。
3.1 内容损失函数
内容损失函数Pi使用曼哈顿距离计算隐藏层的生成图Y与真实内容图X的图像空间损失(L2)[7]如下:
(2)
其中,Hi()表示判别网络第i个隐藏层的L2值。
多个层次的内容损失可表示为:
(3)
其中,λi表示判别网络N个隐藏层i的平衡因子。通过最小化感知损失函数Lcontent使生成图与内容图具有相似的内容结构。
3.2 风格损失函数
考虑到风格损失函数是用来惩罚输出图像在风格上的偏离,包括颜色和纹理等,因此本文使用风格重建方法[1],即通过输出图片与风格图片Gram矩阵的距离获得。把φi(x)设为第i个隐藏层的特征图,这样φi(x)的形状为Ci×(Hi×Wi),判别网络第i层特征图的风格损失值可表示为:
(4)
为了表示从多个层次进行的风格重建,本文把Gi(Ys,Y)定义一个损失的集合(针对每一个层的损失求和)为:
(5)
3.3 感知对抗损失函数
整体感知损失由内容损失和风格损失组合为线性函数,具体如下:
Lperc(Y,(X,Ys))=λcLcontent(X,Y)+
λsLstyle(Ys,Y)
(6)
其中,λ为根据人为经验设定的权重参数。转换网络T与判别网络D基于整体感知损失值进行交替优化。
2个网络之间的交替优化则根据PAN[7]的方法实现min-max对抗。对于生成图Y与内容图X、风格图Ys,网络T的损失函数与网络D的损失函数为:
LT=ln(1-D(T(x)))+Lperc,
LD=-ln(D(y))-
ln(1-D(T(x)))+[m-Lperc]+
(7)
在(7)式中设定一个正数边界值m。通过网络T的参数最小化LT可同时使LD的第2、3项最大化,因为正数边界值m能使LD的第3项实现梯度下降。当LT小于m时,损失函数LD将会使判别网络更新至一个新的高维度层次去计算尚存的差异。因此,通过感知对抗损失,生成图与目标图之间的多样化差异能被持续感知和发掘。
4 实 验
4.1 实验环境及数据
因为图像风格迁移网络的训练需要大量的矩阵计算,以及转换网络和判别网络的前馈和后馈学习,所以本文选择在NVIDIA P40 GPU进行训练运行,并使用Torch平台和CuDNN加速。其中,训练样本使用Microsoft COCO 2014数据集,并把原始图像调整为224×224像素进行特征归一化作为输入的内容图。本文训练了大约7×104张图片,耗时约5 h。
4.2 效果对比
4.2.1 定性对比
本文选取在风格化图像研究中常用的几种风格图为每个风格训练一个图像转换网络,然后把本文效果图与文献[1]和文献[5]的进行对比,具体如图4所示,其中,第1行为内容图和风格图;第2行为文献[1]的方法;第3行为文献[5]方法;第4行为本文方法。

图4 风格迁移效果对比
从效果上来看,本文提出的方法能增强图像的真实和自然感,包括巴士的树木背景、自行车标志及树丛背景、冰熊的身体,内容在语义上更接近原图。不同风格下,背景内容都有清晰的语义表示,如图5所示。

图5 多风格效果图
4.2.2 定量对比
考虑风格迁移方法的目的是实现风格损失和内容损失,即实现(6)式最小化,因此可以从衡量成功减少损失函数幅度上,把本文提出的方法和文献[5]方法作对比。本文分别使用2种方法训练50、100、200张图片对每组训练记录(6)式的值。3种不同尺寸图片的损失函数值如图6所示。从图6可以看出,无论对于低分辨率还是高分辨率的图像,感知对抗网络都能更有效地使损失函数最小化。
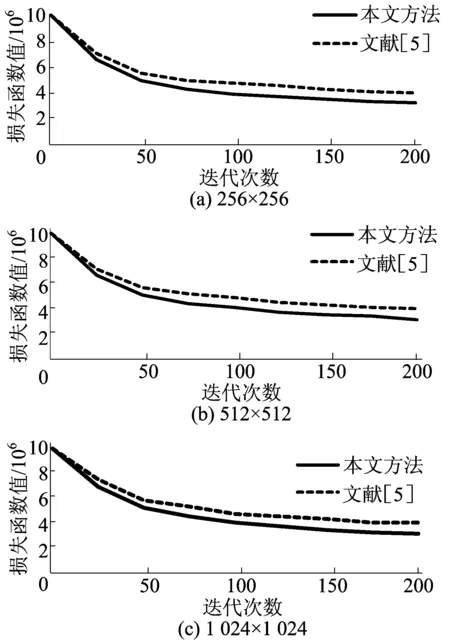
图6 损失函数值对比
5 结 论
本文基于感知对抗损失对图像风格迁移方法进行了改进。根据PAN模型框架,将对抗损失与感知损失相结合,应用于图像风格迁移的卷积神经网络训练。图像风格迁移过程大体上参照文献[5]方法,但与其固定损失网络不同,判别网络根据感知损失持续地更新参数并发掘生成图与目标图之间的特征差异,同时,图像转换网络利用判别网络进行前馈训练,直至差异最小化,得到最优的图像转换模型。因此,图像转换网络与判别网络根据感知损失交替更新。实验结果表明,对比文献[5]方法与其他方法,基于感知对抗损失的图像风格迁移获得更清晰的表现效果,内容结构更接近原始图像。在今后的研究中,将考虑进一步优化网络结构和损失函数,在颜色和纹理等方面,增强了内容图和风格图的结构相似性和语义一致性。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
速读·下旬(2021年11期)2021-10-12
中学生数理化·中考版(2021年3期)2021-07-22
数学小灵通·3-4年级(2021年5期)2021-07-16
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
大东方(2019年12期)2019-10-20
今日农业(2019年15期)2019-01-03
科学与财富(2017年22期)2017-09-10
商情(2017年1期)2017-03-22
