
电影大数据的多角度构建与可视化分析
2020-06-19 04:43黄剑波何绍荣
现代电影技术 2020年6期
黄剑波 何绍荣
(1.上海大学上海电影特效工程技术研究中心,上海200072)
(2.上海中兴软件有限责任公司,上海201203)
自2003年以来,中国电影市场蓬勃发展,年总票房增长了近50 倍。而随着移动互联的到来,国人线上购票比例逐年增加,现今已超过90%的电影购票来自线上。人们越来越多地选择线上下单线下观影,并会留下评价。这无疑给大数据时代的电影分析研究提供了巨大的可挖掘数据。当今除了影视社交平台拥有巨量数据外,无其他独立组织收集、提供中国用户电影数据,这给电影大数据研究者带来巨大的困难,因为收集原始数据是一项繁杂而困难的工作。为此,本文运用网络数据采集技术,致力构建出一个相对全面的中国用户电影数据库,最终构建完成了一个包含:电影基础数据、评价数据、评价者数据、影人数据的电影资料库。这也为电影数据研究工作解决了源头问题。本文数据库信息量大、内容详实,涵盖电影各个维度。此基础之上可进行诸如数据可视化、票房预估、观众偏好分析、个性化推荐、影片评论分析、电影立项决策、市场发展趋势判断等内容研究。
本文构建了一个相对全面的电影数据库,大量的电影数据研究可以此为基础,深入挖掘数据中蕴含的联系,为中国电影数据研究领域提供一定的基础数据信息内容。另外,本文根据此数据库对其中的部分数据进行了可视化分析,直观地展示了数据中诸如年份、国别、类型、评论内容等信息,分析了各部分呈现规律。
1 数据库设计
电影数据库的设计较为复杂,涉及到电影信息、题材类型、国家和地区、演职人员、电影机构等,需要实现大部分信息之间的互动,实现交互式电影数据库。系统要求实现全面的交互功能,即实现在电影信息中,出品、摄制、发行、引进与电影机构链接交互;演职人员如库中有相关人员资料的实现链接交互;剧照、海报、评论文章与相关的电影及电影人员实现交互等,中国电影资料馆林飞等人在《电影数据库设计》中提出了很多建设性意见。制定了一套比较完善的电影数据库,其组成如表1所示。

表1 数据库组成表
2 研究方法

图1 研究工作流程
2.1 数据采集
本文数据采集是通过python 语言的requests,包 括 访 问 各 大 网 站http/https 开 头 的URL 网页获取页面信息,包括豆瓣电影、猫眼电影、Box office mojo等电影信息网页。网页解析需要借助pyquery、xpath及正则表达式等解析库解析获取网页内容。因为大部分商业网站会存在抵抗机器大量密集访问机制,也就是一定时间单个主机IP 仅能爬取限定次数,如果获取网页次数超过限定值就会触发此机制,页面展示信息也就不是目标网页。本文利用VPS云主机进行ADSL动态拨号这一特点获取动态IP,当访问网页时在IP 无法使用时及时更换IP 主机地址,达到连续大量采集信息。
2.2 数据清洗
当采集豆瓣电影页面时,由于其库中存在大量的电视剧、歌剧及真人秀节目数据,这需要避免进入电影数据库。豆瓣还无法从电影评论页获得超过500 个用户评论信息,因为其界面从底层进行了限制,因此本文通过获取大量的用户浏览过的所有电影界面,进而获取电影评论来扩充电影评论数据,这样只要获取用户量足够,部分电影就可以做到超过500 个评论文本。目前已有1000 部电影评论数据超过了500 条。另一方面,在获取电影基本信息时,需要把一些以数字形式在页面显示字符串的转化成短整型或者浮点型,如评分、打分人数、短评数量、长评数量、上映时间等;部分诸如电影类型:“剧情/喜剧”这样的数据需要拆分成列表;不存在的数据需要设置成默认值,最后保存成便于批量运行分析的数据,统一存储到MongoDB。
2.3 数据存储
借助MongoDB 数据库存储工具进行数据存储,总共建立四个数据库:movie_base_data、movie_commenters_data、movie_casts_data、movie_comment_data。movie_base_data 即电影基础数据,其中建立不同的信息表,如票房、卡司等,表里面的数据以字典形式存储,主键以电影特有的ID 命名;movie_commenters_data,即评论者信息数据,其中主要存储电影评论者的个人信息,以用户注册昵称为主键;movie_comment_data,即电影评论信息,其建表以每部电影唯一ID 命名,每条评论以评论者的昵称为主键;movie_casts_data,即电影影人数据,其建表以每个影人的唯一ID 命名,参演电影ID 为主键。
2.4 可视化
数据分析使用numpy、pandas工具,可视化使用工具为seaborn、matplotlib,地图生成工具展示通过Geopandas处理并展示,通过可视化可以直观看到数据库数据组成状况和其中隐含的信息。
3 电影大数据的可视化分析
3.1 电影基本数据分析
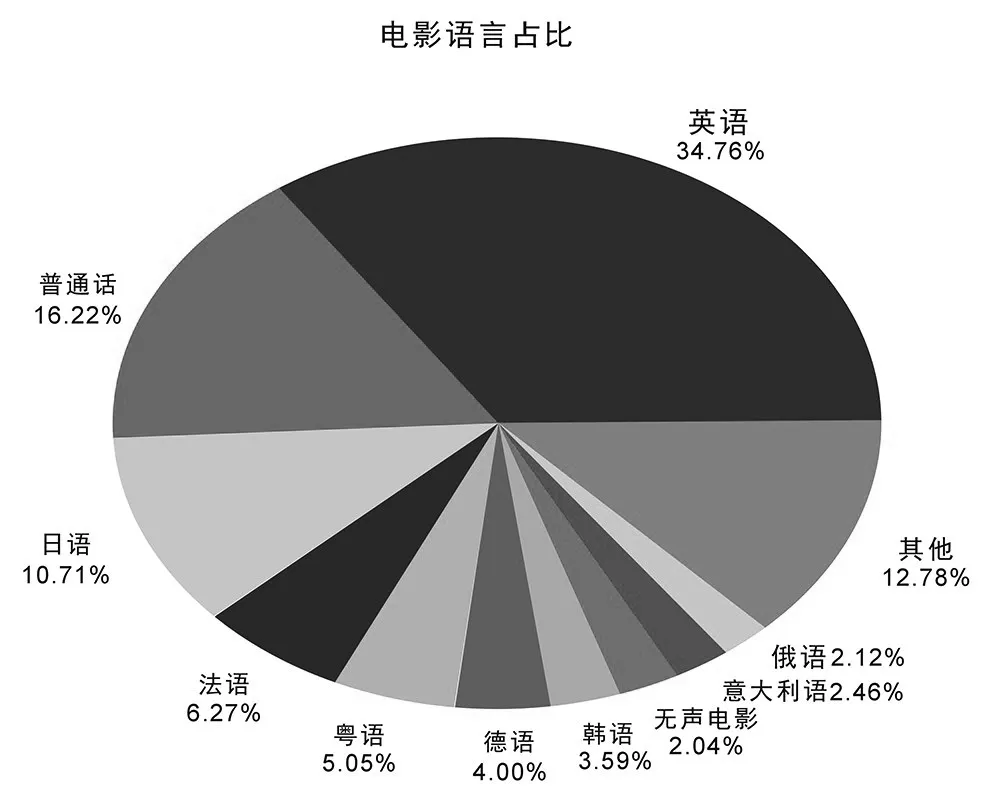
图2 不同语言电影占比
图2 展示了电影基本数据中不同电影所用语言占比,这个数据库较为庞大,几乎涵盖了所有语言。由图2可看出:大家在选择电影时,英语电影占比相对最大,其次是中文电影,比较特殊的是粤语电影占比也达到5.05%,可见中国香港在中国电影市场中占据一定席位。这张图也大致描绘出全球电影产出比例。

图3 世界各国电影数量在地图上的热度显示
图3 展示了数据库中不同国家电影数量对应在地图上的热图,国家产出电影数量越多,颜色越深。此图也基本反映现在世界上各个国家电影市场大小:美国遥遥领先,中国位居第二,接下来印度、日本、韩国、英国、法国等处于第三阶层。总体来说欧洲国家电影产出不是很高,但很多国家在世界占有一席之地;非洲除了南非其余发展中国家普遍在电影产业相对弱后;亚洲国家电影产业最大为中国,印度、东南亚、中东、日本、韩国都存在相对较大的电影产出量。

图4 电影数量在所有年份上的分布,横坐标为年份,纵坐标占比情况
图4 展示了数据库中对应各个年份电影发行数量,可以看到整体呈数量上升趋势。可以看到:电影数量在1900 年左右开始,每年上升比例明显,在2008年有一个小下降,往后一直处于上升阶段,这映衬了中国电影从2008 年以来电影市场快速增长这一趋势。
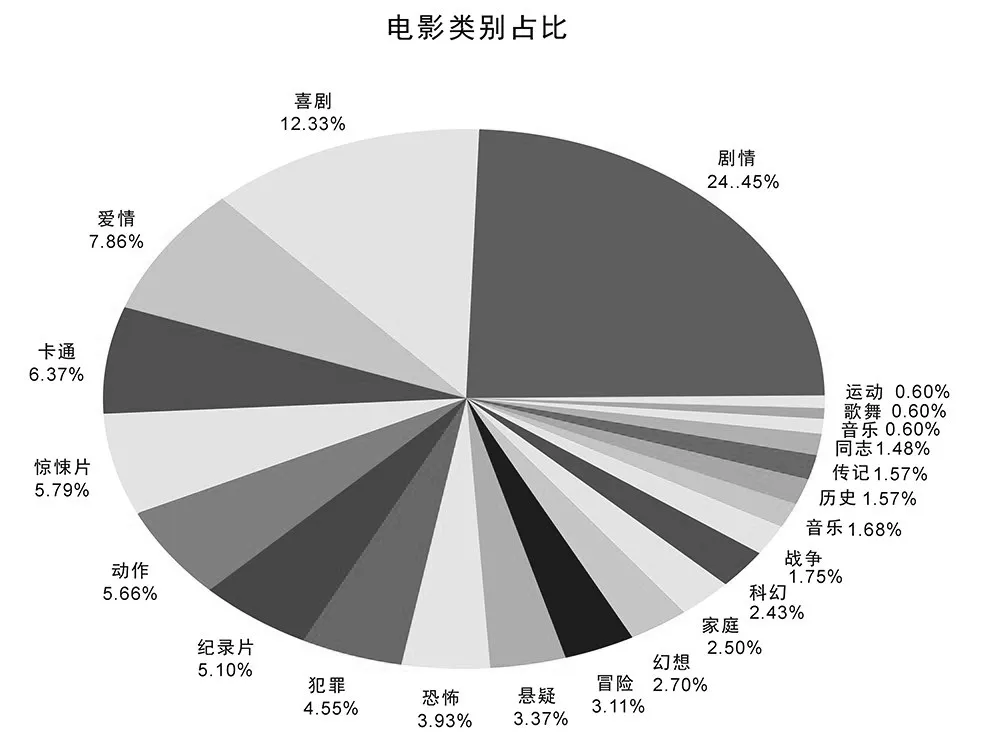
图5 数据库中不同类型电影占比
图5 可以看出各个类别电影在数据库中的组成比例,显然,数据库中剧情片的比例最大,这也很符合我们的预期;其次是喜剧,这两个类型电影数量远超其他类型,爱情、卡通、恐怖片、动作片等比例相差不大。一部电影的类型是可以重合的,既是爱情又是喜剧,还是剧情片,图5是把电影所属类型标签(可以是多个)出现次数进行汇总计算比例。
3.2 电影评论与评论者信息分析
3.2.1 电影评论者信息分析
图6显示了所有电影评分时评论者给出星级所占比例分布,可见大家给电影评分时主要集中在三、四、五星,一、二星相对比例较少。

图6 数据库所有电影一到五星占比,横坐标为单部电影一到五星百分比,纵坐标为出现频率

图7 数据库中所有电影评分分布,横坐标为评分值
图7展示了数据库中所有电影在评分上的分布,可见电影评分主要集中在5.0~8.5 分,基本呈高斯分布,进一步验证了图6 的结论。
图8 显示了豆瓣Top250 电影中所有评论者来自的国家数量热图,颜色越深代表人数越多,很明显评论者绝大部分居住在中国,其次是美国,然后是英国、日本,对比在中国的人数相差两个数量级。图9展示在中国的各个省和直辖市评论者分布情况,旁边的热度条数字为ln (数量),即居住省市人数量取e为底数的对数,因为不同省市数量相差较大,直接取值,颜色不容易突出。可以从图中看出:北京、上海的电影评论者相对大于其他省,推测是由于大城市具有更多电影院、更浓厚的文化氛围等,其次是广东、浙江、江苏,相对来说仍然是经济较为发达的省份,可见经济越发达的地区,看电影和评电影的人越多,电影文化更浓厚。

图8 豆瓣Top250 电影前10 个国家的评论者数量及用户在世界各地分布热图

图9 中国的前10 个豆瓣Top250 评论者数量及常住地和评论者数量的居住地点的热图
3.2.2 单部电影评论分析
(1)单部电影评论词云
图10 展示了电影 《复仇者联盟》的评论词云,本文从1300 条中文豆瓣评论中提出每个词的词频,其中需要过滤掉一些诸如 “一个”“的”“吗”等停用词,因为这些词频在展示时几乎不反应信息,所以进行停用。从图中可以清楚看到在这些评论中常提及的是:英雄、钢铁、绿巨人、队长、爆米花、超级、特效、大片、喜欢、好看等字样,基本包含其中的主要人物、电影特色、观影感受等。由此可见,词云图对电影的整体评论覆盖比较全面,通过词云基本就可以掌握电影基本相关内容以及大众对此片的态度。

图10 基于评论词频的电影 《复仇者联盟》评论词云
(2)单部电影评论情感分析

表2 根据评分分词后并贴标签一星二星为nlike,三星为unknow,四星五星为like

表3 模型在电影评论文本情感分析的准确度
表2 展示了部分评论的标签,由于人工标注需要大量的时间,设置标签时进行了比较简单的处理,电影评价者点评给分为一星、二星时,情感标签为nlike,当给分为三星时情感标签为unknow,四星、五星评论标签为like,即不喜欢、未知、喜欢。表3 为测试集(整体评论的10%)在SVC、朴素贝叶斯、CNN、RNN、GRU 等模型上的准确度,因为在设置标签时过于简单,预测结果并不理想,简单可以看出具有长程记忆的RNN 及其改良的GRU模型具有更好的预测性能。当然这项工作需要更多的实验来验证和改善,最重要的是进行准确的情感标记,这需要在未来投入更多的努力,同时单部电影1000条评论对于神经网络数量也存在不足,可以考虑多部电影评论进行训练,但这可能又会带来欠拟合等问题,所以电影评论文本情感分析还存在大量的工作需要去完成。
4 结语
本文构建了一个包含电影基础数据、评论数据、评论者数据以及影人数据的电影数据库,其中包括超过6 万部电影的类型、出品国别、标题、年份、类型、语言、时长、首映时间、评分等基础信息,以及超过2000 位评论者的所有评论信息和相应的昵称、常住地点、年龄、性别等评论者个人信息,还有相关电影超过5 万位影人信息等,容量已超过国内现有所有公开电影数据集,涵盖数据维度全面。此外部分数据库信息已打包成json 和csv 格式数据,可实现共享。通过对数据库中的数据进行可视化展示与分析,可以看出,目前美国电影市场处于世界领先位置,中国位居第二,远超其他国家。中国电影评论者大都分布在中国的发达省市,海外发达国家也有少部分定居,可见电影文化的繁荣与经济情况呈正相关。另外,从电影大数据可以得知,中国电影在2000 年之后产量一直处于增长状态,世界电影产量也一直处于稳步增长状态。
猜你喜欢
工业设计(2022年4期)2022-05-17
师道·教研(2022年1期)2022-03-12
新闻研究导刊(2021年17期)2021-11-02
智富时代(2019年7期)2019-08-16
智富时代(2019年7期)2019-08-16
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
初中生世界·七年级(2017年2期)2017-01-20
新媒体研究(2016年9期)2016-10-14
小猕猴智力画刊(2016年6期)2016-05-14
