
协同训练算法在滚动轴承故障诊断中的应用
2020-06-18 05:59:48王得雪陈俊杰
计算机工程与应用 2020年12期
王得雪,林 意,陈俊杰
1.江南大学 数字媒体学院,江苏 无锡214122
2.江苏省媒体设计与软件技术重点实验室,江苏 无锡214122
3.西门子中国研究院,北京100102
1 引言
滚动轴承是旋转机械中最常见、最容易损坏的部件之一。在工程实践中,滚动轴承的失效会造成巨大的生产损失和人员伤亡。因此,研究滚动轴承的故障诊断,对于防止意外发生具有重要的意义[1]。
滚动轴承的故障诊断主要包括特征提取和状态识别。针对原始振动信号,往往从时域、频域或时频域等方面提取反映机械设备运行状态的量化指标。然而特征指标的增多会造成特征空间维数灾难,特征集不可避免地包含干扰甚至噪声特征[2],使诊断效果变差。并且在传统的轴承故障诊断中,需要使用大量标记样本训练模型以预测未知样本的标记,数据的标记需要消耗大量的人力、物力,实际应用中往往会出现少量“昂贵的”有标记数据与大量“廉价的”未标记数据共存的情况[3]。
近年来,特征向量维数高和标记样本稀缺问题引起广泛的关注。李军利等[4]提出SVDD-KFCM算法,该算法通过支持向量数据描述(SVDD)方法,利用已知的正常样本建立超球边界,再对未知样本进行判断。选择正常和潜在故障样本在输入空间的中心作为模糊核聚类(KFCM)的初始聚类中心,克服了无监督模糊核聚类算法初始聚类中心随机确定导致分类盲目性的不足。然而该算法是针对在故障样本缺失情况下,如何进行故障检测,不能做进一步的故障诊断;李磊等[5]提出半监督线性局部切空间排列算法(SS-LLTSA),利用部分标签信息来调整样本点与点之间的距离以形成新的距离矩阵,通过新的距离矩阵进行邻域构建,实现了数据本质流行结构和类别标签信息的结合,能够提取区分度更好的低维特征。但该算法在选择合适的目标维数d和邻域参数k时,需要通过多次实验才能确定;杨望灿等[6]提出基于改进半监督局部保持投影算法(ISS-LPP),自适应地调整邻域参数,充分利用带有标签的样本,重新构建原始特征空间中样本间的权值矩阵,从而得到有利于分类的低维特征向量和投影转换矩阵。该算法提高了低维特征向量的辨识度,且利用参数寻优为最小二乘支持向量机(LS-SVM)分类器设置了合适的参数,提高了轴承故障诊断正确率。但对原空间的降维,依然需要设置合适的目标维数和初始邻域参数,不同工况的数据集,设置的参数不同,这给实际应用带来不便。
鉴于Co-Forest算法是以随机树(Random Tree)作为基分类器的集成分类器,随机树是基于特征集中少数几个特征而构建的,这可以避免“维数灾难”问题的发生[7]。且随机森林有一个重要的优点是,没有必要对它进行交叉验证或者用一个独立的测试集来获得误差的一个无偏估计,它在内部进行评估,在生成的过程中就对误差建立一个无偏估计[8]。基于Co-Forest的轴承故障诊断算法,改善了维数灾难和标记样本稀缺问题,提高了故障诊断的正确率,不需要进行维数约简参数和分类器参数的寻优操作,给实际的应用带来便利。
2 半监督学习和基于分歧的算法
2.1 半监督学习
半监督学习是在数据集上寻找最优的分类器,目的是利用带标签数据和未标记数据学习设计分类模型,使得该模型比仅使用带标签数据分类性能更好[9]。
2.2 基于分歧的算法
按学习方式的不同,常见的半监督分类算法可大致分为四类:基于生成模型的算法、基于支持向量机、基于图的算法以及基于分歧的算法[10]。基于分歧的算法由于其受到模型假设影响少、学习方法简单、理论基础坚实等优点,被广泛地应用于文本分析、网络入侵检测、图像识别等领域。基于分歧的算法起始于1998年Blum等人提出的Co-Training算法[11],当满足充分视图和冗余视图的要求时,分类器在未标记数据上的一致性最大化,泛化误差较小[12]。此后,为解决视图不充分、置信度估计、分类准确率等问题,出现了一系列的改进算法。周志华等人先后提出的基于三个和多个基分类器进行协同训练的Tri-Training算法[13]和Co-Forest算法[14]最具有代表性,后来的研究人员将这两种算法应用到不同领域[15-17]。
周志华等(2005)提出了Tri-Training算法:在原始数据集上抽取出有差异的子集,通过训练得到有差异的分类器。Tri-Training采用了三个基分类器(hi,hj,hk,其中i≠j≠k),未标记样本的标记由简单投票法则确定。详细情况是:如果分类器hi和hj对未标记样本xi的标记是相同的,那么就把未标记样本xi及其标记结果y加入到分类器hk的标记训练样本集中。
Tri-training算法通过判断分类器的预测一致性来隐式地对不同未标记样本的标记置信度进行比较,这一做法使得该算法不需要频繁使用耗时的统计测试技术,但与显式地估计置信度的方法相比,这一隐式处理往往不够准确,特别是如果初始分类器较弱,未标记样本可能被错误标记,从而给第三个分类器的训练引入噪音[18]。周志华等对Tri-training进行了扩展,提出了可以更好发挥集成学习作用的Co-Forest算法。
3 Co-Forest算法
Co-Forest算法拥有多个基分类器,对于单个分类器hi( i ∈{1,2,…,N}),它的协同分类器集合是Hi(除hi之外的所有的基分类器)。Hi将高置信度的未标记样本加入到已标记训练样本中,以迭代更新的基分类器hi,从而提高分类器的整体性能[19]。核心步骤如下:
步骤1采用随机子空间和抽样方法,利用已标记数据集L抽取出多个子集L*={l1,l2,…,lN} ,初始化多个基分类器,由此构成初始分类器集合H*={h1,h2,…,hN}。
步骤2对于每一个基分类器hi,利用袋外数据(out of bag)估计Hi在第t轮训练后的分类误差ei,t。若ei,t<ei,t-1,Hi挑选出未标记样本集U中的高置信度样本集Li,t,并将其加入到hi的原训练集中,利用L⋃Li,t训练更新基分类器hi。
步骤3重复步骤2,直到所有基分类器都不再满足更新条件。
步骤2中协同分类器集合Hi对未知样本xi(xi∈U)的标记置信度wxi计算如下:
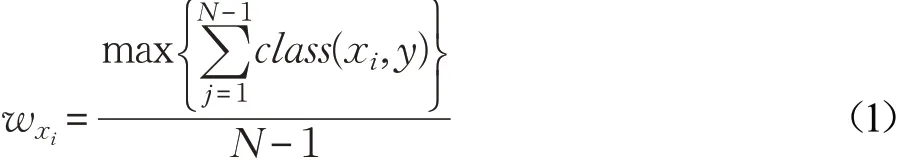
其中,y∈{1,2,…,M},M表示故障的类别数,N表示Co-Forest中树的数目,也是基分类器的个数。表示Hi中对样本xi的标记类别为y的分类器个数。标记后的未知样本xi是不是高置信度样本,判断如下:

置信度阈值θ(0~1)不宜设置太大,防止过拟合,一般设置为0.75。
高置信度的新标记样本的错误标记是不可避免的,周志华等在Co-Forest算法中加入了在噪声环境下确保分类错误率收敛的控制条件。考虑一个关于训练样本集容量m,分类器的预测错误率ε与数据噪声率η的关系式如下:

其中,c是固定常数。式(1)中wxi表示样本xi的置信度,为了降低使用大量无标记样本带来的负面影响,使用置信度对训练样本进行加权,则L中所有样本的权重之和:

其中,m0表示L中样本个数。同样Li,t的权重之和:

其中,mi,t表示在t轮迭代中Li,t的个数,wi,t,j表示在t轮迭代中未知样本xj的标记置信度。
第t轮,hi是在大小为m0的初始标记样本集L和大小为mi,t的新标记样本集Li,t上进行更新。令ei,t表示Hi在Li,t分类错误率,加权后的样本集Li,t中被错误分类的个数是ei,twi,t。令ηL表示L的噪音率,加权后的样本集L中噪音数据的个数是ηLw0。求第t轮训练样本集 |Li⋃Li,t|上的噪音率:

将式(7)代入式(4)得出:
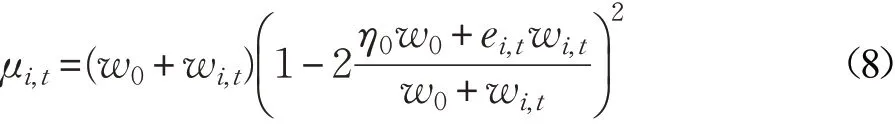
步骤2中不断地更新训练hi,要保证hi在第t轮的预测错误率小于上一轮的预测错误率,即εi,t<εi,t-1,由式(4)知在训练过程中就必须满足μi,t>μi,t-1,得到:

考虑到L的噪音率η0很小,当式(9)左边第一项大于右边第一项,即wi,t>wi,t-1,同时左边第二项大于右边第二项时,即ei,twi,t<ei,t-1wi,t-1时,公式(9)不等式关系必成立。进一步精炼得到的约束条件:

根据式(10)要确保ei,t<ei,t-1和wi,t>wi,t-1同时成立。对于wi,t≫wi,t-1,导致ei,twi,t>ei,t-1wi,t-1这一情况,需要抽取Li,t的子集L′i,t作为新标记样本集:

Hi对子集L′i,t中每一个数据遍历,保留高置信度的样本,同时更改新标记样本的置信度之和wi,t,使得:

4 基于Co-Forest的轴承故障诊断
4.1 SQI-MFS实验平台
如图1所示,SQI-MFS实验平台由电机、变频器、轴承、底座支撑架组成。其中轴承型号为MBER-16K,实验平台利用PCB公司生产的608A11型号加速度传感器和NI公司的数据采集卡NI9234采集轴承的振动信号。该平台可以模拟健康或各类故障轴承在不同转速和不同负载下的运行状态。

图1 SQI-MFS实验平台
如图2所示,从左至右、从上至下,分别为混合故障轴承、内圈故障轴承、外圈故障轴承以及滚珠故障轴承的实物图。

图2 四种故障状态的轴承实物图
4.2 SQI-MFS实验平台采集的数据
实验采集了不同转速,不同负载下的振动数据,分别为:3种负载(0、1、3个转子负载)×3种转速(10 Hz、20 Hz、30 Hz)×5种类型。这5种类型分别是:健康、滚珠故障、内圈故障、外圈故障轴承以及混合故障(故障轴承的故障点大小为19.05 mm)。其中转子负载数为3个,转速为30 Hz的混合故障数据缺失,但并不影响实验。将数据分别按负载(3种)和电机转速(3种)分成9组(采样频率为25.6 kHz)。
首先,利用窗口大小是2 048,步长是1 024的滑动窗口划过轴承数据,得到多段非平稳的时间序列;然后,再对每一段时间序列求得时域特征和频域特征。选择的时域和频域特征指标如表1所示。9组数据经过特征提取后,特征数、数据大小和数据类别如表2所示。
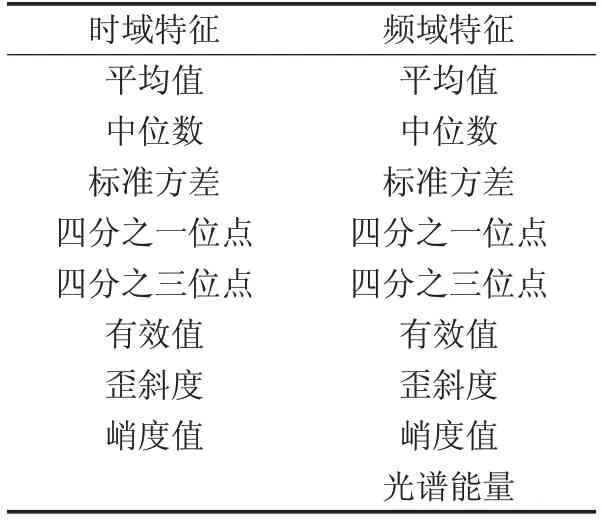
表1 特征表

表2 实验数据
4.3 实验
将每一组数据分为训练集train和测试集test,比例为1∶1,其中train分为已标记样本集L和未标记样本集U。
实验1上述9组数据中随机选择一组数据,观察Co-Forest算法诊断正确率、算法的运行时间与树的数量之间的关系,这里选择第4组数据做实验,结果如表3所示。

表3 正确率、运行时间与树的数量之间的关系
实验2从表3可以看出,随着树的数量增加,Co-Forest算法在轴承故障诊断中的正确率提高不明显,但是算法的运行时间显著地增加。将Co-Forest算法中树的数量设置为100棵,在已标记数据(L)占训练集(训练集∶测试集=1∶1)20%、50%、80%情况下,比较同类型的三种协同训练半监督学习算法的故障诊断正确率。
通过进行多次分类器选择尝试,其中为了让Co-Training算法具有较好的置信度估计依据,基分类器选择朴素贝叶斯分类器,后验概率作为置信度估算依据。Tri-Training的基分类器选择以信息增益率作为划分属性的决策树,实验结果如表4所示。
实验3进一步将Co-Forest算法与当前针对特征向量高维、标记样本稀缺问题的ISS-LPP算法[6]、SS-LLTSA算法[5]作比较,实验结果如表5所示。表中目标维数d值、邻域参数k值经过大范围寻优,然后缩小范围,最后多次实验确定,对应的是较理想的故障诊断精度。
实验4表4、表5显示的是已标记数据集在训练集的占比为20%、50%、80%的情况下,几种算法的诊断正确率对比情况。实验结果显示:Co-Forest算法具有较高的诊断正确率,参数配置简单。接下来模拟几种算法在连续占比为0.05~0.8下的正确率情况,随机选择第1、6这两组数据做实验,实验结果如图3、图4所示。
4.4 实验结论
综合以上4个实验,可得出以下结论:
由于Co-Forest算法的分类器是随机森林,随机森林的基分类器是串行的,故会随着树的数量增加,算法的运行时间增加。表1中正确率并没有因为树的数量增加而显著增加,不建议将树的数量设置很大。

表4 几种协同算法的诊断结果比较

图3 第1组数据的诊断正确率情况
表4在不同的L/(L+U)情况下,Co-Forest算法结合了协同训练和集成学习的思想,故障诊断正确率较高于Co-Training、Tri-Training算法。表5中的ISS-LPP、Co-forest都具有较好的诊断效果,但ISS-LPP算法使用最小二乘支持向量机(LS_SVM)分类器进行故障诊断,LS_SVM分类器的参数选择需要进行参数寻优操作,且该算法需要对特征空间进行降维,过程中的参数选择需要多次试验才能确定。
图3、图4显示随着标记样本的增多,Co-Forest、ISSLPP算法的诊断正确率提高,最后趋于稳定,但Co-Forest算法在第1组数据上诊断效果优于ISS-LPP算法,且Co-Forest算法在标记样本非常少的情况下,也有较好的诊断效果。
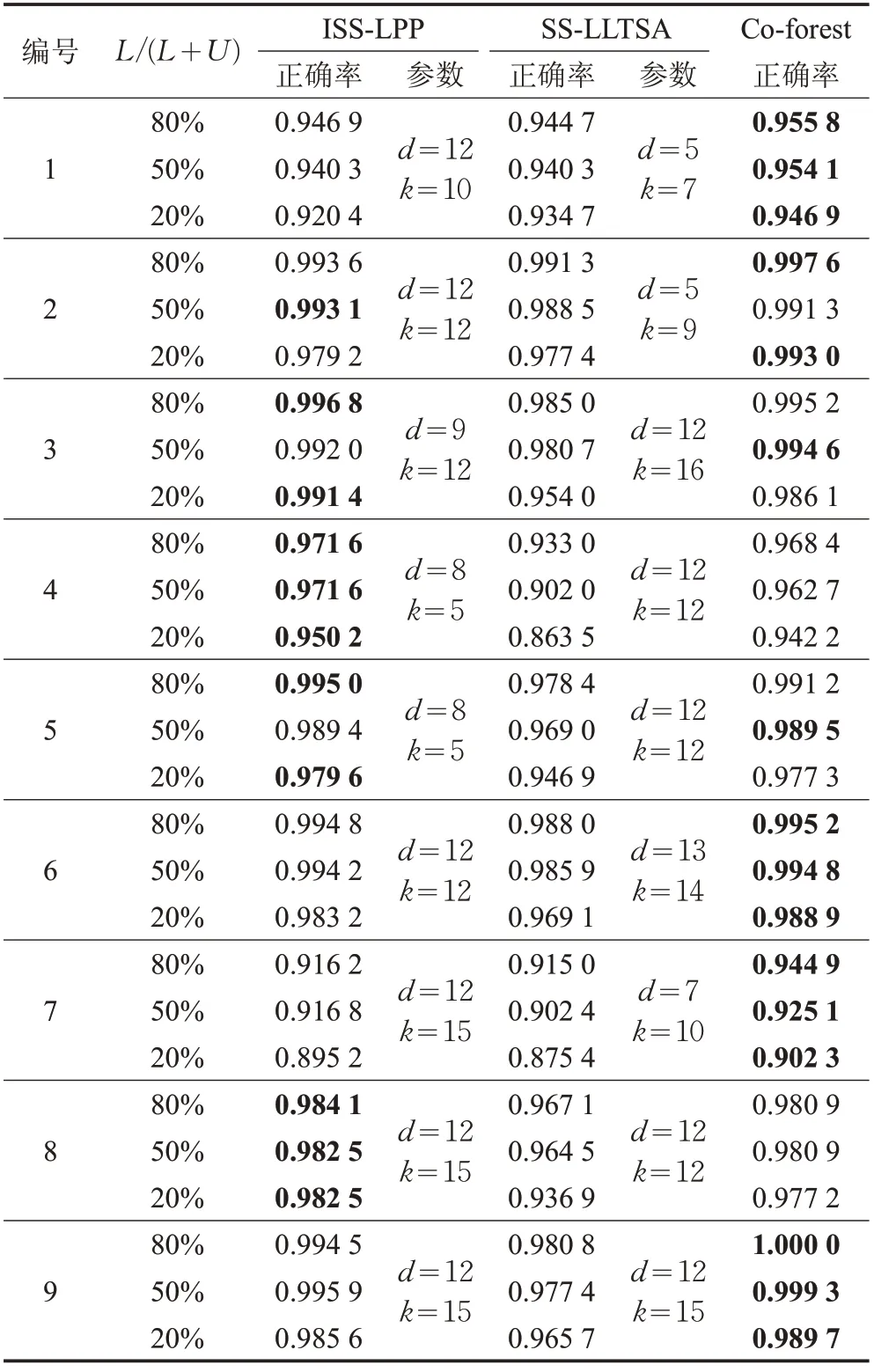
表5 Co-forest算法与ISS-LPP、SS-LLTSA算法对比

图4 第6组数据的诊断正确率情况
5 结束语
基于Co-Forest的轴承故障诊断算法利用SQI实验平台的轴承数据,进行多种算法的对比性实验。与同类型的算法Co-Training和Tri-Training相比:在已标记数据占训练集20%、50%、80%情况下,Co-Forest的诊断正确率有所提高;与用标记训练样本协助维数约简的半监督学习算法(SS-LLTSA、ISS-LPP)相比:Co-Forest算法具有较好诊断效果,参数配置简单,且不需要复杂的维数约简处理。在特征提取方面,这里提取了时域和频域中常见的、易得到的特征,Co-Forest算法直接对样本的特征空间进行分析和预测,实验显示Co-Forest算法具有很高的诊断正确率。因此,Co-Forest算法在滚动轴承故障诊断方面有着较好的实际推广意义。轴承状态的变化是渐变的过程,能敏感识别出轴承故障状态突变点是今后努力的方向。
致谢 感谢西门子中国研究院提供的帮助。
猜你喜欢
核科学与工程(2021年4期)2022-01-12 06:30:22
中华养生保健(2020年7期)2020-11-16 01:14:26
计算机应用(2018年5期)2018-07-25 07:41:26
电子测试(2018年1期)2018-04-18 11:52:35
家教世界·创新阅读(2016年11期)2016-12-27 18:49:15
天津护理(2016年3期)2016-12-01 05:40:01
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
故事会(2016年15期)2016-08-23 13:48:41
轴承(2015年2期)2015-07-25 03:51:04
