
网络注入式攻击检测方案的研究与改进*
2020-06-18 09:08:28廖荣涛代荡荡
计算机与数字工程 2020年4期
刘 芬 余 铮 廖荣涛 徐 焕 代荡荡
(国网湖北省电力有限公司信息通信公司 武汉 430077)
1 引言
目前在系统运维领域,针对代码级的信息系统监控技术得到了前所未有的重视,企业对于信息系统业务性能方面的监控需求也日益提高,维持信息系统的正常运转与保护企业数据安全已经成为了企业生存与发展的必要条件。要实现高水平的业务性能管理,首先需要对对网络中的各种异常信息与进行及时采集与分析,并通过高效的检测方法快速识别,给系统运维管理提供可靠的依据,因此,网络异常信息识别方法的优劣,直接决定了企业业务性能管理工作的质量。另一方面,随着网络站点和各种信息系统的推广使用,各种非法操作和网络攻击行为也层出不穷,虽然相关的数据安全与性能监控系统不断改进,但网络攻击的种类与规模仍然不断上升,给网络管理和系统运维工作造成了严重的干扰。在所有的网络攻击行为中,注入式攻击由于其自身的隐蔽性和易操作性,已经成为了使用频率最高的攻击方法之一[1]。该类攻击行为最大的特点就是从正常的WWW端口对站点发起访问,表面上与正常用户访问并使用站点功能的行为无异,从而能够欺骗大多数防火墙的监控,使其不会对此类操作发出报警,唯有当系统管理员主动查看Web日志时,才能够发现明显的异常痕迹,因此该类攻击往往会延续较长时间才被察觉,给企业的整体业务性能造成了严重的影响,同时也对企业的核心数据资源构成了严重的威胁,进而造成重大的经济损失[2]。
KNN算法在文本分类领域内得到了广泛的认可,显著提高了针对类型多样化的数据进行分类的准确性与可靠性,有不少研究者将该算法进行改进后,应用在网络异常与攻击检测领域,如张著英等人提出建立低维的特征向量空间以节约算法初期的计算规模,提高运算速度[3];胡元等人提出采用区域划分的方式提高样本群的搜索效率[4];Auld等人提出在算法执行前应对样本群进行规范化处理,以减少算法的计算量等[5]。但多数方法并不能很好地针对网络注入式攻击特征进行优化,在准确性和实时性方面均有欠缺。本文提出了针对KNN算法的初始化样本群,构造球型样本空间,形成样本子集聚类,削减初期样本群规模,增强算法计算性能的优化方法,并在结合Web日志提供的信息特征的基础上,将其应用在Web注入式攻击行为的检测工作中,取得了较好的结果。
2 KNN算法的原理及改进
2.1 传统KNN算法原理
KNN算法即K-最邻近分类算法,是一种基于类比学习的智能型检索分类算法,目前在模式分类识别领域内得到了广泛的认可,显著提高了针对类型多样化的数据进行分类的准确性与可靠性。该算法的基本流程是:1)首先构建用于对比分析的样本集合,随后将待检测的文本与该集合中的所有文本进行对比,确定与其相似度最高的k篇文本,将其定义为最邻近样本;2)检索选定的k篇所属类别,若同属一类,则将其定义为待测文本的类别;3)若k篇文本存在多种类别,则采取权重法对类别进行排序,而权重的选定则可根据检测需求灵活设置;4)判别分类排序居首位的文本权重是否超过了设定的阈值,只有当超过阈值时,该类别才可作为待测文本的类别[6~7]。其中待测样本d(x1,x2,…xn)与训练样本di(y1,y2,…yn)相似度采用式(1)进行计算:

而目标样本与某种分类cj的权重值则为
其中y(di,cj)为算法类别属性函数,用以判断di是否归属与cj,其结果分别为1和0。
算法最终的分类需采用分类函数来完成,如式(3):
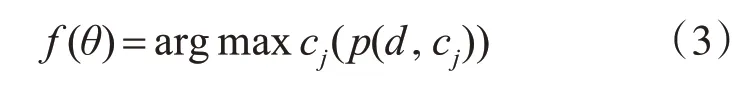
由此可以看出,KNN算法本身复杂度并不高,因此当训练样本群体规模有限时,该算法体现了良好的高效性和准确性。但随着样本群体的不断扩大,该算法在初期时采用的逐一类比方法极大地影响了计算速度,且存在较为严重的计算资源浪费情况,并不适合针对Web注入式攻击行为的检查需求[8]。
2.2 KNN算法的改进
KNN算法的特点决定了待检测样本的最近邻基本位于该样本在空间中的某一区域范围之内,其余分布较远的样本对于算法结果的影响可以忽略不计,按照这一思路,可对算法初期的样本群体进行科学的裁剪,仅保留对分类结果起到重要影响的区域内的样本,从而有效减少了算法的计算规模,提高了执行效率。因此,本次改进工作的关键内容就是设计最优化的裁剪方法,确保剩余样本群体的合理性。
首先,根据训练样本的类别,设置多种样本子集,从而在样本空间上形成多个聚类,其中任一聚类都呈现出以某个样本为中心,其余样本围绕该中心并聚集在其周围的分布状态,每个样本子集是一个聚类。对于一个聚类,它的所有样本都围绕着一个类中心分布,可以根据类中心和测试样本的位置参数,设置合理的裁剪区域半径及坐标。其具体的裁剪规则设计如下:
为每一个分类指定分类中心样本,如第j类样本中心描述为Oj={oj1,oj2,…ojn},则有:

其中Nj为该类样本群体规模,ymi是该群体中第m个样本的第i个属性值。根据多个中心点形成多个聚类,并利用式(1)计算训练样本到每个聚类中心的距离r,比较得出最短距离rmin;将测试样本点d(x1,x2,…xn)作为球心,rmin为半径构造球形的外接正方体区域;检索每个训练样本di(y1,y2,…yn),保留在此区域内的样本应当满足式(5):

若样本不能归属与任何一个聚类,则该样本被去除。如图1所示。

图1 基于球状区域的样本群体裁剪
图1 中A为待测样本,预先设定四个分类,其中心分别为O(X1)至O(X4),根据距离公式的计算,显然可知样本A与O(X3)的距离最近,以两点间距为rmin,构造球状区域和外接立方体,检索训练样本群中的每一个样本,满足式(5)的样本均被保留,从而构造了新的更小规模的样本群。在后续的算法执行过程中,只需对新群体中的样本进行检索和分析,找出其中最近邻中权重最大的类别,最终实现对样本A的分类工作。
3 基于改进KNN算法的检测模型
3.1 检测模型结构设计
将改进后的KNN算法应用于注入式网络攻击检测领域,将Web页面的访问请求定义为一份文本中的字,而针对某一页面的所有GET访问请求则被统一定义为一份文本,从而构建出原始待检测样本群,随后采用上节中所述的改进方法对该样本群进行裁剪,得到改进KNN算法的初始化样本群。
图1给出了检测模型的基本框架结构,可以看出检测工作的首个环节就是从IIS日志提取待检测Web页面的调用序列,分析其中的参数特征,并将该页面转化为调用文本的形式,该文本中存放了所有GET访问记录,从其中提取注入式攻击行为的特征信息,即可将其与构建的样本群中的文本进行对比分析,通过改进KNN算法得到最终的分类判断,即该页面中是否存在可被注入式攻击的漏洞特征,以及发生的访问记录中是否存在符合攻击行为特征的操作[9]。

图2 检测模型结构图
3.2 注入式攻击行为的特征提取
注入式攻击行为的对象一般均为内嵌JSP或ASP代码的动态网页,在该类型网页中存放了N个不同数据类型的参数,当此类网页对数据库发起访问申请时,就存在注入式攻击的可能性。为了对该类型攻击的特征进行提取和分析,就必须研究其攻击行为伴生的信息特点。从攻击方式来看,注入式攻击主要针对以GET方式提交参数的动态页面执行其侵入行为,遵循这一特征,可对GET操作的相关记录进行检索和分析,从而判别和掌握注入式攻击的具体信息[10]。众所周知,IIS的Web访问日志负责对所有的来访行为进行记录,而其中cs-uri-query字段记录了客户端使用GET方式提交的请求参数,因此,注入式攻击语句隐藏在参数中进行提交时,同样会被记录在访问日志中,通过分析cs-uri-query字段的信息特征,就能够大大提高对该类攻击行为的检测效率,同时也可对存在此类漏洞页面的站点进行有效的预警。根据文献[11]的统计,注入式攻击的常用函数及关键字如表1所示。

表1 注入式攻击特征信息提取表
3.3 页面调用文本的数字形式转化
为了采用改进KNN算法对页面信息进行分析,必须将其转化为由若干个特征信息组成的文本形式,本文采用成熟的向量空间模型(Vector Space Model,VSM)来完成这一工作,得到的空间形式为(t1,t2,…,tk),即为注入式攻击行为的信息特征,参照上文所述算法,采用权重法完成排序环节,因此需要计算这些信息特征在Web页面(d1,d2,…,dj)中调用文档的权重值。以某一Web页面为例,将其转变为以上形式后为wj(w1j,w2j,…,wkj,…w||Tj);式中的 ||T 表示特征向量的维数。而wkj即为权重值,其计算公式为
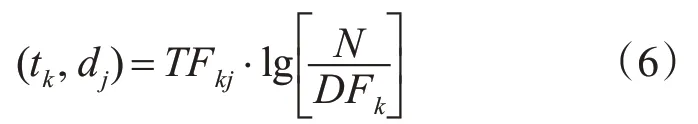
上式中的Fkj为tk出现的次数,DFk则表示样本集中与该特征信息相符合的所有样本的个数。考虑到文本长度可能存在较大差异,因此将上式做如下规范化转变,得到:

而当选定样本中出现多种分类时,其每种分类的权值计算方法如下式:

式(8)中的u为待测页面中的特征向量,dj则为样本群中选取的k个样本之一,y(dj,ci)表示dj在类别ci中的权重值,bi为测试算法预定的阈值,当选定样本类别的权重值超过该阈值时,方可表示该分类结果有效。
3.4 检测算法设计
Step1选定待检测Web页面,将其页面文档定义为待测样本A;
Step2从各种页面文档中调取所有注入式攻击行为所拥有的特征信息,并将其进行数字形式转化,形成原始训练样本群D(d1,d2,…dn);
Step3针对样本群D,采取前文提出的裁剪优化算法,合理削减其规模,得到初始样本群S(s1,s2,…sk);
Step4针对样本群S中的每一个样本,计算其与A的相似度sim(A,sj),若该值为1,则判别X存在攻击行为,输出检测结果,否则执行step5;
Step5根据sim(A,sj),按照相似度对样本集进行排序,并选取前k个Web页面调用文档,对这些样本分别计算其类别权重值;
Step6若权重值超过了预设的阈值,则判别此文档存在注入式攻击,否则判断此文档处于安全状态,转向下一个待测样本,从Step1开始往复执行,直至所有待测样本均检测完毕。
4 实验结果分析
对本文提出的检测算法进行仿真验证,实验分为纵向对比分析与横向对比分析两个环节,首先针对KNN算法的改进方案进行纵向对比验证,即将其与传统的KNN算法进行比较,论证改进后的KNN算法在分类性能上的提升效果。仿真模拟程序采用C#编程实现,运行环境为Windows Server 2012,将网页操作行为分为正常类与攻击类两种类型,每个类别按照平均分布原则随机选择750个样本点,即总样本群规模为1500,两种类别各自取500样本作为训练样本,250样本作为待测样本,分别对两种算法在计算耗时和分类准确率两个方面进行对比分析,结果如表2所示。
从表2中可以看出,在分类准确度方面,改进KNN算法略微领先于传统KNN算法,在K值达到100时,前者的准确度超过后者2.2%,但从该指标变化趋势分析,随着K值继续增大,两者之间的差异将进一步减少,并最终持平;而在计算耗时方面,改进KNN算法则体现出了显著的优势,耗时差平均达到了6.115ms,说明改进后的KNN算法在计算效率上有了明显的提升,改进效果得到了论证。

表2 纵向对比实验结果统计
随后执行横向对比分析实验,除本文设计算法之外,另选择目前常用的三种检测方法即马尔科夫检测法、K-means聚类法和贝叶斯网络检测法同时参与实验,检测对象假定为某中等规模的企业Web站点,模拟该站点共有65个含有参数的页面,预设其中的16个页面中存在注入式攻击漏洞。在仿真实验开始后,24h内共组织了注入式攻击4200次,其检测结果汇总信息如表3所示。
由表3可知,改进KNN算法相对于其他检测算法具有明显的优势,站点中的16个漏洞页面均全部检出,无漏检的情况,仅存在一处误检,准确率达到了93.75%,明显超过了其他检测方法;此外,由于注入式攻击页面的特征信息相对较少,因此不需要对特征向量进行降维处理,这进一步提高了改进KNN算法在该领域内的检测质量,使其具备了良好的实际应用价值。
5 结语
本文针对KNN算法在网络攻击行为检测领域的应用与改进展开研究,提出了构造球状区域样本空间以合理削减样本群规模,从而提高KNN算法的计算效率这一优化方案,并围绕Web站点注入式攻击行为的特点进行分析,通过提取该类攻击的特征信息,构建了攻击行为的检测模型,在此基础上设计和完善了相关的检测算法。在仿真实验阶段,通过与传统的KNN算法的纵向对比分析,以及与其余三种检测方法的横向对比分析,论证了本方案的有效性与可靠性。
猜你喜欢
中国典型病例大全(2022年9期)2022-04-19 23:42:54
宁夏师范学院学报(2021年7期)2021-09-27 12:35:04
散文百家·下旬刊(2018年12期)2018-12-26 12:33:26
光学精密工程(2016年4期)2016-11-07 09:05:25
水利规划与设计(2016年7期)2016-02-28 15:06:22
新校长(2016年8期)2016-01-10 06:43:59
电测与仪表(2015年11期)2015-04-09 11:46:20
文教资料(2014年1期)2014-11-07 06:54:50
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
