
基于模糊孤立森林算法的多维数据异常检测方法*
2020-06-18 09:08汪旭祥
计算机与数字工程 2020年4期
李 倩 韩 斌 汪旭祥
(江苏科技大学 镇江 212000)
1 引言
所谓异常,即为一种具有不同数据特征的数据模式,该模式有别于正常情况,基于这种异常情况的研究与分析就称之为异常检测技术[1~4]。近年来,国内外研究学者不断研究探索提出了许多异常检测的算法,主要包括基于统计的模型,基于距离的模型,基于线性变换的模型,基于非线性变换的模型等。丁洁等[5]提出了一种基于相关系数的异常行为检测方法,该方法借助于自相关系数,研究并实现了基于自相关模型的异常行为自动检测系统,拥有较强的扩展性。文献[6]结合基于成分分裂的增量学习方法,采用局部贝叶斯模型选择方法进行高斯混合模型训练。提出了一种基于高斯混合模型的异常检测算法(LVBGMMS),该算法针对EM算法以及贝叶斯模型选择方法的弊端进行改进。李海林等[7]提出一种基于频繁模式发现的异常检测方法,利用符号化的时间序列找出原有序列中的频繁模式,最后根据最长公共子序列匹配方法度量频繁模式与当前新增加时间序列数据之间的相似度,找出新增数据的异常模式,解决了传统异常片段检测方法在处理增量式时间序列时效率低下的问题。然而上述的这些方法大都基于正常模型,是针对正常数据的一种优化方法,因此,存在一定的误报情况,即将正常数据识别为异常数据或不能全部识别出异常数据。
孤立森林算法由文献[8]首次提出,该算法是由大量的树组成,这里称作iTree,最后的结果则是综合各个iTree的结果。然而iTree树又有别于决策树,就是一个完全随机的过程,因此构建的过程也较为简单。与所有现有方法基本不同,孤立森林算法[9]是纯粹基于孤立的概念检测异常,而不依赖于任何距离或密度度量,放弃了对正常数据建模的过程,通过构建的iTree树显示地找出异常数据,并通过限制树的深度来提高算法效率。由于在使用孤立森林算法[10~11]时大部分的训练样本是不需要被孤立的,并且能够在不隔离所有正常点的情况下使用部分模型,因此利用一个小样本容量的数据集就可以构建模型。然而对于待测的样本而言,在检测过程中需要遍历森林中的每一棵树,得到一个平均路径的长度,再进行异常分数值的计算,但由于每次都是随机选取属性进行建树的,而每个样本数据对于随机选取的属性的异常程度又是不同的,所以显然这种做法存在一些问题。
基于上述问题,本文在孤立森林算法中引入了隶属度函数的概念,利用模糊综合评价的方法对待测数据进行综合评判,提出了一种基于模糊孤立森林算法的多维数据异常检测方法。该方法通过挑选一些有价值的属性对其分别建树组成孤立森林,再对每一维属性的检测结果进行隶属度判断,并与模糊矩阵进行模糊运算得到最终评价结果,最后通过对实际校园一卡通的异常检测实验,验证了其有效性。
2 模糊孤立森林算法
2.1 孤立森林算法
利用孤立森林算法进行异常检测分为两个阶段[12]:第一个训练阶段,使用训练集的子样本构建隔离树;第二个测试阶段,通过隔离树传递测试实例,以获得每个测试样本的异常值。
1)训练阶段
在训练阶段,通过递归地划分给定的训练集,直到实例被孤立或达到一个特定的树高,从而得到部分模型。树的高度限制I是随机的,按次抽样大小设置大约是树的平均高度即I=ceiling(log2),然而我们只研究低于平均值的数据点,因为这些点更有可能是异常的。
假设从n个样本数据的数据集,从数据集中无放回抽样得到个数据样本X={x1,…,xn},并且服从M变量分布,构建一棵iTree时,在样本中选择一个特征值,在其最值区间选择一个属性q和一个分割p,递归地划分X,直到满足下列终止条件:
(1)树的高度达到限制值(从算法效率角度出发,iTree在算法里限制了高度为log2(n));
(2)|X|=1;
(3)样本X中所有的数据相同;
不断循环上述方法,随机选择的不同样本训练得到多个iTree树,训练阶段就完成了,即可对待测数据进行预测。
2)预测阶段
将测试数据x从根节点穿过iTree进行遍历,直到达到叶子节点,其中遍历过程中的路径长度记作h(x),即从根节点,经过中间节点,到达叶子节点的边数。由于iTrees与二叉树或BST有一个等价的结构,因此外部节点终止的平均高度h(x)的估计值与在BST中搜索失败的值相同,我们可以借鉴BST的分析方法来估计其平均路径长度。BST中不成功搜索的路径长度为

其中H(k)是谐波数可以被一个估计值表示,即H(k)=ln(k)+ξ,ξ为欧拉常数,为0.5772156649。
由于c(n)是给定n的路径长度的平均值,我们用它来规范h(x)。则我们定义测试数据的异常分数为

2.2 模糊孤立森林算法
模糊综合评价[13~14]是一种基于模糊数学的综合评价方法,具体来说,模糊综合评判就是利用模糊数学以及模糊关系合成原理,将一些难以量化表达、难以确定边界的因素以定量的形式表达出来,因此可以从多角度对待评价的事物进行隶属等级情况的综合评判。
在本文中用该方法对孤立森林算法进行了优化,即对孤立森林的异常检测分数值不进行异常判断,而是将孤立森林算法检测结果进行隶属度判断再利用算子与模糊矩阵进行模糊计算得到最终评价结果。模糊综合评价的具体步骤如下:
1)确定评价对象的因素集U,ui为评价因素,m为评价因素的个数:

2)确定评价因素的评语集合V,vi为各种可能的评价结果,n为评价结果的总个数:
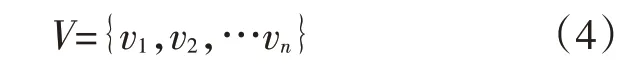
3)进行单因素评价。一般来说,为了研究评价对象与评语集合V的隶属关系,在构造了等级模糊子集后,需要对因素集里的每一个因素ui定量化,即从单因素的角度对各等级的模糊子集做隶属度判断。本文采用的是专家估计法,由专家根据评判等级对评价对象进行打分,最后统计打分结果,并组成模糊关系矩阵:

其中模糊向量rij(i=1,2,…,m,j=1,2,…n)表示某个待评价对象的因素集U中评价因素ui对评语集合V中,各种可能的评价结果vj的隶属程度。即利用rij来描述一个评价对象在某个因素ui的表现。
4)确定评价因素的模糊隶属度[16~17]。由于各因素在综合评价中的重要程度不同,需要对每一个因素ui进行一个隶属度的判断,并组成一个集合T记作ti(i=1,2,…,m)且ti≥0,∑ti=1,T就表示所有单因素的隶属度组成的一个模糊集合。本文将采用孤立森林算法的异常分数值,经归一化后得到的值S'作为模糊集合的值,即5)多因素模糊评价[17~18]。利用M( )·,⊕ 算子将模糊集合T与模糊关系矩阵R进行计算,得到各待评价对象的模糊综合评价结果向量B:


6)模糊综合评价结果分析。将等级看作一种相对位置,并用秩表示,通常为“1,2,3,…,m”,使其连续化。最后利用向量B中对应的分量与对应分量所对应的各等级的秩进行求和,从而得到待评价对象的相对位置:

其中,k为待定系数(k=1或2)目的是防止bj较大时对结果产生影响。
3 实验
3.1 实验数据
本文的实验数据采用的是实际校园一卡通的消费数据,该数据记录了2017年8月至12月校园一卡通的消费情况,共计1136653条。其中,包含了学生和教职工的学号/工号、一卡通号,以及在校使用一卡通卡消费时的时间、地点、每一次的消费金额、交易计数、收支功能、设备ID、设备流水以及期初余额和期末余额等信息。由于本次实验是针对学生展开的,所以在异常检测之前对原始数据进行了预处理,去掉了一些无关信息,例如教职工工号、设备流水等。同时,又利用统计学增加了一些学生在校的消费情况统计,最后提取出一些有价值的属性对其分别建树,具体的实验基本步骤如下:
1)第一步:创建iForest;
2)第二步:计算所有待测样本的异常分数值;
3)第三步:利用模糊孤立森林算法进行模糊综合评价;
4)第四步:实验验证。
孤立森林算法有两个输入参数分别为子采样大小Ψ和树的数目t。其中,子采样大小Ψ控制训练数据的大小,因为当Ψ无限增加时,会增加处理时间并且需要更大的内存,并不能获得较好的检测性能,因此当取样度较小时,孤立方法效果最好,本文采用Ψ=100作为实验值。树t的数量控制集成的大小,因为路径长度通常会在t=100之前收敛,所以本文使用t=100作为实验值。对于孤立森林算法中二叉树划分的阈值本文则选取的是每组数据的均方差。
3.2 数据异常影响因素指标
对一卡通数据异常进行模糊综合评判[19],主要考虑两个方面:判断数据是否存在异常的评价因素,即判断某一学生在校期间是否存在异常行为的评价因素和产生异常的程度。本文主要以经过孤立森林算法处理后的六个方面的学生消费行为为主要评价因素,建立在校学生产生异常行为的指标体系,异常程度也根据实际情况分为四大类。评价指标如图1。
由此可见,评价因素集U为U={单次消费金额,日消费总额,周消费方差,月消费方差,日正常教学活动期间消费频次,日早晨八点前消费频次},评价因素的评语集V为V={特别异常,异常,较为异常,正常},分配给各等级的秩为{4,3,2,1}。通过对办公室老师以及任课老师的调查问卷的统计和归一化后,我们得到的模糊矩阵为


图1 在校学生产生异常行为指标
3.3 实验验证
通过实验,我们得到了实际校园一卡通数据的模糊综合评价的结果,并对结果进行了降序排序,根据结果分布情况按照比例分配,将前10%判断为特别异常,35%为异常,45%为较为异常,10%为正常,如图2所示。为了验证本文所提出的模糊孤立森林异常检测算法的准确性,随机抽取了一百位学生进行回访调查,根据了解有的学生因为身体的原因需要在校看病买药所以导致了单次消费过高,有的学生确实存在逃课的行为,有的学生不爱吃早饭因此每天早晨八点前消费次数较少,有的学生已经申请了走读所以在校的消费行为较少。由此根据调查结果的统计情况,计算出本文所提的算法准确率为90%,达到了不错的检测效果。

图2 模糊孤立森林算法异常检测结果图
4 结语
针对原有的孤立森林算法采用的是随机选取属性的方法进行建树,最后综合各个树的结果进行异常判断,而忽略了每一条数据对于所选取的属性异常程度是不同的这一问题。本文提出了一种基于模糊孤立森林的异常检测方法,在原有的基础上引入了模糊的概念。利用隶属度函数,从多维度出发,将数据相对于属性的隶属度考虑进去,对孤立森林的结果进行了隶属度的判断,最后与由评价对象和评语集的隶属度关系组成的模糊矩阵进行模糊计算,得到一个综合评价的结果。该方法从多角度对待测样本进行了一个模糊综合评判,使得检测的标准更加的全面、更加的合理化,检测的结果更加准确,因此达到了较好的实验效果。
猜你喜欢
中老年保健(2022年5期)2022-08-24
小学生学习指导(低年级)(2021年12期)2021-12-31
阅读与作文(英语初中版)(2019年8期)2019-08-27
魅力中国(2017年16期)2017-07-31
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
作文大王·笑话大王(2017年1期)2017-02-21
作文大王·笑话大王(2016年10期)2016-10-18
作文大王·笑话大王(2016年7期)2016-08-08
作文大王·笑话大王(2016年2期)2016-02-24
