
依赖蝙蝠算法SVM的云计算资源负载预测
2020-06-17 02:44李旭晴
安阳师范学院学报 2020年2期
李旭晴
(长治学院 沁县师范分院,山西 长治 046400)
随着云计算技术的发展,传统的信息产业变革使得云计算的规模越来越大,同时,云数据中心的规模迅速增加,每个云计算中心的能耗也在不断增加,能耗变得越来越巨大[1-3]。云计算中的负载预测技术是降低云计算中心能耗的方法之一。当负载恒定时,如果可以准确地预测下一阶段的负载情况,则可以适当地分配资源。同时,可以在满足服务水平协议(SLA)时关闭某些计算机,以减少云中心能耗[4-5]。但是,与网格计算和高性能计算相比,云计算的任务多变。有学者比较了云计算和网格计算的负载曲线,发现云任务长度仅为网格任务长度的[1/20,1/2]。因此,云计算的负载曲线更加陡峭,增加了建模和预测云计算负载的难度[6]。
已有学者对云计算中心中的负载预测问题进行了大量研究[7]。预测方法主要分为三类,第一类为传统统计,如自回归算法、自回归综合移动平均算法(ARIMA)等;第二类为智能算法、神经网络(NN)、SVM算法等;第三类是混合算法,例如,将Kalman滤波器与SVM结合的算法,以及将相空间重构与进化相结合的算法[8-10]。就单一预测算法而言,有许多相对成熟的预测算法。同时也可以使用贝叶斯模型对云计算中心的CPU和内存进行负载预测,但是这只能预测未来一段时间内的平均负荷,而不是实际负荷值。还有学者提出了一种使用资源重定向机制的新的容量分配算法,但是该模型针对的是特定的资源使用方案,并且不具有通用性[11]。近年来,已经研究使用了混合预测算法,如针对主机负载急剧变化和云中的大量噪声,可以将相空间重构方法和分组数据处理方法结合在一起。所提出的方法可以减少累积误差,但是当考虑SLA时,进化算法的效率较低。有学者提出了一种基于卡尔曼滤波器的支持向量机模型,用于在云中进行负载预测,但是权重系数的选择只是从小到大的简单增加,难以反映云中的负荷特性[12]。近年来,也出现了一些新的混合方法,如模糊理论和蝙蝠算法变换等已被用于负荷预测[13]。综上所述,现有方法仍然存在以下缺点,单一预测算法在某些情况下可以预测云计算的负荷,但是其预测精度不高,也无法增加预测长度;混合预测算法在预测精度和长度上都有一定的提高,但是将其预测结果应用于资源分配还存在一定差距,另一方面,混合算法的操作相对较长;近年来,诸如WT等的新型混合算法显示出了很好的预测效果,但主要用于风电功率预测,在云计算负荷预测领域的应用很少[14-15]。
将蝙蝠算法(BA)与支持向量机(SVM)相结合,提出了一种蝙蝠算法支持向量机(BASVM)模型。该模型结合了WT分析输入信号的周期和频率的优势以及SVM的非线性回归分析特性,使输入信号的回归分析更加有效。然后提出了一种基于BASVM的云计算负荷预测算法。最后,使用Google数据集进行了实验,证明了与SVM、自回归综合移动平均(ARIMA)和自适应神经模糊推理系统(ANFIS)算法相比,该算法的预测结果和准确性得到了显着提高。
1 BASVM负载预测模型
本文提出的BASVM模型由WT和SVM组成。该模型利用WT的时间序列分解特征,用蝙蝠算法函数代替SVM的核函数,以提高负荷序列的回归分析精度。同时,云平台中的负载变化是非线性、不稳定和随机的。因此,根据云中的负载变化特征,使用BASVM预测负载更为有效。
1.1 云计算负载
在云计算环境中,可以收集的资源序列主要包括CPU利用率cpu,内存利用率radio mem,网络负载利用率radio bw等。由于用户在云中提交具有随机性和多样性的任务,因此服务器的加载时间序列始终具有非线性、不稳定和随机的特征。但是云中服务器的负载时间序列具有一定的规律性。因此,可以通过历史负荷数据预测当前负荷。
定义1三维向量L=(cpu,men,bw)表示云计算中心的负载,包括CPU利用率,内存利用率和网络带宽利用率三种负载类型。
定义2设向量Ht=[Lt-D,Lt-D+1,…,Lt-1]T表示历史加载序列,其中t表示当前时间,D表示嵌入维数,并由数据样本的自相关系数确定。
在本文提出的算法中,将历史载荷序列用作输入向量,并使用BASVM模型通过回归方法进行分析。
1.2 蝙蝠算法支持向量机模型
通过对云计算平台中负载的深入分析,可以知道负载时间序列具有非线性、不稳定和随机的特征。通用的研究方法很难描述和分析载荷时间序列。支持向量回归的基本思想是设置一个核函数,该函数可以将输入数据映射到高维特征空间,在此基础上,进行空间线性回归分析。将非线性问题转换为线性问题可以降低算法的复杂度。同时,SVM具有良好的泛化能力和出色的性能,在分析云计算负载序列方面具有独特的优势。通过构造母蝙蝠算法函数,WT可以保留原始序列的时间和频率特性,同时将时间序列分解为一组基本序列。它能进行深入的挖掘,特别是时间序列中的变化,此外,对于多尺度的时间序列变化区域,支持向量回归也能预测其发展趋势。WT可以在时域和频域中同时定位输入信号,时变信号具有独特的优势。因此,将WT与SVM结合可以充分发挥两者的优势,并且可以更有效地对云负载的历史序列进行回归分析。
给定样本集(x1,y1),…(xi,yi)…(xN,yN),其中xi∈x⊂Rn是样本集的输入,yi是分类的标记(yi={-1,1})。在此基础上,引入函数ε(不敏感损失函数),转化问题为极小值,约束条件如公式(1)所示:
s.t.yi-wΦ(xi)-b≤ε+ξi
(1)
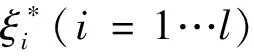

(2)
因此,支持向量机的回归决策函数如公式(3)所示。
(3)
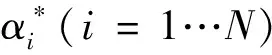
蝙蝠算法基函数(WBF)是WT中的重要函数,它由蝙蝠算法序列组成,并且可以按翻译的规模和时标构成一堆函数。不同的WBF对输入处理的重视程度不同,结果也不同,有时相差很大。
(4)
在公式(4)中,γ是高斯函数的参数,k是控制WBF形状的参数。通过引入变量k,蝙蝠算法核函数的形状将不会固定为一种形状。当k=0时,WBFψ(x)成为径向基函数核函数,当k=1.5时,WBFψ(x)在区间[-1,1]上近似于Mexhat核函数。令α∈R表示WT中的翻译因子,就可以得到满足公式(5)所示的核函数平移不变性的平移不变核函数。
(5)
参数k可以提高支持向量机的泛化能力,对具有不同特征的样本点进行回归分析可以获得更好的结果。因为WT和SVM都具有关键的内核功能,所以通过将它们结合起来,回归分析可以对输入序列更有效。然后,通过将(5)代入(3),可得到SVM的决策函数,如公式(6)所示:
(6)
1.3 基于BASVM的云计算负载预测模型
在分析了云计算负载序列之后,提出了基于BASVM的云计算负载预测模型。输入空间为Ht,当前云计算负载为Lt=(cupt,memt,bwt),这是通过对历史负载序列Ht进行分析和计算得出的。公式(7)是云计算负载预测模型的决策函数。
(7)
式中,Ht,i表示Ht的jth元素,而Hi,j表示ith训练样本Hi的jth元素。该模型利用(2)获得所需参数,并使用公式(7)计算时间t处的云计算负载值。
1.4 云中的BASVM负载预测算法
蝙蝠算法支持向量机负荷预测(BASVMLF)算法的主要思想如下。首先,设置BASVM模型的参数组(k,γ,C,ε),确定BASVM模型。然后将训练样本用于训练BASVM模型,并通过公式(2)和输入训练样本获得BASVM模型中的一些关键参数。最后,通过公式(7)获得云计算负荷值。
考虑到云计算负载训练样本的序列长度为l,将其分割为间隔s,并且N=l/s代表样本的总段数。令负载序列的每个段对应一个力矩,则力矩t对应于tth负载序列。通过对N个片段样本进行自相关分析,可以在设置阈值rT之后获得嵌入维D。
BASVMLF算法的步骤如下:
步骤1.设置参数组(k,γ,C,ε);
步骤2.处理云计算负载训练数据;
步骤3.使用训练数据训练BASVM模型;
步骤4.通过公式(7)计算力矩t;
步骤5.使用BASVM模型进行预测,并获得预测误差。
BASVMLF算法的伪代码如图1所示。

图1 BASVMLF算法的伪代码
2 实验与分析
为了验证BASVMLF算法的有效性和准确性,本文搜集了云计算中心的近一个月12000台计算机使用情况信息,利用BASVMLF算法进行性能综合,且与其他常用算法进行性能的比较。实验数据包含67万个作业和2500万个任务,及其相关的任务计划时间、资源的分配和相关的调配使用记录。此外,这些数据还记录了微秒级的配置、结束等的工作和任务及其他信息,例如CPU的需求和使用状态、内存、带宽等。
因此,围绕该数据集进行了许多相关研究。云计算数据集包括作业事件、任务事件、约束和使用情况、机器事件等6个部分。在本实验中,仅选择了对CPU资源进行测试,但BASVMLF算法也可以对内存和其他资源进行预测。在实验中,预测方法的前提是使用固定步长。
首先,对相关云计算序列进行自相关分析,分析的结果如图2所示。
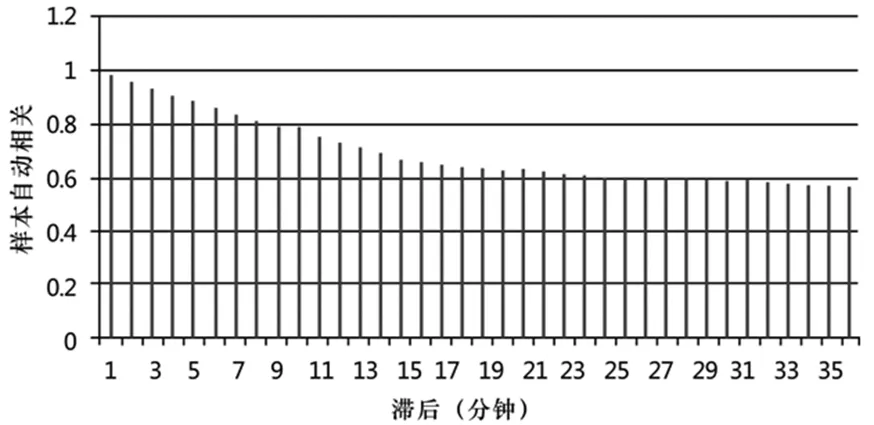
图2 云计算负载的自相关分析
其次,在基于自相关分析结果的基础上,可以得出该序列呈现较高的线性相关,设置阈值为rT=0.6,输入向量的步长为35。在此设置的前提下,对数据进行归一化的统一,同时将负载数据集作为输入样本,利用BASVM模型来预测负载。
通过以下步骤设置参数组(k,γ,C,ε)。首先,选择k=0并修复γ和C以找到最佳ε;其次,修复C和ε以找到最佳γ;然后修复ε和γ以找到最佳C;最后,将γ,C和ε固定为穷举搜索k。
在众多负载预测算法中,选择已有三种算法(ANFIS、ARIMA、BASVM)与本文提出的算法进行比较。选择这三种算法是由于本文提出的算法是在SVM的基础上进行改进的,而ANFIS和ARIMA分别代表智能算法和传统统计方法,支持向量机的参数与本文提出的模型相同。对于ANFIS,迭代数设置为500,隶属函数数为5。首先,通过减法聚类方法确定自适应模糊神经网络的结构;其次,使用混合学习算法训练前端和结论的参数;最后,将载荷序列数据输入到训练后的自适应模糊神经网络。对于ARIMA,从自相关分析中可以知道负载序列不稳定,因此应对负载序列进行差分,并设置时间序列d=1的差分时间。根据图2,可以得到带有回归项p=3和移动平均值q=2的ARIMA(3,1,2)模型。
预测算法的实验结果如图3所示。
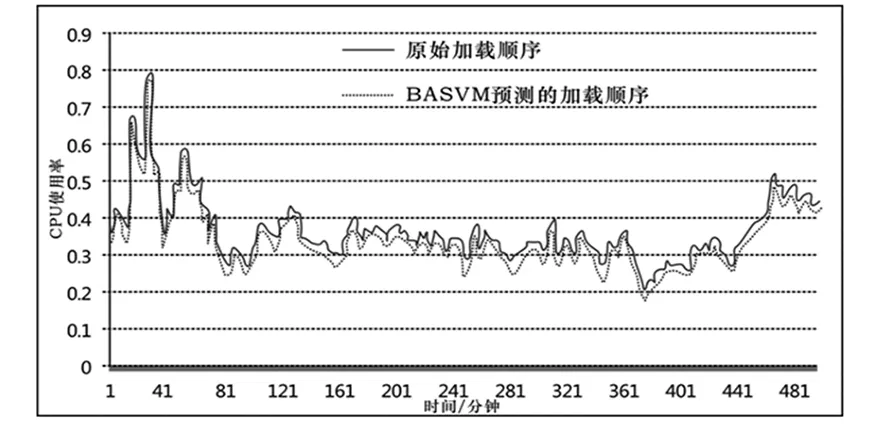
图3 (a)BASVM预测的加载顺序

图3 (b)支持向量机预测的加载顺序
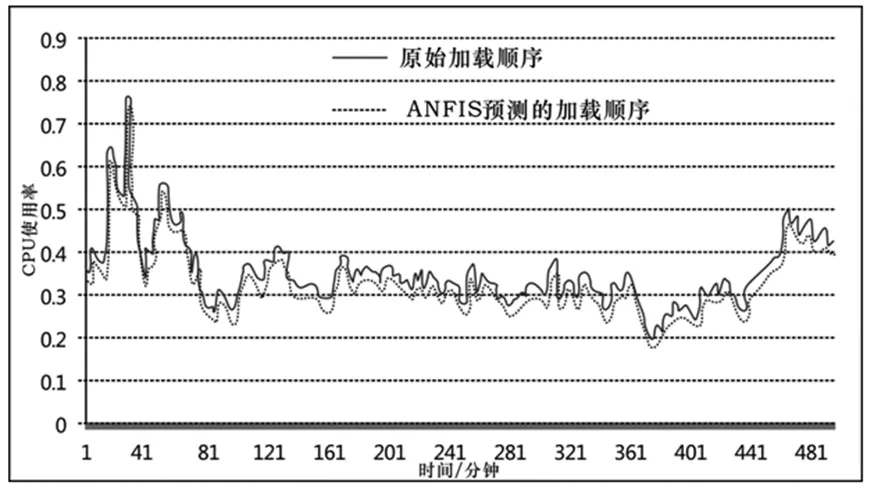
图3 (c)ANFIS预测的加载顺序
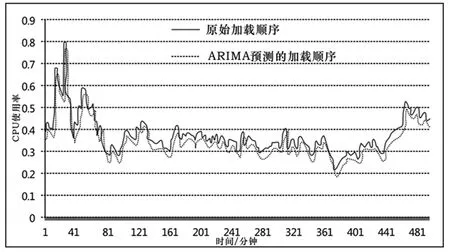
图3 (d)ARIMA预测的加载顺序
从图3 a-d中,很难看出明显的优化。因此,选择均方根误差(RMSE)和均方根误差(MAE)来评估四种预测算法。两种评估指标的计算如式(8)所示。
(8)
根据评估指标,将四种预测算法的误差与图4和表1中的相应数据进行比较。
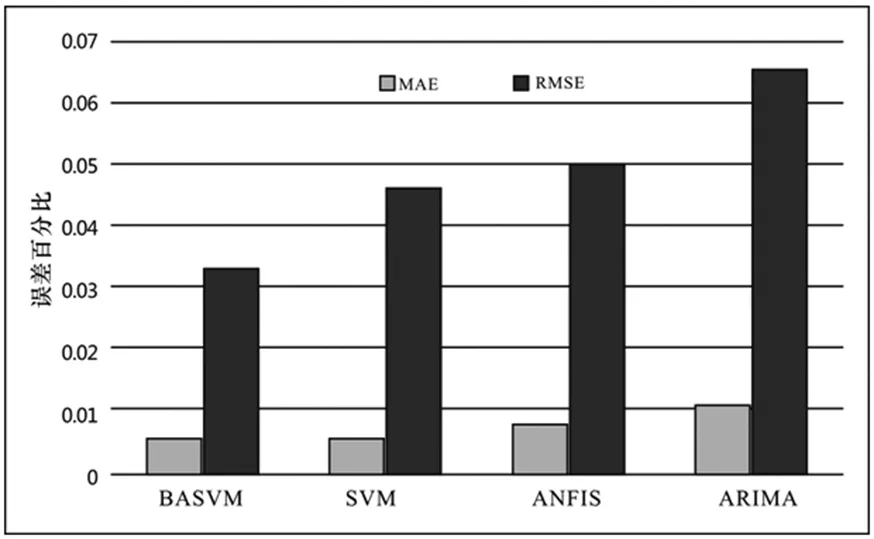
图4 不同算法的评估值

表1 不同算法的评估值
从图4和表1结果可知,BASVM的预测精度最优,提高了云计算预测算法的精度。
3 结论
本文在深入研究云计算任务特征的基础上,提出了一种基于BASVM的云计算负荷预测模型,该模型可以结合WT和SVM的优势,对输入序列进行更有效的回归分析。为了验证本文提出的算法,选择了云计算中心数据集,并分析了其CPU负载统计信息。通过使用本文提出的预测模型,可以预测负荷序列并将其与其他几种常用的预测算法进行比较。实验结果表明,所提出的BASVM云计算负荷预测模型在预测精度上优于其他三种预测算法。
猜你喜欢
现代经济信息(2022年27期)2022-11-24
新高考·高一数学(2022年3期)2022-04-28
科技创新导报(2021年31期)2021-05-10
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中国计算机报(2020年42期)2020-12-03
小溪流(画刊)(2016年12期)2017-02-04
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
微型小说选刊(2015年5期)2015-06-05
现代企业(2015年4期)2015-02-28
