
一种融合单目信息的RGB-D SLAM优化方法
2020-06-16 02:43马树军王英蕾金铁铮白昕晖
东北大学学报(自然科学版) 2020年6期
马树军, 王英蕾, 金铁铮, 白昕晖
(东北大学 机械工程与自动化学院, 辽宁 沈阳 110819)
RGB-D相机可以同时采集彩色图像和深度图像,可以提供丰富的场景信息并且减小在SLAM系统中的计算难度,基于RGB-D相机的SALM系统一直是视觉SLAM领域的热门研究问题[1].但当相机运动速度过快、场景没有足够的结构或者存在干扰光源时,会有深度信息不存在和不可靠的情况;而且RGB-D相机的有效工作范围为0.6~4 m,当其不在有效范围内工作时深度会变得离散和稀疏,整体深度的不确定性成指数增长[2].不精确的深度估计会引起较大的线性化误差,影响估计精度,甚至发散[3].所以一直依赖深度信息工作的SLAM系统必然会受到存在误差的深度信息的影响.
为解决RGB-D SLAM存在的问题,有学者提出融合其他传感器的方法.RGB-D相机和激光雷达融合[4],激光雷达可以提供精度更高、范围更大的数据支持.但是激光雷达价格昂贵并且几何尺寸和重量都比较大,因此在小型的室内移动机器人上并不适用.RGB-D相机和IMU惯导模块融合[3,5],利用IMU传感器提供加速度和角速度测量,在深度信息丢失或没有特征信息的情况下,仍然可以对位姿进行估计,使系统具有很好的鲁棒性并且不需时刻保持低速以防RGB-D相机跟丢.但IMU存在漂移误差,而且增加了对系统计算能力的要求.RGB-D和单目进行融合[6],当图像传入系统,该方法依次对单独的彩色图像和彩色与深度组合的图像分别进行计算,然后从二者中选择最优的方式.这种融合方法使系统在深度缺乏的情况下具有更好的精确性.但系统对每帧都分别进行两种方式的处理会过多占用系统的计算资源.
通过研究,本文基于ORB SLAM系统[7-8]提出一种RGB-D和单目信息融合的优化方法,该方法可以通过判断深度图像的信息,有选择性地进入RGB-D SLAM或者Mono SLAM.
1 系统框架
本文提出的融合单目信息的RGB-D SLAM优化方案如图1所示,系统通过RGB-D相机采集场景信息进行SLAM工作.其中利用RGB图像进行特征提取与匹配,并进行初始位姿估计.对深度图,本文提出一个基于深度的判断机制,从深度信息的存在性、准确性和离散性三个方面来判断深度图像是否具有足够的信息来进行位姿优化.若满足,则将深度图像输入,则系统是采用包含深度信息的三维信息对当前帧的初始位姿进行优化,此为典型的RGB-D SLAM 方式;若没有足够的深度信息,则该帧的深度图像不输入系统,系统采用二维信息对当前帧的初始位姿进行优化,此为Mono SLAM方式.系统还包含回环检测和全局优化,最后将优化的位姿作为输出.

图1 优化算法流程图
2 系统详述
2.1 特征提取
系统在前端使用的是ORB(oriented FAST and rotated BRIEF)特征提取算法.ORB算法包含改进的FAST(features from accelerated segment test)特征检测算法和BRIEF(binary robust independent elementary features)特征描述算法[9].
FAST算法检测图像像素点的灰度值,并与周围点灰度值进行对比,若两者存在较大差异,则认为该像素点是特征点,可用式(1)来描述该过程.在ORB特征算法中针对FAST角点不具备方向性和尺度的弱点,添加对了尺度和旋转的描述.
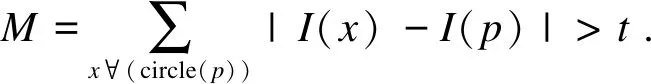
(1)
式中:I(p)为圆心的灰度值;I(x)为圆周的灰度值;t为对比阈值.
BRIEF是一种二进制编码的描述算子,用于对已检测到的特征点进行描述.其工作原理就是在关键点B周围随机选取两个像素点a,b作为一对,通过式(2)对比两个像素点的灰度值得到一组k位的二进制字符串.其中k为随机选取的点对数,在本文中k=256.图像经过BRIEF算法处理之后,图像中的每个特征点都对应一个256位的二进制字符串用于特征点之间的匹配.

(2)
2.2 位姿估计
在位姿估计中,若系统处于正常状态,有两种位姿估计的方式:若上一帧跟踪成功并且相邻两帧有足够的匹配点对,则通过上一帧的位姿和变化的速度来估计当前帧的位姿;若上一帧跟踪失败或者相邻两帧没有足够的匹配点对,则系统需要通过关键帧来估计位姿.若处于丢失状态,则系统需要通过重定位的方式来估计当前帧的位姿.重定位的方式是从包含关键帧的库中找到与之最相似的关键帧,并进行匹配.通过EPNP(efficient perspective-n-point)算法计算当前相机坐标系下的匹配点坐标,再利用 ICP(iterative closest point)算法进一步求解当前帧的位姿.
2.3 深度判断机制
为了评估相机在各方面的适用性,本文进行了一系列测试来描述不同情况下深度数据的质量.
实验一:通过控制搭载Kinect的移动小车在实验室和楼道各采集200张图片,对每张图片进行是否检测到深度数据的测试(d>0).同时,该实验也对TUM[10]数据集内的多个数据集进行了测试.实验结果见图2,该图表示的是深度信息低于70%的图像占数据集总数的百分比.
前6个数据均来自与TUM数据集,后2个分别是采集楼道和实验室的图像集.统计结果说明,不管是数据集还是实际应用中,都会遇到深度信息采集不完全的情况,而这样的场景信息必然会影响SLAM的鲁棒性.
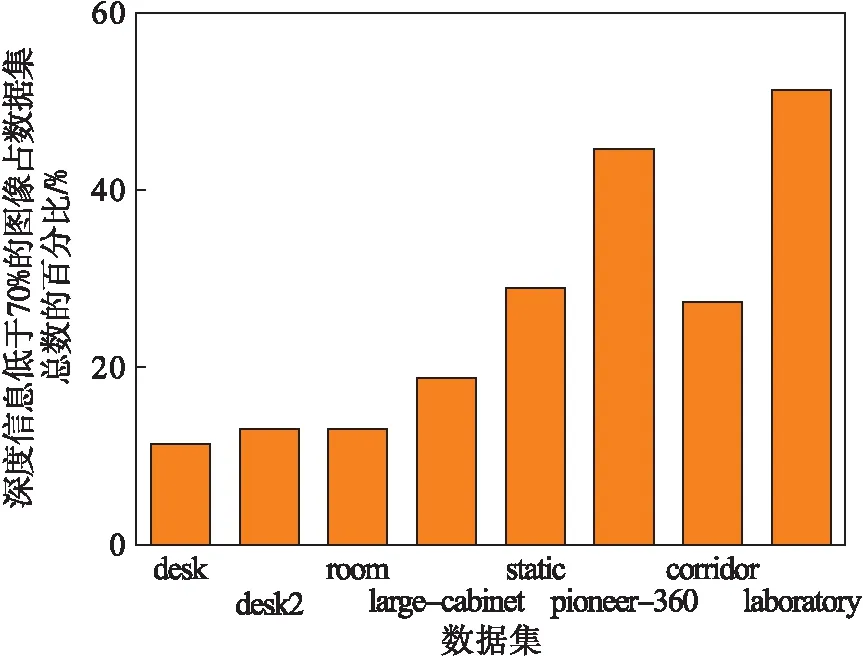
图2 深度信息分析
实验二:对Kinect距离准确性进行测试.使Kinect面向普通墙壁,与墙壁的距离由50 cm增加至440 cm,每次的增量为30 cm,在每一个节点中采集50张图像,为排除地板和图像边角误差的干扰,划定一个160×240的网格区域来进行测度检测,如图3中蓝色图框所示.

图3 实验样本图
图4展示了本次实验的结果,分别计算了每一组图像距离排序的前50%和前80%像素点所对应的距离与真实距离的误差百分比.从结果可以看出,测量距离为0.8~3.8 m时结果比较理想,当距离过近或过远时,整个结果会出现较大误差.

图4 前50%和80%数据与真实距离的误差百分比
实验三:提出猜想,即使有足够的深度信息,但是深度特征过度分散,也会影响SLAM的精度.针对以上,本文对TUM数据集进行了实验.如图5所示,在TUM两个数据集内分别提取两组数据,一组为与质心的像素距离大于215和一组与质心像素距离小于195,对这两组数据进行实验.实验结果表明,在其他条件相似的情况下,距离过大会导致误差增大.

图5 距离质心不同像素距离数据运行结果对比
针对以上实验,本文从三个方面提出三个模型作为深度选择机制:
情况一:深度信息不存在.
d>0 .
(3)
情况二:深度信息不可信.
γ1≤dreal≤γ2.
(4)
情况三:深度信息过度分散.
(5)
(6)
其中:d为像素点的深度值;dreal为像素点的真实距离.P为深度图像的质心,由式(6)计算得到.模型(3)和(4)是对单一的像素点进行判断,最后还要满足式(7),对整张图片所有像素点的判断.
nc/n<γd.
(7)
nc为满足式(3)和(4)的像素点的数量;n为整张图像像素点的总和,本文中涉及到的n=480×640.阈值的选取通过实验得到:γ1和γ2分别为0.8 m和3.8 m,α取215,γd在保证系统处理速度的情况下取数据集总量的15%.
2.4 位姿优化

(8)

(9)
(10)
(11)
式中:b为结构光相机和红外摄像机之间的基线;fx,fy,cx,cy为相机的内部参数.
2.5 全局优化
系统利用关键帧之间建立的约束完成回环检测的工作.为了更好地闭合回环,最后通过全局BA优化来实现误差的消除.
3 实验研究
所有实验均在Ubuntu 14.04环境下完成.实验数据来自于TUM RGB-D 数据集[10].
本文用优化的系统运行TUM数据集,来验证整个系统的优劣.本文以teddy数据集展示运行结果.图6中展示了数据集运行的对比结果.通过实验结果可以看出,本系统运行得到的轨迹结果与真实的轨迹十分贴合.通过运行EVO算法评估真实轨迹和估计轨迹,可以得到不同时间轨迹的绝对误差、均方误差、中位数和中值等参数指标以及不同坐标轴的轨迹误差.图7展示了评估结果.

图6 估计轨迹和真实轨迹对比图
本文还通过EVO工具对本文系统和ORB-SLAM运行相同数据集时得到的运行结果进行了对比.如图8所示,从运行结果可以看出,本文优化的系统相比ORB-SLAM系统的精度更高一些.

图7 teddy数据集分析结果
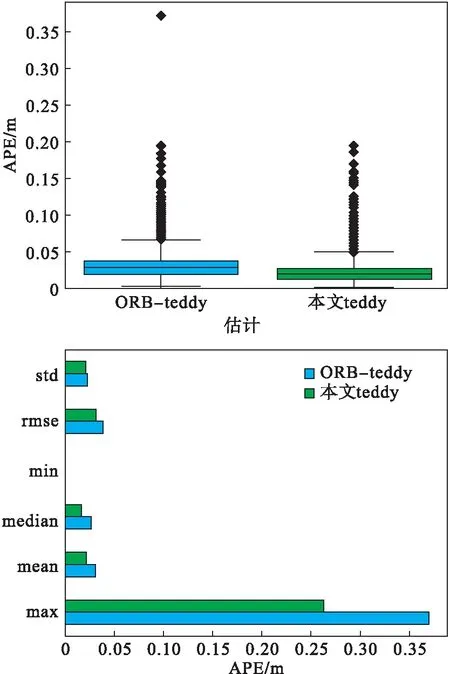
图8 teddy数据集对比结果
TUM数据集共包含6个分类39个图像序列,本文将优化的系统与ORB SLAM[7]分别进行对比.由于篇幅有限,只选取其中具有代表性的数据进行展示.图9为两种算法运行数据集得到的均方误差的对比结果;图10为两种算法运行数据集所需时间的对比.其中共有15组序列,1~6对应的序列分别为rgbd_dateset_freiburg1模式的desk,floor,room,rpy,xyz和teddy;7~9对应rgbd_dateset_freiburg2模式的xyz,pioneer_360和pioneer_slam2序列;10~15对应的序列是rgbd_dateset_freiburg3模式下的structure_texture_near,nostructure_texture_far,sitting_static,sitting_xyz,walking_xyz和teddy.从图中可以看出,在多数情况下,本文改进的优化系统具有更好的精确性和高效性.

图9 两种算法均方误差对比
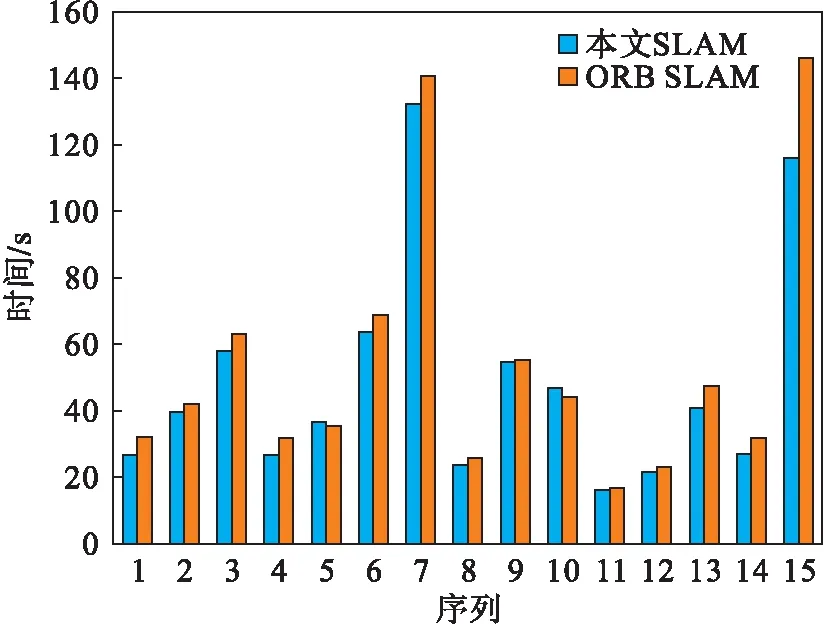
图10 两种算法时间对比
4 结 语
本文提出一种融合单目信息的RGB-D SLAM优化系统.该算法可以更好地规避误差较大的深度图像给系统造成的影响.通过实验验证了改进算法的可行性与精确性.
猜你喜欢
今日农业(2021年17期)2021-11-26
现代电子技术(2021年1期)2021-01-17
中国科技纵横(2020年13期)2020-12-11
现代信息科技(2020年22期)2020-06-24
山东工业技术(2019年16期)2019-07-19
现代电子技术(2018年18期)2018-09-12
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
科技与创新(2018年12期)2018-06-22
电脑知识与技术(2018年35期)2018-02-27
