
基于多通道卷积神经网络的单幅图像深度估计
2020-06-16 10:40:58朱丙丽高晓琴阮玲英
计算机应用与软件 2020年6期
朱丙丽 高晓琴 阮玲英
1(重庆三峡学院计算机科学与工程学院 重庆 404100)
2(四川工商职业技术学院信息工程系 四川 都江堰 611830)
0 引 言
图像深度估计是计算机视觉中的一个基本问题,在该领域中有着广泛的应用。深度信息是理解场景中几何关系的重要线索,具有颜色和深度通道的RGBD图像可以应用于多种任务,如三维模型重构[1-2]、场景识别[3-4]和人体姿态估计[5]等。
深度估计通常是使用多幅或单幅图像预测场景深度图的过程。当使用多幅图像预测深度图时,通常采用运动序列图像进行预测[6-7],其得到的深度图可以用于理解相对丰富的三维结构信息。相比之下,从单幅图像估计深度更具挑战性。这是因为在使用单幅图时,无法将立体图像和时间帧进行相互匹配。
越来越多的方法尝试对单幅图像进行深度估计,大致可以分为两大类:基于学习的方法和交互式方法。一些传统的基于学习的方法将深度估计表述为一个马尔可夫随机场学习问题。Saxena等[8]使用线性回归和马尔可夫随机场从一组图像特征预测深度。Liu等[9]提出了一种考虑相邻超像素之间关系的离散连续条件随机场模型,实现了深度估计与语义分割的强相关性,利用预测的语义标签,通过对类和几何先验深度的强化引导三维信息重建。
目前基于学习的方法大多依赖于深度学习的应用,其中深度卷积神经网络(Convolutional Neural Network,CNN)的使用最为普遍。Eigen等[10]设计了一个全局粗尺度深度CNN,直接从输入图像返回一个粗略的深度图,然后训练一个局部精细网络进行局部优化。Liu等[11]通过探究CNN和离散连续条件随机场提出了一种深度估计的深度卷积神经场模型。在统一的深度CNN框架下,共同学习离散连续条件随机场的一元势和成对势。Wang等[12],与传统的基于学习的方法一样,使用CNN联合预测由像素深度值和语义标签组成的全局布局,通过深度和语义信息的交互提高性能。
为了通过单幅图像进行深度估计,本文提出了一种基于多通道卷积神经网络的单图像深度估计算法。首先,为了提取信息更多的CNN中间层特征,对ResNet[13]的框架进行了改进;然后对输入图像进行各种比例的裁剪来生成多个深度图候选对象,并将这些深度图候选对象映射合并为一个深度映射候选对象;最后,通过傅里叶反变换生成最终估计深度图。
1 算法设计
1.1 深度估计网络结构
ResNet-152是一个非常深的网络,包括151个卷积层和1个全连接层。如图1所示,原始的ResNet-152包含50个BC。为了提取信息更多的中间层特征,对BC进行了改进。BC,C′表示修改后的块,其中:C是输出特征图中的通道数,C′为特征映射中通过附加路径提取的通道数。在这里,中间特征映射从BC的最后一个ReLU层提取得到。
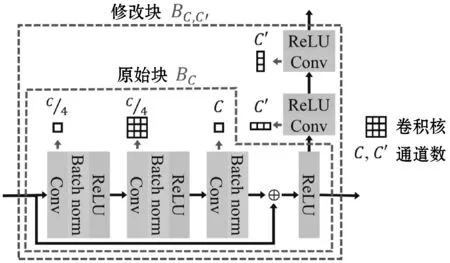
图1 原始块和修改块的结构图
在训练阶段,为了提升训练速度和提高深度估计的性能,本文采用双阶段训练方法。在第一阶段,使用ResNet-152的原始结构对网络进行训练。然后从ResNet-152参数开始,对图像分类任务进行预训练,并使用训练图像及其实际深度图对其进行微调。在第二阶段,使用第一阶段的参数开始训练,用高斯随机值初始化附加特征提取部分的参数。
1.2 深度平衡欧几里得损失
在回归问题中,经常使用欧几里得损失:
(1)
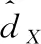
(2)
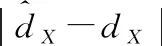
为了克服这个问题,本文提出一种新的损失,称为深度平衡欧几里得(DBE)损失:
(3)
式中:g是平衡的二次函数。
(4)
然后可得:
(5)
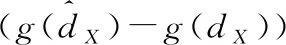
1.3 基于多通道卷积神经网络的深度估计
基于上文提出的深度估计网络结构,使用DBE损失进行训练,可以将输入图像生成多个深度图候选对象。图2说明了生成深度映射候选对象的过程。首先,将输入图像分别裁剪到四个角,裁剪比r定义为裁剪后的图像与整个图像的大小比。其次,通过CNN对每个裁剪后的图像进行处理,得到相应的深度图。最后,将这四个部分估计的深度映射合并为一个深度映射候选对象。

图2 多通道卷积神经网络中深度图候选对象的生成过程
在合并过程中,所有深度值都应该按1/r的倍数进行缩放,以补偿裁剪后的图像中物体看起来更近的缩放效果。缩放后,将部分深度图转换到它们的位置,然后叠加,对重叠区域的叠加进行平均。
由于CNN参数不对称,翻转后的图像不会产生翻转后的深度图。因此,本文水平翻转输入图像,获得裁剪比r的深度映射候选对象,并翻转深度映射候选对象。
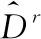
(6)
式中:u和v是水平和垂直频率。
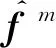
(7)
(8)
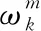
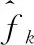
(9)
这可以使用Tk的伪逆运算来解决:
wk=TK+tk
(10)
本文对所有k重复这个过程以确定所有的权值和偏置参数。
2 实 验
2.1 实验设置
本文使用NYUv2深度数据集[1],其中包含大约280 000幅训练图像。为了训练所提出的CNN,本文使用比例、旋转、颜色和水平翻转变换来执行数据增强。NYUv2数据集还提供654幅单独的测试图像。如上文所述,这里采用双阶段训练法。在第一阶段,使用预先训练的ResNet-152网络初始化参数,再进行50万次迭代训练,区域块大小为4,学习率为0.000 16。在第二阶段中,将现有部分的学习率降低10-3倍,对于附加的特征提取部分,将学习速率设置为0.000 16,块大小也设为4。
对于每幅图像,本文生成9个具有裁剪率r∈{0.60,0.65,…,1.00}的深度图候选对象,并且为每个裁剪率使用翻转候选对象。因此,最终可得到18个候选对象。
2.2 实验指标
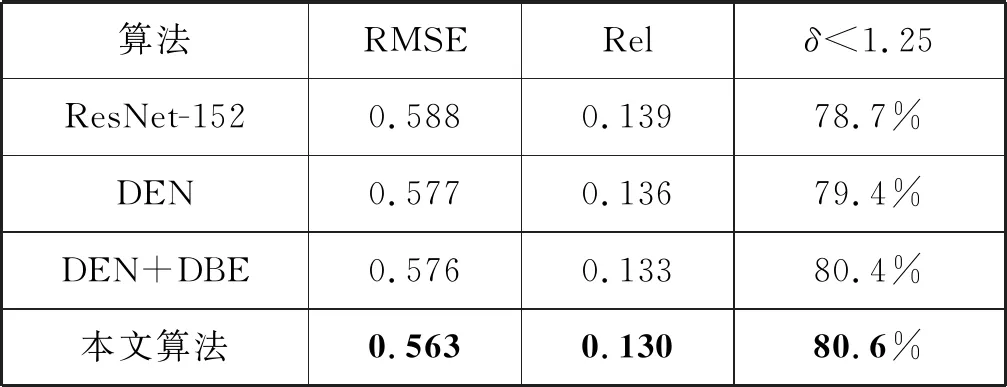
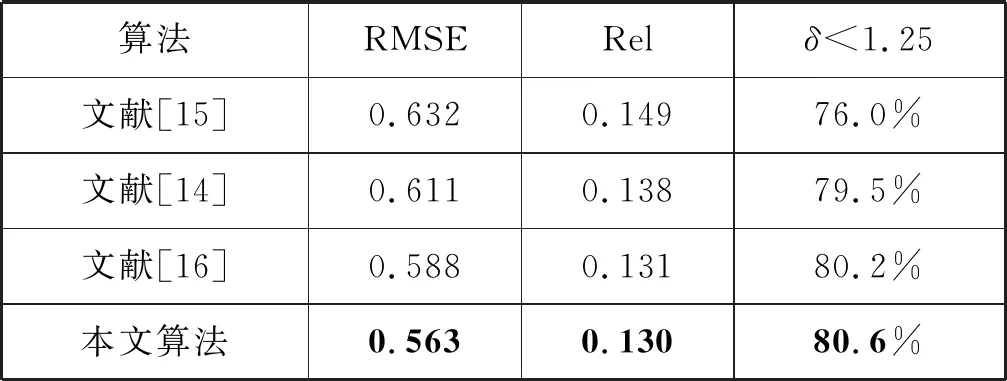
这里使用了三个性能指标[14]来进行结果对比,分别为RMSE、Rel和δ δ 本文基于ResNet-152提出了改进的深度估算网络(DEN),然后提出了改进的深度平衡欧几里得(DBE)损失函数,最后提出了基于傅里叶联合算法(FDC)。 为了较好地对比本文的算法效果,分别使用ResNet-152、DEN、DEN+DBE和本文算法对输入图像进行深度估计。深度估计结果如图3所示。 (a) 输入图像 (b) ResNet-152 (c) DEN (d) DEN+DBE (e) 本文算法 (f) 实际深度图 为量化对比分析图3的深度估计结果,分别使用RMSE、Rel、δ<1.25指标对图3(b)~(e)进行计算,结果如表1所示。观察表中数据可发现,对网络结构的改进优化了深度估计结果,例如RMSE从0.588(ResNet-152的值)提高到0.577(DEN的值)。同理,DBE和FDC均优化了深度估计结果。因此本文完整算法的最终指标为最佳值,如表1中粗体字所示。 表1 本文算法的指标结果 将本文算法与最近提出的先进算法进行比较,结果如图4所示。与其他算法相比,本文算法能够准确、可靠地估计深度信息,减少模糊伪像。通过对比表2中的指标结果,同样可发现,本文算法的质量指标最佳、效果最好。 (a) 输入图像 (b) 实际深度图 (c) 文献[15] (d) 文献[14] (e) 文献[16] (f) 本文算法 表2 与其他算法比较的指标结果 本文提出了一种基于多通道卷积神经网络的单图像深度估计算法,该算法生成多个深度映射候选对象,并将这些候选对象组合到傅里叶频域。具体来说,本文开发了基于ResNet-152的CNN结构,并引入了DBE损失对网络进行深度训练。此外,本文通过裁剪具有不同裁剪比例的输入图像来生成多个深度图候选对象。为了利用不同深度映射候选函数的互补性质,在傅里叶域中对它们进行了组合。实验结果表明,该算法取得了较好的效果。2.3 实验结果



3 结 语
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:57:22北京航空航天大学学报(2021年9期)2021-11-02 08:24:26计算机应用(2019年3期)2019-07-31 12:14:01电子制作(2019年11期)2019-07-04 00:34:38传感器与微系统(2018年7期)2018-08-29 00:44:48北京航空航天大学学报(2018年1期)2018-04-20 06:38:17自动化学报(2017年11期)2017-04-04 02:52:30软件导刊(2016年9期)2016-11-07 22:22:57自动化学报(2016年3期)2016-08-23 12:03:02科技视界(2016年2期)2016-03-30 11:17:03
