
基于深度学习的大型陨石坑识别方法研究
2020-06-16 03:27郑磊胡维多刘畅
北京航空航天大学学报 2020年5期
郑磊,胡维多,*,刘畅
(1.北京航空航天大学 宇航学院,北京100083; 2.中国科学院深圳先进技术研究院,深圳518055)
人类对月球及更远的天体或空间环境开展的探测活动,是如今航天活动的重要方向和空间科学与技术创新的重要途径,是当前和未来航天领域的发展重点之一。陨石坑作为反映星体地表情况及地质年龄的重要参考对象,为安全登陆地球以外的其他星球并展开实地考察研究提供了可靠的依据,因此近年来关于月球、火星等星体表面陨石坑情况的研究越来越多。
陨石坑是陨石体高速运动并撞击到天体表面或天体内部熔岩喷发后所形成的坑穴。这种坑穴蕴含着丰富的信息,如陨石坑大小和个数的统计形成了月球和火星的地质地层学,并且陨石坑的数目已成为衡量遥远行星地质形成年龄的唯一工具;陨石坑形态学促进了自然降解过程、地质的区域性差异、地下挥发物质的分布等大量的行星地质问题的研究[1-2];陨石坑因其显著的地形特征,常常作为深空星体探测时的地面标志物和导航路标,用于探测器的位置定位及着陆避障任务中[3]。陨石坑在星际探测多个方面都得到了广泛的研究和应用,因此,如何识别星体表面的各种陨石坑,为星际任务提供应用基础,已成为航天领域研究的热点和难点。
近年来,国内外学者对星体表面陨石坑的识别方法进行了深入的研究。美国喷气推进实验室(JPL)的Cheng等[3]将光照方向与陨石坑边缘信息相结合,通过陨石坑边缘锚点之间的几何相关性实现了陨石坑的识别;Sawabe[4]和Kim[5]等根据陨石坑的特定形状,构造相对应的陨石坑模板,通过模板匹配实现陨石坑的检测;冯军华等[6]基于Canny方法及边缘配对完成陨石坑检测;丁萌等[7]利用基于弦中点Hough变换的方法,有效结合Kanade-Luca-Tomasi(KLT)特征检测算法实现了陨石坑的检测。这些传统的基于图像处理及图像配准的陨石坑识别方法,虽然有效地对陨石坑进行了较为准确的识别,但工作量大,任务繁琐,并且缺乏实时性。
得益于近年来人工智能的发展,现在关于陨石坑识别的研究越来越趋向于机器学习和神经网络方面的自动识别领域[8-9]。例如,文献[10]中利用主成分分析(PCA)方法统计纹理测量信息,并应用纹理分析分割图像达到检测陨石坑的目的;Boukercha等[11]利用机器学习增强算法对陨石坑进行初步筛选得到陨石坑候选区域,结合支持向量机(SVM)和多项式分类器对陨石坑进行进一步的检测;Silburt等[12]利用卷积神经网络实现了数字高程模型(Digital Elevation Model,DEM)中陨石坑的识别。这些方法虽然实现了陨石坑的自动识别,提高了识别效率和精度,但均将陨石坑统一拟合为椭圆或圆,对小型陨石坑采用正负样本的二分类方法,对于较大的、形态不规则的复杂陨石坑及陨石坑撞击盆地并不能有效识别。相比小型陨石坑生命周期较短并存在侵蚀、覆盖、掩埋及转化问题,大型陨石坑能够在漫长的时间长河里保持形态和结构稳定性,无论是在天体地质学还是作为路标导航方面的研究,大型陨石坑都具有很强的时效性。因此,本文以星体宏观视角下的大型陨石坑作为研究对象,创建了不同数据源的陨石坑样本数据库,构建了基于深度学习的多尺度陨石坑自动识别网络框架,改进了目标检测时常用的非极大值抑制(Non-Maximum Suppression,NMS)算法,提出了一种效率更高的陨石坑多分类识别方法。
1 陨石坑样本数据库构建
1.1 数据来源
陨石坑作为本文研究对象及训练深度学习识别网络的核心组成部分,其数据来源的真实性和图片质量的清晰度是选取数据时应该重点考虑的2个因素,但由于能够查阅到的各天体大型陨石坑图片资料相对较少,本文选取了人类研究最多且最为熟悉的月球作为数据采集对象。月球表面拥有大量的各类陨石坑,对于很多大型环形山类型的陨石坑,人类在地球上用肉眼即可观测到,并且用天文拍摄设备可以取得质量较好的大型陨石坑图片。因此,本文选取了在不同月相情况下月球表面的多个大型陨石坑作为识别对象。
具体数据来源有2个方面:①公布在美国国家航空航天局(NASA)科学可视化工作室官网[13]的2018年全年高清仿真月相图,该月相图的生成参数源自2009年开始执行绕月飞行的月球勘测轨道飞行器(Lunar Reconnaissance Orbiter,LRO),其所携带的激光高度计和航天照相机使得以前所未有的清晰度来观察月球成为可能。本文选取了2018年每个月由新月到月盈、再到月亏的月相图作为大型陨石坑样本提取和检测数据源,图1为2018年2月的部分月相图[13]。②笔者于2018年11月和12月利用专业相机拍摄的月相图,拍摄设备主要由相机、二倍镜及长镜头构成,最大焦距可达400mm,能够较清晰地拍摄到月球表面众多大型陨石坑。由于拍摄天气及环境等因素影响,本文只选取了部分清晰度高的月相图作为实验数据,图2为2018年12月的部分月相图。

图1 NASA官网提供的仿真月相图[13]Fig.1 Simulated moon phases provided by NASA official website[13]

图2 专业相机拍摄的真实月相图Fig.2 Realmoon phases captured by a professional camera
1.2 陨石坑样本数据集
本文选择了月球表面的危海(Mare Crisium)、澄海(Mare Serenitatis)及第谷(Tycho)3个具有代表性的大型陨石坑作为识别的对象。危海是位于月球东北半球的月海,直径605 km,面积约17.6×104km2[14]。澄海是月球上大型月海陨石坑之一,直径约600 km,环形结构可延伸至880 km[15-16],基于其退化的外观,澄海陨石坑被一些研究者认为是月球上最古老的陨石坑之一[17]。哥白尼时代被广泛研究的第谷陨石坑,是月球正面最年轻、最显著的大型陨石坑之一[18]。危海有类似尾巴的部分,澄海有一个突出的三角,而第谷周围有以其为中心的放射状沟壑,均具备显著特征,如图3所示。

图3 危海、澄海及第谷陨石坑Fig.3 Mare Crisium,Mare Serenitatis and Tycho craters
通过2个不同的数据源,本文采集了大量陨石坑样本块,并构成了样本数据库。样本数据库具体包含3个不同的陨石坑样本数据集:①单独从NASA官网下载的月球图片中采集样本构成第1个陨石坑样本数据集(NASA crater,Ncrater);②单独从专业相机拍摄的月球图片中采集样本构成第2个陨石坑样本数据集(Camera crater,Ccrater);③将前2个陨石坑样本数据集合并,构成同时含有2个不同数据源样本的第3个陨石坑样本数据集(NASA and Camera crater,NCcrater)。为了提高识别精度,增加样本间的差异性,上述每个样本数据集中除了包含待识别的危海、澄海、第谷这3种陨石坑样本外,还增加了负样本,构成用于四分类问题研究的样本数据集。
由于能够直接采集得到的陨石坑数量很难满足训练识别网络的需求,本文采用了数据增强的方法,对上述3种样本数据集中原有的每个样本分别通过镜像、均值滤波、加少量椒盐噪声和高斯噪声等9种图像处理方法来扩充数据,并将新生成的样本保存到各自对应的样本数据集中,从而将原来的3个样本数据集的样本数扩充了10倍。表1为数据增强后3个样本数据集各自包含的各类样本总数。图4显示了样本数据集中各类陨石坑样本块,每个样本块尺寸为3×227×227。采取数据增强的方法,不仅能大幅度增加每个样本数据集样本数量,而且在保持待识别目标主要特征的同时,一定程度上增加了样本的多样性,提高了网络模型的泛化能力。

表1 数据增强后各类样本数Tab le 1 Num ber of d ifferent types of sam p les after data augm entation

图4 四类陨石坑样本Fig.4 Four types of crater samples
2 陨石坑识别网络框架搭建
2.1 识别网络的选择
随着近年来人工智能领域的飞速发展,越来越多的深度学习神经网络模型进入大众的视野,如卷积神经网络(CNN)、递归神经网络(RNN)及最近几年热门的生成对抗网络(GAN)等。CNN由于其独特的卷积结构,在图像处理领域有着明显的优势。过去几年中,CNN已成功应用于许多经典图像处理问题,如图像去噪[19]、超分辨率图像重建[20]、图像分割[21]、目标检测[22-24]、物体分类[25-26]等。通常,越深层的网络将具备越强的学习能力,近年来CNN网络发展迅速,并趋向于更加深层次的网络模型。然而,层数越深的网络训练起来就会越困难。一方面,网络训练多采用梯度反向传播算法进行参数学习和优化,过深的网络因为层数太多会出现梯度消失的情况,造成网络无法收敛;另一方面,越是深层的网络对训练设备和训练样本数量有着越高的要求,性能普通的设备训练时间将会十分漫长,而较少的训练样本将会造成网络过拟合。本文选用CNN作为陨石坑识别网络,并且通过综合考虑训练时间消耗、识别精度、现有的训练设备性能和陨石坑样本数量等方面因素,发现相比于GoogLeNet等近年来发展的新型深层网络,选择CaffeNet模型对陨石坑样本图像进行分类,不仅能保证较高的识别精度,还能够节约大量的时间成本,同时避免了更深层网络中过拟合现象的出现。CaffeNet模型是基于Krizhevsky等[27]针对数据集ImageNet训练生成的神经网络架构AlexNet,并在AlexNet基础上进行了一定的优化,近年来在各种图像处理任务中仍展现着出色的表现。
2.1.1 卷积神经网络模型
一个典型的CNN网络由多个卷积层、池化层及全连接层组成。卷积层是CNN中计算量最大的部分,同时也是最重要的结构。卷积层内部包含多个卷积核,组成卷积核的每个元素都对应着一个权重系数和一个偏差量,卷积核与输入数据进行卷积运算,从而提取输入的不同特征,第一层卷积层可能只能提取一些如边缘、线条和角等低级的特征,深层的卷积网络能从低级特征中不断迭代提取更复杂的特征。卷积层的作用多为检测特征,池化层的作用则是提取、凝炼特征。池化层基本执行向下采样操作,类别得分在全连接层之后计算,正因如此,池化层常常被放置在卷积层之后。全连接层的作用是把所有局部特征进行汇总变成全局特征,用来计算最后每一类的得分。
选用CNN作为陨石坑识别网络有着多方面的优势。CNN具有极强的通用性,可以近似于任何线性或非线性转换,能够有效地提取各类陨石坑特征;CNN不需要通过手工制作的过滤器来进行目标物特征的提取,取而代之的是机器自动学习算法;同时,得益于GPU的并行计算能力,CNN能够高速处理输入数据。
2.1.2 随机梯度下降法
在选择了用于陨石坑识别的神经网络模型后,就可以通过一些优化策略来进行网络训练参数学习。通常用于训练CNN模型参数的算法是随机梯度下降(Stochastic Gradient Descent,SGD)法,其使用反向传播来计算梯度进行权重的更新,通过不断减小损失函数输出值来进行参数的自动学习。反向传播是多层网络中最常用的算法,该算法的核心是应用链式法则计算网络中各权值对损失函数的影响[28],从而寻找网络的全局最优解。
SGD法的目标是使损失函数最小化,从而在CNN模型中找到对目标问题具有良好泛化能力的最优参数[29]。为了量化SGD法的作用,定义损失函数的形式为

式中:w为网络中权重的集合;b为偏置的集合;n为每个批次中样本的个数;a为输入为x时的输出;y(x)为对应的期望输出或为每个类别样本预先贴上的分类标签值;求和是在总的训练输入x上进行的。SGD法的基本思想是:通过随机选取小批量训练输入样本,不断计算使损失函数C(w,b)输出值减小的梯度,同时更新网络参数,从而寻找损失函数全局最小值时的最优解。网络权重和偏置的具体更新方式为
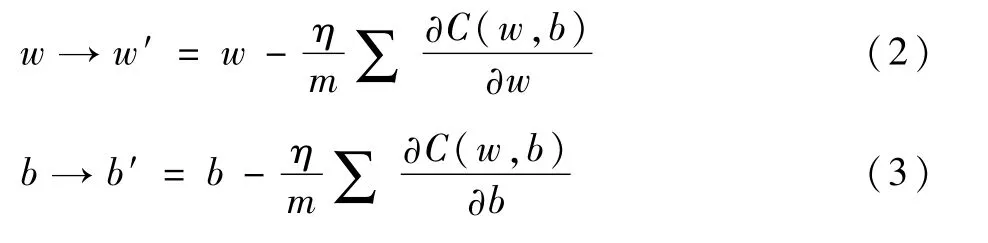
式中:m为随机小批量数据样本大小;η为学习率,是一个很小的正数。
2.2 陨石坑识别网络框架
在训练陨石坑识别网络的过程中,先将包含各类陨石坑的样本数据集以3×227×227尺寸输入到网络,并以CaffeNet的卷积层和全连接层作为各类陨石坑特征的提取器,将提取到的各类特征信息输入到相当于分类器的Softmax层,并结合预先设置的标签进行陨石坑分类,对全部输入的样本数据集进行3 000次训练,生成多类陨石坑识别网络模型,进而利用该模型结合目标检测算法实现多类陨石坑的识别。具体方法流程如图5所示。
2.3 陨石坑检测算法
在实际中,各类陨石坑分布在地形图的任意位置,同一幅图片中可能会存在多种陨石坑,但采用的识别网络输入尺寸是固定的,训练网络时用的只是每类陨石坑的3×227×227样本块,因此需要一种有效的检测算法,在可能存在陨石坑的图片中判断是否有待检测的目标,并对其进行分类和标注。本文在目标检测研究中常用的NMS算法基础上,结合陨石坑检测时的实际情况,对NMS算法进行了优化,提出了一种准确率更高的陨石坑检测算法,经过参数优化和实验验证构建了基于深度学习的多尺度多类别的陨石坑自动识别网络框架。

图5 陨石坑识别流程Fig.5 Flowchart of crater identification
2.3.1 基于NMS的目标检测算法
通常,基于深度学习的目标检测算法包括3个步骤:①通过目标样本集训练好最优的识别和分类网络模型;②在待检测的图中以网络输入要求的尺寸,通过遍历的方式选取待识别对象输入到训练好的网络模型进行分类,并返回位置信息和类别信息;③通过NMS算法选出有效检测结果,并在原图中标注。
NMS算法的基本思想为抑制非极大值的元素,是广泛应用于目标检测中寻求局部最大值的算法,主要目的是消除冗余(交叉重复)的窗口,找到最佳目标检测位置。传统的NMS算法流程如下:
步骤1 对根据识别网络输出得到的目标检测候选框所对应的置信度得分进行排序。
步骤2 选择置信度最高的检测框添加到最终输出列表中,并将其从候选框列表中删除。
步骤3 计算置信度最高的检测框与其他候选框的IoU(Intersection over Union),IoU指2个候选框的交集部分与并集部分的面积比值。
步骤4 将IoU小于阈值(一般取0.3~0.5)的候选框按置信度得分重新排序,重复步骤2、步骤3。
步骤5 重复上述过程,直至候选框列表为空,最终输出框中存有的即为所求的目标检测框。
当将上述传统的目标检测算法运用于本文的陨石坑检测时,主要存在3点不足:①待检测的多类陨石坑以相同比例尺呈现在一幅图中,因此其大小有较大差别的,传统以网络输入尺寸对待测图片进行遍历的单个检测框,并不能将所有不同类别的陨石坑在一次遍历搜索中检测出来;②识别网络模型对目标并不总能做到百分百的正确识别,因此目标候选框中会存在个别与置信度最高的框没有相交面积,或者相交面积太小的误检测框,此时运用NMS算法会将这些误检测框作为正确信息输出;③当对图片中目标进行分类和标注时只需一个最准确的检测框就行,但当用到NMS算法时最终往往会输出多个满足条件的检测框,通常解决此问题的方法是不断改变IoU的阈值直到最终只输出一个检测框,这种做法随机性太大,手动干预太多,效率太低。
2.3.2 检测算法优化
针对基于深度学习的传统检测算法的不足,本文提出了多尺度的陨石坑自动识别网络框架。首先,对识别网络模型读取待测图片的方式进行了改善,设置了一个缩放因子(本文取0.9)。当检测框每次对待测图片遍历后,将当前图尺寸按缩放因子缩放,进行下一次的遍历,直到待测图片接近检测框尺寸,并在每轮遍历结束时将得到的目标候选框在原始图中对应的位置信息及置信度存储。对NMS算法,本文结合实际情况也进行了相应优化,增加了IoU阈值下限,并将阈值固定为

这样就可以淘汰与置信度最高的框没有相交面积或者相交面积太小的误检测框,并且提高算法的自动检测效率。
同时,在NMS算法输出最终检测框的部分也进行了相应优化,增加了最大差值法,即在最终输出的各检测框的顶点间实行x轴和y轴2个方向上的差值运算,取差值最大的4个点作为最终输出的唯一检测框的顶点,从而在保证检测准确度的同时,避免了传统NMS算法带来的最终检测结果中多个检测框框出同一目标的冗余问题。图6为本文优化后的多尺度多分类陨石坑检测算法的流程。其中,待检测的原图像尺寸在实际检测中均大于3×227×227,craterNMS为优化后的NMS算法。
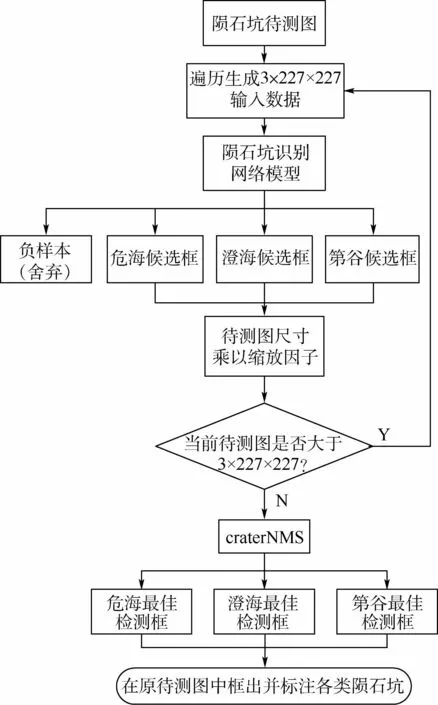
图6 多尺度陨石坑检测流程Fig.6 Flowchart ofmulti-scale crater detection
3 实验结果及分析
为了验证本文提出的基于深度学习的大型陨石坑识别方法的可行性,主要从以下3方面进行相关实验:①在不同网络训练参数优化方法下,陨石坑识别网络模型的训练效果;②不同数据来源的训练集对识别网络的泛化能力的影响;③基于craterNMS的多尺度多分类的陨石坑检测算法与传统方法的检测结果比较。
在实验过程中,将3个陨石坑样本数据集Ncrater、Ccrater和NCcrater,依次按7 ∶3的数量比例构建训练集和测试集,得到3组单独的网络训练集。分别对本文的陨石坑识别网络进行训练,且训练集和测试集仅用于网络模型的训练过程中,不参与训练完毕后网络模型泛化能力等性能的验证。
3.1 网络参数优化方法
训练一个有效的深度学习网络,调参是永恒不变的话题。如何让各个网络参数随着训练数据的输入自动学习,从而使网络训练朝着所需要的方向收敛是当前人工智能领域研究的热点。因此,越来越多的网络训练参数优化策略被提出,近年来经常被应用于网络训练时参数学习的优化方法主要有SGD法、AdaDelta优化法[30]、Adam 优化法[31]、RMSprop优化法[32]等,这些方法均为基于梯度的网络参数优化方法。
SGD法是目前使用最多的一种优化方法;AdaDelta是一种“鲁棒的学习率方法”,通过把历史梯度累积窗口限制为固定的大小来调节参数;Adam是一种自适应学习率的方法,与AdaDelta不同的是,其使用了动量进行学习率衰减;RMSprop与AdaDelta类似,但在调参时添加了衰变因子防止历史梯度求和过大。
本文分别利用上述4种优化方法在构建的3种样本数据集上进行了陨石坑识别网络模型的训练。采用样本数据集Ncrater和Ccrater时的初始学习率为η=0.000 5,样本数据集为NCcrater时η=0.001。表2为本文实验的计算机测试环境。表3~表5统计了4种优化方法在3种样本数据集上训练网络时最终的准确率、最低损失代价值及训练时间。可知,4种优化方法在3种样本数据集上训练网络都取得了很不错的效果,最后的训练结果都相差较小,但依旧不难发现无论利用哪个样本数据集,SGD法取得的精度都是最高,最低损失代价值都最小,训练时间都最少。由此可见,训练陨石坑识别网络模型时,SGD法的参数优化效果最好,鲁棒性最强,因此在其他关于陨石坑识别方法研究的实验中,均采用SGD法作为网络参数优化策略。

表2 计算机配置参数Table 2 Com puter configuration param eters
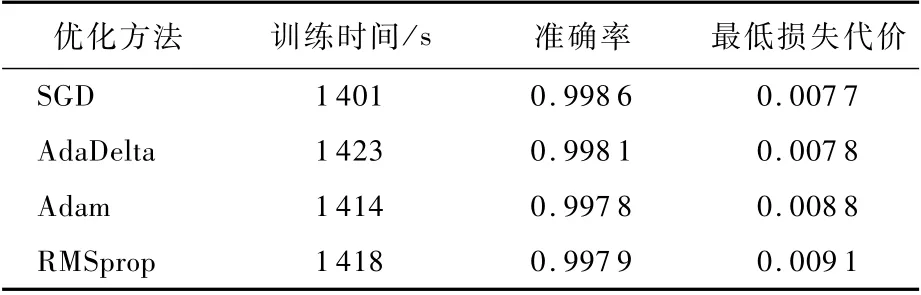
表3 样本数据集Ncrater训练结果Table 3 Training results of sam p le data set Ncrater
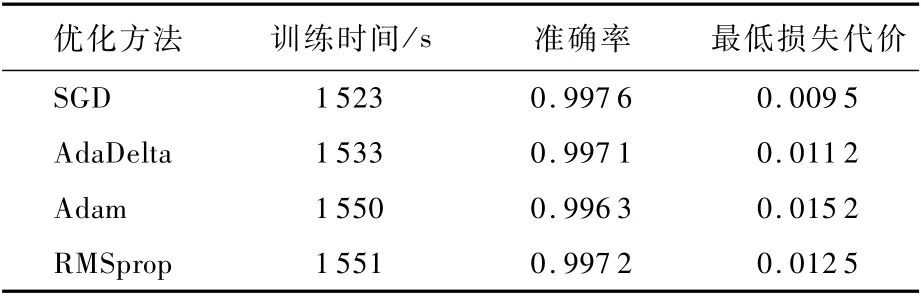
表4 样本数据集Ccrater训练结果Tab le 4 Training resu lts of sam p le data set Ccrater
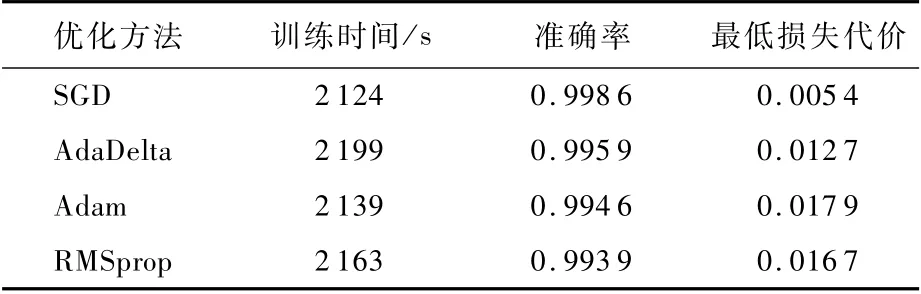
表5 样本数据集NCcrater训练结果Tab le 5 T raining resu lts of sam p le data set NCcrater
3.2 不同数据源样本数据集网络泛化效果
从3.1节的实验结果可以看出,陨石坑识别网络模型的训练准确率已经达到了很高的水平,但这并不能充分说明深度学习方法在实际陨石坑检测中也能有很好的效果。这是由于时间和数据资源的限制,能够用于本文研究的陨石坑样本数据集数量并不是很庞大,因此在训练时可能会出现过拟合的现象;同时,在衡量一个网络模型的优劣时,训练过程中准确率及最低损失代价值只是一部分的参考指标,主要用于监测网络的训练情况,而网络模型的泛化能力才是最为关注的关键性指标。泛化能力越强的网络模型,在未被用于训练的验证样本数据集(以下简称验证集)上的识别准确率就越高,在执行实际的识别任务时的效果相应就会越好。因此,选用网络在验证集上的识别准确率作为陨石坑识别网络模型的评估指标,定义Pi为特定陨石坑的识别准确率,Ni为该类陨石坑正确识别数,Si为验证集中该类陨石坑总数,Pn为网络模型识别准确率,I为验证集中样本类别总数,评价公式为

为了研究通过训练集和测试集训练完毕生成的网络模型的泛化能力等性能,从2个不同数据源重新采样,构造了2个未参与陨石坑识别网络训练过程的验证集VNcrater(Validation NASA crater)和VCcrater(Validation Camera crater)。验证集中各类样本的数量如表6所示。
如表7和表8所示,分别利用构造的3个训练集训练网络模型,然后在2个验证集上统计每个网络模型对各类样本的识别准确率。表中:Nnet、Cnet和NCnet分别代表利用训练集Ncrater、Ccrater和NCcrater训练得到的陨石坑识别网络模型,总准确率即为网络模型识别准确率Pn。
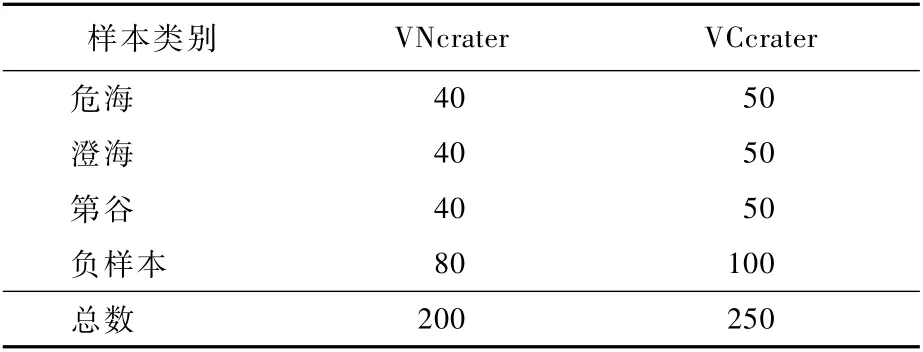
表6 验证集中各类样本数Tab le 6 Num ber of different types of sam p les in verification set

表7 验证集VNcrater上的识别准确率Table 7 Identification accu racy on verification set VNcrater

表8 验证集VCcrater上的识别准确率Table 8 Identification accu racy on verification set VCcrater
从实验结果可知,Nnet、Cnet在与其训练样本来自同一个数据源的验证集上测试时,分别达到了0.985和0.920高识别准确率;由于NCnet的训练集来自2个数据源,因此在验证集VNcrater和VCcrater上都展现了不错的识别效果,分别取得了0.991和0.945的识别准确率;同时,用Nnet、Cnet在与其训练样本数据来源完全不同的验证集上检验时,虽然识别准确率有所下降,但还是取得了不错的效果,特别是Cnet能在异源验证集VNcrater上准确地识别出第谷和负样本,并取得了0.863的总准确率。在实验结果中可以注意到一点,对危海的识别准确率并没有其他类陨石坑的高,这是由于危海位于月球边缘地带,在月相发生变化时,其形态特征在地球观测者视角里将随之发生一些变化,因此对识别精度产生了一定的影响。
同时,表7和表8中实验结果都反映了本文提出的陨石坑识别网络模型具有较强的泛化能力,不管在同源还是异源的验证集上实验都能达到较高的识别准确率。因此,在实际应用中构造网络对其他陨石坑进行识别时,可以利用由本文建立的陨石坑样本数据库训练得到的网络模型,结合迁移学习方法进行参数初始化,从而有效避免因待测陨石坑样本少而出现过拟合的现象,提高识别精度。
3.3 多尺度多分类陨石坑检测算法
本文优化了传统基于NMS算法的目标检测算法,并结合陨石坑识别的实际情况,提出了基于craterNMS的多尺度多分类陨石坑检测算法。为了验证该算法的有效性,本节分别用Ccrater和Ncrater这2个样本数据集训练网络模型,并用各自数据源中未用来采集样本的图片对上述2种算法进行对比实验。其中,选自NASA官网的仿真月相测试图有12张,选自专业相机拍摄的真实月相测试图有18张,2类测试图均包含了从新月到月盈、再到月亏等多种形态的月相图。在训练网络模型时,选取的参数学习策略为SGD法,初始学习率均为η=0.000 5,Softmax输出各类陨石坑置信度得分的阈值均为0.5,检测框滑动步长为45像素。实验结果如图7和图8所示,每一行图片依次为未采用NMS算法、采用传统NMS算法(IoU阈值为0.4)和craterNMS算法得到的陨石坑检测结果,红色框为危海检测框,绿色框为澄海检测框,蓝色框为第谷检测框,同时在craterNMS算法检测图中显示了黄色虚线框表示的真实框标注,用作实验结果对比。由于受光线、天气等因素影响,专业相机拍摄的月相图比仿真月相图图像特征更具多样化,相应地更能验证本文陨石坑检测算法的鲁棒性,且篇幅有限,因此图7仅展示了2幅NASA官网仿真月相图的陨石坑检测结果,图8展示了5幅专业相机拍摄的月相图陨石坑检测结果。
由于Softmax进行陨石坑分类时置信度阈值选取的较低,在未采用NMS算法时会有许多误检测框出现,采用NMS算法后效果有所改善,但仍然有一些误检测框存在。当然,在前2种算法中可以通过反复调节识别网络模型中Softmax分类

图7 样本数据集Ncrater的实验结果Fig.7 Experimental results of sample data set Ncrater

图8 样本数据集Ccrater的实验结果Fig.8 Experimental results of sample data set Ccrater
置信度和NMS算法中IoU这2个阈值的大小来剔除误检测框,但需要手动不断干预检测过程,效率太低,并且当替换一副不同的陨石坑待测图进行检测时,又要重新调试阈值,泛化性能很差。
相比前2种检测算法的不足,第3种采用craterNMS的多尺度陨石坑检测算法得到的结果效果显著,能在分类置信度和IoU这2个阈值都固定的情况下成功得到各类陨石坑唯一的精准检测框,充分说明本文陨石坑检测算法的确能在很大程度上改善陨石坑识别效果,并且具有通用性,在不同的样本数据集上都能实现自动精准检测陨石坑的目的。同时,图7和图8的检测结果也很好地验证了本文提出的陨石坑识别方法的有效性。例如,图8第1行月相图片中澄海较大部分面积已进入阴影,但仍能被本文方法准确地检测到。

为了对上述3种陨石坑检测算法的检测结果进行定量的数据分析,引入了平均检测准确率P和平均检测框冗余数R两个评价指标,N为2种数据源待测试的月相图总数,Kj为当前测试图中正确检测框数,Ks为该测试图中检测框总数,Kr为该测试图中冗余正确检测框数,评价公式为式(7)和式(8)。
表9为各类陨石坑置信度得分阈值均为0.5时,总数共30张的2种数据源待测月相图最后检测结果的P、R值统计。可知,相对于前2种算法,本文提出的craterNMS的多尺度陨石坑检测算法不仅能消除冗余检测框,而且能在分类置信度阈值较低的情况下准确地检测出各类目标陨石坑。
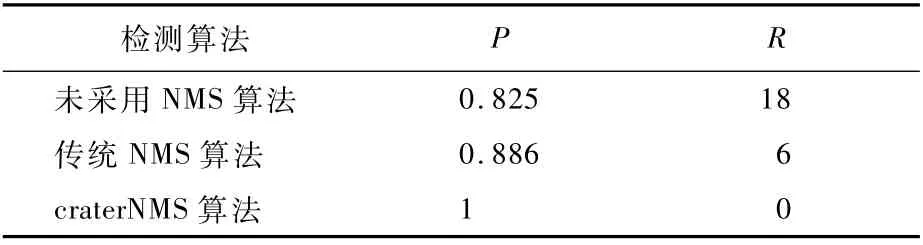
表9 三种检测算法数据分析Table 9 Data analysis of three detection algorithm s
4 结 论
本文以星体宏观视角下的大型陨石坑作为研究对象,结合图像处理和神经网络等方面的知识,提出了一种基于深度学习的多尺度陨石坑自动识别网络框架和陨石坑检测算法,经实验验证主要得出以下结论:
1)从2个不同数据源采集样本进行实验,陨石坑识别网络在与训练集同源的验证集上的识别率可以分别达到0.985和0.920,在异源的验证集上的识别率最高可达到0.863,说明本文的陨石坑识别方法具有良好的泛化能力,同时证明了训练集的数量及来源对识别网络模型的泛化能力和识别精度都能产生较大的影响。在条件允许的范围内,样本数据集数量越大、数据来源越丰富,将越有利于网络泛化能力和识别准确率的提高。
2)训练网络模型时,网络参数优化方法的选取也十分关键,需要根据实验的具体情况选择适合当前研究的优化策略。通过多种优化方法的实验结果对比,发现SGD法在基于深度学习的陨石坑识别方法研究中具有良好的参数优化效果。
3)通过改进传统陨石坑二分类方法,以及优化基于NMS的目标检测算法,实现了多种陨石坑的有效分类,并且不同于传统方法需反复调试阈值,能在分类置信度和IoU这2个阈值都固定的情况下,成功得到各类陨石坑唯一的精准检测框,节约了时间成本,提高了陨石坑自动检测的准确率。
4)通过实验论证了基于深度学习的大型陨石坑识别方法的可行性。
随着科技的发展,将人工智能引入星际探测等领域的研究将具有更为广阔的应用实践和发展前景。
猜你喜欢
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
小天使·四年级语数英综合(2020年10期)2020-12-16
文萃报·周五版(2020年15期)2020-04-22
阅读与作文(小学高年级版)(2020年3期)2020-03-02
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
