
基于特定主题的社交网络影响力评估方法
2020-06-13 07:11:16蒋沁吟
应用科学学报 2020年3期
蒋沁吟, 张 熙
1.北京邮电大学网络空间安全学院,北京100876
2.北京邮电大学可信分布式计算与服务教育部重点实验室,北京100876
近年来,移动互联网发展飞速,社交网络成为互联网用户发布信息、沟通交流的重要途径.在传播信息的同时,社交网络已成为网络营销、舆情传播的重要平台.在网络营销中,为了更好地进行品牌推广,商家需要找到影响力较大的用户进行广告投放.如何衡量社交网络中用户的影响力是当前的一个研究热点,对此学者提出了多种基于社交网络的影响力评估方法.
一个研究方向是基于传播的影响力评估,根据用户的转发行为预测用户微博的转发量,以此衡量用户的影响力大小.这种方法需要获取用户的直接转发数据,由于微博是动态变化的社交网络,用户可以更改昵称且其隐私会受保护,因而需要获取用户转发数据的研究存在一定的局限.
另一个研究方向是基于网络拓扑的影响力评估,根据用户关注信息来评估用户影响力.PageRank 算法便是基于这种思想,但算法仅考虑到用户发布微博数量和用户关注网络,忽略了用户发布的内容.文献[1]提出了TwitterRank 算法,在Twitter 数据集上实现了基于主题的影响力评估,可以计算用户在不同主题分布下的影响力.但这种方法也存在不足.首先,文献[1]认为不同主题之间是相互独立的,但在实验中我们发现提取到的多个主题之间并没有明显的边界.此外,在广告投放、舆情分析等实际应用中,我们往往只对某个特定的目标主题感兴趣,但TwitterRank 中的主题是通过无监督的隐含狄利克雷分布(latent Dirichlet allocation, LDA)提取得到的,导致获取到的主题与目标主题不完全符合.
为了解决上述问题,本文提出了一种新的影响力评估方法,即采用基于网络拓扑(而非基于传播)的影响力评估.该方法通过引入改进的主题提取算法,可提取与关键词相关的目标主题,从而得到特定主题下的用户影响力评估结果.此外,利用不同主题间的交互作用,可使特定主题下的影响力评估更加全面.实验表明,本文方法不会受到转发数据缺失的限制,优于现有的影响力评估方法.
1 相关工作
社交网络中的影响力评估通常分为基于传播的方法和基于用户关系网络的方法两种.
文献[2]提出用户发布微博的平均转发量最能代表用户影响力大小,利用用户发布微博的时间分布、微博时效性和转发偏好计算用户帖子的平均转发量,用以衡量用户的影响力.该方法侧重分析用户发布微博时间分布对被转发频率的影响,忽略了微博内容与用户偏好对转发关系强度的影响,因此不能区分不同偏好的用户对影响力的贡献度.
文献[1]基于用户间的关注关系和用户发布推特的主题信息,分析了在特定主题下用户影响力的大小,并发现将算法给出的排名应用于个性化推荐时可取得较好的效果.文献[1]认为一个人在社交网络中拥有的关注者越多,影响力就越大.但该方法并未考虑到不同主题之间的交互以及特定主题下的用户影响力分析,并且作者提出的用户间相似度衡量方法也存在不足之处.文献[3]使用LDA 主题模型分析用户的兴趣话题相似度,基于用户的传播概率、兴趣相似度和结构相似度构建随机游走模型,提出了一种用户传播能力排序算法.该算法侧重分析用户之间在结构和兴趣话题上的相似度,忽略用户兴趣与参与话题之间的关联性,最终筛选得到的用户包含并非真正关注兴趣话题的用户或者并非持续产生影响力的用户.若直接使用LDA 主题模型提取用户潜在兴趣话题的分布,则容易导致兴趣主题缺乏特异性而无法获取特定主题上的用户影响力.
有的文献把基于传播的方法和基于用户关系网络的方法结合起来.2017 年,文献[4]利用消息内容、标签、转发、回复和提及构建主题行为网络,采用启发式搜索方法生成用户的主题行为影响树,通过最大化受影响用户数和最小化传播路径识别有影响力用户.该方法侧重用户之间主题行为影响树的构建,忽略用户对主题的兴趣以及特定主题的分析.文献[5]提出基于话题和传播能力的用户排序算法,该算法基于微博话题分析用户转发行为的时间特征,进而构建用户转发和用户博文转发的关系网络,以此分析用户对话题信息的传播能力、用户与背景话题间关联性,并综合各项特征计算微博用户影响力.但该算法忽略了影响力分析通常只对特定主题感兴趣这个重要因素.还有的研究将特征交互与社交网络结合,例如文献[6]将用户交互行为的整个时间区间划分成时间片,在主题模型中引入文本主题、各类交互关系以及交互的时间片,提出了一种基于时序和主题的影响力模型.该模型侧重基于转发、评论等交互行为所属时间片来识别影响力有潜在增长趋势的用户,忽略主题与主题之间的交互,因此不能有效提取主题相关的信息.
综上所述,现有的研究方法存在以下问题:1)无法针对特定的主题进行影响力分析;2)忽略了主题之间的交互关系.本文主要从这两方面入手,分析特定主题下的用户影响力以及主题交互的用户影响力.
2 模型定义
2.1 模型框架
本文首先利用特定主题的LDA 模型对用户发布的微博内容进行处理,得到用户对每个主题的偏好,并以此计算出用户与邻居节点之间的主题相似度.将此相似度运用到主题相关的PageRank 中,构建用户主题关系网络,以计算每个主题下的用户影响力.在计算用户之间主题相似度的过程中,还引入了主题之间的交互特征.模型框架图如图1 所示.
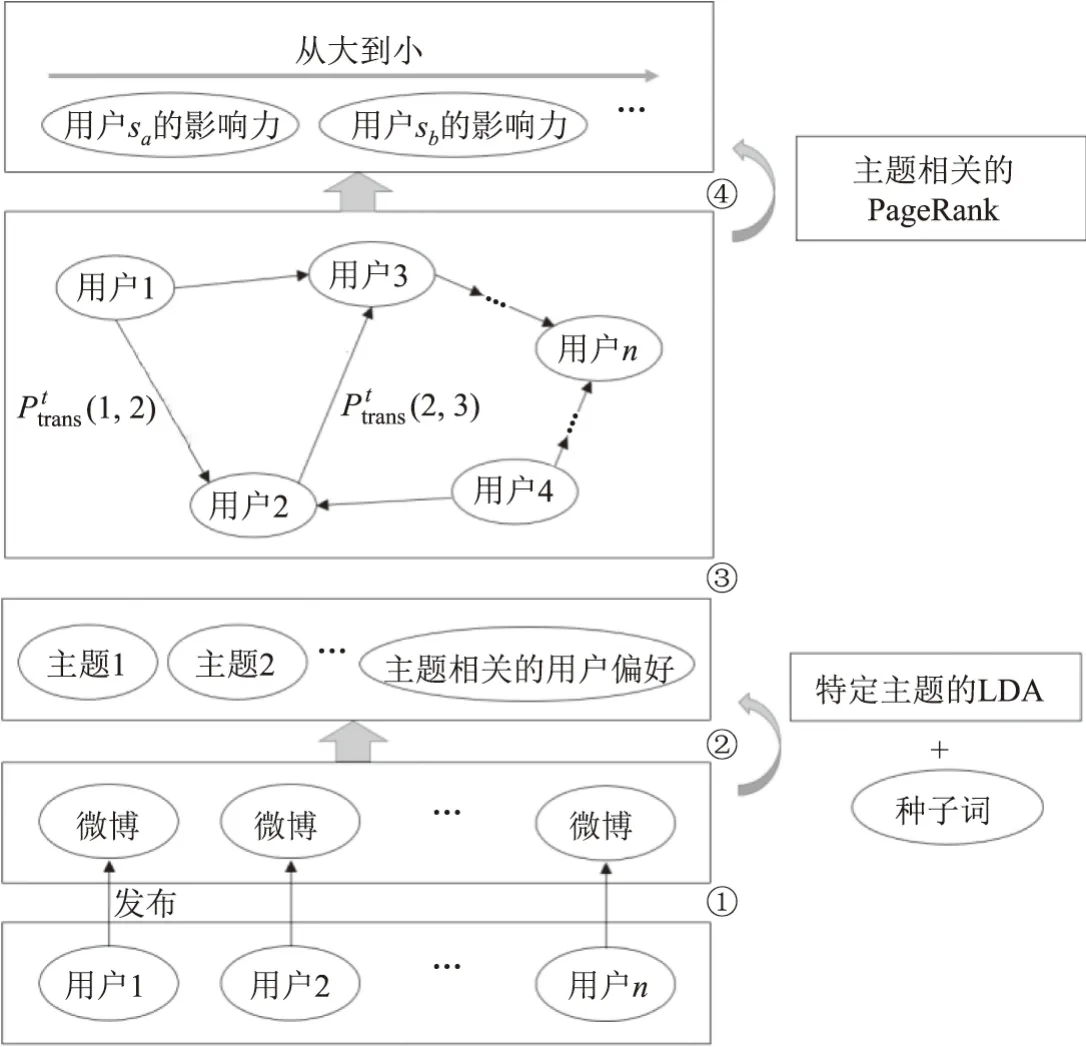
图1 模型框架图Figure 1 Model structure
模型的具体步骤如下:
步骤1获取微博用户发布的所有微博.
步骤2利用特定主题的LDA 模型对用户发布的微博内容进行处理并提取主题,得到用户对主题的兴趣偏好.
步骤3基于用户对主题的兴趣偏好在用户之间构建一个特定主题的关系网络.在不同的主题下,从一个微博用户到另一个微博用户的转移概率也不相同,如图1 中主题t下转移向量和.
步骤4 利用主题相关的PageRank 在特定主题的关系网络中执行随机游走操作,计算得到每一个微博用户的影响力,并对影响力进行排序,得到最终的影响力排名.
2.2 特定主题的LDA 模型
传统主题建模通常是一种无监督学习算法,而且主题通常是难以解释的隐式变量.本文的特定主题是由人工指定的可解释的主题,如“Space”和“Tech”属于不同的主题,且这两个主题是我们关注的重点方向.但是如果这两个方向的文档较少或者两者经常一起出现,则它们可能会被错误地归类为一个主题.
本文引入一种半监督方法用来提取重点关注方向的主题即特定主题分布.在以上案例中,可以为主题“Space”和主题“Tech”分别设置一些种子词集合Sseed1、Sseed2,然后引导模型围绕这些词收敛.这种半监督主题提取方法即为特定主题的LDA 模型[7].
实际上我们希望把“SpaceX”和“NASA”分配给“Space”主题,但若使用传统无监督的LDA 模型处理时,在模型初始化阶段会将文档中包含“SpaceX”和“NASA”在内的所有词随机赋予一个主题编号,然后开始采样迭代,过程如下:利用吉布斯采样公式为文档中的每一个词更新主题编号,直到吉布斯采样收敛为止.最终统计文档中各个词的主题,从而得到该文档的主题分布.由于“SpaceX”和“NASA”通常与“Tech”相关的词同时出现,这两个词被分配给“Tech”主题的概率最大,最终得到的文档主题分布中“Tech”对应主题编号的概率也较高.
特定主题的LDA 模型在初始化阶段做出了改进,首先对文档进行扫描,若当前词为种子词“SpaceX”或“NASA”,则该词被赋予“Space”对应的主题编号的概率将会升高;若当前词不属于种子词集合,则随机赋予一个主题编号.由于种子词被赋予“Space”对应主题编号的概率提高,在吉布斯采样迭代的过程中,种子词更容易收敛到“Space”对应主题编号,从而得到“Space”对应主题编号概率较大的文档主题分布.
控制种子词初始化概率的参数是可调节的,该参数被称为种子置信度Sseed_confidence,其取值范围为[0,1].当Sseed_confidence= 0.1 时,种子词被赋予对应主题编号的概率增加10%.选择一些词作为各目标主题下的初始种子词.在迭代过程中,将有更多词被划分到目标主题,文档主题分布向目标主题收敛,从而引导LDA.
2.3 主题相关的PageRank
微博用户的影响力可以理解为网页的权威性.如果微博用户的粉丝影响力之和较高,那么该用户的影响力也较大.同时,粉丝受此用户的影响占比取决于粉丝关注的其他用户所发布微博的数量与此用户发布数量的比例.
虽然网页的权威性与微博用户的影响有一定的相似之处,但也存在一定差异.用户对每个粉丝的影响不能仅依赖于其发布微博的相对数量,因为即使发布微博的相对数量很大,粉丝也可能对该用户发布的内容不感兴趣.通常每一位微博用户都有独特的兴趣爱好,他们对不同主题的关注度是不一样的,因此在各个主题下的影响力也不同.鉴于此,提出了一个主题相关的PageRank 来衡量微博用户影响力.
微博用户集合Vvertices和用户之间的相互关注关系Eedges构成了有向图Gdirected_gragh(Vvertices,Eedges),其中Vvertices为顶点集,包含数据集中所有的微博用户;Eedges为边集,若两个微博用户之间存在关注关系,则这两个用户之间就存在一条边,且由粉丝指向被关注者.
在社交网络中,采用主题相关的PageRank 模型来计算用户影响力,其过程是随机游走有向图Gdirected_gragh中的边并以一定的概率访问每个微博用户.与传统PageRank 不同,主题相关的PageRank 执行的是主题相关的随机游走操作,从一个微博用户到另一个微博用户的转移概率是特定于主题的.通过主题相关的随机游走,我们在微博用户之间构建了一个特定主题的关系网络.
主题t下用户的转移概率矩阵公式为

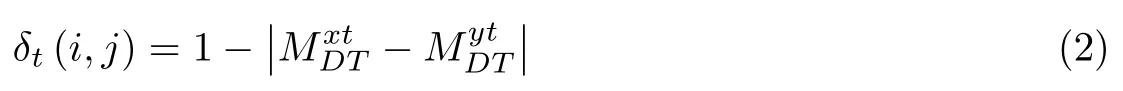
式中,MDT是一个D ×T矩阵,其中D是微博用户的数量,T是主题的数量.为用户si发布的微博中每个词被分配到主题tj的次数.
从式(1)可以看出,给出了两部分:首先,设用户si关注了许多好友,这些被关注者发布不同数量的微博,所有微博都直接对si可见.好友sj发布的微博越多,si读取的微博中来自sj的部分就越多,因而对si的影响就更大,对应si到sj的转移概率也更大.图2 显示了一个转移概率的计算示例.sc关注了分别发布500 和1 000 条微博的sa和sb,此时若不考虑3 个用户之间的主题相似性,sb对sc的影响应该是sa对其影响的两倍.其次,sj对si的影响也与两者的相似性有关.si和sj在主题t上的相似性可以评估为两个微博用户对同一个话题t感兴趣的相似程度,即δt(i,j)的值,两用户的相似性越高,从si到sj的转移概率越高.矩阵MDT的行归一化结果是通过主题提取得到的,的第i行为微博用户sj对不同主题感兴趣的概率.
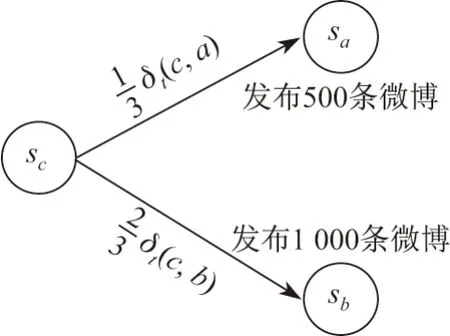
图2 转移概率计算示例Figure 2 Transfer probability calculation example
有些微博用户可能会以一种循环的方式彼此关注,而不关注圈外的其他微博用户.这样的循环会造成影响的积累.为了解决这个问题,引入一个转移向量计算随机跳转到其他微博用户而不是沿着有向图Gdirected_gragh的边移动的概率.主题t中随机跳转的转移向量为

式中,为矩阵MDT的第t列,它是矩阵MDT的列归一化结果.MDT是主题提取的结果矩阵,每一个元素都包含了一个用户发布的微博中每个词被分配到特定主题t的次数.
于是可以计算出用户与主题t相关的PageRank 值公式为
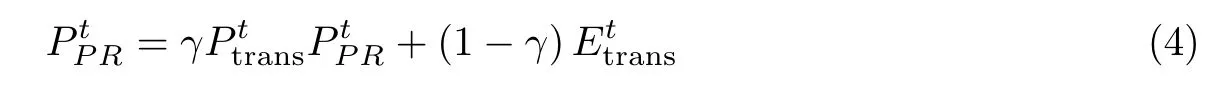
式中,γ是控制跳转概率的参数,取值范围在0∼1 之间.γ越低,随机跳转到其他微博用户的概率就越高,反之亦然.
2.4 基于主题交互的用户相似度计算
受到基于特征交互相似度工作[8]的启发,本文引入主题交互的概念来定义用户之间的相似度.
把发布内容与主题相关的用户组成的一个集合信息表,并用S=< U,A,V >三元组表示.其中U={u1,u2,···,um,···,uM}表示用户集合,M为集合中用户的数目.A={a1,a2,···,an,···,aN}表示N个不同的主题.Vn={v1n,v2n,···,vmn,···,vMn}表示在用户发布的微博内容中主题an的占比,vmn为第m个用户发布的内容与主题an相关的概率.基于特征交互定义,不同主题之间以及不同用户之间都相互影响并存在耦合关系,其耦合关系如图3 所示.
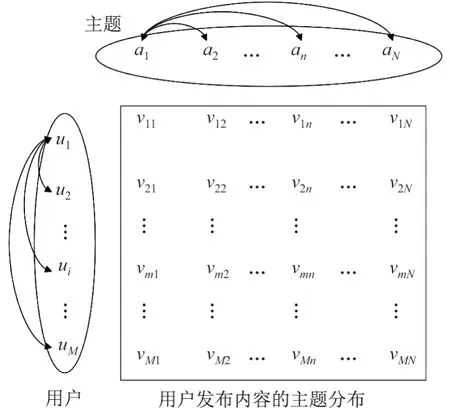
图3 用户主题分布Figure 3 Distribution of user’s topic
2.4.1 主题耦合相似度的定义
不同的主题具有不同的主题词概率分布,概率分布越接近说明两个主题越相似,主题词与主题分布的关系如图4 所示.
两个主题at与an的耦合相似度用δ(t,n)表示,定义为
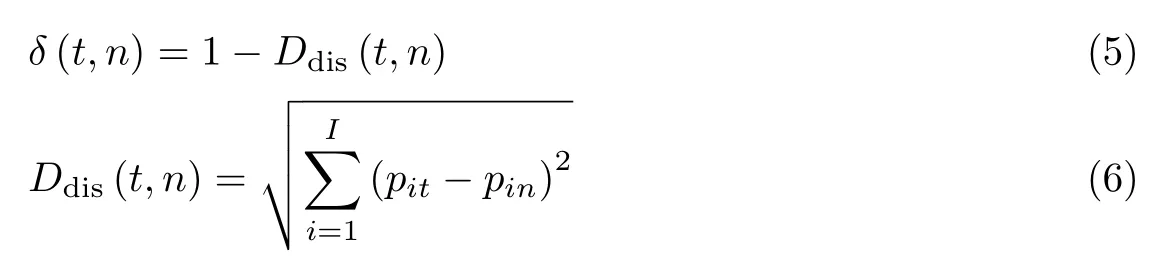
式中,Ddis(t,n)为主题t与n之间的距离,pit为主题t关于第i个主题词的概率分布.
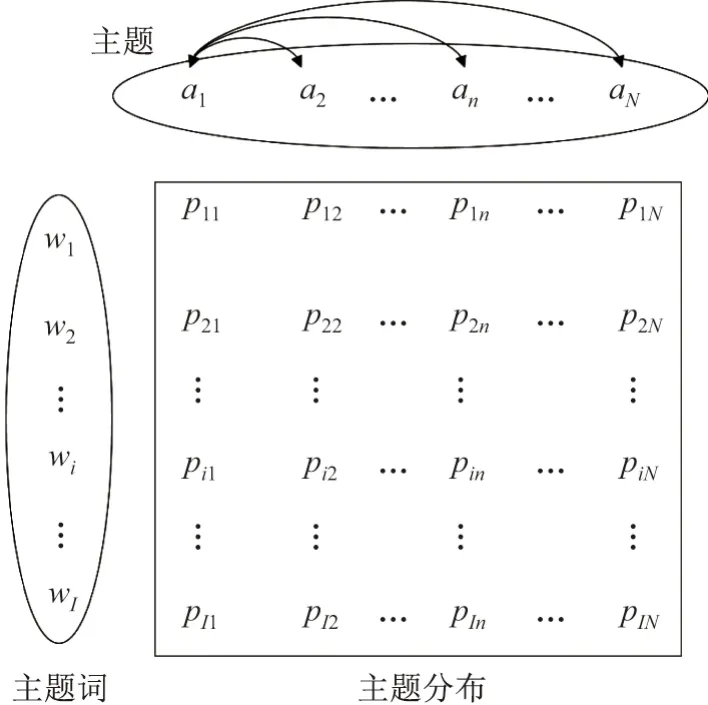
图4 主题耦合关系Figure 4 Coupling relationship between topics
2.4.2 用户耦合相似度的定义
δt(x,y)表示在主题t下的两个用户x,y之间的耦合相似度,它由每一主题n与主题t之间的主题耦合相似度δ(t,n)乘以相似度累加得到,其中的计算方法将在2.5 节中给出,耦合相似度δt(x,y)的计算公式为
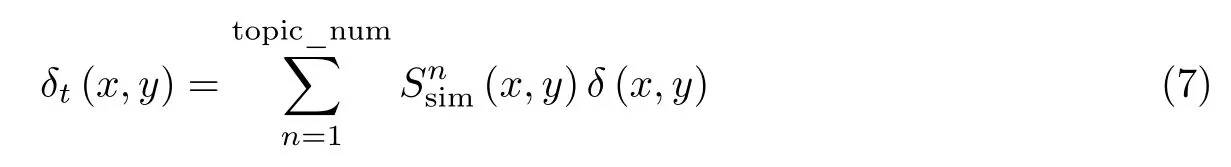
2.5 “逻辑与”式的相似度衡量方法
文献[1]提出了一种的计算公式,为
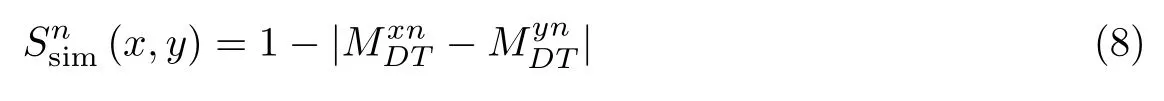
式中,MDT为用户发布微博的主题分布,为用户x发布的微博内容中属于主题n的占比.这种计算方法存在不合理之处,对于存在好友关系的用户x、y,若用户x对主题n不感兴趣,用户y对主题n感兴趣,则x对y在主题n上的影响应该较小,但实验中该影响依然较大;若用户x、y对主题n都不感兴趣,的值会较小且十分接近,从而导致的值也较大,同样也不合理.
为此,本文提出了一种新的计算方法.引入了基于sigmoid 的映射函数
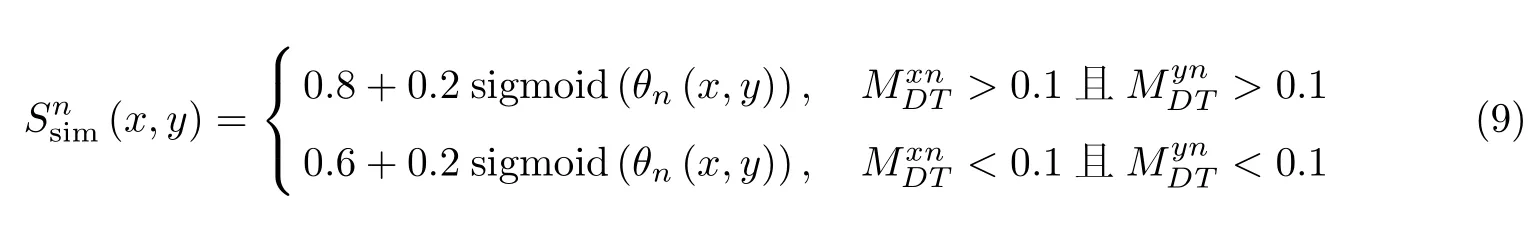
式中,θn(x,y)可通过以下两种方式求得:
第1 种利用差值求取,其公式为
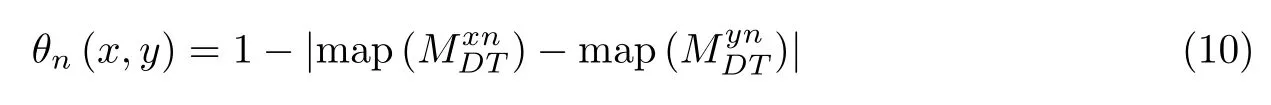
第2 种利用KL 散度求取,其公式为
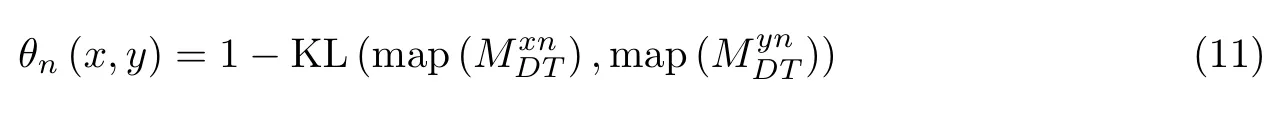
基于sigmoid 的映射函数定义如式(12),其函数图像如图5 所示.

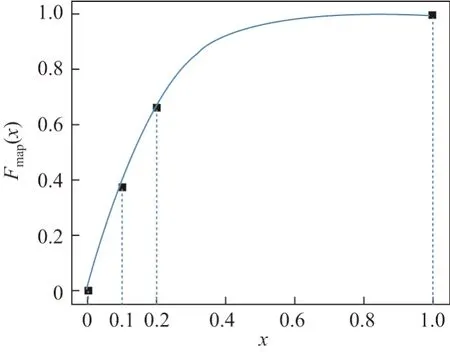
图5 映射函数Fmap(x)图像Figure 5 Image of map function Fmap(x)
由于用户的兴趣被主题模型分为10 个方向,对用户x而言,就能说明x对主题n的关注度是高于均值的.但在衡量相似度的过程中,由于1/10 依旧很小,不能很好地评估用户之间对主题偏好的相似性,因此需要对进行映射.
上述计算方式可以更合理地定义,即当且仅当用户x、y都对主题n感兴趣的情况下,其相似度及相互之间的影响才较大;在其他情况下的值都较小.
3 实 验
3.1 实验设置
3.1.1 数据集
本文使用的数据集是从文献[9]发布的微博数据集中筛选出的5 000 个转发量最大的用户.原数据集是一个由170 万用户组成的关于30 万条微博的转发网络和关注网络.通过实验将PageRank 中控制跳转概率的参数γ值设为0.2,提取的主题数量设为10,LDA 的迭代次数为100 次.在基于特定主题LDA 引导模型中引入9 组种子词,且Sseed_confidence=0.15.
3.1.2 评估指标
为了体现基于特定主题LDA 模型的影响力评估的优势,本文分别利用LDA 和基于特定主题的LDA 模型提取用户主题,将提取到的用户主题分布用于计算用户影响力.采用主题间相似度作为评估指标,并引入人工评估,具体实验过程见3.2 和3.3 节.此外,本文还对主题交互的用户相似度计算和影响力评估进行了实验分析,分别参见3.3 及3.4 节.
3.2 基于特定主题LDA 模型的影响力评估
本文的迭代过程为:先筛选种子词,再基于种子词提取主题分布,最后根据分布高频词优化种子词.考虑到存在一些未知的方向,选出9 个方向的种子词,包括体育奥运、星座恋爱、微博相关、明星娱乐、生活、金融、IT、政策、社会民生;第10 个方向不设种子词,设为“其他”.
从实验结果可以看出,传统的LDA 无法区分开星座和娱乐明星(Topic 10)等方向,有的主题方向相近,如主题1 和5 都与微博相关,主题3、4、7、9 都与社会民生有关.而topicspecific LDA 模型的提取效果却十分明显,大部分主题与种子词相关性强:主题1(体育奥运)、主题2(星座恋爱)、主题3(生活)、主题4(微博相关)、主题5(政策)、主题7(明星娱乐)、主题8(社会民生),难以分辨部分主题的类别有主题6、7、9、10.此外,由于与金融、IT 主题相关的种子词较少,并没有明显与这两个方向相关的主题.
通过计算每一主题下100 个高频词的词概率分布与其他主题的KL 散度,衡量所提取到的主题与主题之间的相似度,以此定义主题相似性.将特定主题LDA 的主题间相似性与LDA 进行比较,如表1 和2 所示,可以看出LDA 主题之间的差异性较大,主题分布更随机.而特定主题的LDA 引入种子词后更贴近真实情况,随机性也更小.
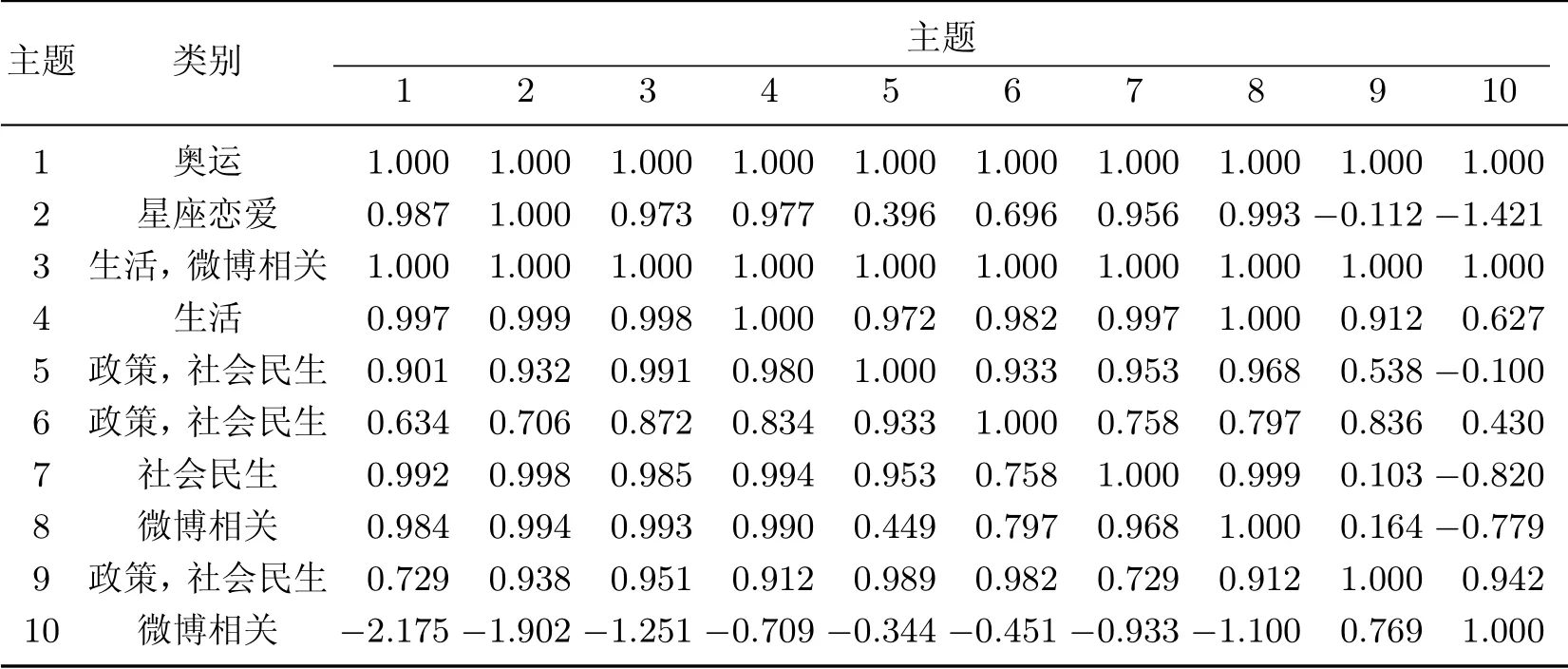
表1 LDA 的主题间相似性Table 1 Similarities between LDA topics

表2 特定主题LDA 的主题间相似性Table 2 Similarities between topic-specific LDA topics
此外,本文还比较了TwitterLDA 和特定主题的LDA.可以看出,TwitterLDA 无法区分体育奥运和娱乐明星(主题9),主题3、5、7、10 都与社会民生有关,主题5、7、8 都与政策相关,主题1 无明显方向.特定主题的LDA 优于TwitterLDA.
分别依赖LDA 和特定主题的LDA 两种主题提取方法计算用户影响力,LDA 和特定主题的LDA 分别在每个主题下计算得到的影响力最大的用户ID 及其相关信息如表3 和4 所示.
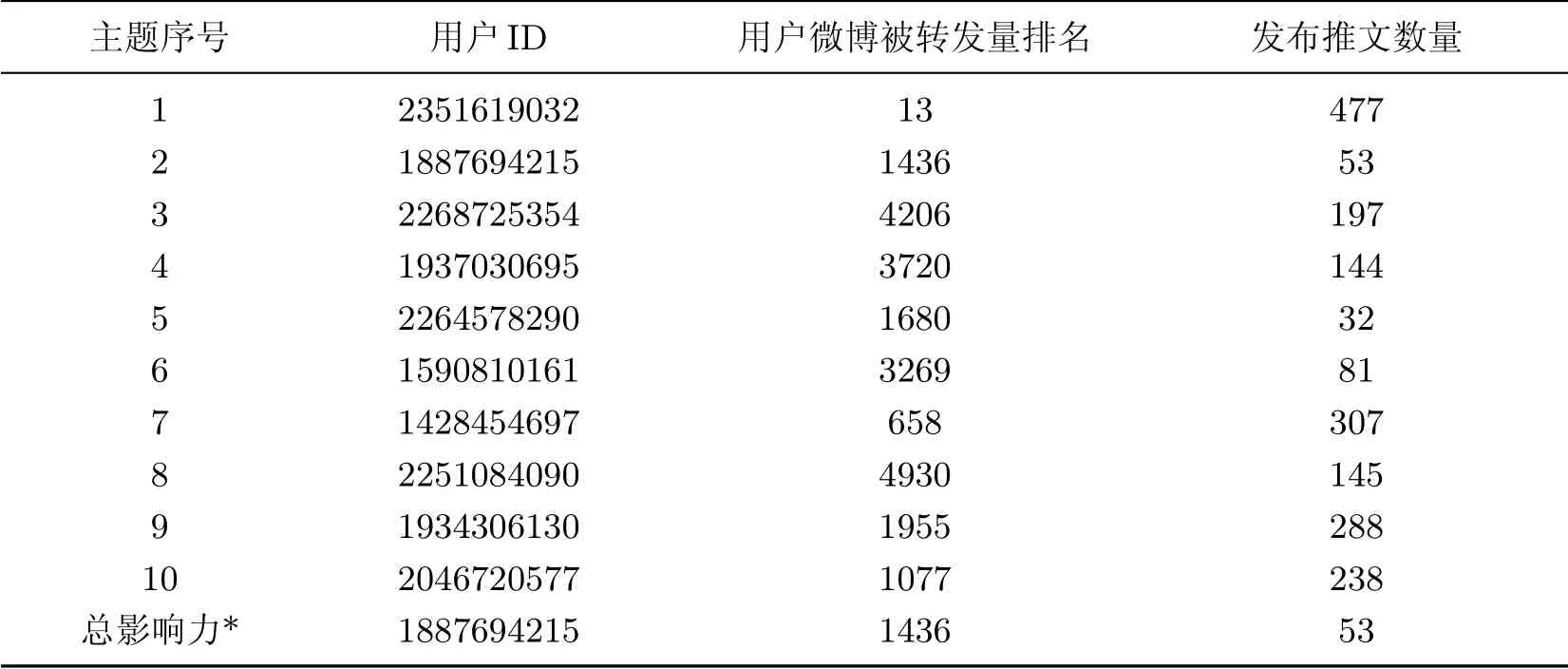
表3 LDA 影响力计算结果Table 3 Influence results calculated by LDA
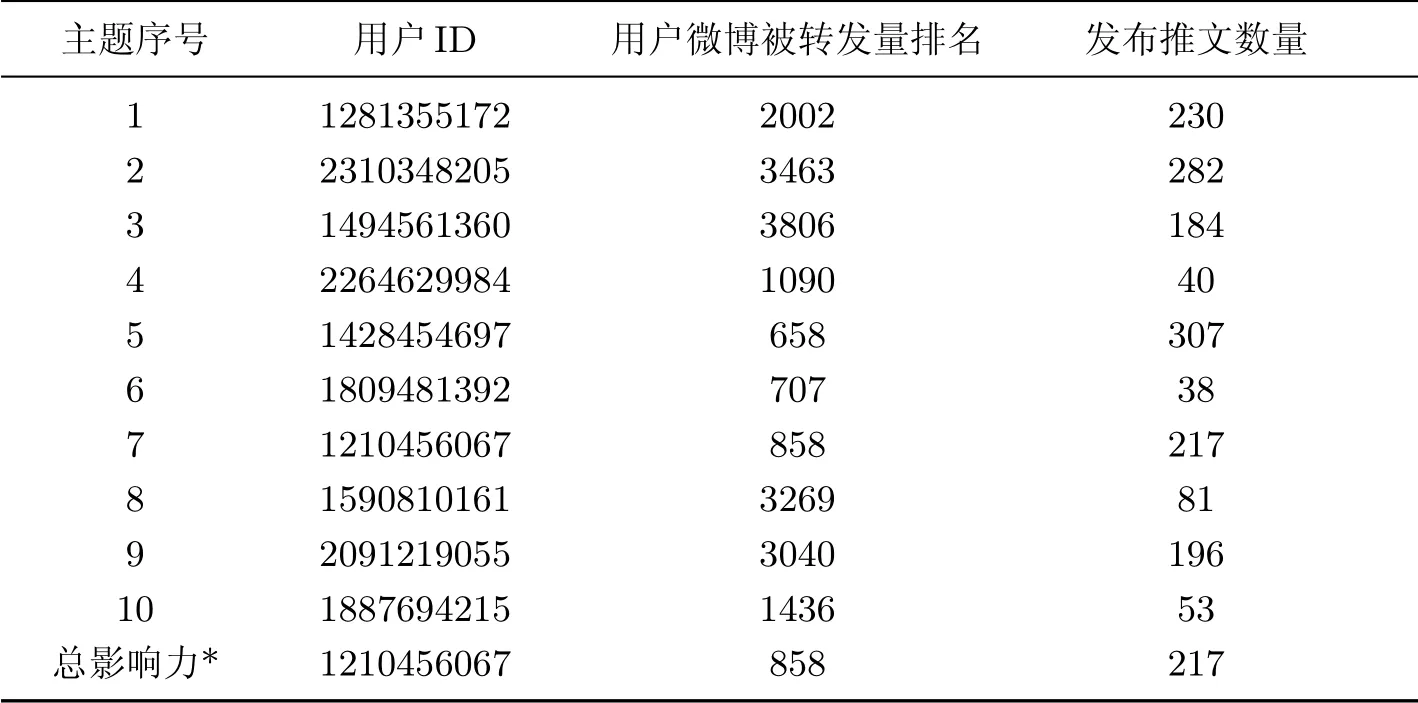
表4 特定主题的LDA 影响力计算结果Table 4 Influence results calculated by topic-specific LDA
假设我们对奥运相关内容感兴趣,topic-specific LDA 中奥运相关的主题为Topic 7,影响力最大的用户ID 为1281355172,而LDA 中与奥运主题最相近的是Topic 10,影响力最大的用户ID 为2251084090,这两个用户发布的微博词汇中奥运相关高频词所占比例分别为82.700%、71.922%.由此可见,引入topic-specific LDA 后,目标主题上的用户影响力评估更为准确.
3.3 主题交互的用户相似度计算和影响力评估
从3.2 节的实验可看出,即便引入了种子词,也存在难以区分提取出的主题是哪一个方向主题的现象.从提取到的高频主题词中可以看出,主题6、7、9、10 有极相似的部分,它们之间相互影响,不能将不同主题下的影响力评估割裂来看.每一主题下100 个高频词的词概率与其他主题相比较,得到的主题相似度如表5 所示;添加主题交互和无主题交互时,各主题下影响力最大的用户ID 及其相关信息如表6 和7 所示.

表5 特定主题LDA 的主题相似性Table 5 Topic similarity of topic-specific LDA
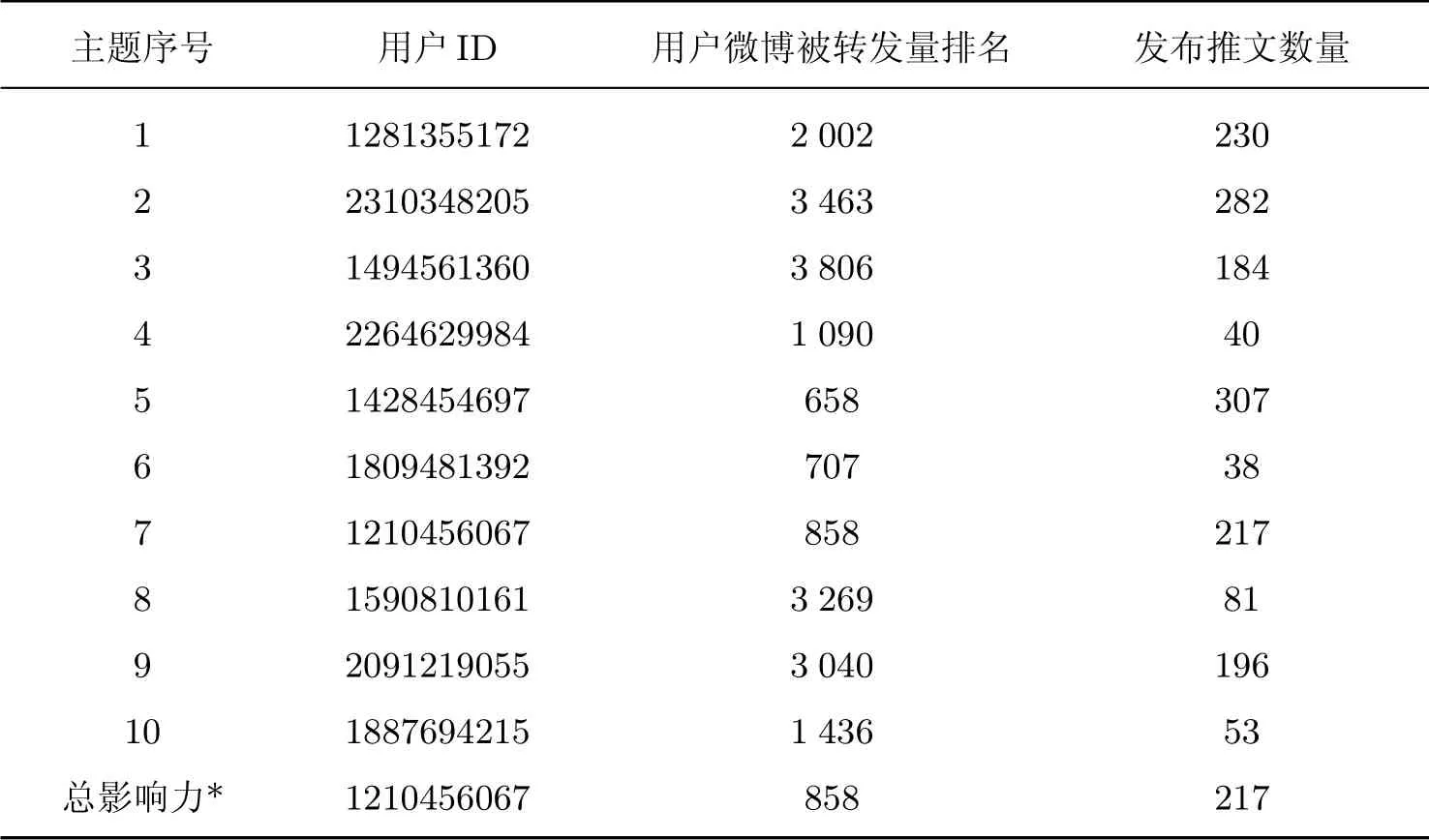
表6 添加主题交互时,各主题下影响力最大的用户ID 及其相关信息Table 6 The most influential user ID and related information with topic-interaction
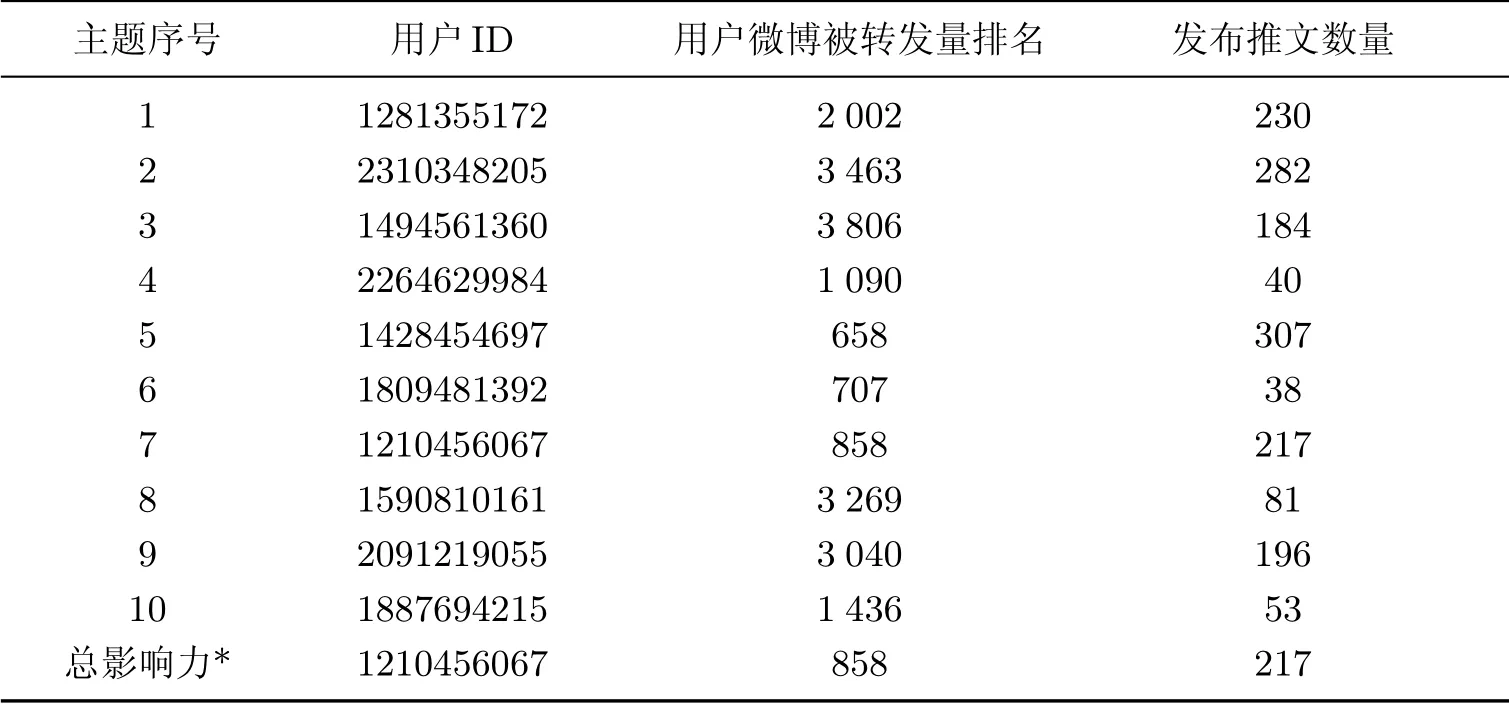
表7 无主题交互时,各主题下影响力最大的用户ID 及其相关信息Table 7 The most influential user ID and related information without topic-interaction
显然,添加主题交互与无主题交互实验所得的影响力最大的用户完全一致.但两者对所有用户的影响力排名依然存在差异.在主题1 下计算用户影响力并排序,影响力最大的前20 位用户如表8 所示.
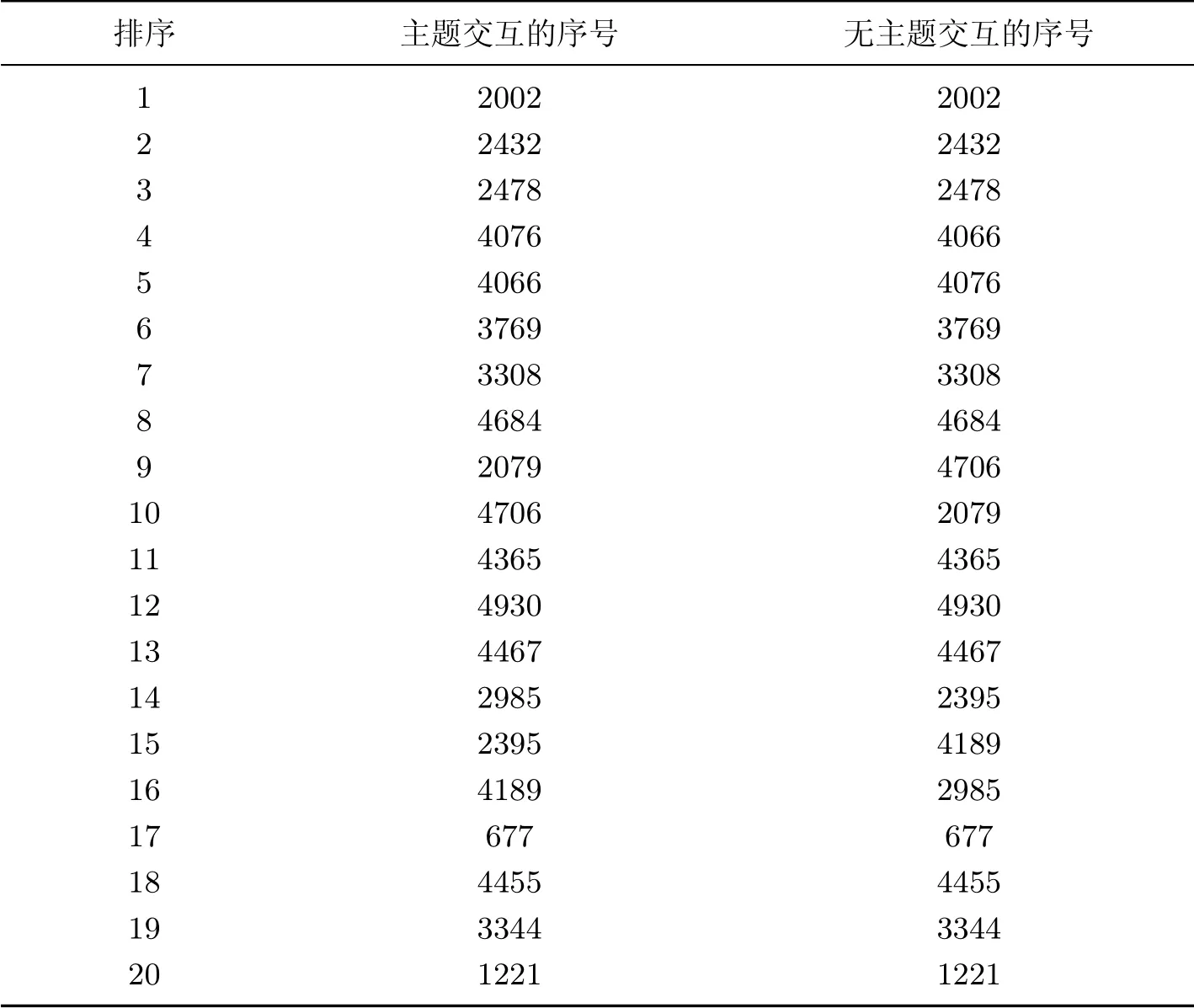
表8 基于主题交互的用户影响力排序Table 8 User influence ranking based on topic-interaction
此处的用户用序号表示.针对序号为2079 和4706 的两位用户,基于无特征交互实验时在主题1 中用户4706 的影响力大于用户2079.两位用户在其他主题下的影响力排名如表9 所示.
显然,用户2079 的总影响力排名比用户4706 高得多,并且主题1 与其他主题的相似度极高,在加入主题的特征交互后,2079 在主题1 中的排名受到了其他主题下的用户偏好与用户相似度的影响,在主题1 中的排名也比4706 靠前.
此外用户2079 与4706 发布的微博内容中属于奥运相关高频词的词汇所占比例分别为71.630%,68.198%,可以看出用户2079 对主题1 更感兴趣,这也与本文实验结果相吻合.

表9 用户2079 和用户4706 在各个主题下的影响力排名Table 9 Influence ranking of user 2079 and user 4706 under each topic
3.4 用户相似度分析
通过TwitterRank[1]给出的方法计算得到的用户间相似度如表10 所示,表中的x和y为用户序号,分别为用户x和y发布的微博词属于主题n的概率.
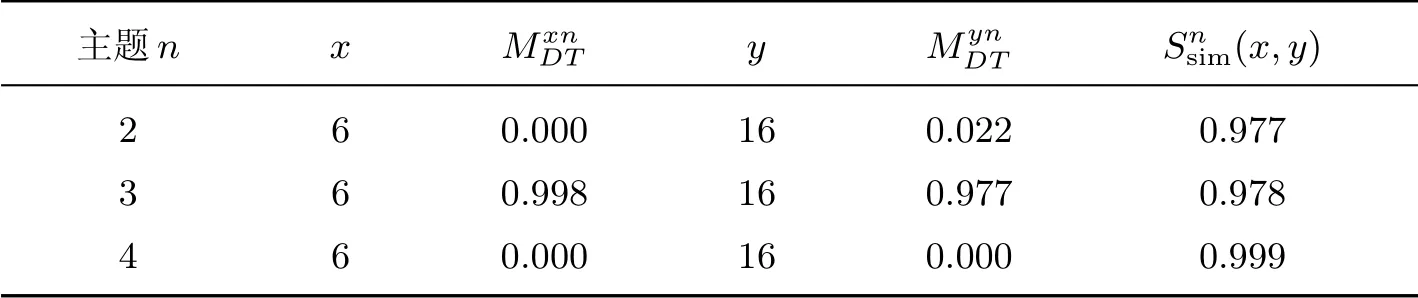
表10 利用式(8)计算出的用户相似度Table 10 User similarity calculated by formula (8)
从表10 可以看出,将差值直接作为用户之间的差异是不合理的.在x和y都对主题很感兴趣(即都很大)的情况下求得的相似性却比在x和y都对主题不感兴趣情况下的相似性低.
为了解决这个问题,本文提出了一种“逻辑与”式的相似度衡量方法,计算得到新的相似度如表11 所示.可以看出,新的方法计算得到的结果满足我们对差异性的要求.

表11 利用“逻辑与”的相似度衡量方法计算出的用户相似度Table 11 User similarity calculated by the similarity measurement method of “Logic AND”
4 结 语
本文提出了一种面向特定主题的社交网络影响力评估方法.通过引入种子词来引导主题模型提取目标方向的主题并计算用户在目标主题下的影响力.利用基于特征交互的主题耦合相似度的计算方法,改进了传统基于主题的影响力评估忽略了主题与主题之间交互的缺陷,并将其应用到用户相似度的计算中,以改善用户关系网络的构建.此外,还对主题相关的PageRank 中衡量用户之间相似度的参数计算方法进行改进,保证只有在两个用户都对主题感兴趣的情况下用户相似度才会较高,用户之间影响力才能较大.
经过实验与样例分析,本文提出的方法在特定主题下的影响力评估、主题特征交互下的影响力评估中的表现优于已有的方法.因此,本文的方法是可行且高效的.
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05 06:49:10
中学生数理化·中考版(2021年6期)2021-11-22 07:52:30
新世纪智能(数学备考)(2021年4期)2021-08-06 09:04:50
新世纪智能(数学备考)(2021年4期)2021-08-06 09:04:50
儿童时代·幸福宝宝(2019年9期)2019-10-28 18:04:52
幼儿园(2018年15期)2018-10-15 19:40:36
NBA特刊(2018年14期)2018-08-13 08:51:40
莫愁·家教与成才(2017年7期)2017-07-11 21:31:47
人大建设(2017年11期)2017-04-20 08:22:49
瞭望东方周刊(2015年12期)2015-04-14 23:28:02
