
基于改进Ising模型的心理量表大数据分析
2020-06-13 07:11姚汝婧胡应鑫
应用科学学报 2020年3期
姚汝婧, 杨 磊, 杨 涛, 胡应鑫, 田 强, 吴 偶
1.天津大学应用数学中心,天津300072
2.杭州知乎者也科技有限公司教育大数据研发中心,杭州310008
3.天津师范大学计算机学院,天津300387
随着网络时代的到来,社会个体成员之间的相互影响容易被渗透与放大.心理健康问题也成为个体、团队乃至整个社会不可忽视的重要问题.社会个体的心理特征会影响其自身外在情绪与行为,进而影响到所在的社交团队和整个社会.不健康的心理状态极容易受到外在因素的影响,而且因不健康心理导致的不良甚至极端的行为又会对群体以及社会造成恶劣的后果.因此,更好地感知个体的心理并准确地把握个体的心理状态与特征对于提升个体的心理健康水平及维护社会的稳定具有极其重要的意义.
自评量表是测量个体心理状态的最主要工具[1],它能够比较准确地获取被测试个体在设定问题维度上的心理特征[2].早期受限于各种信息化手段,参与量表的个体数量通常比较少,一般属于几百以内的规模,这就限制了完全依赖数据层次进行深度分析的可行性.于是传统的分析方法一般是由心理学家事先定义好一些综合度量维度,从而获取被测个体更高层次的心理属性.
随着信息技术的普及以及心理健康问题越来越受到各种组织、管理者以及社会公众的重视,参与自评量表的用户越来越多,已经超过了上万的规模.与原来的几十或者几百个用户样本相比,现有的数据已经逐步变成了量表大数据.因此也需要引入更多的数据挖掘与大数据技术来对心理量表大数据进行更好地分析.
于是,研究者们开始利用统计相关性或者Ising 模型[3]来构建每个量表问题之间反映心理特性的复杂网络,然后分析网络的结构与重要节点.这种分析方式能够提供更多的分析维度,得到更多的结论,为后续的心理评价与介入提供更多的帮助.但是,现有的Ising 模型仅能处理答案为二值类别的问题,也就是说,如果量表问题答案的类别数量大于2,那么需要人为映射到2 个类别,然后运行Ising 模型.这种方式容易造成信息的大量丢失.本文根据机器学习模型,针对现有Ising 模型只能处理二值类别的缺陷,提出多类Ising 模型,针对心理量表里面的答案通常是以等级的方式出现的情况,提出了序Ising 模型,使改进后的模型更加适合于实际量表数据的分析和处理.最后,在一个大型的心理量表数据上进行分析,并且根据构建的心理特性复杂网络来计算关键性心理特征以及不同人群的网络差异.
1 相关工作
对个体的心理特征或者状态进行量化研究一直是心理学研究领域的热点问题.特别是随着心理健康意识的持续提升,获取较大规模的心理数据已经成为了现实.在这种情况下,基于大规模心理数据的挖掘成为了心理学以及相关研究领域的重要量化研究手段.现有的研究主要分为以下两个方面.
1)基于社交媒体数据的心理分析.社交媒体指对用户链接关系的内容进行生产与交换的网络平台.智能手机以及新一代网络技术的发展,使微博、微信等常用社交媒体成为民众分享意见、见解、经验和观点的最主要工具和平台[4].由于每一个社交媒体节点均为一个个体,一个社交媒体节点内容与行为信息很大程度上也是该个体的内在心理反映[5].例如研究者发现社交网络重度用户患抑郁症的几率为普通用户的3 倍[6].因此,很多研究者利用这些数据来对用户心理进行分析[7-12].文献[1]通过分析用户的微博数据建立心理计算模型(包括心理健康状态计算模型与主观幸福感计算模型),实验结果显示该心理计算模型的建模效果良好.通过分析网络数据来计算民众的心理特征,有利于改善心理测验的实施规模与施测效率.文献[12]利用机器学习技术识别出抑郁症的标志,并使用颜色分析和面部检测等算法,计算社交网站的4 000 多幅图片的统计特征,包括色调、亮度以及滤镜等.研究发现抑郁症患者在社交媒体发布照片时,更倾向于应用冷色调、褪色或黑白滤镜,由此表明社交网络照片可以用来判断个体是否患有抑郁症.尽管基于社交媒体数据的心理分析开辟了心理量化研究的新途径,但也存在较大的缺陷.当需要研究某给定人群(例如一所大学的大一新生)的时候,该特点人群很可能拒绝公开其社交媒体账号.此外,本项研究还存在着统计偏差,即许多用户并不会热衷于在社交媒体上发表见解,甚至不会在上面有任何的行为,对于这些人便难以进行有效分析.
2)基于用户量表数据的心理分析.与基于社交媒体数据的心理分析相比,通过用户填写量表数据来对用户进行心理状态分析更容易在给定的人群上进行操作.由于心理量表本身就是由心理学家精心设计,通过这种方式得到数据的质量较高,对其深入分析挖掘的结果可以为心理评估与心理咨询等提供更多的支撑.因此,基于用户量表数据的心理分析仍旧是现阶段心理量化研究的主要手段[13-14].近年来,基于用户量表数据来构建一个复杂网络可以更好地理解不同心理特征(即问题)的关联性.定位关键性心理特征是一个非常有潜力的技术,该技术能够提供比常规方法更多的数据视角[15].文献[16]选取了约300 人的群体研究丧失配偶与心理状态(特别是抑郁症)之间的关系.所研究的对象均有过丧失配偶的事件发生,在群体填写完专门的心理量表问卷之后,用Ising 模型来构建不同行为状态之间的复杂网络,并且着重分析了不同人口统计学的群体网络差异以及哪些因素与抑郁症有更紧密的关联.结果发现“孤独”这一心理状态发挥了关键作用:丧亲主要影响孤独感,反过来激活其他抑郁症状.文献[17]获取了包括1 409 个年龄介于13∼19 岁青少年的心理量表数据,通过网络分析来挖掘中心节点以及各个节点与抑郁症之间的关系.结果显示,所构建的网络的中心节点包括自我憎恨、孤独、伤心与压力.在对青少年的抑郁症状进行干涉的时候,需要重点关注上述4 个节点对应的状态.
尽管量表问题的答案很少为二等级的选项,但是心理学领域学者受限于大数据分析的手段,所采用的Ising 模型只能处理二类分类问题.所以现有的研究一般都需要把三等级或者五等级的选项首先映射到二等级.例如将“很少”,“一般”,“经常”中的“很少”映射为0,将“一般”和“经常”映射为1.这显然是很不合理的,因为“一般”和“经常”的语义差别非常明显.为此,本文将Ising 模型拓展到多类Ising 模型和序Ising 模型,使改进后的模型更加适合于上述分析与处理.
2 Ising 模型及其改进模型
2.1 Ising 模型
Ising 模型[18-19]处理的是一组二值随机变量.不失一般性,假定有n个随机变量构成的向量,记为x={x1,x2,··· ,xn}, 其中xi的取值为0 或者1.Ising 模型通过构建如下的预测函数来得到其中任意一个变量xi与所有其他变量xi之间的关联:

式中,Vi表示除i外其他所有变量的集合;wij和bi为模型参数,wij刻画了变量j对i的作用.图1 展示了变量xi与所有其他变量xi之间的关联.
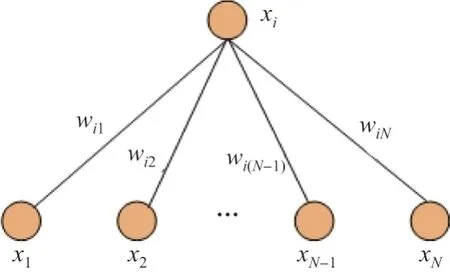
图1 xi 与xi 之间的关联Figure 1 Association between variable xi and xi
式(1)中所有变量的取值范围为{0, 1}.依次将n个变量中的每个变量作为标签,其余变量作为特征变量,就可以得到任意两个变量i和j之间的关系参数wij和wji.其优化目标函数为
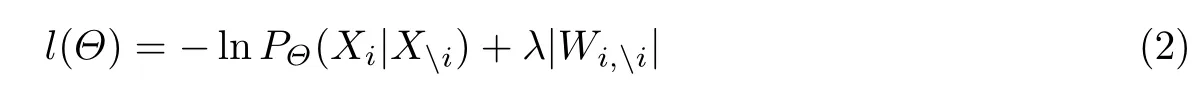
式中,Xi为用户在第i个变量上的取值,Xi为用户在除变量i外所有变量上的取值,后面的正则化项为1-范约束,能够起到特征选择的作用.假定总共有K个用户,那么式(2)可写为
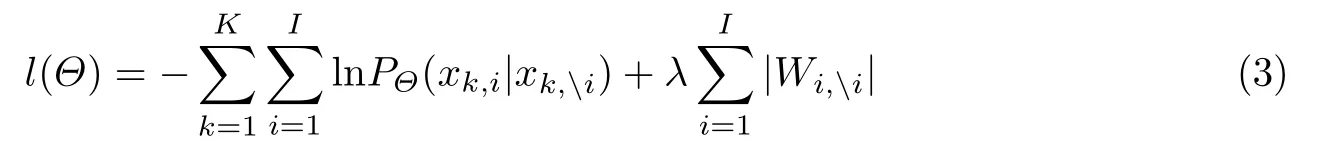
式中,xk,i为第k个用户在第i个变量上的取值,xki为第k个用户在除第i个变量之外的其他所有变量上的取值.
得到了K个用户的所有量表数据后,将每个量表问题的答案转化为二级选项(即0/1),然后对式(3)定义的目标函数进行优化,便可以得到任意两个节点之间的关系wij和wji,进而求均值,公式为

可以看到,Ising 模型只能处理二级选项,而心理量表在多数情况下包含三级、五级甚至更多级的选项.
2.2 多类Ising 模型
式(1)是一个二类分类模型,需要扩展到多分类模型.将式(1)改写为
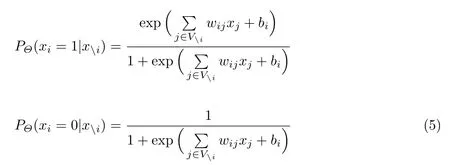
从式(5)可以看出,Ising 模型实际上是基于二类Logistic 回归的模型.于是本文利用多类的Logistic 回归来替代Ising 模型的二类Logistic 回归.
多类分类的思想一般就是将问题分解成多个二类分类问题.假定类别数为C,则利用多类Logistic 回归可使每两个变量得到2C个模型.两个节点最终的链接权重为

式中,表示以i为标签时第c个模型中两个变量的参数.
2.3 序Ising 模型
多类Ising 模型直接将三选项或者五选项量表问题中的不同选项当作不同的类别,虽然有一定意义,但是它忽略了实际量表选项中大多存在序等级的情况.例如下面是两个代表性的量表问题及选项:
Q1:你经常感觉到开心吗?
选项:从不;很少;一般;很多;一直
Q2:你是否经常运动?
选项:从不;比较少;一般;经常;非常频繁
可以看到,在Q1 里面,假定一个用户的回答是“从不”,那么算法预测出“很少”和“很多”这两个结果在目前的多分类Ising 模型里面,分类错误率都是一样的.但是实际上,预测出“很少”这个结果比预测出“很多”明显更接近于真实答案“从不”,其背后原因在于几个答案选项不是目录类型,而是等级类型.而量表问题的答案选项绝大多数均为上述等级类型,那么理论上将答案的选项完成看成是目录型的类别是不太合适的.
为此,本文引入排序学习来对原始的Ising 模型进行改进,新的模型称被为序Ising 模型.假定序等级为C,那么序Ising 模型实际上是由C −1 个二类Ising 模型构成的,也即将序Ising 模型的学习问题拆分成C −1 个二类Ising 模型学习问题.假定序等级记为1,2,···,C.则第c个二类模型学习的优化目标函数为
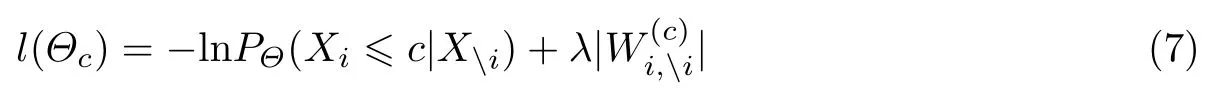
从式(7)可以看到,第c个二类问题实际上是将原始的多个序等级分类问题转化为小于等于c以及大于c的二分类问题.
因此,总的优化目标函数定义为
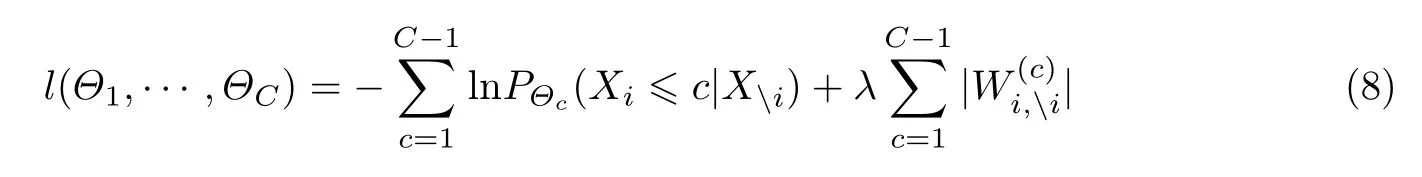
依据式(8),假定一个用户在图中的Q1 上选“很少”这一选项,若总的模型输出为“一直”,则在4 个模型上的总误差为3;如果总的模型输出为“一般”,那么在4 个模型上的总误差为1.这说明上述序模型能够捕捉到序等级之间的关联与差异,与单纯的多类模型相比,预测损失更为合理.
与多类Ising 模型类似,序Ising 模型同样产生多个模型,计算最终两个节点的关联权重亦如式(6)所示.
3 基于改进模型的心理特性网络构建与分析
利用2.2 和2.3 节中提出的多分类Ising 模型或者序Ising 模型得到任意两个节点(一个节点对应着心理量表汇总的一个问题)的关联系数之后,便可以构建一个心理特性网络.
为了达到较好的可视化效果,且避免一些关系不紧密的连接影响整体的分析,将设定阈值来过滤掉一些关系连接不紧密的边,保留关系紧密的边,这样就形成了一个以问题为节点的网络图.
本文将在构建的网络图基础上进行如下分析.
1)节点强度:节点强度的值为与节点相连的所有边权值之和,其计算公式为

式中,M(v)为与节点v相连接的节点集合,wvi为节点v与i之间的边的权值.
2)紧密中心性:从该节点到网络中其他所有节点最短距离的平均数的倒数,其计算公式为

式中,dvi为v到节点i的最短距离,n为节点数量.
3)介数中心性:在所有最短路径中经过该节点的路径数量占最短路径总数的比例,其计算公式为

式中,s,v,t都属于V,V是所有节点的集合,σst(v) 为经过节点v的s到t的最短路径数量,st为节点s到t的所有最短路径的数量.
4)结构相似性:本文定义了一种基于邻域相似性的图结构相似性度量,其计算公式为
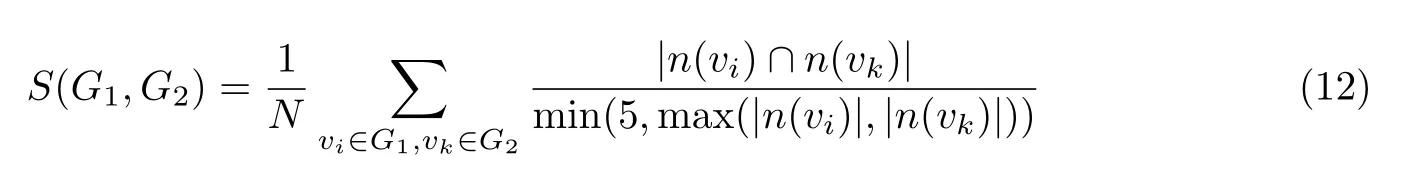
式中,n(vi)表示vi节点的邻域节点集,本文考虑5 近邻邻域.
为了比较不同心理人群的心理特性是否存在着明显差异,本文分别利用不同心理人群的量表数据来训练各个人群对应的心理特性网络.通过衡量网络的相似性分析比较人员的心理.网络相似性主要体现在结构相似性、中心节点一致性两个方面.
4 实验数据
本文的实验数据来源于心理测量学数据汇集网站https://openpsychometrics.org.所选取的BIG5 英文数据集中的数据都基于标准的大五人格量表,包含了50 个问题,总共有19 719份问卷.此外还有相关的人口统计学特征,包括国籍、性别、年龄、种族、母语等,这些人口统计学特征有助于进行不同群体之间的心理特性差异性分析.
为了防止用户随意答题而带来有噪声甚至错误的数据,设计了一些关联性非常高的题目,例如图2 所示的2 对题目的关联性极高.
人为挑选了15 对题目,并且根据15 对题目的答案一致性对每份问卷进行打分,一致的加1分,15 对题目全一致的为15 分.分数越高,反映个体答题的质量可能越高.图3 显示了得到不同分数的问卷样本的数量及比例.可以看到,完全通过15 对题目的样本只有693 个.

图2 两对用于质量校验的量表问题Figure 2 Two pairs of scale questions for quality verification
为保证数据质量只选取得分大于10 的问卷样本,最终得到的有效问卷为13 278 份.随后对15 对高相关性的题目对进行了合并,最终留下了41 道题目.
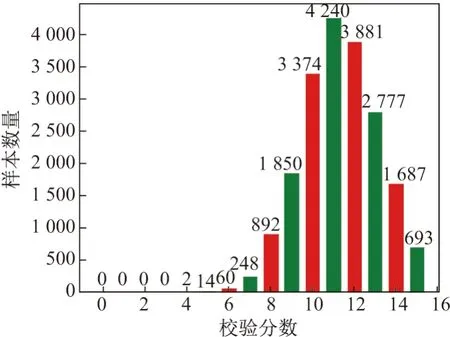
图3 不同校验分数上的样本数分布Figure 3 Distribution of sample numbers on different verification scores
5 实验与结果
5.1 实验设计
本研究的实验设计如下:
1)两个改进Ising 算法的比较,包括多类Ising 算法和序Ising 算法.将从3 个方面进行比较:分类准确率、序正确率和相关度准确率.其中分类准确率为常规的分类准确率.序正确率Arank的计算公式为

相关度准确率Arelevancy的计算公式为
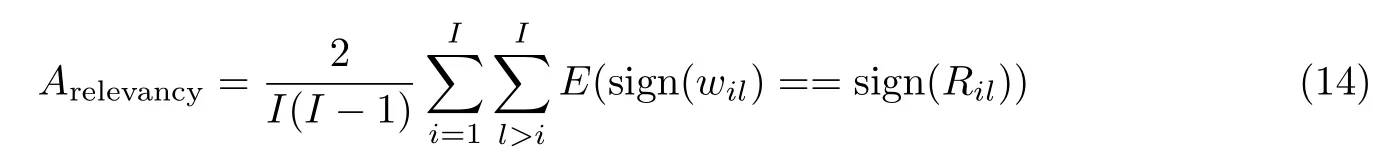
式中,当sign(wil)==sign(Ril)成立的时候,E()取值为1,否则为0.sign 为符号函数,Ril为基于统计的相关性系数.
2)利用整体的数据(除人口统计学数据外)进行模型训练并得到一个复杂网络,进而计算中心、结构差异,得出结论.
3)选取两个维度(年龄、性别)来比较不同人群所对应的心理复杂网络的差异性,并计算中心、结构差异等来量化不同人群的心理状态区别.
5.2 改进算法比较
原始的Ising 算法只能处理二类分类问题,不适用于本实验数据.实验l1-norm 正则化的超参数的选择范围为{0.01, 0.1, 1, 10, 100}.选用5 份交叉验证,在每个验证集上分别计算分类准确率、序正确率和相关度准确率.求平均之后,结果如表1 所示.
可以看到尽管在分类准确率和序准确率上,两个算法的性能差不多,但是在相关度准确率上,序Ising 的效果明显好于多类Ising.因此,在后续的分析中将选用序Ising 模型来构建心理复杂网络.

表1 两种改进模型在3 个维度上的准确性Table 1 Accuracy of two improved models in three dimensions %
5.3 整体网络分析结果
基于全部13 278 个量表样本数据构建的心理特性网络如图4 所示,其中包括了41 个节点,每个节点的字符串为原始题的缩写.绿色表示关联系数为正,红色表示关联系数为负.对照表见附录A1.
取前15 个最主要链接,如图5 所示.可以看到最紧密的两个节点是“Blue”和“Conv”,并且呈现正相关性.其中“Blue”节点的问题是“我很少感觉忧郁”,而“Conv”节点的问题是“我开始交谈”.两者的强正关联也说明了对外交流对于减少忧郁是很有帮助的.最负相关的为“Order”和“Belong”, 前者对应的问题是“我喜欢有秩序”,后者的问题是“我把我的东西放在附近”.两者确实存在着一定的负相关.
考虑到篇幅,我们对于整体网络计算的各个节点(问题)紧密中心性、介数中心性和节点强度的结果不再赘述.这3 个指标的对比将在下一节中进行讨论.
5.4 不同群体网络分析结果
本节进行两个对比性分析.
第1 个对比性分析选取了男性和女性2 个类别,分别构建网络.图6 给出了男性和女性在节点强度、紧密中心性和介数中心性上的对比结果.可以看到男性和女性在节点强度上非常一致.强度最大的3 个节点分别是“TaPar”“Stre”和“Chore”.3 个节点对应的问题分别是社交、压力感知以及勤做家务3 个方面,这与实际也是相符的.压力感知是心理状态非常重要的方面,而社交与家务分别代表个体对外和对内的主要表现.但是男女性在中心性上有着显著的差别.其中,第16 个节点(“Insu”)在紧密中心性和介数中心性上差距非常大,该节点对应的问题是“我侮辱别人(I insult people)”.这说明男性更倾向于有这种行为,男性与女性在对他人的文明方面差别非常大;在第26 个节点(“Mess”)上,差距也非常大.该节点对应的问题是“我把事情搞得一团糟(I make a mess of things)”.这说明男性更容易因为事情不顺利而影响各种其他的心理状态.本文计算了两个网络的结构相似性,其值为0.86.
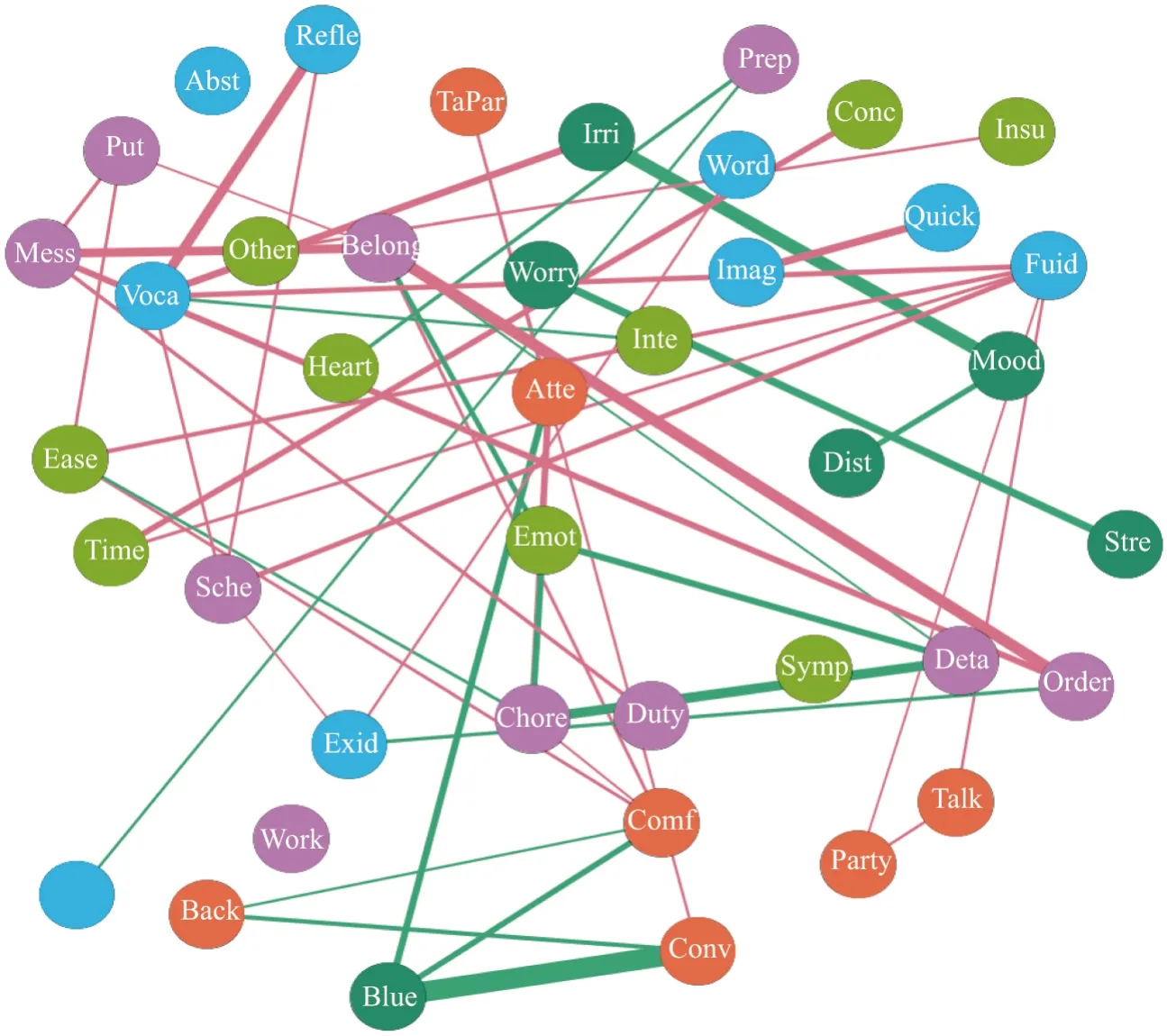
图4 全体样本数据构建的心理特性网络Figure 4 Psychological network constructed by the whole samples

图5 前15 个最主要链接构建的心理特性网络Figure 5 Psychological network only with the top 15 main links

图6 男性女性在3 个指标上的对比Figure 6 Comparisons of three indicators between male and female
第2 个对比性分析中选取了年龄上差距较大的两个人群.一个人群的年龄在18 岁以下,另一个人群的年龄在35 岁以上.从图7 可以看到,这两个人群的节点强度仍旧高度相似,但是介数中心性的差距非常明显.18 岁以下组人员的介数中心性值都明显小于35 岁以上组人员,这说明18 岁以下组人员各个心理状态之间的彼此影响性较小,而35 岁以上组人员可能更易患得患失,任意一个心理状态都会影响很多其他心理状态.35 岁以上组的紧密中心性最大的点编号为23(“Prep”),对应问题为“我经常做好准备(I am always prepared)”;而18 岁以下组的最大点编号为19(“Heart”),对应问题为“我有一颗柔软的心(I have a soft heart)”.说明35 岁以上人员更加注重应对各种事情,也即更加理性;而18 岁以下人员更加注意内在心理,也即更加感性.两个网络的结构相似性为0.81.其差异性大于性别差异.
通过上述这种方式,还可以分析不同国籍、不同种族人群对应心理网络及指标差异.利用图的形式来呈现关键心理因素的关联确实能够为心理研究者和从业者提供一个非常好的可视化方式,方便理解与运用.
5.5 从机器学习视角的讨论
利用机器学习方法来构建节点之间的预测模型,并利用模型系数来构建心理网络已经成为心理学领域研究的一个非常重要的手段,因为该模型能生成便于心理专业学者或者从业者直观了解各个关键因素之间关系的网络图而受到越来越多的关注.但是从现有研究来看,此方面的研究主要由心理学研究者开展,很少由专业性的机器学习、大数据研究者主导,仍存在着以下几个不可忽视的问题.
1)建模合理性的问题:与传统的利用两节点取值的相关性来构网相比,基于机器学习的构网方式更加有合理性.但是这种方式是否最合理、是否还存在其他更合理的方式,目前则很少有学者对此进行探讨.
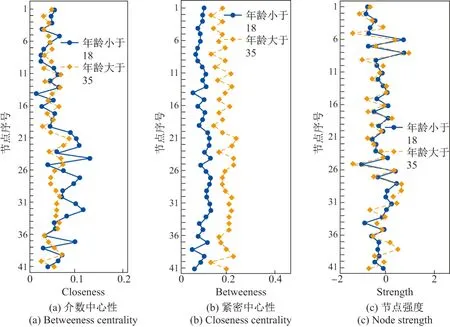
图7 不同年龄段人群在3 个指标上的对比Figure 7 Comparisons of three indicators in different age groups
2)建模有效性的问题:目前的构网方式依赖于一个机器学习预测过程,结果的好坏影响着构网的有效性.目前没有文献讨论当准确率为何值时所构建的网络是有效的.
3)数据有效性的问题:目前在构建网络的过程中,极少有文献讨论数据的有效性问题.通过一个含有较多噪声的数据集构建的网络,所得结论的可信度也不高.
上述问题依赖于更多的机器学习、大数据和心理学等学科共同解决,即在心理学理论的指导下,利用机器学习与大数据的理论和方法来解决心理网络的构网原则、评价指标等基础性问题.
随着互联网技术的飞速发展,获取较大规模的量表数据在许多社科领域已经成为了可能.如何将机器学习与大数据技术更好地引入到社科量表大数据中,以得到更为可靠、准确的结论,是一个值得讨论和研究的课题.
6 结 语
本文针对心理量表大数据分析的需要与现有模型的缺点,提出了两种改进的Ising 模型,即多类Ising 模型和序Ising 模型.并且以一个公开的规模较大的量表数据为例来进行分析,挖掘整体的心理特性网络和不同人群的心理特性网络的区别.实验结果表明,本文提出多类Ising 模型和序Ising 模型的总体分类准确率和序错误率是相当的,但是序Ising 模型的可解释性要好于多类Ising 模型.此外,本文还获得了一些不同人群心理特性网络的对比结论.后期的工作将重点关注由用户随意填写心理量表问卷而带来的数据噪声问题,便于更好地建模.
附录A:量表问题与图节点缩写对照
原始量表有50 个问题,去除9 个校验性质问题,剩余41 个.见表A1 所示.

附表A1 41 个量表问题与图节点缩写对照Table A1 Comparison of 41 scale questions and graph node abbreviations
猜你喜欢
意林彩版(2022年2期)2022-05-03
好日子(2021年8期)2021-11-04
纺织科技进展(2021年5期)2021-07-22
小学生学习指导(高年级)(2021年4期)2021-04-29
河北理科教学研究(2020年2期)2020-09-11
第一财经(2020年4期)2020-04-14
中国中医急症(2019年10期)2019-05-21
文苑(2018年17期)2018-11-09
中国卫生标准管理(2015年1期)2016-01-15
中国中医眼科杂志(2015年1期)2015-12-28
