
基于元学习的推荐算法选择优化框架实证
2020-06-12 09:17迟翠容王佳英
计算机工程与设计 2020年6期
任 义,迟翠容,单 菁,王佳英
(沈阳建筑大学 信息与控制工程学院,辽宁 沈阳 110168)
0 引 言
目前,成熟的推荐算法主要分为协同过滤推荐、基于内容的推荐和混合推荐3类[1]。但在机器学习领域,由于在大数据环境下用户和项目数量的不断增加,所造成的数据稀疏性使得现有的推荐方式已经远远不能对用户选择的项目做出正确的预测。
算法选择问题是许多研究领域需要解决的NP难题[2]。数据集的多样化导致单一的推荐算法难以在所有的推荐预测过程中均获得最优的推荐性能[3]。在这种情况下,基于元学习的推荐算法选择建模显得尤其重要。元学习最早被应用在心理学领域,之后广泛应用在计算机科学、人工智能、运筹学、统计学等学科领域。关于元学习的定义有很多,Santoro等[4]将其主要思想描述为分类问题。Lemke等[5]将元学习定义为元学习系统必须包括一个学习子系统,学习子系统通过单数据集提取的元知识获得经验。因此,元学习不仅是获取学科知识,而且被视为对学习本身的理解和适应,通过获取数据特征与算法性能之间的映射来实现此过程。
本文的创新点:
(1)提出一种基于元学习的推荐算法选择优化框架。
(2)改进元特征的提取方式,在数据集元特征的基础上融入了算法特征测度的因素。
1 相关技术
1.1 算法选择模型
对于现存的一些可用算法,算法选择是解决哪一个算法在特定问题领域中执行最好的主要手段。算法选择最简单的方法是通过反复实验选取性能最优的算法。该方法虽然操作简单,但是计算资源相对过高,而且考虑到运行时间耗时也相对较长。基于专家经验的算法选择获取专家经验代价较高,同时可扩展性较差。为特定的问题选择算法,需要研究所提取的特征与算法性能之间的关系,最终以推荐算法排名的形式进行推荐[6]。1976年,Rice提出算法选择抽象模型,如图1所示。该模型定义问题空间P:代表问题实例的集合;特征空间F:包含应用于实例的可测量特征;算法空间A:作为问题的所有合适算法的集合;性能空间Y:表示每种算法到一组性能测量的映射。根据此框架,算法选择的问题可以表述为:“对于给定的问题实例x∈P,具有特征f(x)∈F,找到选择映射S(f(x))到算法空间A,这样选择的算法α∈A使性能映射y(α(x))∈Y最大化。”
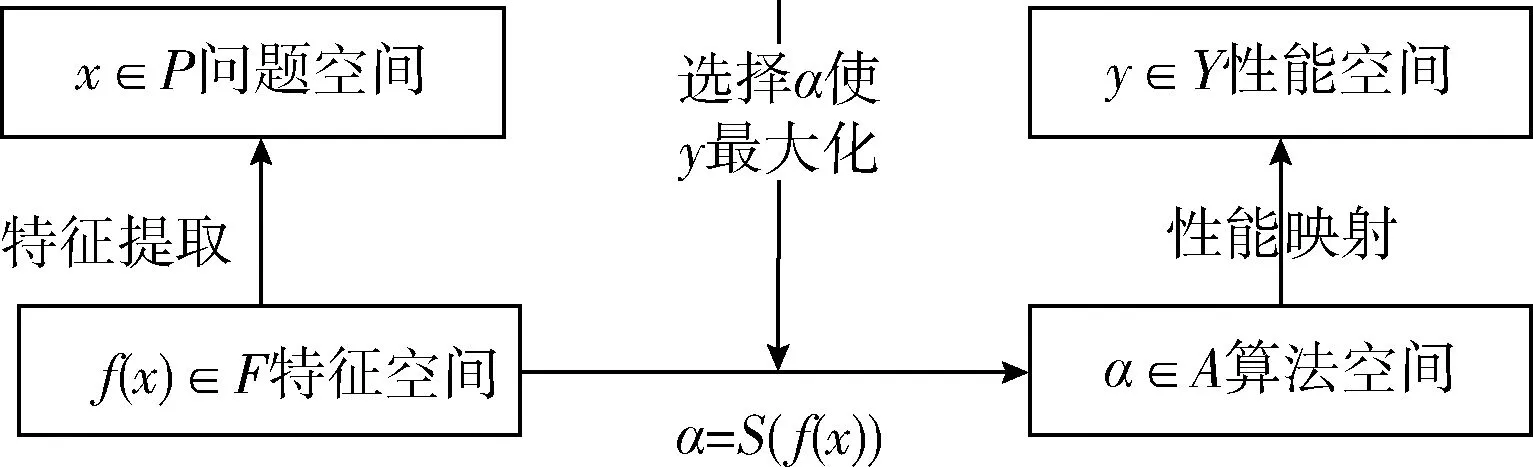
图1 Rice算法选择抽象模型
根据Rice算法选择抽象模型,本文定义的问题空间P:DonorsChoose和Movielens推荐数据集;提出一种新的特征空间F:用于描述数据的元特征和算法元特征的组合;算法空间A:选取6种元启发式算法:KNN、SVD、SVD++、BMF、TF-IDF和FastText;性能空间Y:算法性能评估指标。四元组
1.2 元学习
元学习属于机器学习范畴,是算法选择发展的一个阶段,一些学者在推荐算法选择时已使用了元学习方法[7,8]。一些学者使用元学习在推荐系统中进行算法选择。Cunha等和Soares等[9,10]试图为整个数据集选择最佳算法,通过定义元特征,将数据集中的信息聚合为单数统计,再使用有监督的机器学习来学习元特征与推荐算法的性能之间的关系,通过标准度量来衡量。Pinto[11]提出一种框架,以系统化元特征的提取,从3个组成部分定义元特征:元功能、对象和后处理,以此方便元学习的研究。Hutter等[12]在构建元模型时更注重参数的选择。本文将元学习用于算法的选择,尝试为数据集的单用户请求选择最佳算法。
元学习方法有两种模型归纳级别:基础级别(base-level)和元级别(meta-level)[13]。在本文的研究中,基础级别指的是应用在DonorsChoose和Movielens数据集上的推荐算法,元级别研究数据集特征对算法的影响。元学习处理算法选择问题可以分为两个阶段:训练和预测。在训练阶段,数据集由一组可测量的特征来表示,推荐算法在数据集的每一组“用户-项目”对进行性能评估,之后,在元数据上训练学习算法以构建能够将数据集的特征与最佳基础级算法相关联的元模型。在预测阶段,用前一阶段构建的元模型来预测给定的“用户-项目”对的最佳算法。
1.3 元特征提取技术
在选择最佳算法时,元特征的提取是元学习最关键的一个环节。元特征不仅要包含能够影响算法效率的有效信息,而且要求计算结果是有效的。Rivolli等[14]总结了各个领域元特征的提取方法,在元学习推荐领域,通常采用3种方式提取元特征,包括:统计和信息论、模型和landmarking。目前,大多数研究者只考虑数据集的元特征,却忽略了结合多种类型的特征测度来提高算法的推荐准确率。本文提出一种元特征提取方式,数据集的元特征和算法元特征的组合,具体在第二章节介绍。
1.3.1 基于统计和信息论的提取技术
此类元特征的提取方式主要针对数据集的简单特征、统计特征(用户数、项目数、几何平均、调和平均、方差、偏移度等)和信息特征(属性变量的信息熵、噪声率等)。数据集的统计特征主要反映数据的中心趋势和属性点离散程度;信息特征反映不同属性之间关联程度,见表1。

表1 基于统计和信息论的元特征
1.3.2 基于landmarking的提取技术
Landmarking方法的主要思想是:使用简单快速学习算法的性能来表征数据集的度量。已知分类器A和B,对于给定的问题,将基准分类器A和B进行测试排名,若A表现比B好,测试新问题时,选择与A归纳偏置相同的分类器。Landmarking元特征提取方式能较好体现出分类算法的应用场景。
1.3.3 基于模型的提取技术
模型元特征的提取是从训练出的模型中提取此模型的特征度量。研究者大多采用了基于决策树模型(DT)的方式。如Rivolli等[14]基于DT模型将描述学习的复杂度作为特征度量。基于模型的元特征见表2。

表2 基于模型的元特征
2 基于元学习的推荐算法选择优化框架设计
2.1 算法选择优化框架设计
元知识学习是将元算法应用于元特征与算法性能测度间映射的过程。应用第一章所述的3类元特征提取方式,研究者通常只考虑数据集元特征,而未考虑到推荐算法的特征测度,从多维度考虑元特征的提取方式更能提高推荐
精度。因此,本文从数据集和算法两个方向进行元特征提取。本文提出推荐算法选择优化框架如图2所示。
本文提出的算法选择优化框架主要由基础级别的元知识数据库和元级别的预测算法推荐两部分构成。元知识数据库包含训练数据x和候选推荐算法α。每条训练数据x包含元特征和学习目标两部分。从x提取的一组度量指标作为元特征,训练数据x在推荐算法α的性能指标作为学习目标。特定的学习算法t用于构建元推荐模型。元推荐模型构建成功,对于新用户请求推荐合适的算法就变的很简单。即,首先提取xnew元特征;然后结合构建模型和提取的特征推荐合适的算法。具体实现步骤如下:
开始:给定训练数据x∈P,推荐验证数据xnew∈P,推荐算法集合α∈A,元算法t∈T,性能评价指标y∈Y。
步骤1 提取数据集中描述“用户-项目”对的特征度量,生成相应的特征向量,同时评估数据集上所有候选推荐预测算法的性能,生成相应的算法元特征,构成特征集合f(x);
步骤2 对x∈P,执行∀α∈A,找到各算法依据性能评价指标y∈Y的映射,形成元知识数据库;
步骤3 基于元算法t∈T。构建出训练数据均方根误差(RMSE)最小的元模型,用于测试实例的预测;
步骤4 利用元推荐模型对xnew做预测。

图2 优化框架
2.2 数据集选取
本文实证分析所需要的原始数据集来自Movielens和DonorsChoose,其中Movielens由Minnesota大学的GroupLens课题组提供,是学术界用来实验推荐系统的经典数据集,其内容包括了943位用户评价1862个项目的10万条评分数值。DonorsChoose是一个慈善网站数据集,提供了捐献者和项目以及交互的大量信息,包含21.2万用户对11.1万项目的46.9万条交互信息,为方便测试将DonorsChoose数据集的交互信息用评分表示,同时为了确保元数据和性能度量的值在数据集之间具有可比性,将数据集评分归一化在1-5范围内。本文从上述数据集选择出10万条数据进行实证分析。为了充分反映元特征对算法性能测度的重要性,所选取的两组实验数据集特征值差别较大,相关数据集信息见表3。
2.3 数据集元特征提取
本文元特征从两方面提取:一方面,为了反映数据的中心趋势和属性点的离散程度,首先应用系统元特征框架技术来提取统计和信息论的元特征。该框架定义3个主要元素:对象ο、函数f和后函数pf。首先将函数应用于每个对象产生相应结果,然后将每个后函数应用于该结果,以生成元特征的值,可以表述为{ο}、{osub}、{f}、{pf}。其中{ο}表示数据集、用户、项目和评分;{osub}表示ο的子集,反映了不同属性之间的关联程度;f表示对象ο的数量值;pf表示缺失值百分比等。本研究提取统计和信息论的元特征步骤如下:
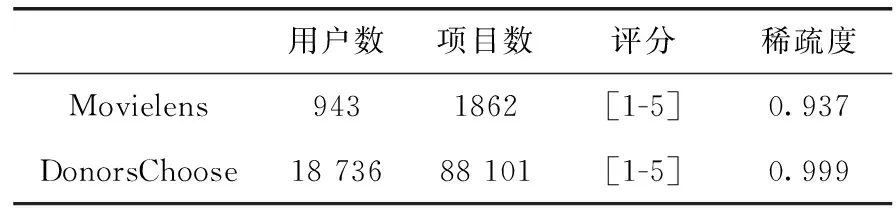
表3 数据集基本特征
(1)将函数f应用于数据集对象ο及子集osub。即,f(o)提取用户数、项目数和评分数等信息,见表3,f(osub)提取相应子集的有效属性,包括:年龄、性别、职业、位置信息等;
(2)将后函数pf应用于f(o)的输出结果以提取数据稀疏度等信息。
另一方面,考虑到上述统计和信息论的元特征是常用的特征度量,通常描述的是数据集、用户及项目的元特征。为了强化算法性能测度,提高算法推荐的正确率,本文在此基础上融入新的特征测度,即将算法性能表示为评分。
算法的特征测度提取的元特征定义为f′(o),表示每个数据集x所采用的推荐算法α的排名,通过线性转换

元特征提取流程如图3所示。
综上所述,本文提取的元特征f(x)=f(o)∪f′(o)如图4、图5所示。

表4 符号定义及含义
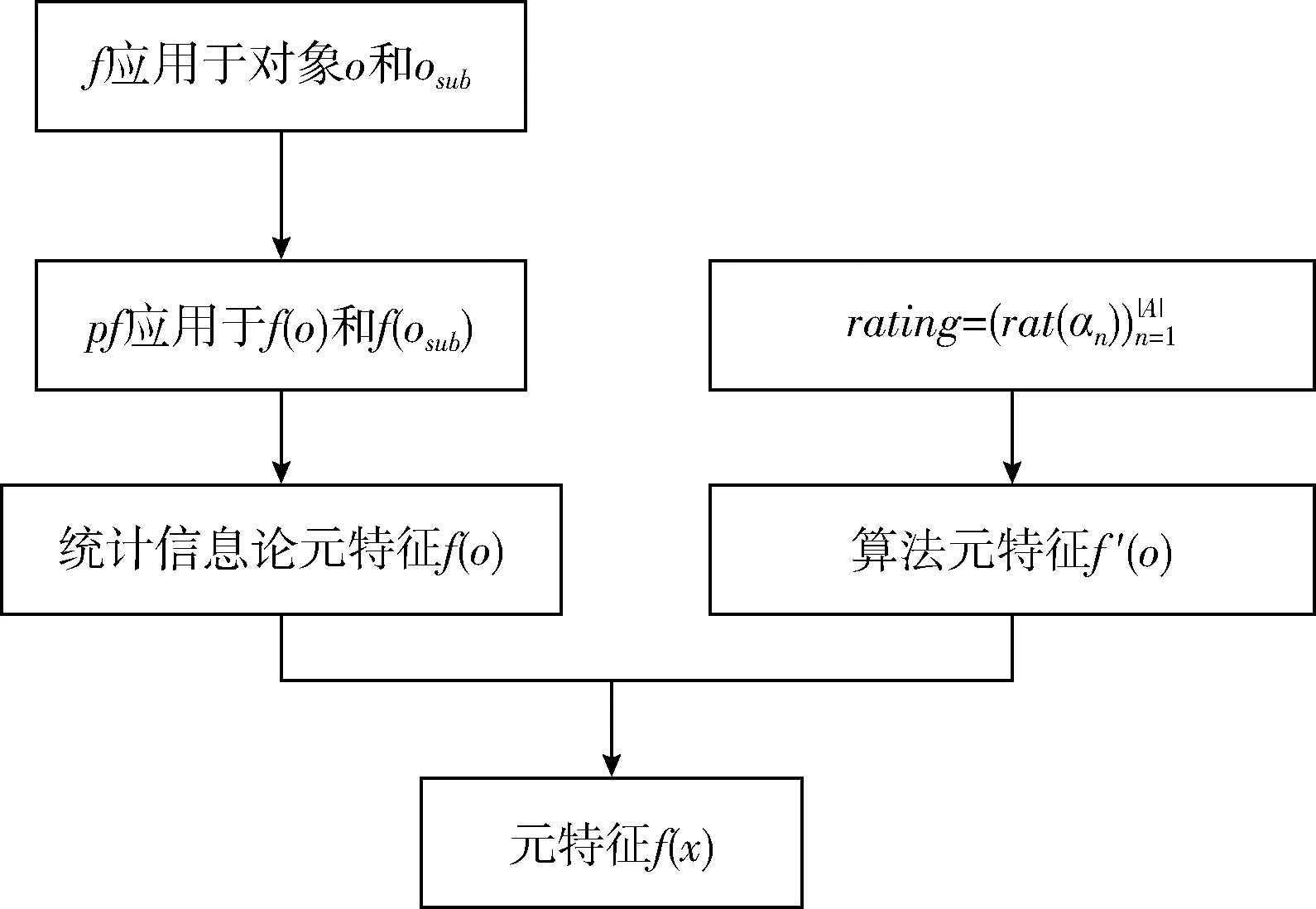
图3 元特征提取流程

图4 Movielens数据集

图5 DonorsChoose数据集
为了方便计算,本文将用户的性别等信息表示为布尔值,例如用户性别男表示为1,性别女表示为0。ZIP表示邮编。用户评分表示为整型,数值范围在[1-5]。算法特征转化为评分,用整数表示。
2.4 算法选择
2.4.1 基础级别算法选择
为了验证所构建的推荐算法选择优化框架是可行的,需要在基础级别进行推荐算法的选取,在选择推荐算法时,更多地考虑了所采用数据集的属性特征,如Movielens数据集没有文本属性,则不适用基于文本推荐的TF-IDF和FastText两种算法,因此,本文对这两种数据集各选取了4种有代表性的推荐算法。针对Movielens数据集,选用了常用的推荐算法:KNN、SVD、SVD++和BMF;针对DonorsChoose数据集,选用了常用的推荐算法:KNN、SVD、TF-IDF和FastText。
2.4.2 元级别算法选择
元模型的构建需要在元级别阶段选取分类算法,本文为了保证实证分析结果的普遍性,随机选取了3种分类算法,分别为:Usercluersting、RandomForest、StackingDecisonTree。根据分类算法来预测数据集中每个用户的推荐正确率。第一种算法使用K-means思想,该思想基于元特征的聚类事务来解决算法选择问题,并通过多数投票为测试用户分配最佳算法;第二种算法是堆叠决策树,根据元数据和基础级别的输出,来执行事务的分类,将基础级别的输出作为元级别的输入给出预测;最后一种算法是对训练数据进行随机采样,对于每个训练集构造一棵决策树,汇总决策树对算法分类的结果,哪一类算法被选择的最多,预测归属为哪一类。
2.5 算法评价指标
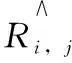
(1)
预测正确率是指元模型预测值减去RMSE值为0或无效值(NaN)的个数与测试数据的总个数之比,其定义

(2)
3 实证分析
3.1 算法预测正确率
本文验证了算法选择优化框架,在DonorsChoose和Movielens数据集元特征的基础上,提取出算法元特征,生成元特征与预测值一一对应的目标矩阵。
DonorsChoose数据集元特征与预测目标值
Movielens数据集元特征与预测目标值
在此基础上,利用Userclustering等3种元算法对该目标进行元模型构建,通过RMSE指标将元特征与推荐算法进行匹配。训练数据和测试数据按照80%和20%的比例进行分组,训练组用于训练获得元模型,测试组用于验证模型的预测正确率。将算法应用于整体数据集,评分预测指标RMSE如图6所示。

图6 评分预测指标(RMSE)
针对DonorsChoose数据集,KNN算法表现结果最好,RMSE达到0.6049。相对Movielens数据集,SVD++算法效果最好,RMSE为0.8082。对于整体数据集来说,KNN和SVD++是最佳的表现算法。但针对数据集的单一用户选择算法,结果会有不同的表现。如图7所示。

图7 算法表现百分比
TF-IDF用于DonorsChoose数据集的每一行用户,预测性能最好的算法所占的百分比达到52.3%,而KNN算法表现最差,百分比只有0.49%。SVD算法也仅有10.1%的百分比。在Movielens数据集,SVD++算法有较好的表现,达到42.3%的百分比。同样,KNN算法占有9.9%的百分比,表现依旧较差。
对于以上结果进行分析,不管是哪个数据集,KNN算法和SVD算法都没有较好的表现。考虑到每个用户的平均交互次数较少,交互的项目较多,KNN无法找到合适的邻居。而SVD没有好的表现与其数据的稀疏度有关。基于内容的协同过滤TF-IDF和FastText过滤技术在Donors-Choose数据集表现较好的原因是用户对项目进行显式搜索而不是查询相关可能的项目。
针对2.4.2提出的3种元算法进行元模型的构建,在元级别预测正确率的结果与选定的基线作比较(两条虚线表示选定的基线)。DonorsChoose数据集选择最佳表现算法TF-IDF(52.30)作为基线。Movielens数据集选择SVD++(42.30)算法。结果如图8所示。

图8 预测正确率
StackingDecisionTree表现最佳,在DonorsChoose数据集预测正确率高达86.58%,在Movielens数据集是80.39%,因为StackingDecisionTree是一种集成学习方法,可以提供更多的交互信息。Userclustering表现最差,在DonorsChoose数据集仅有50.81%的正确率,在Movielens数据集达49.27%正确率。
从用户聚类的不良性能可以推断,相似的交互行为使用相同的推荐算法不一定产生一致的结果。元级别预测的结果显然受到基础级别的影响,由于基础级别引入KNN算法和SVD算法相对性能较差,并且未引入相应的惩罚,使得元级别算法训练构建的元模型对测试实例的预测会产生更大的误差。此为以上预测数据出现差异的根本原因。
3.2 计算资源与时间性能
推荐算法的选择另一重要的评价指标是资源占用率和时间性能。本文实验环境:CPU为4核DELL Core i5,主频3.20 G Hz,内存8 GB,算法实现采用Python 3.6。在此实验条件下,所有推荐算法均能处理100%用户量,并且均能成功推荐。
DonorsChoose和Movielens数据集采用推荐算法的CPU占用率与本文提出的框架模型(meta-model)CPU占用率进行了对比,如图9、图10所示。由图中数据可以看出,KNN算法CPU资源占用率最高。本文提出的框架模型占用CPU资源虽不是最低,但相对KNN、SVD算法却得到一定优化。

图9 DonorsChoose数据集CPU占用率
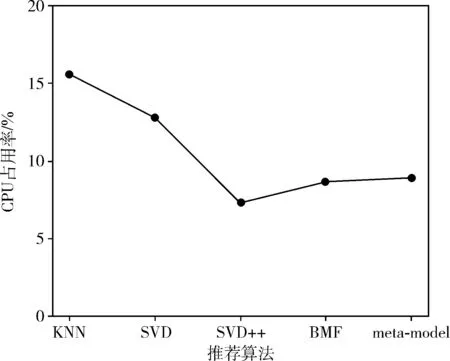
图10 Movielens数据集CPU占用率
推荐算法运行所需的时间见表5。从表5中数据可以看出每一种单一算法运行时间低于本文提出的算法选择框架时间,但是对于给定的用户需求,算法的选择具有盲目性和随意性。用户在不清楚哪种算法推荐效果更好的情况下,需要运行已知的所有算法从中选择最优的推荐。

表5 时间性能/s
对于DonorsChoose数据集,4种算法运行时间的总和高于本文提出的算法选择框架时间,而对于Movielens数据集,4种算法运行时间的总和低于算法选择框架的时间。本文提出的算法选择框架时间主要消耗在提取元特征与构建元模型阶段。元模型构建完成,在实际应用中能很快从多个推荐算法中选择出最优的推荐算法。算法越多,越能体现本文提出的算法选择框架的优越性。
4 结束语
本文对基于元学习思想的推荐算法选择提出了算法选择优化框架,实验结果表明,该设计方案是可行的,Stac-kingDecisionTree分类算法构建的元模型具有较好的算法选择性能,引入性能较差的推荐算法在元级别预测阶段会产生较大影响。同时结果表明较常使用的KNN和SVD算法由于其难以匹配到相似的元特征会在分类和预测阶段对高预测率造成间接的影响。本文研究为以后的元学习算法选择奠定基础。后期的研究工作可以考虑进一步提升元特征提取的正确度进行元模型的构建。
猜你喜欢
小资CHIC!ELEGANCE(2022年1期)2022-01-11
中华养生保健(2020年7期)2020-11-16
数学物理学报(2020年3期)2020-07-27
晚晴(2018年3期)2018-12-06
家庭影院技术(2018年5期)2018-06-29
家庭影院技术(2018年3期)2018-05-09
中学生(2017年13期)2017-06-15
家教世界·创新阅读(2016年11期)2016-12-27
天津护理(2016年3期)2016-12-01
故事会(2016年15期)2016-08-23
