
面向完全冷启动的深度混合协同过滤推荐算法*
2020-06-09 06:17陈健美
计算机与数字工程 2020年3期
胡 杨 陈健美
(江苏大学计算机科学与通信工程学院 镇江 212013)
1 引言
在这个数据爆炸的时代,如何快速找到需求的信息变得越来越困难。搜索引擎的出现帮助人们通过关键字快速找到想要的信息,但是很多时候,人们的需求往往不是很明确,或者是想要更加符合个人口味和喜好的结果,推荐系统便应运而生。除此之外,很多商业组织也使用推荐系统来拓展业务,提高业绩。
这些年来研究产生了大量的推荐算法,它们大体上可以划分成两类[1]:基于内容的推荐[2]和协同过滤[3],其中最为常用的是协同过滤。基于内容的推荐主要是根据推荐物品或内容的元数据,发现物品或者内容的相关性,进行推荐;而协同过滤则根据用户对物品的评分记录,分析出用户与用户之间存在的关系以及物品与物品之间隐藏的关联,预测用户对某个物品的潜在评分,进行推荐。
当前,在协同过滤方法中最为成功有效的是隐含因子模型(Latent Factor Model,LFM)[4]算法。隐含因子模型算法直接从用户-物品评分矩阵中学习有效的隐含因子。但是,在实际情况下用户-物品评分矩阵往往是特别稀疏的,只有小部分元素有值,这就导致协同过滤算法在学习隐含因子时性能会显著下降。协同过滤存在的另外一个问题是冷启动问题,在系统中出现新用户和新物品时,无法对其进行精准推荐。
因此,对于协同过滤算法存在的冷启动问题,融合辅助信息进行推荐是必然的,混合推荐[1]也变得越来越流行。虽然现在有很多种混合推荐来解决推荐系统的稀疏性和冷启动问题,但是冷启动问题依旧是一个开放的问题。
为了解决协同过滤的冷启动问题,本文提出了一种深度混合协同过滤推荐算法,它是基于深度学习方法、融合物品信息的混合推荐模型,并考虑到时间因素。主要贡献如下:1)提出了一种结合协同过滤与机器学习的通用框架,该框架可用于对冷启动物品进行推荐;2)提出了一种基于堆栈降噪自编码机器的物品特征学习算法,将稀疏高维的物品内容编码成稠密、低维度的物品特征向量;3)提出一种结合安全的半监督S4VM 的预测算法,对冷启动物品进行评分预测,并将堆栈降噪自编码机学习的特征向量和S4VM 预测的结果融入完全冷启动情景下的LMF 算法中。实验结果证明,所提出的算法能有效缓解冷启动与稀疏性问题,与现有的算法相比,在推荐精度上有较大提升。
2 相关工作
传统的协同过滤算法主要分为基于邻域的算法和基于模型的算法。基于邻域的算法主要通过相似度计算公式,计算出物品与物品之间的相似度后,再依据计算出的结果以及用户曾经的评分行为为系统用户进行相关物品的推荐[5]。基于模型的算法尝试填充用户-物品评分矩阵,依托一些机器学习算法来对物品的向量进行训练,建立模型预测用户对新物品的评分,如基于朴素贝叶斯(Naïve Bayesian)[6]、主题模型(Topic Model)[7]、支持向量机(SVM)[8]等协同过滤算法。
由于协同过滤受数据稀疏性和冷启动的影响较大,越来越多的方法尝试融入额外的信息来克服这个问题。广泛受到关注的是HFT(Hidden Factors as Topic)[9]将主题模型 LDA(Latent Dirichlet Allocation)[10]与协同过滤结合,其准确率较经典的LFM 模型有一定的提升。其余多融合用户的社会标签或人口统计学信息进行协同过滤推荐,但是它们的辅助信息的隐含表示受到极度稀疏的内容信息的影响,不能有效的学习。
近些年来,深度学习在自然语言处理、图像处理等领域上取得了巨大的成功,而在推荐系统方向,它的应用仍处于萌芽时期。国内外学者将深度学习引入到推荐系统的主要有以下几个经典模型:1)Hinton 等 使 用 RBM(Restricted Boltzmann Machines)[11]来进行协同过滤,但是其没有融入辅助信息;2)王[12]等直接使用 CNN(Convolutional Neural Network)和DBN(Deep Belief Network)从主题信息中获取隐含因子,但是他们只考虑物品信息,且该方法只适用于音乐数据;3)王[13]等在SDAE 的基础上提出了Bayesian SDAE 模型,并与概率化LFM 模型结合,但是它仅关注到用户信息稀疏的情况,而且主要任务是进行TopN推荐。
由上可知,利用深度学习及辅助信息来解决推荐的稀疏性和冷启动问题是一个必然趋势,但是现有研究工作仍存在很多不足,例如很难从有限的粗糙的属性中挖掘出具体的特征,没有充分考虑到时间、位置等因素。
针对上述问题,本文提出了一种深度混合协同过滤推荐算法(DCF_CS),结合 SDAE、S4VM 与LFM 模型,同时考虑到时间因素,有效缓解冷启动问题,提高推荐精度。
3 深度混合协同过滤推荐算法
深度混合协同过滤推荐算法主要思想为采用深度降噪自编码机获取物品特征,然后根据特征使用安全的S4VM 初步预测完全冷启动物品的评分,结合考虑时间因素的LFM 模型,最终产生预测评分。下面将介绍算法使用到的模型的原理及意义,最终展示所提的预测算法。
3.1 SDAE
降噪自编码器(denoising auto-encoder,DAE)[14]是一种三层神经网络,它包含输入层、隐藏层和输出层。其目标是学习恒等函数h(x)=x,即学习一个近似的恒等函数,使得输出近似等于输入。同时,为了解决恒等函数的风险,我们往往会随机采用部分受损的输入,使得自动编码器必须进行恢复或者降噪,从而在隐藏层得到输入的良好表征。具体做法是对原始数据,进行人为随机损坏加噪声,得到损坏的数据,该噪声可以采用高斯噪声或bi-nary mask噪声。
对于给定样本集合S,降噪自编码器对输入的编码和解码如下:
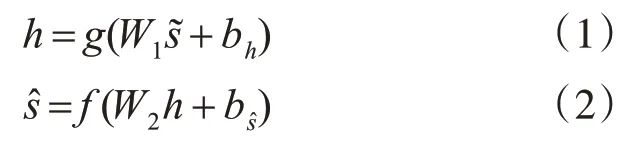
其中代表加噪后的输入,代表重建的输入样本,h为隐藏层,即输入的隐含表示,W为权重矩阵,b为偏置向量,g(·)为编码函数,f(·)为解码函数。
因为单个降噪自编码器的编码能力是有限的,现有研究表明[15~17],将多个降噪自编码器堆叠在一起,可以在隐藏层中产生更加丰富的表示,从而使SDAE 比DAE 有更出色的处理能力。SDAE 的每一层都当成一个DAE,通过逐层贪婪的训练方式,首先对第一层DAE 进行训练,将第一层的输出作为第二层的输入,再将第二层的输出作为第三层的输入,以此类推。假设SDAE 有L层,我们通常把前2/L 层作为编码部分,后2/L 层作为解码部分,编码部分学习受损输入的特征表示,解码部分恢复其受损前输入。L层SDAE解决如下优化问题:

其中SL表示 L 层的输出,Wl和bl表示 L 层的权重矩阵和偏置项,本次研究采用的是4 层SDAE。隐藏层学习得物品特征后,将用于LFM模型中。
本文是采用SDAE 替代LDA 模型及矩阵分解得到物品特征向量,主要原因如下:1)矩阵分解得到的物品特征向量缺乏语义上的解释,而SDAE 的隐藏层学习得的物品特征向量能更好地反映出物品的特征;2)降低物品内容向量的维度,使其与隐含因子向量相等,能够融入隐含因子模型中,并增加矩阵分解的一般性。
3.2 引入S4VM
半监督学习是一种将少部分有标记的样本和绝大部分无标注的样本结合的学习框架,其中的直推式学习把将要预测的数据作为未标记样本,这与推荐系统中数据稀疏性、冷启动问题十分一致。S4VM 是一种安全的半监督支持向量机,所谓“安全”,是指半监督学习方法的性能不会明显低于只利用小部分有标记样本的归纳学习方法的性能。由于S3VM 存在多个低密度划分导致性能下降,所以才出现了S4VM。它首先找到候选的低密度划分,然后对未标记样本的标记进行优化使得性能提升最大[18]。当半监督学习的低密度假设成立时,S4VM 必定安全[19]。因此,使用 S4VM 来预测未标记样本的协同过滤推荐算法,在理论上要优于其他的相似性、基于聚类、基于朴素贝叶斯等协同过滤算法。
传统算法的针对冷启动问题,主要是采用相似度计算将冷启动物品与非冷启动物品关联起来,主要有Top-of-Al(lToA)和Top-of-User(ToU)两种算法。ToA 主要是通过在所有的非冷启动物品中找到M 个与冷启动最相近的物品来预测冷启动物品的评分,预测规则如下:

其中SM(j)表示与冷启动物品j最相似的M 个非冷启动物品的集合,既可以是真实评分也可以是预测评分。
ToU 则是根据一个用户对M 个最相似的非冷启动物品的评分来预测冷启动物品评分,预测规则如下:
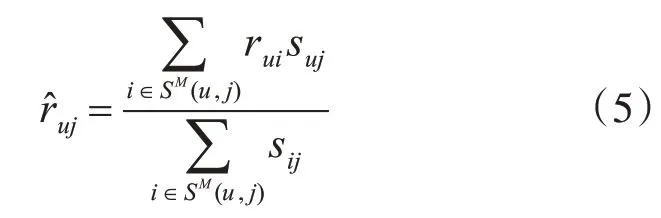
其中SM(u,j)表示用户u 对与j 最相似的M 个非冷启动物品的集合,rui表示训练集中的真实评分。
上面两种方法简单的通过相似性来预测评分,忽略了评分矩阵中的其他信息,经过之前的分析,使用安全的半监督S4VM 对冷启动物品进行预测理论上要优于之前相似性算法。同时,我们也对S4VM 预测的效果与基于相似度的ToA 和ToU 进行实验对比,结果显示S4VM 的性能要优于它们。因此,为了初步预测完全冷启动物品的评分,使用S4VM 取代相似度等算法,根据SDAE 隐藏层学习得的物品特征,将训练集中冷启动物品随机划分为n 个数据集,非冷启动物品构建为初始数据集。对于冷启动物品,构建其属性特征,并将其与非冷启动物品的特征和评分标签作为S4VM 算法的输入,S4VM将输出冷启动物品的评分标签。
3.3 评分预测模型
隐含因子矩阵分解(LFM)是推荐系统中应用较为普遍的模型,如果把用户对物品的评分看为一个矩阵,则矩阵的每个元素都是某个用户对某个物品的评分,则可以将评分矩阵R 分解成2 个低维度的矩阵P 和Q,假设用户数为u,物品数为i,则评分R=(ru,i),预测评分为

由于不同的人有不同的评分习惯,且物品也有质量的好坏等差别,我们从这两个角度考虑,使用基于平均偏差的矩阵分解模型,评分预测如下:
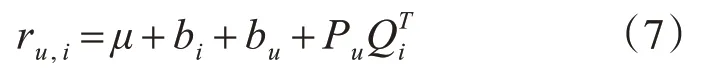
其中,偏置项可用来模拟用户兴趣随时间的变化以及物品的生命周期,因此将bi和bu变成一个随时间变化而变化的参数:
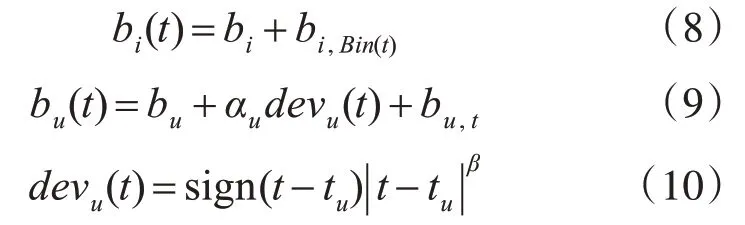
其中,时间相关的物品偏置由一个固定部分bi和一个随时间变化的部分bi,Bin(t)组成。Bin 为把数据集划分的不同间隔;时间相关的用户偏置同样由一个固定部分和一个随时间变化的部分组成,其中αudevu(t)代表了用户兴趣的偏移,bu,t代表某个特殊时期的突然偏移。
由于完全冷启动物品没有获得任何评分,因此冷启动物品没有参与到LFM 模型的训练。同时作为一个新物品,我们不知晓其质量等偏置因素,相比于用户物品因素则显得更加静态,不会随时间的变动而改变,所以仅考虑用户偏置,将S4VM 预测的结果φ融入LFM 模型中,替换平均评分和物品偏置项。因为传统的协同过滤算法不能直接应用于完全冷启动问题,所以用物品内容特征θi替换物品因子Qi,得到所提出模型的预测公式:

具体算法步骤:
输入:用户-物品评分矩阵R,物品属性集Y,评分标签I
输出:推荐列表
步骤1:根据物品内容属性集,训练SDAE,SDAE的隐藏层将学习得物品的特征;
步骤2:将冷启动物品的特征,非冷启动物品的特征和评分标签作为S4VM 算法的输入,S4VM将输出冷启动物品的评分标签;
步骤3:将S4VM输出的评分标签及由步骤1获得的物品特征融入LFM 模型中,通过随机梯度下降法最小化损失函数;
步骤4:根据预测评分,为用户推荐其预测评分较高的物品。
所提出模型(图1)与经典LFM 模型(图2)的对比如下。
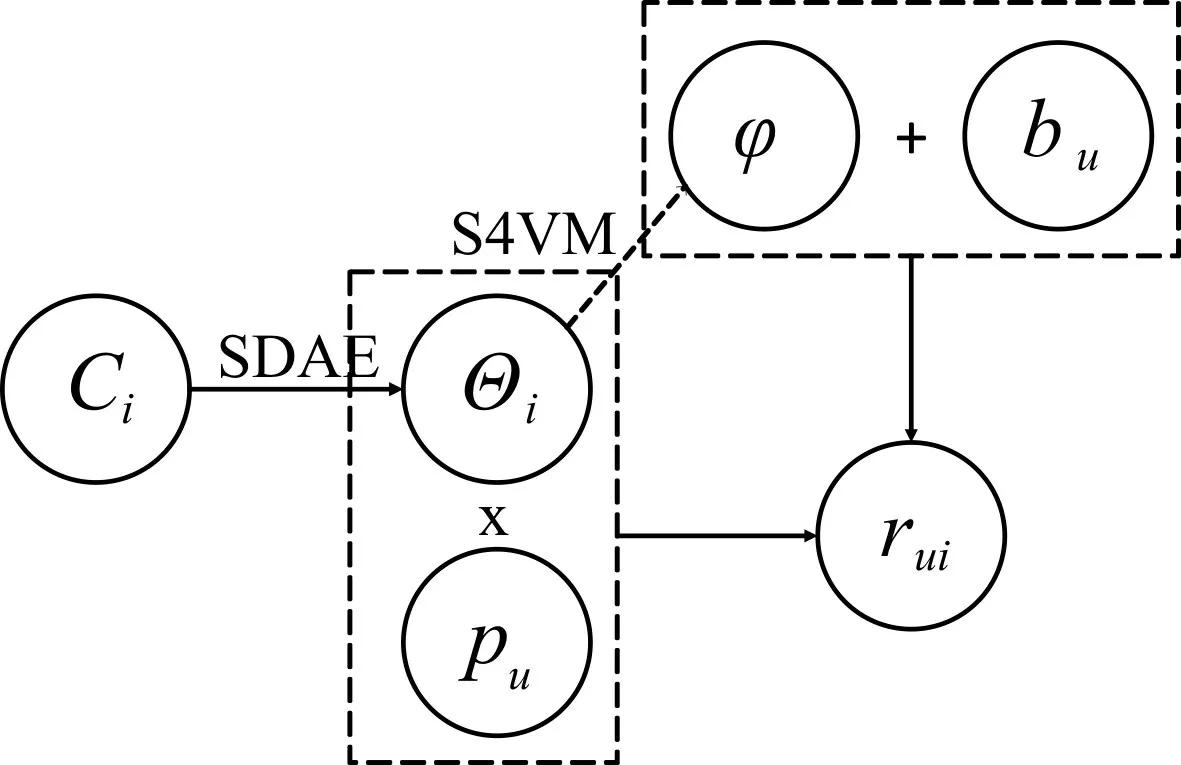
图1 DCF_C模型框架
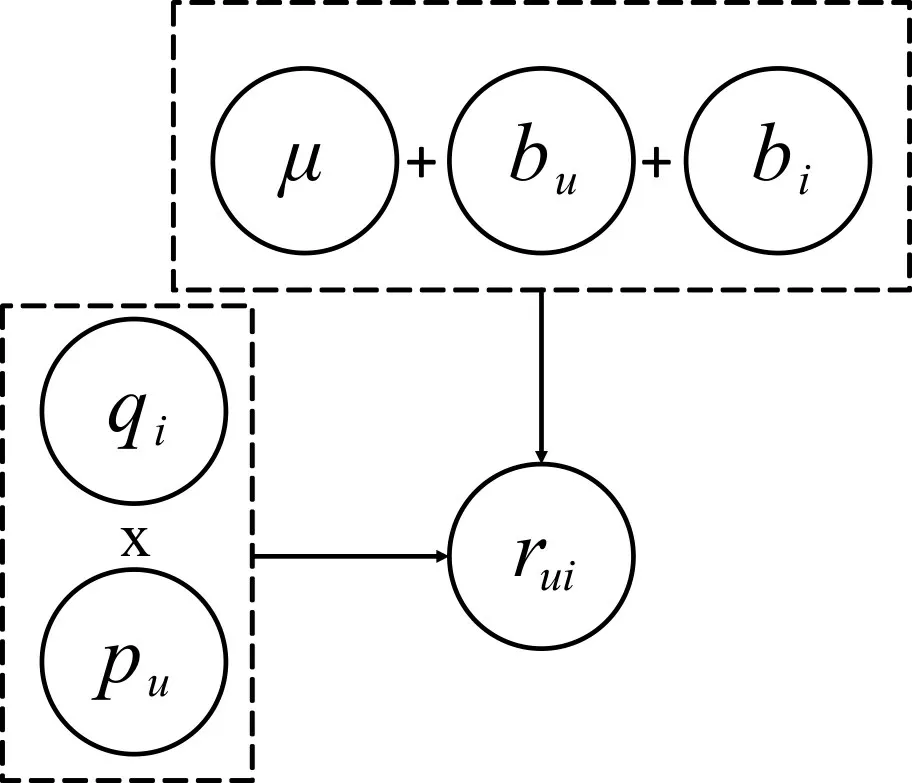
图2 LFM模型框架
基于矩阵分解的算法在数据稀疏时非常容易出现过拟合现象,因此,使用常用的正则化方法来避免过拟合,优化模型的目标就是最小化:
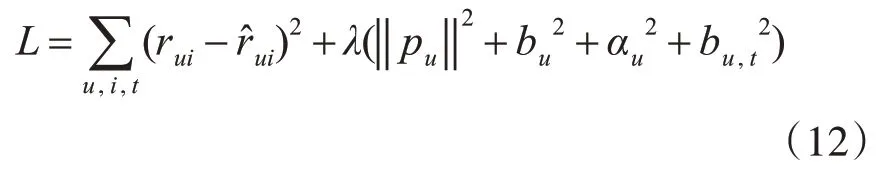
由于上式中所有的参数都是用户相关的,因此训练之后可用来预测完全冷启动物品的评分,我们使用随机梯度下降法(SGD)来进行系数优化。
4 实验
4.1 实验数据集及设置
本次实验采用的是标准数据集MovieLens中的1M 规模数据集,其包含了使用者对电影的百万个打分,每个打分都是一个1~5 的数值,我们二值化评分数据,将评分值在4 分及以上记为1,4 分以下记为0。此外,从数据集中取出电影的内容信息,包含电影标题,电影发布时间,电影所属类别等。我们将其编码成二值向量,向量长度为1943。同时,数据集还提供了电影第一次受到评分的时间戳,我们将其划分为10 个间隔,统计每个间隔中有多少部电影。为了模拟新电影出现的情况,我们选择L 个最新的电影作为测试集,其余电影作为训练集,从而保证这L 部电影不会被训练集中的任何用户看到。
4.2 评价指标
与绝大部分现有工作一致,本次实验采用均方根误差(Root Mean Squared Error,RMSE)指标来衡量算法的效果,均方根误差的公式如下:
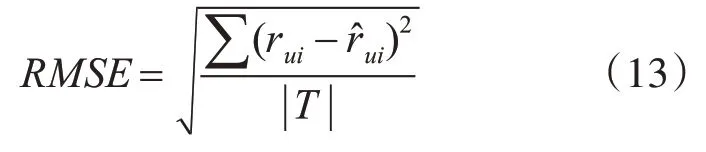
其中rui是用户u对物品i的现实打分,是与其所对应的预测评分。T是测试集,代表测试集中所有评分的数量。
由于评分信息是以隐式反馈的形式,与CDL一致,我们采用召回率(Recall)作为另外一种指标。公式如下:

4.3 实验结果与分析
为了评价所提出的DCF_C 算法的优劣,本文选择了 Top-of-All(ToA)算法,Top-of-User(ToU)算法,timeSVD++算法和CDL 算法作为比较算法。表1 展示了预测结果的RMSE 值,其中L 指完全冷启动电影的测试集的规模。

表1 所提算法与相关算法的性能(RMSE)对比
由表可知,我们提出的算法(DCF_C)的RMSE最低,性能最好,且显著好于其他算法。ToA 算法主要是通过M 个最相似的物品来预测冷启动物品的评分,而ToU算法主要是通过用户对M 个最相似物品的评分来预测冷启动物品的评分,它们都是基于相似性的,但是忽略了其他信息,因此它们的性能比所提出的算法要差,实验中我们将M 取值100。timeSVD++是考虑时间因素的SVD 算法,虽然考虑了时间因素对用户物品的影响,但是未充分利用辅助信息,因此性能不如我们提出的算法。CDL 是基于深度学习的协同过滤推荐模型的典型代表,它是由王等在SDAE的基础上,提出了Bayesian SDAE 模型,利用该模型学习物品的隐含特征,进而利用概率矩阵分解来拟合原始评分矩阵。但是,CDL 只关注于用户稀少的情况,且主要任务是进行Top-N 推荐,因此对于冷启动情况性能一般,但好于另外几种比较算法。
图3 展示了我们提出的混合模型与ToA,ToU,timeSVD++,CDL的召回率对比,从中可以看出ToA的召回率最低,性能最差,它是最简单的相似性算法。timeSVD++的性能低于CDL 以及我们所提出的混合模型,但高于ToA 与ToU 算法,因此考虑时间因素是必要的,但是其未考虑辅助信息。所提模型的性能最佳,推荐的物品受用户喜欢数较多,且显著高于CDL,因为我们结合了S4VM,预先对冷启动物品进行初步预测,然后结合改进的LFM 模型进行预测,同时充分利用SDAE 隐藏层获得的电影特征,替换矩阵分解中的电影特征向量,因此可以进行对冷启动物品进行更准确的推荐。
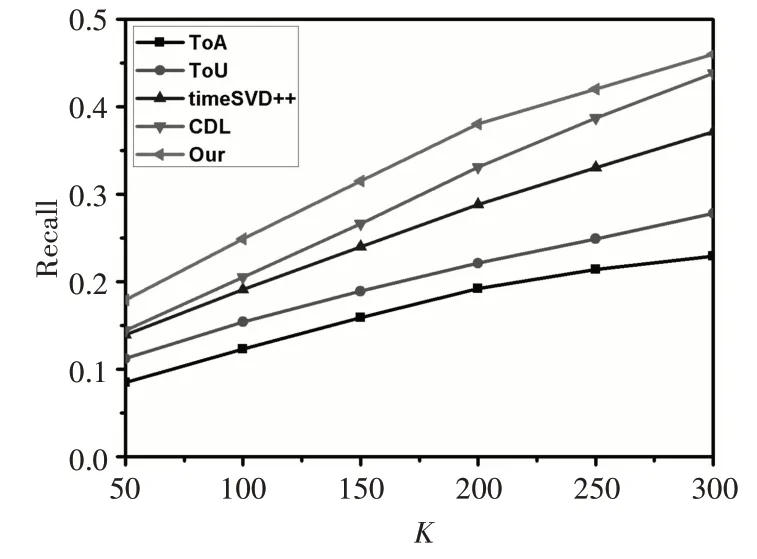
图3 召回率对比
在所提混合模型中,将参数λ设置为0.01,随机梯度下降中的学习率设置为0.004。与CDL模型一致,将噪声等级设置为0.3。由于使用到SDAE模型,其隐藏层的学习能力与编码机的层数设置有关,本次实验也对其层数进行研究,经过实验研究,将SDAE 的层数设置为4 层,其性能较单层的DAE提升0.79%。
5 结语
对于协同过滤存在的数据稀疏性与冷启动问题,本文提出了一种基于深度学习的混合协同过滤算法,既能预测冷启动物品的评分,又可以缓解数据的稀疏性问题,同时充分考虑到物品的属性以及时间因素的影响,从我们的分析和实验结果可知,物品的内容以及时间因素对推荐的影响是较大的,尤其是冷启动物品;我们所提出的算法性能显著优于其他算法,对冷启动物品的推荐精度和质量均有较大提高。
本文使用的是深度网络是SDAE,下一步工作考虑将其他深度学习网络与协同过滤融合,替换SDAE来提升更多的性能,例如CNN或RNN。
猜你喜欢
重庆大学学报(2022年6期)2022-06-23
小学生学习指导(低年级)(2022年5期)2022-05-31
汽车实用技术(2021年17期)2021-09-23
客联(2021年2期)2021-09-10
疯狂英语·初中天地(2021年11期)2021-02-16
少年漫画(艺术创想)(2019年2期)2019-06-06
读与写·教育教学版(2017年10期)2017-11-10
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
