
基于大数据模式识别机器学习算法的热力站动态能耗指标预测模型
2020-06-07 09:13:32张海增胡新华
电力大数据 2020年4期
王 炎,张海增,胡新华,赵 隽,李 添
(北京华源热力管网有限公司,北京 100025)
在集中供热系统中,由于用户需热情况复杂,受热力站及二次管网系统结构、供暖用户建筑物结构、保温情况、用户用热习贯和室外天气等多重因素影响,传统的计算方式多以调度人员的经验和一些计算公式无法准确获得合理热负荷预测值,其估算的调整结果容易出现用户室温不达标或室温偏高导致能源浪费等情况的发生[1]。针对上述情况,本文采用了大数据模式识别机器学习算法对各供热参数进行数据集合统计计算和分析,得出热力站热负荷和影响热负荷的各个因素之间的关系,从而准确高效地调节和控制用户室温,在节能降耗的同时提升供热舒适度[2]。
1 算法研究
1.1 数据采集和数据质量
实现大数据模式识别机器学习算法对各供热参数进行数据集合计算,其采集内容、采集频率和采集数据质量是关系到整个数据模型分析结果能否可用的关键重要因素。
目前,国内的热力站运行数据,通过SCADA系统、购买专业地区气象台数据、IoT(物联网)技术和热计量采集系统等方式获得。采集频率数据采集频率的设定,一般考虑如下三个方面的因素;一是SCADA系统的数据处理能力的限制;二是受到数据上传链路带宽和性能的限制;其数据传输时间间隔为不大于5分钟,三是IoT(物联网)数据,包括用户室内温度和热计量数据,其传输频率一般设置在10分钟到30分钟。天气预报一般以小时为最小采集单位。
数据采集质量的控制,关系到整个系统能否正常使用,确保数据质量满足如下三点;一是数据采集测点的稳定性的控制;二是设备采集精度的控制;三是对于天气预报等数据,要求数据传输接口的稳定性,必要情况下,可以通过冗余方法提供两个天气预报数据源[3]。
1.2 数据存储
实现大数据模式识别机器学习算法对各供热参数进行数据集合计算,数据存储架构是系统进行集合计算的保证。合理有效的数据存储方式关系到整个系统能否正常的使用。目前,有如下三种存储方法。
1.2.1 实时数据库
实时数据库的出现,主要是为了解决当时关系型数据库不太擅长的领域,包括:①海量数据的实时读写操作;②大容量数据的存储;③集成了工业接口的数据采集;④集成控制功能,可实现实时控制[4]。
1.2.2 关系数据库
关系数据库,是建立在关系模型基础上的,是由关系数据结构、关系操作集合、关系完整性约束三部分组成。关系数据库可以满足复杂的查询,这一点上要优于实时数据库,但是,将关系数据库应用于SCADA系统的时候,其缺点就暴露无疑了,主要表现在其并发处理速度低,一般为每秒1 000到3 000个读写请求;与实时数据库每秒200百万级的并发请求相差甚远。
1.2.3 大数据
“大数据" 通常指的是那些数量巨大、难于收集、处理、分析的数据集[7];其存储方式和结构与关系数据库和实时数据库完全不不同,采用列存储技术。其存储的内容为非结构化数据,其数据类型含盖了关系数据库所有数据类型;其最大的变化是其存储结构采用分布式结构;查询速度和复杂度远高于关系数据库。但其也存在一些缺点,其有效实时并发性能尚未达到实时数据库性能,数据接口标准处于严重匮乏阶段[5]。
以上三种数据存储方式,目前在SCADA系统中都有采用,比较新的理念是,采用实时数据库和大数据的架构共同完成对各供热参数进行数据集合分析计算。
1.3 数据计算
数据计算是实现大数据模式识别机器学习算法的工具,没有数据计算的基础理论作保证,其所有数据没有任何实际意义。因此,有效选择计算方法和基础数据准备是数据计算的根本[7]。
1.3.1 数据的辨析
基于大数据模式识别机器学习算法的热力站动态能耗指标预测模型,首先,要利用相关性分析原理合理的确定使用那些数据,在不断的试错中找出最为合理和有效的数据[8]。
(1)因变量。大数据模式识别机器学习算法对各供热参数进行数据集合计算,首先要求对数据采集样本进行有效选择。其中因变量的选择是非常关键的,依照一般的思维逻辑,选择热力站热负荷值(一次或二次)是首选,但在实际数据计算试错中,发现由于热负荷值采用了温度差和流量两个参量进行计算,其中流量的值容易出现跳跃,造成了因变量计算结果的差异。而采用供暖热力站二次送水温度作为因变量。具有温度变化平缓,不会出现跳跃,且其二次送水温度可以非常近似表示其热负荷的变化。
(2)自变量。自变量的选择,关系到整个预测模型的实际预测效果和相关性的程度,其中天气预报数据的选择为重点。采用全天24h4个时段的平均天气预报温度、风力以及湿度和照度等,可以最大限度减少预报室外环境参数的偏差;其历史记录的室外环境温度、风力、湿度和照度为当时的地区以小时为时间间隔实际室外环境参数。
供热用户室内温度,是以各个热力站对应的典型室内测量温度为参考,在测量室内环境温度时应加入偏移量补偿措施,使其获得的室内环境温度尽可能的准确。
供热用户室内环境温度的设置,按照国家供暖规定,在供暖季,用户室内温度不得低于18℃,考虑到供热用户的舒适度要求,将供暖季室内温度设置四个时段,分别为上午、下午、夜晚和凌晨;四个时段的用户室内环境温度设定值分别为22℃、20℃、22℃和18℃;考虑到其为典型用户,实际应用中可能会出现正负2℃的偏差。
1.3.2 数据抽取
数据的抽取,关系到所获数据质量是否符合标准的关键节。
(1)数据抽取的环境。为了保证数据抽取的成功和便于下一步的查询和分析,利用大数据架构,将实时数据库采集的数据,通过接口以统一的时间间隔(5 min)将需要进行分析计算的数据抽取转储至大数据结构节点服务器中存储。
(2)数据抽取原则。将实时数据库中,各个热力站的热负荷、二次流量、二次送、回水温度、一、二次压力、调整阀门开度、变频数据;对应地区的小时天气预报中实时室外环境温度、风力、照度和湿度,对应地区的次日小时天气预报中的室外环境温度、风力、照度和湿度;各个热力站对应典型供热用户室内温度等关键数据以时间顺序抽取存储到大数据节点服务器中。
1.3.3 数据清洗
数据清洗工作,是对大数据计算分析的数据清洗,是发现并纠正数据文件中可识别错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。
(1)将抽取的数据依照时间序列进行判断,将系列数据任一时间点的数据出现缺失、错误的数据依照其所在的时间段进行整段删除。重点关注典型室内环境温度出现异常,热力站热负荷和流量出现严重跳跃,天气预报实时数据缺失三种情况;
(2)将抽取的数据中不在供暖期间的数据和特殊供暖期(出现一次系统供热故障)的数据进行整时段删除。
1.4 大数据分析
大数据分析是指用适当的统计分析方法对收集来的大量数据进行分析,提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。这一过程也是质量管理体系的支持过程。在实用中,数据分析可帮助人们做出判断,以便采取适当行动[9]。
1.4.1 欧式距离
欧几里得度量(Euclidean metric)(也称欧氏距离)是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离。
欧式距离算法公式:
(1)
(1)算法描述。热力站热负荷分析的目的,利用大数据节点服务器中存储的已经清洗的数据,将供暖季室内温度设置四个时段,分别为上午、下午、夜晚和凌晨;四个时段的用户室内环境温度设定值分别为22℃、20℃、22℃和18℃;将时间序列数据中各个换热站的典型室内温度、对应该地区的室外温度和室外风力历史值作为依据计算出其欧氏距离值。由此计算出依照时间序列生成为欧式距离数据集,并取其最小值所对应的时间序列[10]。
(2)具体算法公式。
(2)
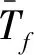
(3)时间序列数据集的选择。欧式距离数据集时间段的选取原则为最少150个供暖日,如果要将雪天和湿度参与计算,考虑到其样本数量在一个供暖季中出现的天数很少,其分析数据集时间段的选择可以不进行限制。
1.4.2 复相关系数
复相关系数是测量一个变量与其他多个变量之间线性相关程度的指标。它不能直接测算,只能采取一定的方法进行间接测算,是度量复相关程度的指标。复相关(多重相关)的实质就是Y的实际观察值与p个自变量预测的值的相关。
热力站热负荷分析和计算,如果在已清洗的数据当中能够检索到其欧式距离为0的时间序列记录,就可以直接引用该时间序列对应的热负荷值作为次日对应时段的负荷预测值,其算法简单有效。但是,当其最小欧式距离为不为0的时候,就会发现,需要对最新的预测值进行系数修正,这个系数如何确定,这就需要用到复相关系数。
可以利用其热力站热负荷与室内环境温度、室外环境温度、室外风力的最大复相关系数(一般在0.85-0.99之间);将获得一定时间段的内最大复复相关系数减去1的绝对值(0.01-0.115)作为修正系数,实现对热力站热负荷的预测。
(3)
(4)
(1)算法描述。首先,要求进行数据的辨析,选择合理因变量和自变量是保证其算法有效的关键;在1.3.1数据的辨析中,已经对因变量和自变量的选择辨析进行了详细的分析。将二次供水温度作为因变量,当其温度提高时,其对应的室内温度会与室外环境(温度、风力等)产生一个相关性,但这种相关性需要一个延迟时间,通过固定时间步长的迭代计算复相关系数,多长延迟时间后,二次供水温度的变化与其对应的室内温度会与室外环境(温度、风力等)相关性最强,就将该时刻的最大复相关系数和时间标作为的修正系数和延迟时间[11]。
利用统计学中的计算模型,依照时间序列按照固定时间步长将自变量集迭代导入就可以计算出时间序列的复相关系数序列;如果其下一个复相关数小于前一个复相关系数,就得出了其在此时间序列中的最大复相关系统,否则该时间系列复相关系数无效。具体算法公式:
(2)具体算法公式。
(5)
(6)
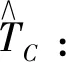
(3)时间数列历史时段的选择。为了保证复相关系数的有效性,通过不断的试错和依据热力站热负荷的实际,选择的时间数据列为其为欧式距离计算点对应时间标前后6个小时,作为复相关系数时间序列数据集的计算分析数据源。其时间段过长或过短都对其计算结构产生一定的影响,如图1所示。
图1通过热力站二次送水温度,与室内环境温度,室外环境温度、风力,计算出的时间序列复相关系数(R)
Fig.1 Time series complex correlation coefficient(R)calculated by secondary water supply temperature of thermal power station,indoor ambient temperature,outdoor ambient temperature,wind power
(4)热负荷预测算法。
(7)
(5)延迟时间算法。热力站热负荷计算还存在一个非常关键的问题,迟滞时间Dt;这是供热行业一个特有的现象,由于热力站与供热用户由二次热网管线连接,热量的输送需要一定的时间,同时供热用户的保温情况,户外环境温度和风力大小,以及雪天和照度对用户温度的影响,都会给供热用户到热力站之间热传导产生一个动态的延时。如果能够通过算法分析将此迟滞时间计算出结果。就可以提前一定延时时间对热力站进行调整,在预定时间,使其室内温度达到设定值,解决了热力站热负荷预测这一难题。
延迟时间为时间序列相关性分析数据集合,从开始时刻通过迭代计算得到到其复相关系数最大值时刻的时间差;该时间差的精度与其分析数据集的时间间隔密切相关,建议采用不大于10 min的时间间隔进行计算,如图2所示[12]。
其延迟时间为Dt=90分钟,其R(lmax)最大值为0.962;K=0.038
预测热负荷Qf=3.67(凌晨0时-8时)。
(6)热力站热负荷预测的逻辑流程图如图3所示。
1.5 数据验证
实现大数据模式识别机器学习算法对各供热参数进行数据集合计算,是一个无量纲的计算分析过程,期间除了补水热负荷计算引用了热力学计算公式外,其它的计算方法完全遵循了统计学的基本原理和计算模型。
1.5.1 数据清理在计算分析中起这举足轻重的作用
在数据采集和数据抽取过程中,无效和坏的数据随时都会发生,建立起一套完整有效数据清理方法是非常必要的,需要遵循如下要点:
(1)要保证时间顺序数据类历史记录间隔的基本一致性,可以通过数据抽取存储来处理,也可通过时间差值算法进行数据整理。
(2)要保证时间顺序序列数据的完整性,一旦有某个数据失信,就要自动将整个时间段的序列数据排除掉,一般为6个小时或24个小时。
(3)要严格把好数据清理关,只存储供暖季的数据,对一些容易失效的数据,可进行冗余数据处理。
1.5.2 在复相关系数分析计算中,要注意排错处理
在利用已经清理好的数据进行分析计算时,出现错误的计算结果是无法避免的。所能够做的,就是将错误计算结果的数据丢弃,选择另一段数据进行重新计算,直到出现最大复相关系数为止。
1.6 模型优化
实现大数据模式识别机器学习算法热力站热负荷进行分析计算,还有很长的路要走,随着数据量的不断积累和数据的深入验证,有可能将雪、日照和湿度等更多的因素加入进来进行分析和运算,同时,也可以对室内温度的采集和计算方法进行不断的优化和完善。该模型算法思想和理论可延伸到一次热网的运行状态的预测和分析当中,其迟滞时间的创造性算法对整个热力行业具有深远的意义,如图4所示和图5所示[13]。
2 结语
本文运用大数据模式识别机器学习算法建立了热力站动态能耗指标预测模型。相比人为手工计算,机器学习的好处是运行速度快,随着不断地学习和有效样本的增加,预测的准确性也逐步提高,通过对模型的不断调整和优化为供热精确调节打下了坚实的基础[14-17]。
本文简单地选取了6座热力站近40天热负荷作为样本输出。而实际的情况却更为复杂。延迟时间受多方面因素影响,每一户的延迟时间都可能不同。可以考虑采用机器学习的方式来学习每一个用户的热传导延迟时间,进一步提高预测准确性[18]。
猜你喜欢
建材发展导向(2022年6期)2022-04-18 08:17:40
煤气与热力(2022年3期)2022-03-29 07:49:02
煤气与热力(2021年10期)2021-12-02 05:11:42
Bone Research(2021年2期)2021-09-11 06:02:56
中国宝玉石(2018年3期)2018-07-09 03:13:52
汽车维护与修理(2016年10期)2016-07-10 08:17:41
工程建设与设计(2016年1期)2016-02-27 10:50:31
风能(2015年4期)2015-02-27 10:14:38
振动、测试与诊断(2014年1期)2014-03-01 01:13:44
河南科技(2014年24期)2014-02-27 14:19:40
