
基于轻量自动残差缩放网络的图像超分辨率重建
2020-06-07 07:07王永梅牛子未
计算机应用 2020年5期
代 强,程 曦,王永梅*,牛子未,刘 飞
(1.安徽农业大学信息与计算机学院,合肥230036; 2.南京理工大学计算机科学与工程学院,南京210094)
(∗通信作者电子邮箱wym@ahau.edu.cn)
0 引言
图像超分辨率重建技术具有非常广阔的应用前景,在视频游戏、高清音视频、医学成像等许多领域具有很高的实用价值。单幅图像超分辨重建是一个典型的计算机视觉问题,旨在将低分辨率(Low-Resolution,LR)图像重建为高分辨率(High-Resolution,HR)图像。此外,神经元科学领域的信息门控以及注意力机制[1-2]的思想对于构造出更好的单幅图像的超分辨率重建网络影响很大。随着深度学习的不断发展,深度学习已应用于许多图像超分辨率重建任务。与早期算法相比,卷积神经网络具有更高的性能。AlexNet[3]在图像识别中的出色表现使深度卷积神经网络成为当今的研究热点。之后,VGG[4]证明了通过加深卷积神经网络各层来增强识别性能的方法,但是,随着网络的深入,模型的训练变得越来越困难。为了解决这个问题,Highway Network[5]被提出,随后的深度残差网络(deep Residual Network,ResNet)[6]使极深的网络模型成为可训练的。卷积神经网络在早期只用于识别任务,但是后来发现卷积网络在许多领域都具有巨大的价值,例如目标检测[7-8]、图像语义分割[9-10]和图像风格迁移[11-12]等。图像超分辨率重建是计算机视觉领域的重要任务,诸如最近邻插值、双线性插值和双三次插值之类的早期插值方法已在各种软件中广泛使用。然而,以上图像重建方法几乎不能达到令人满意的水平。
Yang等[13-14]提出了基于经典稀疏编码的图像超分辨率重建方法,并取得了良好的效果;Salvador等[15]提出了贝叶斯方法来完成图像超分辨率重建任务;Timofte等[16-17]通过锚定邻域回归提出了调整后的基于邻域快速回归的快速的超分辨率方 法(Adjusted Anchored Neighborhood Regression for Fast Super-Resolution,A+)。这些模型进一步改善了图像的峰值信噪比。Huang等[18]提出了具有图像自相似的单幅图像超分辨率方法(single image Super-Resolution from transformed Self-Exemplars,SelfExSR)模型,针对纹理自相似的图像具有更好的还原效果。近年来,许多基于深度神经网络的单幅图像超分辨率重建模型被提出进一步提高了重建性能。Dong等[19]提出了基于卷积神经网络的超分辨率方法(Super-Resolution Convolutional Neural Network,SRCNN),SRCNN是深度学习在图像超分辨率重建上的开山之作,对于一个低分辨率的图像,SRCNN首先采用双三次插值(bicubic)将低分辨率图像放大成目标尺寸,接着通过三层卷积网络拟合非线性映射,最后输出高分辨率图像结果。后来,文献[20-21]提出用于稀疏先验的图像超分辨率的深层网络(Deep networks for image superresolution with sparse prior,CSCN),且具有更高的重建性能。Shi等[22]通过高效的亚像素卷积神经网络实现了实时图像和视频超分辨率重建,该方法在低分辨率空间中提取特征图,同时引入了一个有效的子像素卷积层,该层学习了一个升序滤波器阵列,将最终的低分辨率特征图升级到高分辨率输出,这样可以有效更换超分辨率通道中的双三次插值滤波器,并为每个特征图进行专门训练以获得更复杂的升频滤波器,同时还降低了整个超分辨率操作的计算复杂度。Lai等[23]提出了一个基于拉普拉斯金字塔网络的图像超分辨率重建模型(Laplacian Pyramid Super Resolution Network,LapSRN),该模型的每一级的金字塔都以粗糙分辨率的特征图为输入,用解卷积来升采样得到更精细的特征图,此外该模型可以通过一次正向计算实现多尺度的超分辨率重建。后来,Ren等[24]提出了一种具有k-均值和卷积神经网络的单幅图像超分辨率重建方法,该方法不仅利用卷积神经网络的深度学习能力,而且使它们适应于描绘纹理多样性以实现超分辨率重建。Tai等[25]提出了利用局部残差学习和全局残差学习的通过深度递归残差网络实现图像的超分辨率方法(Image Super-Resolution via Deep Recursive Residual Network,DRRN),该模型中的每个残差单元都共同拥有一个相同的输入,该模型中的每个残差单元都包含2个卷积层,在DRRN中的每一个递归块内,残差单元内对应位置相同的卷积层参数都共享。Tong等[26]也利用密集连接建立了一个超分辨率重建网络,该模型引入了一个由递归单元和门单元组成的存储块,通过自适应学习过程准确地挖掘持久性存储器。递归单元在不同的接收域下学习当前状态的多级表示,该模型在各层之间密集地连接特征图,并取得了很高的性能。
本文提出了一个具有自动残差缩放功能的轻量级网络(light-weight Network with Automatic Residual Scaling,ARSN),并与加速超分辨率卷积神经网络(Fast Super-Resolution Convolutional Neural Network,FSRCNN)[27]、使用超深度卷积网络的精确图像超分辨率方法(accurate image Super-Resolution using Very Deep convolutional network,VDSR)[28]、用于图像超分辨率的深度递归卷积网络方法(Deeply-Recursive Convolutional Network for image super-resolution,DRCN)[29]、用于图像还原的持久性存储网络(persistent Memory Network for image restoration,MemNet)[30]等网络比较了网络输入、层数、是否使用残差学习等参数。如表1所示,这些方法的网络层数趋于越来越深,而本文方法网络权重相对较轻,层数少得多。同时,本文方法可以直接输入低分辨率图像而无需进行双三次插值,这可以减少额外的计算。
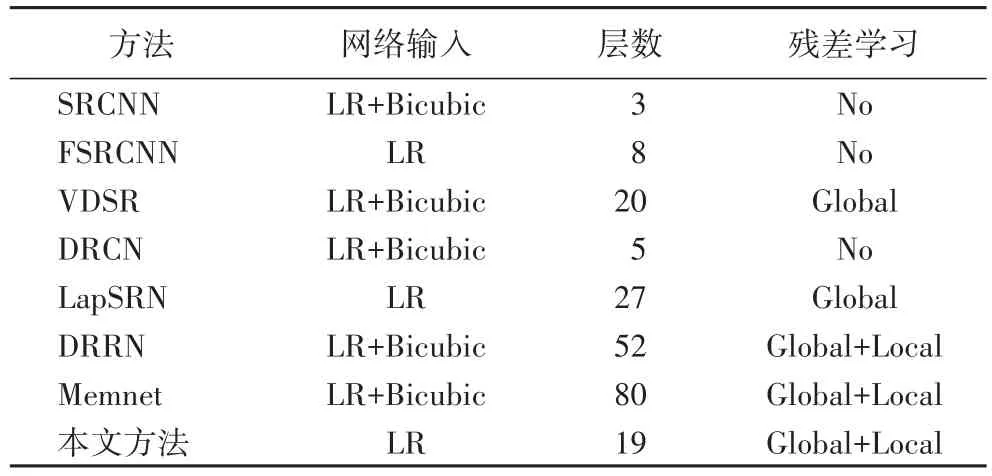
表1 先进方法概述Tab.1 Overview of state-of-the-art methods
1 本文方法
1.1 模型结构
ARSN的基本结构如图1所示,该模型包含几个用于特征提取的特殊残差块,残差块的数量可以根据实际情况增加或减少,所有残差块的输出通过跳跃连接在级联层中连接,然后使用重建网络来重建出高分辨率图像。
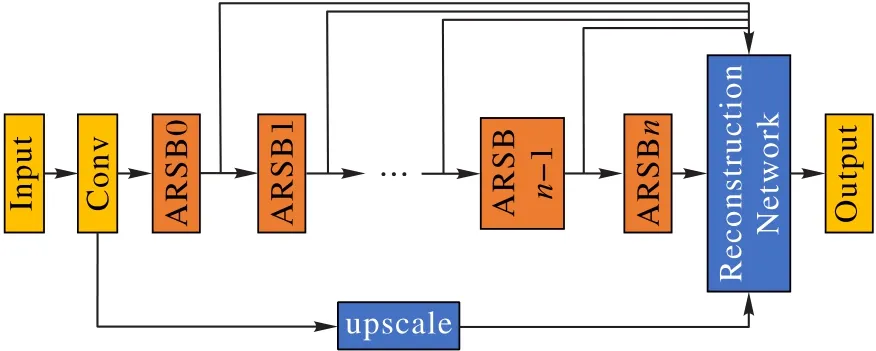
图1 ARSN的结构Fig.1 Structure of ARSN
1.2 残差模块
如图2所示,每个残差块包含两个卷积层,每个卷积层包含64个具有3×3内核大小的卷积核,以保持输出特征图的比例。

图2 特定残差块的结构Fig.2 Structure of a specified residual block
残差块中的第一卷积层通过参数整流线性单元(Parametric ReLU,PReLU)[31]激活函数。PReLU的公式如下所示:
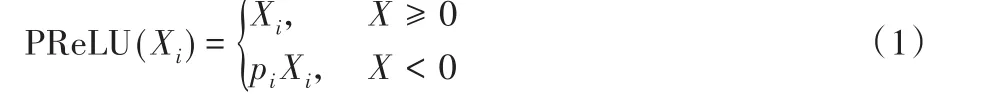
pi用式(2)进行权重更新,其中μ是动量,ϵ是迭代的学习率,而ε是损失函数。

与标准残差网络和SrResNet中的残差块不同,本文提出的模型中的残差块会删除无用的批标准化层。Szegedy等[32]发现添加特征图将使模型的训练变得不稳定。因此,按照Szegedy等[32]和Lim等[33]的方法,本文提出的模型在残差块的第二个卷积层之后添加残差门控。
根据最新流行病学资料显示[7-8],全球糖尿病患者人数在3.8亿左右,是目前最为严重的代谢性疾病之一,严重影响患者的生活质量和生活健康。糖尿病患者往往存在多饮、多食、多尿以及身体消瘦等临床症状,对糖尿病患者进行中医护理具有重要意义。中医认为人体是一个有机的整体,强调人与自然、环境的相互统一,中医学中,糖尿病(消渴)病机是阴津亏损、禀赋不足以及燥热偏盛等,所以强调在疾病的治疗和康复中保证患者的生活护理质量,从整体的角度出发。其次,中医特色护理具有个性化特征,针对不同个体患者和患者疾病的不同阶段[9],在中医辨证的基础上进行个体化指导,能够让治疗具有针对性,促进患者的康复。
如图3所示,本实验研究了残差块的4种不同结构。
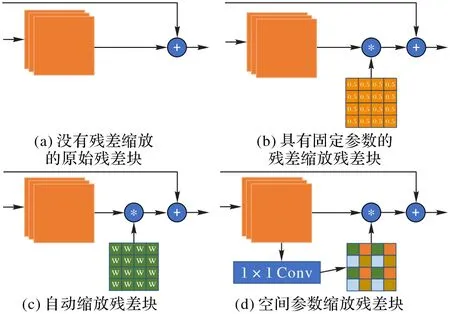
图3 不同残差块的结构Fig.3 Structure of different residual blocks
本文提出模型中的残差块可以表示为式(3):

其中:xi是一个残差块的输入;xi+1是输出;G表示残差缩放门;W1、W2是每个卷积层的权重;δ表示PReLU激活函数。
1.3 重建网络模型
本文在重建网络中利用了全局残差学习,这可能会导致网络的主要分支学习或预测图像的细节。ARSN还使用了亚像素重组(subpixel shuffle)来放大低分辨率图像,实验发现与简单的反卷积层或双三次插值相比,全局残差可以更快地收敛并产生更好的质量。主要的重建过程如图4所示。
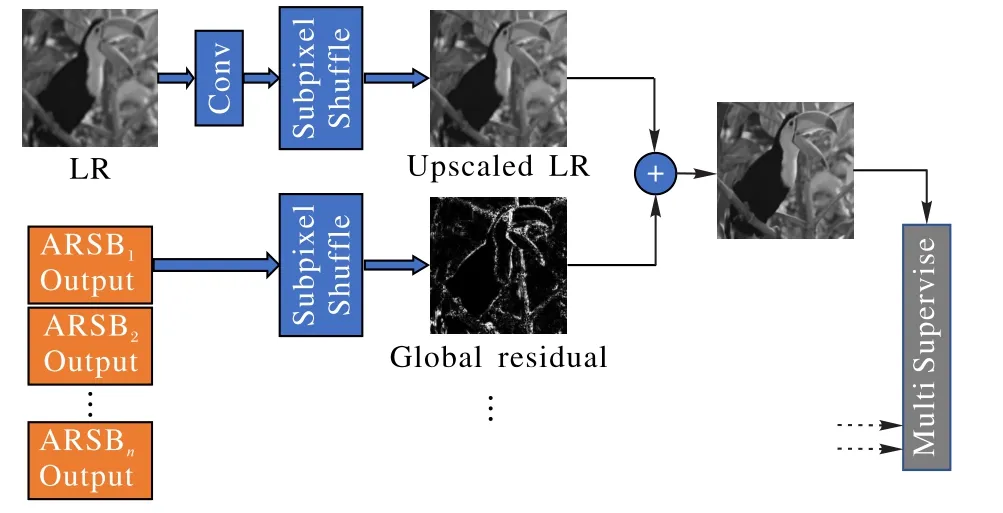
图4 重建网络的结构Fig.4 Structureof reconstruction network
实验还使用称为多重监督的重建网络监督ARSN的每个输出。通过最小化模块的平均L1损失来训练模型,可以在式(4)中看到:
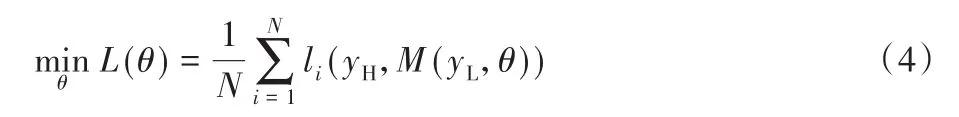
其中:L表示总损失函数;N表示自动残差缩放块的数量;yH和yL表示高分辨率标签图像和低分辨率输入图像;M代表本文提出的神经网络从低分辨率到高分辨率的映射;θ代表要优化的网络参数。
2 实验过程与结果
2.1 数据集
在实验中,DIV2K数据集用于训练模型。将训练图像随机旋转或翻转作为数据增强。所有RGB图像都被转换到YCbCr色彩空间,在训练期间仅使用其Y通道。另外,还使用BSD100[34]、Set5[35]、Set14[36]和 Urban100[18]作为测试集来评估模型的性能。
2.2 训练细节
实验硬件配置:CPU为Xeon 48 Cores,GPU为NVIDIA Tesla P40,256 GB内存。软件环境:Ubuntu16.10,CUDA8.0/CUDNN5.1,PyTorch 0.2。本文模型使用PyTorch作为框架来构建超分辨率模型,并使用并行计算机架构(Compute Unified Device Architecture,CUDA)来加快训练速度。将初始学习率设置为0.000 1,并且在60个epoch后会降低。实验还使用Adam优化器来最小化损失函数,并训练了120个epoch。初始残差比例因子设置为0.25,并将在训练模型时自动更新。动量设为0.9,权重衰减设为0.001。将256张图像设置为mini batch,以供输入模型。
2.3 实验结果

使用8位图像,因此n值为8,此外,均方误差(Mean Squared Error,MSE)可以用式(6)表示:
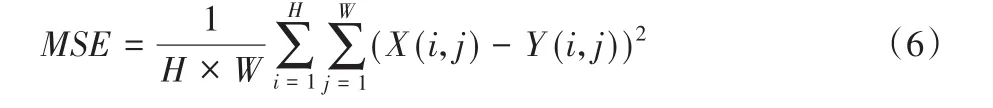
本文仅使用YCbCr图像的Y通道,对于单通道输入,公式中的W和H表示输入图像的宽度和高度,X和Y表示原始图像和生成图像。
表 2和表 3显示了 Set5、Set14、BSD100和 Urban100上scale x2和scale x4超分辨率任务的方法的结果,最好的结果用加粗标记,第二好的结果用下划线标记。
2.4 超分辨率结果的视觉比较
作为比较示例,本文从BSD100数据集中选择了3个图像,分别是img_052、img_039和img_084。本文将传统的重建方法,包括本文将传统的重建方法,包括双三次差值、A+、SelfExSR,基于深度学习的方法,包括SRCNN、VDSR、DRCN、LapSRN与本文提出的ARSN进行了比较,如图5所示。

图5 本文模型与现有方法的定性比较Fig.5 Qualitativecomparison between ARSNwith existingmethods
从图5可以看出,ARSN在细节和纹理上都有较好的表现:图5(a)只有ARSN可以正确重建斑马线上的纹理,而其他对比方法则会使线条模糊;图5(b)显示本文方法在重建一些难以恢复的密集纹理时具有较少的错误;图5(c)的结果表明,与现有方法相比,本文方法在重建图像细节上的性能更加优异。
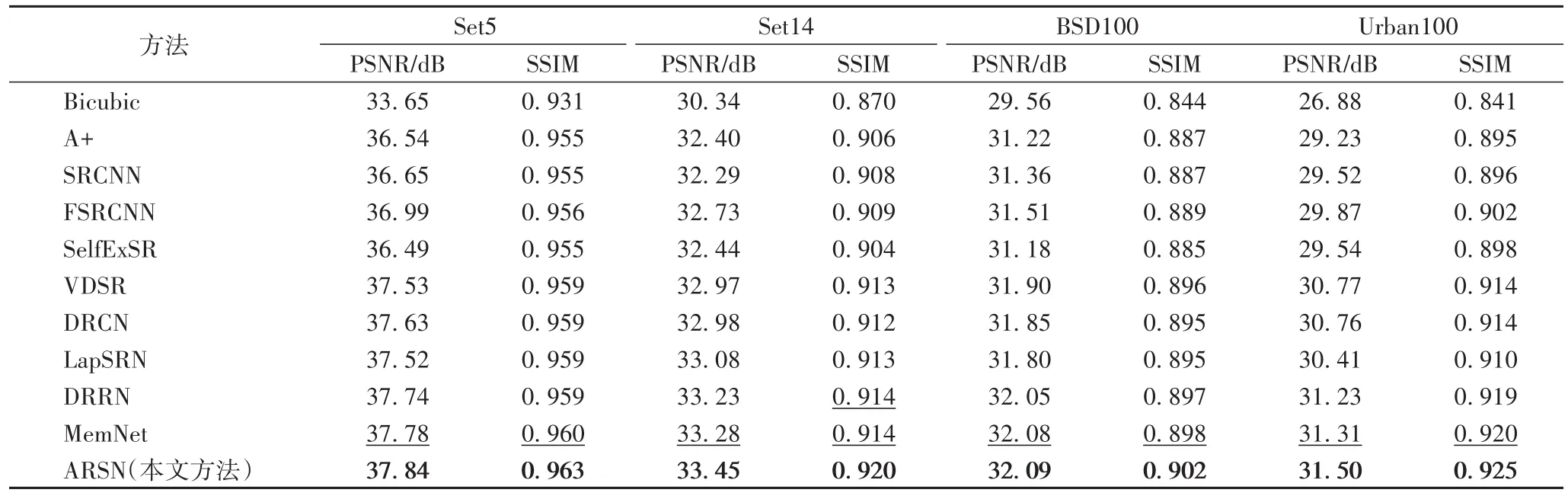
表2 数据集Set5、Set14、BSD100和Urban100上的scale x2的PSNR和SSIMTab.2 PSNRand SSIMof scalex2 on Set5,Set14,BSD100 and Urban100 datasets
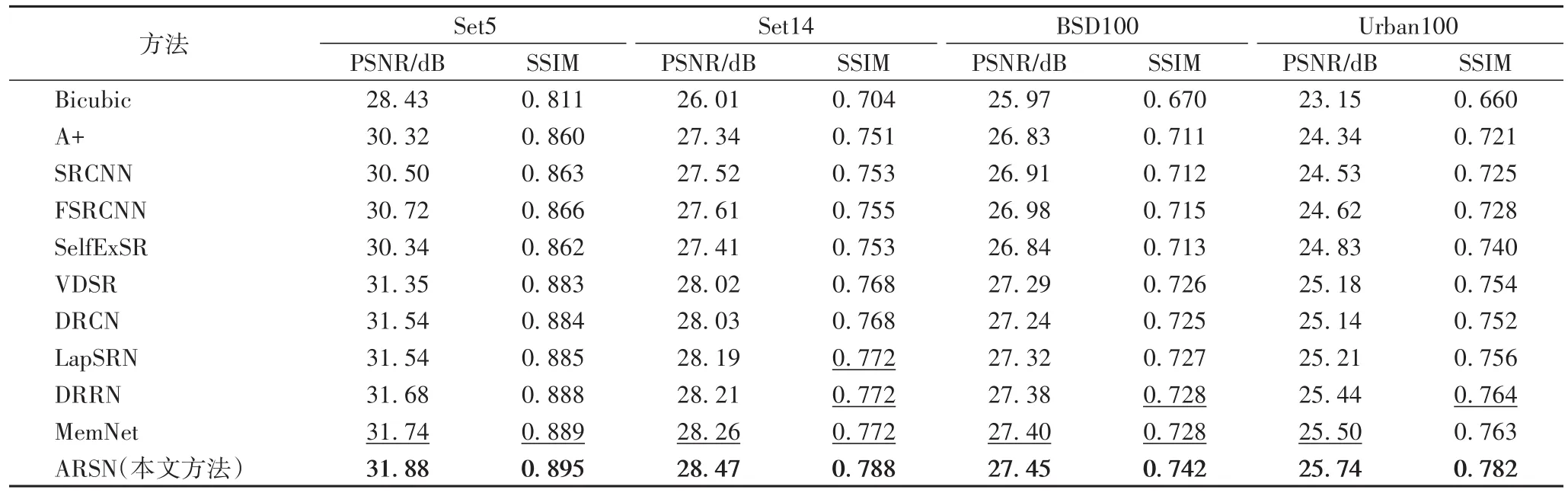
表3 数据集Set5、Set14、BSD100和Urban100上的scalex4的PSNR和SSIMTab.3 PSNRand SSIMof scalex4 on Set5,Set14,BSD100 and Urban100 datasets
2.5 参数数量与性能比较
模型参数的数量会影响模型的速度和硬件占用率,而较少的参数可以有效地减少计算量。图6显示了本文提出的ARSN与其他先进模型参数的比较以及在Set14测试集上的图像重建性能的比较。

图6 不同模型参数数量和PSNR值比较Fig.6 Comparison of thenumber of model parametersand PSNR valuesof different methods
图6包括与DRRN、LapSRN、带有跳跃连接且可以快速而准确的实现图像超分辨率方法(Fast and Accurate Image Super Resolution by Deep CNN with Skip Connection and Network in Network,DCSCN)[37]、VDSR、DRCN、MemNet和使用具有对称跳跃连接的非常深的卷积编码器/解码器网络进行图像恢复的方法(image restoration using very deep convolutional encoderdecoder networks with symmetric skip connections,RED30)[38]等网络模型,可以看出ARSN在Set14测试集上具有更高的PSNR值,并且模型的参数也较少。
3 讨论
3.1 残差块数
在ARSN模型中,每个残差块包含两个卷积层,残差块的数量控制模型的深度。随着残差块数的变化,模型的性能将在一定程度上变化,但是,残差块数量的增加将大大增加模型中参数的数量,过多的残差块会降低模型的速度。因此,为了使模型具有较高的性能和速度,找到合适数量的残差块是非常重要的。实验在NVIDIA Tesla P40显卡上进行测试,测试了不同数量的残差块的时间和内存消耗,结果显示见表4。本文使用BSD100测试集测量内存消耗和运行时间,该测试集包含100张分辨率为480×320的图像。此外,本文使用Python中的时间库来计算这些图像之间的平均运行时间。
从表4中可以看出,随着残差块数的增加,模型的性能会更好,但是当残差块数的数量超过7时,模型的性能几乎没有提升而内存消耗和运行时间却增加了很多,所以,从实际的角度来看,为了确保模型的实时速度和低内存占用率,应将残差 块的数量控制在7个以下。
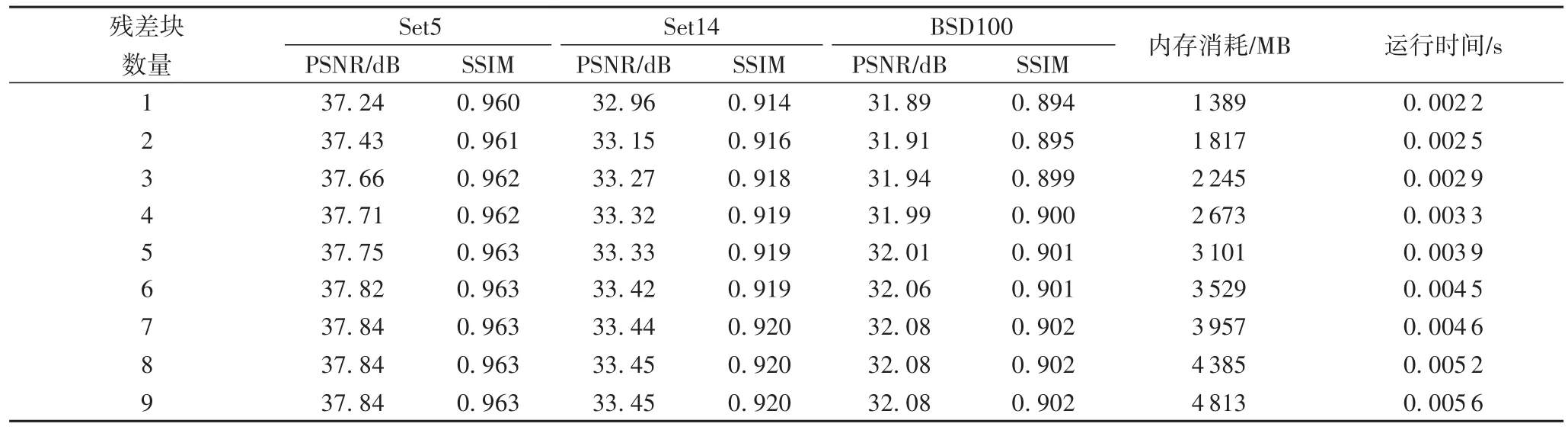
表4 不同数量的残差块的性能比较Tab.4 Performancecomparison of different number of residual blocks
3.2 滤波器个数
每个卷积层中的滤波器数量会影响模型的性能和参数数量。数量太少会导致性能不佳,但是,如果数量太大,模型的训练将变得不稳定,模型的速度将大大降低,因此有必要找到合适数量的滤波器。表5中显示了模型性能与每个卷积层中滤波器数量之间的关系。本节以和第3.1节中相同的方式测量GPU内存消耗和运行时间。
从表5中可以看出,当滤波器的数量超过64时,模型的性能会下降,但GPU内存消耗和运行时间却会增加很多。这是由于当滤波器数量过大时,模型中的参数数量很大,模型的训练将会变得非常困难,往往会出现过拟合,模型的性能也会降低,所以选择合适的滤波器数量是非常重要的。

表5 每层中不同数量滤波器的性能比较Tab.5 Performancecomparison of different number of filtersin each layer
3.3 激活函数
本节研究残差块中卷积层之间的激活函数。实验用7个残差块固定模型,并将模型性能与Sigmoid、ReLU、PReLU和Swish[39]进行比较,实验结果见表6。
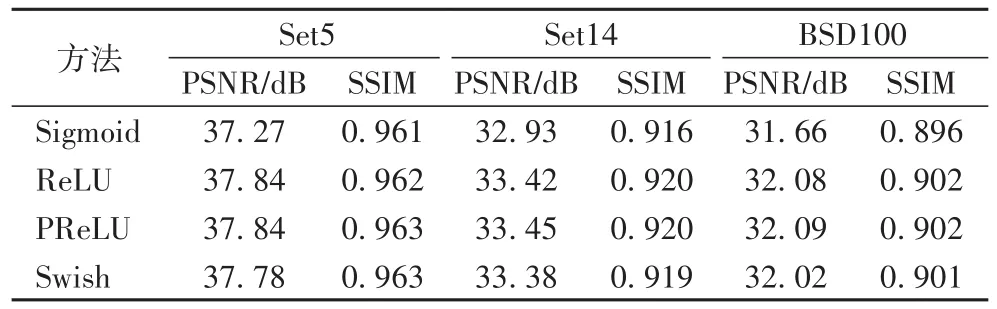
表6 不同激活函数的模型性能表现Tab.6 Performanceof models with different activation functions
如表6所示,根据PSNR,ReLU和PReLU在Set5中获得了相似的结果,但是PReLU在Set14和BSD100中更好。Sigmoid的成绩最差,仅在Set5中得分37.27。事实证明,Swish在其他任务(如图像分类)中具有更好的性能,而实验发现这种方法不适用于超分辨率重建任务。
3.4 残差缩放
本节主要研究残差缩放如何影响最终模型的性能。从3.1节的实验中可以得出,当残差块数量为7时,模型的性能最好,所以在本节研究残差缩放如何影响最终模型的性能的实验中,用7个残差块固定了模型,并比较了有0.5缩放因子的固定缩放(Fixed parameter)、自动残差缩放(Automatic scaling)以及空间参数缩放(Spatial parametric scaling)等三种缩放对最终模型的性能影响,其中没有使用缩放的模型(Original residual)用来作实验对比。
从表7的实验结果得出使用了缩放的模型在SSIM中获得了相似的分数,而自动缩放在PSNR的3个测试集中获得了第一名,然后是固定因子缩放和空间参数缩放,而没有使用缩放的模型的实验结果是最差的。

表7 不同残差缩放的模型性能表现Tab.7 Performanceof modelswith different residual scalings
4 结语
本文提出了一种具有自动残差缩放而且可用于单幅图像的超分辨率重建的轻量网络。与其他对比模型相比,本文提出的模型大幅减少了参数数量,并具有实时重建图像的能力。本文提出的模型已经在许多标准测试数据集上进行了测试,其性能达到了很高的水平。与之前提出的加深的超分辨率卷积神经网络模型相比,该模型具有更好的性能以及更高的实时处理能力;此外,该方法大幅减少了模型参数和计算量。因此,该模型具有较高的实用性。将来,它可以在诸如智能电话和物联网监视系统的终端设备中使用,改善其成像性能。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
成都信息工程大学学报(2022年2期)2022-06-14
北京大学学报(自然科学版)(2022年1期)2022-02-21
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
北京航空航天大学学报(2020年10期)2020-11-14
家庭影院技术(2020年2期)2020-03-25
北京航空航天大学学报(2019年9期)2019-10-26
CHIP新电脑(2016年3期)2016-03-10
