
基于生成对抗网络的文本图像联合超分辨率与去模糊方法
2020-06-06 02:07陈赛健朱远平
计算机应用 2020年3期
陈赛健,朱远平
(天津师范大学计算机与信息工程学院,天津300387)
(*通信作者电子邮箱zhuyuanping@tjnu.edu.cn)
0 引言
图像的超分辨率和去模糊通常被分开处理,但本文提出了一种联合的超分辨率与去模糊方法以处理低分辨率的模糊图像。这类图像通常是由于相机远离目标对象,并且相机和目标对象之间存在相对运动而产生的。从模糊的低分辨率(Low-Resolution,LR)图像中重建出清晰的高分辨率(High-Resolution,HR)图像,不仅提高了图像的视觉效果,还有利于其他的视觉任务,如目标检测[1]和识别[2]。
顺序地使用现有的超分辨率[3]和去模糊方法[4]来处理这个联合问题是一种自然的思路,但这种策略面临诸多问题:一方面,两个模型之间的简单连接使得第二个模型放大了第一个模型的估计误差,重建的HR 图像存在严重的伪影;另一方面,这种组合方式不能充分利用两个任务之间的相关性,而且需要分别训练模型,这造成大量的时间消耗。
针对上述问题,本文提出了一个高效的端到端的生成式对抗网络(Generative Adversarial Network,GAN)来处理这个复杂的联合问题。生成器由两个模块组成,首先上采样模块对输入的低分辨率模糊图像进行4 倍上采样,输出超分辨率(Super-Resolution,SR)图像;然后通过去模糊模块重建去模糊的SR图像。由于输入图像的低分辨率和严重的模糊退化,上采样模块生成的SR 图像通常是模糊的并伴有令人不悦的伪影,利用这种双模块结构有利于最终重建出清晰的SR文本图像。在鉴别器中使用全局平均池化层(Global Average Pooling,GAP)来减少模型参数。此外,引入了一个联合的损失函数,其由超分辨率与去模糊的集成像素损失、基于文本图像先验的特征匹配损失以及对抗损失组成,它们分别在像素、语义层和高频细节方面迫使重建图像与真实的HR 图像相似。本文所提模型不含批量归一化层(Batch-Normalization,BN),并且大多操作在LR 空间执行,因此大大降低了计算成本。实验结果表明本文方法能够处理更真实的退化图像,获得比现有算法更好的重建效果。
1 相关工作
1.1 图像超分辨率
传统的图像超分辨率算法主要采用稀疏编码[5]、自相似性[6]等。 近 年 来,卷 积 神 经 网 络(Convolutional Neural Network,CNN)在图像超分辨率方面得到了广泛的应用[7-9],并取得了比以往方法更好的效果,然而,这些峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)导向的方法不能很好地反映图像的视觉质量,因此,感知驱动的方法[3,10]被提出。它们可以重建更逼真的图像,但是大多数的SR算法都是针对简单的双三次退化而设计的,当输入的LR图像具有复杂的模糊退化时不能表现良好。
1.2 图像去模糊
现有的盲图像去模糊算法大多都涉及到模糊核的估计步骤[11-12],然而,不精确的核估计会导致去模糊图像具有严重的振铃伪影。最近基于CNN 的方法[4,13]省略了核估计,能有效地处理图像模糊问题,但是对于低分辨率的模糊图像,这些方法无法放大空间分辨率,并重建出清晰的图像细节。
1.3 联合的图像超分辨率与去模糊
联合的超分辨率与去模糊问题引起较少的关注,但在现实世界中经常能遇到模糊的LR 图像。一些方法[14-15]利用光流估计来重建清晰的HR 图像,但不适用于单幅图像输入。Xu 等[16]提出SCGAN(Single-Class GAN)模型能有效地超分辨率模糊的文本图像,但与之不同的是本文使用深层的双模块网络去重建更清晰的高分辨率文本图像,同时所提方法的计算效率更高,鲁棒性更强。Zhang 等[17]为处理这个联合问题提出了一个深度编码-解码网络,但该网络只聚焦于简单的均匀高斯模糊退化的LR 图像。Pan 等[18]提出的基于物理的生成对抗模型能处理图像去模糊、图像超分辨率等图像复原问题,但与本文不同的是该模型不能联合处理图像的超分辨率与去模糊问题,只能单独分开实现。Zhang 等[19]提出了一个门控融合网络(Gated Fusion Network,GFN)来超分辨率模糊的LR图像,但是该模型是为具有运动模糊的自然场景图像设计的,对于极低分辨率的模糊文本图像表现糟糕。
2 本文方法
2.1 网络结构
本文提出的模型受到条件对抗网络[20]的启发,如图1 所示,生成器网络由上采样模块和去模糊模块两部分组成。在上采样模块中输入低分辨率模糊文本图像,生成超分辨率图像,然而由于输入图像缺乏良好的细节,加上平均绝对误差(Mean Absolute Error,MAE)损失函数(式(1))的影响,生成的SR 图像通常过于平滑且伴有令人不快的伪影,因此,添加了一个去模糊模块使生成的图像更加清晰,这也提高了鉴别器网络区分真实图像和生成图像的能力。此外,在鉴别器中采用全局平均池化层[21]代替传统的全连接层,降低了网络参数量和过拟合的发生。
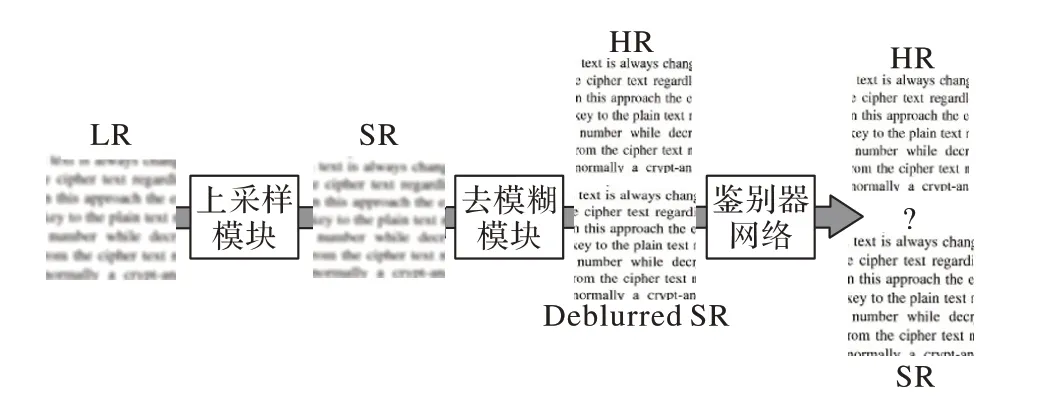
图1 本文提出的联合超分辨率与去模糊的网络结构Fig. 1 Proposed joint super-resolution anddeblurring network structure
2.1.1 生成器网络
如图2和表1所示,生成器网络由上采样模块与去模糊模块组成,网络采用了一种残差学习结构,并如Lim 等[9]所建议,移除残差块(如图3)中的批量归一化层,以保持特征的范围灵活性。但不同于文献[9]的是本文的网络中有两个反卷积层,每层反卷积将低分辨率图像上采样2倍。
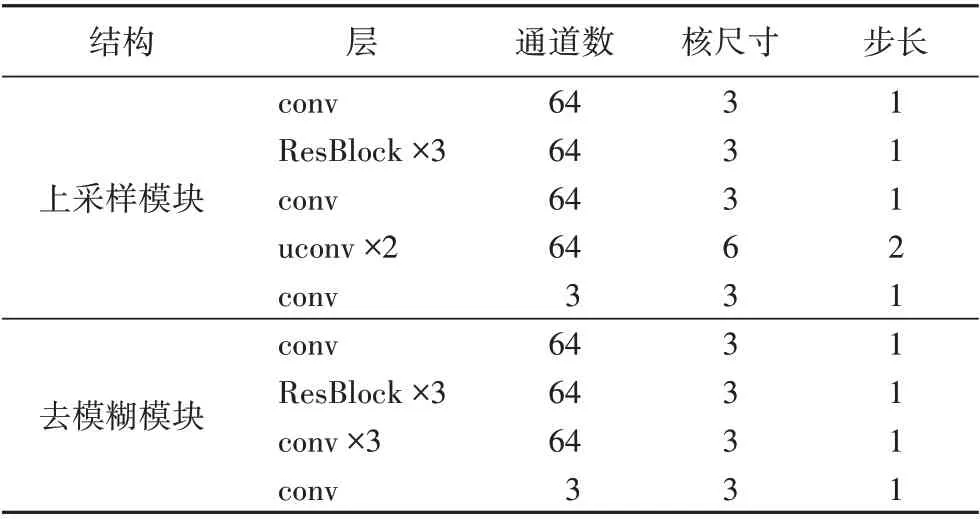
表1 生成器网络参数设置Tab. 1 Generator network parameter settings
注:“×3”表示3个残差块或卷积层,“×2”代表2个反卷积层。

图2 生成器网络结构Fig. 2 Generator network structure

图3 残差块Fig. 3 Residual block
此外,生成器网络还包含一个去模糊模块,其网络结构类似上采样模块,但去模糊模块中没有反卷积层以保持图像的空间分辨率不变。类似于Nah 等[22]的方法,在每一层之后使用整流线性单元(Rectified Linear Unit,ReLU)激活。但每个模块的最后一层除外,其后使用双曲正切函数激活。
2.1.2 鉴别器网络
鉴别器网络如图4 和表2 所示,该网络的输入是图像,输出是输入图像为真实图像的概率。类似于VGG 网络,在使用步长卷积(strided convolution)对图像进行降采样的同时特征数 量 翻 倍。正 如Ledig 等[10]所 为,使 用 斜 率 为0.2 的LeakyReLU 作为激活函数,但最后一层使用sigmoid 函数。此外,一个全局平均池化层被用来代替第一个全连接层。

图4 鉴别器网络结构Fig. 4 Discriminator network structure

表2 鉴别器参数设置Tab. 2 Discriminator parameter settings
2.2 损失函数
2.2.1 集成像素损失
基于学习的图像超分辨率或去模糊方法通常以重建图像与真实图像之间的平均绝对误差(Mean Absolute Error,MAE)损失作为目标函数[7,9]。不同于大部分的方法[3,16]约束生成器网络的最后层输出,本文对上采样模块和去模糊模块分别使用了MAE 损失,这迫使上采样模块输出清晰的SR 图像来帮助去模糊模块更好地重建HR 图像。集成像素损失LX包含超分辨率像素损失和去模糊像素损失,其计算公式如式(1)所示:

2.2.2 特征匹配损失
在深度CNN 模型中,仅使用像素损失可以获得一个特别高的PSNR 值。然而由于缺乏高频内容,生成的图像往往存在令人不满的伪影和过于平滑的纹理。为了获得更逼真的图像,将特征匹配损失引入目标函数中。此损失比较的是生成图像与对应的真实图像的CNN 特征图之间的差异。不同于常 见 的 感 知 损 失[10,23]利 用 在ImageNet 数 据 集 上 预 训 练 的VGG19(Visual Geometry Group 19)网络,本文采用的是在文本图像数据集上训练的CNN15 全卷积网络[24],这有助于学习到特定的文本图像先验。特征匹配损失被定义为式(2):

其中:Φ是在上文描述的CNN15网络中获得的特征图,W和H分别代表特征图的宽度和高度。此外,正如Wang 等[3]所建议,使用激活前的特征,在本文中使用CNN15网络的第7层卷积,这个特征匹配损失迫使真实图像和生成的高分辨率图像具有相似的特征表示。
2.2.3 对抗损失
除了上述损失函数外,还使用了对抗损失,这激励生成器网络生成更清晰的高频细节来欺骗鉴别器网络。其被定义为式(3):

其中:Dθ(Gω())表示生成图像Gω()是高分辨率图像的概率。在实践中,通过最小化-ln(Dθ(Gω(ILR)))而不是ln(1-Dθ(Gω(ILR)))来促进梯度计算。
2.2.4 目标函数
综上所述,本文的目标函数是集成的像素损失、特征匹配损失和对抗损失的组合。其可表示为式(4):

其中:α和λ是两个权重参数,ω1 和ω2 是上采样模块G1与去模糊模块G2的网络参数。在实践中,生成器G 和鉴别器D 通过式(5)、(6)进行优化。
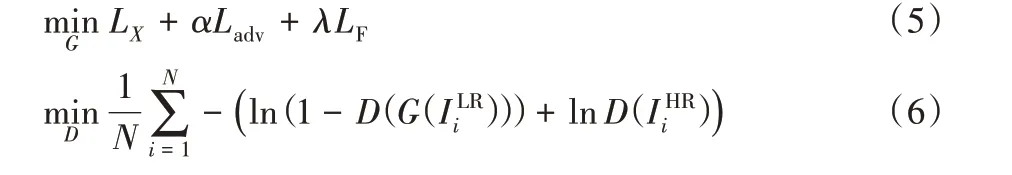
3 实验与结果分析
3.1 数据集
本文采用来自Hradiš 等[24]的文本图像数据集,数据集包含超过6万张模糊的和清晰的HR 图像对,模糊的文本图像具有失焦模糊和运动模糊。为了生成更多的训练数据,将HR图像对随机裁剪成64×64 的子图像以获得模糊的HR 子图像Hblur和清晰的HR 子图像Hsharp,接着对Hblur使用Bicubic 下采样4 倍以获得模糊的LR 子图像Lblur。最终,总共70 万张图像对(Lblur,Hsharp)用作训练集。测试集由100 张失焦模糊和运动模糊的文本图像组成,使用相同的方式下采样测试集。真实场景下的文本图像包含40 张各类场景下的退化图像,利用真实世界中的文本图像以评估本文所提方法的鲁棒性。为了降低光照的影响,对真实世界中的图像使用了对比度变换和伽玛校正来进行预处理。
3.2 训练细节
本文将所有输入和真实图像的范围归一化到[-1,1]来执行预处理。式(5)中的权重参数α和λ根据经验分别被设置为0.001 和0.01。采用ADAM 优化器[25]来训练模型,minibatch 大小设置为128。学习率初始化为2×10-4,并在每1×105个mini-batch 更新时减半,使用He 等方法[26]初始化每层过滤器的权重。训练时交替更新生成器和鉴别器网络,即更新比率设置为1。所有的模型都在NVIDIA 1080Ti GPU上训练。
3.3 与先进算法的比较
本文将提出方法与几种先进的算法进行了比较,包括超分辨率方法[10]、超分辨率[3,10]和去模糊算法[4,13]的组合,以及联合的图像去模糊和超分辨率方法[16,19]。
3.3.1 在合成数据集和真实世界图像上的效果
本文使用上述的文本图像测试集,根据PSNR 和结构相似度(Structural SIMilarity index,SSIM)来评估提出的方法。定量结果如表3 所示,所提方法将PSNR 和SSIM 分别提高了1.52 dB、0.011 5,这表明本文方法能更好地恢复文本图像。
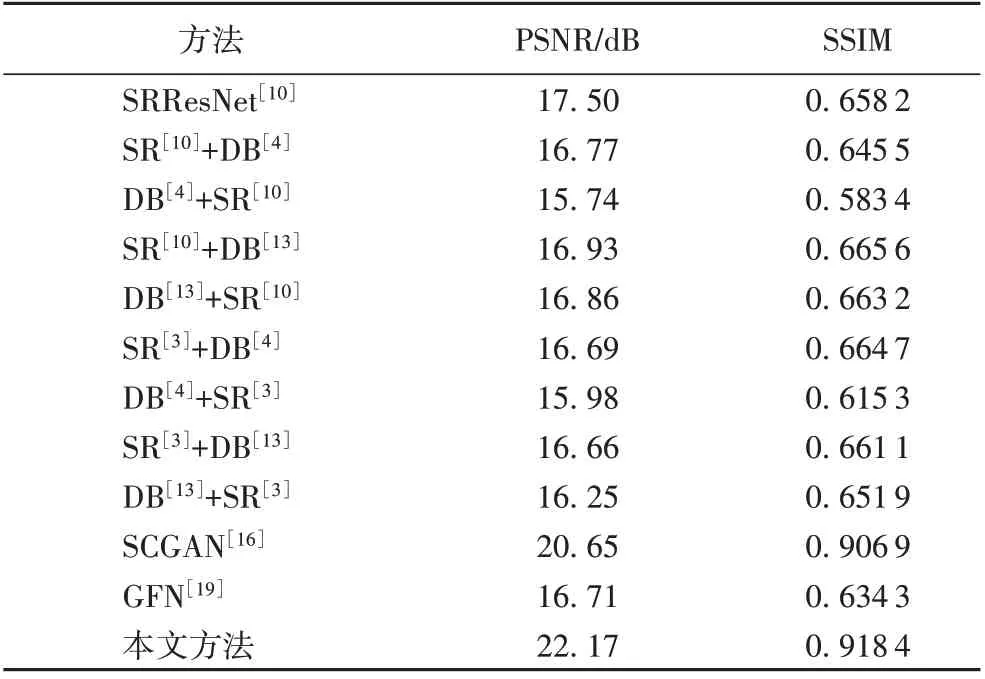
表3 不同算法在测试集上的质量评估结果Tab. 3 Quality evaluation results of different algorithms on test set
定性结果如图5 所示,可观察到顺序组合超分辨率与去模糊方法不能生成清晰的图像,这种组合方法会由于误差累积而加剧伪影。定性结果与定量结果相一致,提出的方法表现优于现存的联合方法。

图5 不同算法在测试集上的重建结果对比Fig. 5 Reconstruction results comparison of different algorithms on test set
此外,如表4所示,在同一GPU 上提出的方法比现有的联合方法需要更少的运行时间。由于图像恢复过程只涉及到生成器网络,与文献[19]相比,提出的模型尺寸要小得多(0.9 MB vs 12 MB)。又不同于文献[16],本文的生成器中不使用批量归一化层,同时也不在模型的初始层就实现上采样操作,这大大减少了计算量。正如图6 所示,提出的方法收敛更快。

表4 OCR精度、模型尺寸和平均运行时间的比较Tab. 4 Comparison of OCR accuracy,model size and average running time

图6 损失函数曲线图Fig. 6 Loss function graph
由于本文的生成器模型是一个全卷积网络,因此提出的方法可以恢复任意大小的文本图像。从图7 可以看出,所提方法生成的文本图像比现有的联合方法在真实世界中的文本图像上获得更好的视觉效果。

图7 真实场景下的不同联合方法的重建图像对比Fig. 7 Comparison of reconstructed images of different joint methods in real scenes
3.3.2 字符识别的效果
提高OCR(Optical Character Recognition)的精度是本文提出方法的主要目的之一。此外,由于PSNR 不能很好地评价基于GAN 方法生成的图像,因此可以利用文本图像的字符识别率来评估重建图像的质量。直接使用ABBYY FineReader 14 基本上无法识别上文描述的测试集中的低分辨率模糊文本图像。但是,如表4 所示,与其他的联合方法相比,所提方法将OCR 精度提高了13.2 个百分点,在测试集上获得了81.6%的字符识别精度。
3.4 分析与讨论
为了验证去模糊模块、对抗训练和集成逐像素损失中的超分辨率损失对本文提出方法的有效性,分别进行了消融实验。从表5 可以看出,移除去模糊模块显著降低了重建图像的质量。一个原因是上采样模块加剧了由输入图像中像素退化引起的伪影。因此,在生成器中添加去模糊模块可以有效地抑制伪影,生成字符更清晰的文本图像。当不使用对抗训练去优化模型时,从表5 中可以看出PSNR 和SSIM 都有一定的提高,这并不令人惊讶。正如在文献[10,27]中所观察到的一样,这是因为模型是专门针对这两个指标优化的。这样重建的图像通常过于平滑并且缺乏足够的图像细节,因此OCR的精度明显降低。正如表5 所示,去除集成逐像素损失中的超分辨率损失(即式(1)的第一部分)后,图像质量有一定程度的下降。此损失迫使上采样模块生成的超分辨率图像接近真实图像,这有助于后续的去模糊模块重建出更清晰的高分辨率图像。

表5 所提方法的不同部分的影响Tab. 5 Effect of different parts of the proposed algorithm
4 结语
本文提出了一个轻量级模型来重建具有复杂模糊的极低分辨率文本图像。此模型基于生成式对抗网络,其中生成器网络包含两个模块,分别进行上采样和去模糊操作。此外,引入了一个由集成像素损失、基于文本图像先验的特征匹配损失以及对抗损失组成的联合训练损失来指导生成器网络恢复良好的图像细节。实验结果表明,所提方法是高效的且能更好地重建真实世界中的退化图像,在视觉质量和PSNR、OCR精度等客观指标方面均明显优于现有的算法。
尽管所提方法可以重建清晰的高分辨率图像,但在重建的文本图像中有个别字符不同于真实图像。这可能是因为本文的方法更多聚焦像素级的文本图像恢复,而没有充分考虑文本图像的上下文依赖性。在未来的工作中,将尝试引入递归神经网络来进一步提高文本图像的重建效果。
猜你喜欢
今日农业(2022年15期)2022-09-20
小哥白尼(军事科学)(2022年2期)2022-05-25
家庭影院技术(2020年2期)2020-03-25
小天使·二年级语数英综合(2019年10期)2019-11-08
红领巾·萌芽(2019年8期)2019-08-27
CHIP新电脑(2016年3期)2016-03-10
CHIP新电脑(2016年3期)2016-03-10
读者·校园版(2015年19期)2015-05-14
海外英语(2013年8期)2013-11-22
微型计算机(2009年4期)2009-12-23
