
基于软件定义网络的对等网传输调度优化
2020-06-06 02:07向雄,田检
计算机应用 2020年3期
向 雄,田 检
(1. 广州大学华软软件学院网络技术系,广州510990; 2. 广州大学华软软件学院基础部,广州510990)
(*通信作者电子邮箱tj@sise.com.cn)
0 引言
“互联网+”的兴起,有力地推动了云计算、物联网、电子商务、互联网金融的蓬勃发展,各行各业开始与信息技术紧密结合,这样导致了以网络为基础的应用异常丰富。这种现象具有两个明显的特点:一是上层应用正在反推底层网络架构作出改变,软件定义网络(Software Defined Network,SDN)[1]就是其中一个主要变化方向;二是来自于各领域的应用比如区块链、视频点播、视频直播等,大多数都采用或以可选方式采用对等网(Peer-to-Peer,P2P)机制对信息、文件、带宽、存储及处理器周期等各种资源进行管理[2]。这样就使得基于SDN 的P2P传输研究成为了一个很紧迫的问题。
SDN 是一种最具吸引力的未来网络体系结构,它具有三个主要特点:集中控制、动态可编程、转发逻辑和控制逻辑相互分离,能够很好地满足高带宽、高数据量和拓扑动态可变的网络需求。 SDN 的组成部件分为SDN 控制器(SDN Controller,SDN-C)和SDN 转发元件(SDN Forward Element,SDN-FE)两部分,SDN-C 和SDN-FE 之间通过可靠安全的带外信道连接。SDN-C 是一个集中式的全局控制器,可部署在高性能的服务器(或集群)上来监控和管理整个网络。SDN-FE是一个不具有控制功能的纯转发设备,它依据流表规则执行转发。流表规则由SDN-C 通过带外信道使用OpenFlow 协议安装在SDN-FE上。
P2P 网络是一个建立在TCP 或HTTP 协议之上的虚拟覆盖网,每个节点在这个虚拟空间中被赋予一个用作通信地址的唯一ID,有的结构化P2P 网如内容寻址网络(Content Addressable Network,CAN)、Pastray 等使用ID 号来定位资源。P2P 系统都包含了一套机制将ID 号映射到IP 地址以进行实际的数据传输。P2P 系统会采用一些网络测量技术来使虚拟空间中的距离关系尽量与底层物理网络相一致,比如:文献[3]提出了一个能感知节点位置的改进型GnuTella 非结构化P2P 系统,它使用一个爬虫(crawler)来携带和修改网络拓扑图并获取节点的地理位置;文献[4]则利用Gossip协议让节点相互交换信息来获取动态实时的网络状况。
从网络的角度来看,P2P 传输优化问题重点就是流调度问题。ECMP(Equal Cost MultiPath Routing)这类传统的流调度策略无差别对待所有流,看起来很公平,却无法根据网络状态进行优化。Al-Fares 等[5]利用模拟退火算法或首次匹配法根据预估带宽进行流调度,成功解决了Clos(发明者为Charles Clos)网络中的大象流冲突问题,取得了远高于ECMP的带宽利用率。类似地,如何根据P2P 数据传送特点进行传输调度优化呢?这就是本文要解决的问题。
P2P 网络中的数据传输方式有两种:1)点对点方式比如BitTorrent,这种方式的流调度问题可参照传统方式解决。2)组播方式,这种方式在P2P 系统中特别是P2P 流媒体应用中非常普遍。组播树最合适的结构就是树结构,但树结构有一个致命的缺点就是节点的离开会导致其子树上的节点在组播树重构完成之前无法接收数据,所以通常都是网状结构,最 典 型 的 就 是ESM(End System Multicast)[6]和ALMI(Application Level Multicast Infrastructure)[7]。学术界对于选择应用层组播(Application Layer Multicast,ALM)还是IP 组播是有争议的[8],ALM 把应用与网络相分离,体现了分层的原则,但会产生应用层与底层不一致的问题,无法充分利用网络。SDN 可以弥补这一不足,通过在SDN-C 中嵌入相应的服务,就可以使P2P 系统中实施ALM 时能够根据网络状态进行实时动态的流调度以满足体验质量(Quality of Experience,QoE)等传输需求[9]。
本文设计了一个基于SDN的P2P传输调度优化架构。其核心过程是从SDN-C 那里获取流量矩阵,转化成带权重的网络拓扑图,在此基础上生成组播树,并利用神经网络智能化地确定更新周期,能够实现网络性能的提升。
1 系统模型
本方案假定每个P2P 系统都使用一个UUID(Universally Unique IDentifier)作为唯一标识,任何需要加入的节点首先得获取此标识,生成和分发此标识的过程不在本系统范围之内。整个系统参考架构如图1所示。
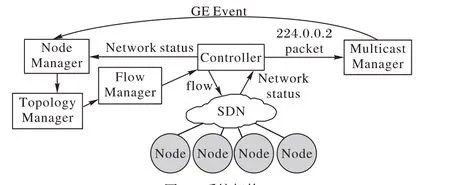
图1 系统架构Fig. 1 System framework
SDN 实施组播并不需要通过IGMP(Internet Group Management Protocol)v1/2/3 协议来实现[10],故组播路由器地址如224.0.0.2等没有实际意义,本文使用它来产生PacketIn事件。当一个节点加入或退出P2P 系统时,它会发送一个包含了事先协商好的UUID 的数据包给224.0.0.2。控制器事先在交换机上安装流表项让目的地为224.0.0.2 的数据包PacketIn 到控制器;组管理器(Multicast Manager,MM)侦听控制器的PacketIn 事件,发现目的地为D 类IP 多播地址的话就产生组播事件(Group Event,GE),对组播感兴趣的其他模块都可以侦听,比如IGMP 或其他组播实现方式,这样就做到了与现有系统兼容。节点管理器(Node Manager,NM)是GE 事件的侦听者,它收到GE事件后分析其中内容是否符合自己的应用规范,不符合则丢弃;否则转交给拓扑管理器(Topology Manager,TM)。
TM 负责从GE 事件中取出P2P 系统标识UUID,然后根据此标识将此节点加入到对应的P2P 拓扑中。TM 周期性地从控制器那里获取网络流量矩阵并转化成权重网络图,使用终端优先组播树生成算法(见3.2 节)生成组播树并交给流管理(Flow Manager,FM)模块。
FM 根据组播树生成相应的流表规则交给控制器下发到交换机上。在传统非SDN 网络中,IP 层是无法感知上层应用的,不同的IP 组播组是以组播地址来区分的,无法按应用分类。在SDN 中,根据OpenFlow 协议,只需在流表项中设置匹配域:dl_type=0x0800,nw_proto=6,nw_src=源IP,tp_src=应用程序所使用的端口,然后actions 中设置多个output,转发到多个目标IP,即可实现将特定应用程序的数据包进行多播了。FM 根据OpenFlow 协议生成SDN 组播规则。下面对本系统中的关键过程进行说明。
2 流量矩阵测量
一个包含N个节点的系统的流量矩阵如矩阵M所示,其中包含了任意一对节点在t1到tp时间点的流量值,共有N2对,它是网络设计、运维、计帐及安全的关键依据,也是本文中TM模块进行拓扑优化的依据。

传统的网络测量框架都存在非确定性线性逆问题。这是因为直接测量法成本太高,大多数方法都是分析SNMP(Simple Network Management Protocol)、NetFlow 或sFlow 采集到的抽样数据,然后使用最大似然法、贝叶斯方法、PCA(Principal Component Analysis)等算法进行估计,都存在一定的误差,有时还会比较大。
SDN 与传统网络相比在网络测量时更为方便。OpenFlow 协议1.3 中共定义了40 个计数器,其中有9 个是必需的,特别地有3 个基于端口必需计数器Received Packets、Transmitted Packets 和Duration 可以用来精确地获取SDN-FE中每个链路上的流量。在SDN 中进行网络测量就是通过查询和分析上述计数器产生的统计数据来生成基于OD 对(Original-Destination Pair)流 量 矩 阵,OpenTM(OpenFlow Traffic Matrix)[11]、DCM(Distributed and Collaborative traffic Monitoring)[12]等工作很好地解决了此问题。
SDN 演变至今,目前很多SDN-C 倾向于将OpenFlow 网络和传统网络混合起来统一处理,比如OpenDaylight 和ONOS(Open Network Operating System),这样就使得上述基于OpenFlow 端口统计的流量测量工作难以应用到当前的实际网络中,iSTAMP[13]等方法不得不扩展上述基于流的流量矩阵测量方法来增强其实用性。iSTAMP 的理论依据是压缩感知(Compressed Sensing,CS)技术,它认为一个高波动性的稀疏矩阵中的全部数据可以通过一个精心定义的压缩过的线性测量值估计出来。具体过程是首先精心挑选一部分流进行聚合以获取压缩流,然后通过MAB(Multi-Armed Bandit)算法从TCAM(Ternary Content Addressable Memory)流表中选取部分对ALM 系统影响最大的流,分别对这两类流采样就可以推断出整个流量矩阵。
3 拓扑管理
拓扑管理模块TM 根据网络状态修改ALM 树,这需要解决两个关键问题:应用层组播与底层的不一致问题和可扩展性Steiner 树问题。下面首先阐述这两个问题,然后给出解决方式。
3.1 应用层组播与底层的不一致问题
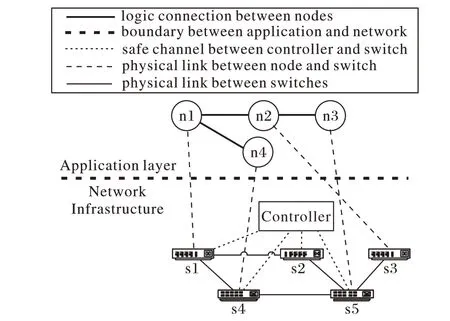
图2 ALM树与基础网络Fig. 2 ALM tree and basic network
假设n1是组播源,则其ALM树为(n1(n2(n3),n4)),由于传统网络中应用层的组播在底层仍然是单播,其实际IP 层的传播树可能是(n1(s1(s2(s5(s3(n2(s5(n3)))))))),数据包从n1 到n2 时要经过链路s5-s3,从n2 到n3 时也要经过链路s3-s5,这是一种无意义的重复流量。
在SDN 中,TM 模块会从SDN-C 那里获取交换机连接方式,然后将上述ALM树的IP层传输路径修改为:(n1(s1(s2(s5(s3(n2),n2))))),从而解决应用层组播与底层的不一致问题。
3.2 可扩展性Steiner树
在SDN 中实施多播既可以用一个流表项对应多个output动作来实现,也可以使用组表中的action bucket 来实现,但这二者都面临着一种可扩展性问题。因为在SDN-FE 中,流表是一种受限资源,硬流表如TCAM 价格昂贵,软流表如OVSDB(Open Virtual Switch Data-Base)则速度堪忧,都不能有效地应对指数级的组播树数目[14]。为了解决此问题,本文提出了一种终端优先组播树(Terminal First Steiner Tree,TFST)。
TM 周期性地与SDN-C 通信获取网络的流量矩阵M并其中的数据量化到[1,10]区间,就可以得到如图3(a)所示的带权重的网络。TFST 将实施多播的流表条目只存储在分支节点(至少包含三条边的节点,用空心圆表示)上,中间节点(黑色实心圆)以单播隧道方式进行数据包的转发,无需安装组播流表项,这样就减少了流表的数量,从而可解决多播树的可扩展性问题。

图2 显示了由n1~n4 四个节点组成的位于应用层的ALM树,节点之间进行通信的基础网络由s1~s5 五个OpenFlow 交换机组成。
TFST算法中的起点可以选择任意一个终端节点。算法分为树的生成和优化两个阶段。第2)步是生成阶段,它在经典Dijkstra算法基础上进行了两点改进:1)若被展开的节点是终端节点,则将其距离值设置为0。因为所有终端节点都是组播树的必经之地,所以每到达一个最近的终端节点就可以把它当作新的起点。2)若遍历到的邻居已经被访问过了,说明它已经在组播树上但与被展开节点不在树的同一分支上,于是将此边加入树中并寻找所形成一个环路,随后去掉这个环路中的最大边。这样就既降低了树的总代价又保持了连通性,从而得到一棵近似Steiner树。优化阶段分3)4)5)步进行,主要过程是第5)步以降低公式c(T)+α*b(T)的值为目标将所有分支节点按度从小到大的顺序进行重连。由于c(T)是组播树中所有边的权重和,代表流量代价。b(T)是组播树中分支节点数量,分支数量越多,意味着要消耗的流表资源越多,组播实施代价越高。通过调整参数α,就可以在流量代价和实施代价之间进行权衡调节。
TFST 算法的时间复杂度主要取决于树生成阶段。若节点数、终端节点数分别用N、M表示,其时间复杂度上界为O(N2M),与其他经典的Steiner树生成算法一致。

图3 TFST的构建Fig. 3 Construction of TFST
4 更新周期管理
组播树的不断调整会导致SDN-C 对SDN-FE 中的分支节点进行大量的流表更新,这样一方面会导致数据包的丢失,另一方面还可能引起网络的不一致性,导致一些安全、认证等策略失效。数据包的丢失可以通过应用层重传来解决,网络不一致性也可以通过一些日志重放方法来恢复,但频繁更新显然会导致网络性能下降。本文设计了一个精巧的基于神经网络的模型来让其自动选择更新间隔。
网络性能的主要指标有时延(Delay)、带宽、丢包率(Loss)。SDN 环境下有很多可用的网络测量方法及工具[15-16]来测量这三个指标。带宽通常比较稳定,那么衡量网络性能变化的主要指标就是拥塞指标P=Delay+Loss了。用L表示由流量矩阵M′所反映的网络负载,那么P既与L相关,又与更新间隔T有关,所以P是L和T的函数,记作P=f(L,T),P和L都是可测量的,确定T值的问题就是一个根据样本值P,L对参数T进行估计的问题,显然f形式未知且非线性,无法采用传统的参数估计和线性回归等工具来计算T值。为此,本文设计了一个如图4 所示的带反馈环的逆系统来根据P自动调整T,其中的下标i表示第i次迭代。
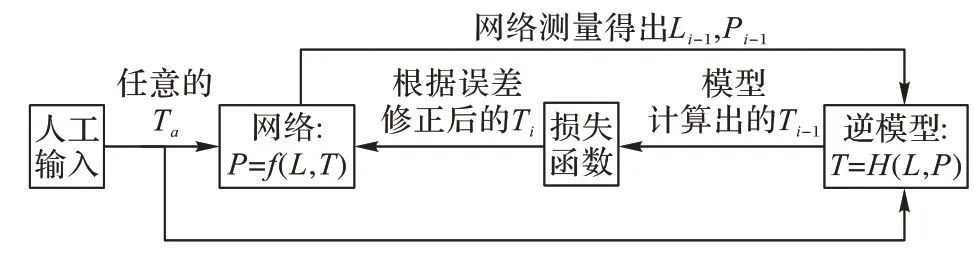
图4 带反馈环的逆系统Fig. 4 Inverse system with feedback loop
Hornik已经证明,只需一个包含足够多神经元的隐层,多层前馈网络就能以任意精度逼近任意复杂度的连续函数[17]。函数逼近问题的本质是一种有监督的学习。为了实现上述逆系统,本文设计了一个如图5 所示的递归神经网络模型来逼近f函数,输入层中的x1、x2、x3、x4 分别表示流量矩阵M中的流量均值、众数、方差、链路流量平均变化率,刻画了网络负载的四个特征;x5 和x6 分别表示丢包率和平均延迟,反映了网络性能特征。x7 是模型的输出结果T的反馈输入。偏置值x0=1(图并未画出),隐藏层采用6个神经元,激活函数采用ReLU(Rectified Liner Uints)。损失函数定义为当前网络拥塞指标与理想拥塞指标之差:|P-Popt|,优化器采用随机梯度下降(Stochastic Gradient Descent,SGD)算法。为避免数据规模对结果的影响,P和T等所有数据都用双正切函数映射到(0,1)区间。
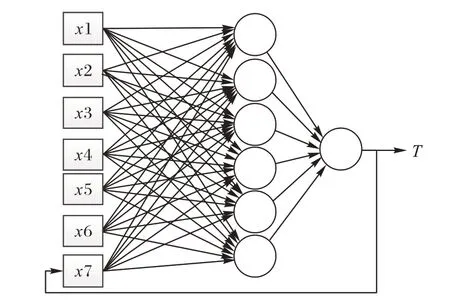
图5 递归神经网络模型Fig. 5 Recursive neural network model
5 实验与仿真
本文仿真网络采用Mininet,控制器采用ryu,python 版本为3.6,机器学习模块采用谷歌的TensorFlow。仿真时使用的网络拓扑由networkx 库中的函数random_kernel_graph 随机生成,随机选择一定数量的节点作为终端节点,终端节点占全部节点的比例r是一个可调整的参数,链路上的带宽在30 MB/s、40 MB/s、50 MB/s 中随机选择,每个终端节点连接一台主机,主机上运行iperf,每隔1 s向网络发送随机10~20 MB/s的随机流量。
5.1 有效性
图6是有效性仿真结果,横轴是以秒为单位的运行时间,纵轴是每隔5 s 计算所得的P值,也就是归一化后的Delay+Loss值,Loss通过ryu 控制器的Web 管理界面统计得出,Delay为所有终端节点的平均接收延迟。由于注入网络的流量总体上小于链路的带宽,整体上网络性能都比较好。刚开始时优化网络的拥塞指标高于原始网络,这是由于更新周期较小,控制器频繁地更新流表导致了网络性能下降;大约10 s以后,优化模块的效果开始显现,P值一直平稳地低于未经优化的原始网络。从总体上看,原始网络P均值为0.15,优化后为0.08,网络拥塞指标在原来的基础上降低了47%。
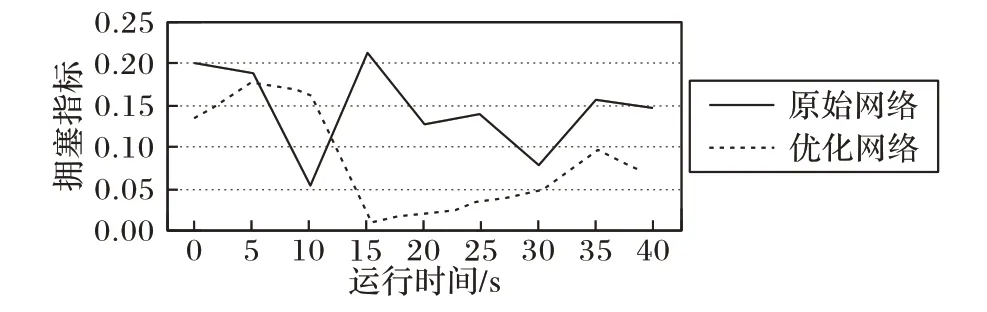
图6 优化效果Fig. 6 Result of optimization
5.2 参数组合
从表1 所列出的部分结果可以看出:1)不同的网络测量方法istamp(用i表示)和opentm(用o表示)所测得的流量矩阵对优化结果影响不大。2)α值对系统有较大影响,主要原因是α值增加时,TFST 算法主要侧重于组播树的可扩展性,减少了分支节点数量,从而加大了组播的流量代价,导致P值增加。3)增加节点的度可以显著提升网络性能。这是因为可选路径大量增加后,流量可以灵活地被实时调度到空闲的链路上。
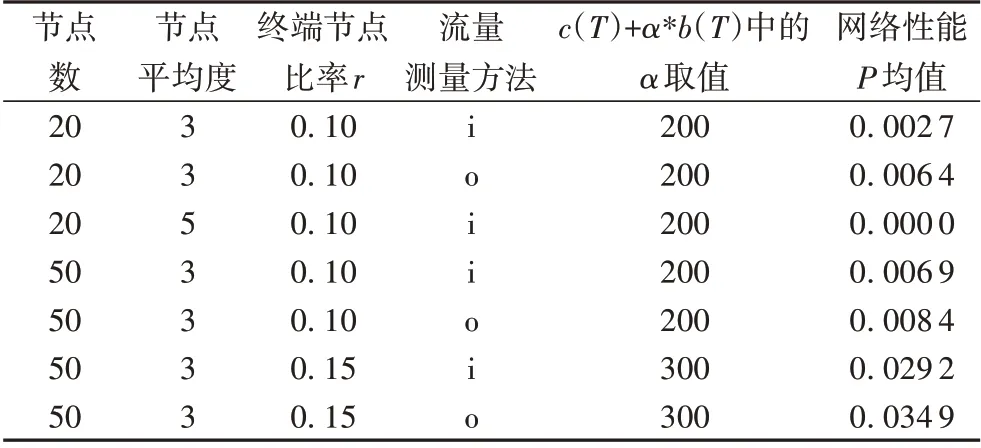
表1 不同参数组合运行结果比较Tab. 1 Running results comparison in different parameter combinations
5.3 更新周期的变化规律
在mininet 中生成仿真网络后立即进行网络性能测量的结果作为网络的最优性能Popt。图7 显示了运行过程中更新周期T随着性能P的变化情况,从图中可以看出,当性能稳定下来之后,更新周期会逐渐变长,最后逐渐收敛于1,这意味着网络性能已经趋于稳定,优化过程对网络性能的提升作用已经很小了,调整模块无需频繁介入。当网络性能发生较大变化时,特别是当P增加时,此时意味着性能下降,调整模块会不断尝试最优路径,最终达到提升网络性能的目的。
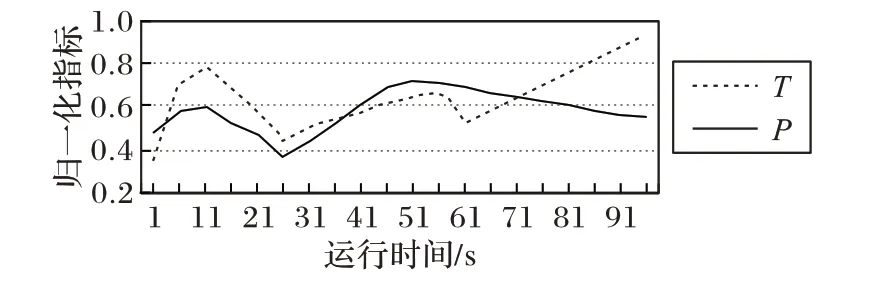
图7 T随P变化的趋势Fig. 7 Trend of T varying with P
5.4 不同更新方式对比
图8 显示了当组播树发生变化时,不同的更新周期管理方式所得到的网络性能的对比结果。PN 是采用神经网络模块确定新流表的部署时机,P0 表示立即部署,P5 表示固定间隔5 s 部署一次。从图中可以看出P0 方式虽然有时能取得较好的性能,P 值大幅下降,但总体水平还是略高于神经网络方式。经计算,PN、P0、P5三种方式得到的网络拥塞指标均值分别为0.42、0.51 和0.56,前者与后二者相比,分别降低了17.6%和25%;标准差分别为0.06、0.12 和0.13,这说明神经网络模块在网络中等负载的情况下既能抑制网络性能下降果,又能将网络性能稳定在一个相对较为理想的水平。
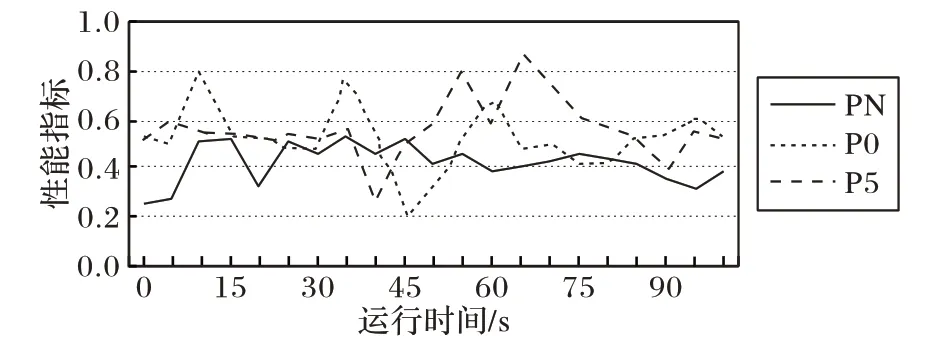
图8 不同更新方式的效果对比Fig. 8 Effect comparison between different update methods
6 结语
SDN 与传统网络相比更能贴近应用的需求,能充分利用人工智能和大数据技术向网络注入智能。本文提出的方案一方面能够使SDN 中应用层组播像IP 组播一样节省流量,无需像IP 组播一样运行繁琐的组播协议,另一方面在网络智能化方面进行了有效的探索。本文虽只是针对P2P应用中的ALM特点对网络性能优化,但这样的研究对如何针对网络中多种多样流量特点进行优化调整[18],促使SDN 在安全模型、运行机制[19]等方面全方位智能化有很大的启发作用,这将是我们下一步研究目标。
猜你喜欢
今日农业(2022年16期)2022-11-09
房地产导刊(2021年8期)2021-10-13
出版人(2020年4期)2020-11-14
汉语世界(The World of Chinese)(2019年1期)2019-03-18
读与写·教育教学版(2017年10期)2017-11-10
电子技术与软件工程(2017年3期)2017-03-22
教育教学论坛(2016年49期)2017-02-27
物联网技术(2015年8期)2015-09-14
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
