
基于深度学习的采动地裂缝成因分析和预测
2020-06-03 01:31吕义清
太原理工大学学报 2020年3期
贾 杨,吕义清
(太原理工大学 矿业工程学院,太原 030024)
地裂缝是地下开采引起的主要地质灾害之一,对地面建筑物、道路、植被以及耕地会产生严重破坏。在地表坡度较大、地面岩层稳定性差、松散堆积物较多的地区,地裂缝会加剧降雨及风蚀作用的影响,使地表产生更加严重的地质灾害,如滑坡、泥石流等。此外,如果地裂缝与地下采空区相通,会对矿井通风产生影响,甚至带来矿井水害威胁。因此,准确解释采动地裂缝的成因并预测其发育程度,具有很强的实用价值。
研究人员通常通过模拟实验与实际调查相结合的方法对地裂缝进行研究。吴侃等根据概率积分法和莫尔-库伦破坏准则提出了地裂缝的分布模型,并通过实例验证了模型的准确性[1];LIU et al[2]利用土质坡体圆弧形条分法原理,建立了描述黄土沟壑区滑动型采动地裂缝形成条件的力学模型;胡青峰等[3]通过在采空区地表布置观测线,结合开采过程和地质条件对地裂缝发育特征进行了分析;GUO et al[4]开发了一种新型地裂缝监测设备,可对地裂缝发育过程进行三维变形监测。近年来,许多学者使用UDEC和Flac3D等软件对采动地裂缝的形成过程进行了数值模拟[5-6]。
上述研究存在的问题是:研究的影响因素有限,适用范围较窄,缺乏对比性和综合性,并且分析过程较为复杂。为实现对采动地裂缝成因的多因素耦合分析,本文采用深度学习的方法,以实测数据为基础对各影响因素进行了量化处理,对地裂缝发育程度不同的区域进行了划分,以预测准确率为指标分析了各因素的影响程度,以便使结果更加符合实际。该方法能够实现对采动地裂缝整体规模上的预测而不仅仅预测地裂缝发育的最大宽度和深度,因而具有更好的实用价值。
1 研究区概况
官地井田位于太原市西南17.5 km处的郊区,地处山西高原吕梁山脉中段,属中山区。井田内地势西南高东北低,山高坡陡,切割剧烈。黄土主要分布于山顶及缓坡地带,山脊及陡坡处岩石裸露,风化剥蚀作用强烈。该井田属于石炭、二叠系含煤盆地,主要含煤地层为太原组和山西组,开采煤层为2号、3号、6号、8号、9号煤层。
受区域构造的控制,井田内地层走向NW—SE、倾向SW,总体上呈单斜构造。地层倾角4°~10°,为缓倾斜地层。除边界断层外,井田内大中型断层较少,但小型断层较为发育,煤田内陷落柱较发育。
官地矿井田面积大、开采历史长,采用一次采全高自动垮落法采煤工艺,顶板破坏大。由于官地矿可采煤层数多、煤层较厚、采空区较多且属分层开采,故该井田为研究地裂缝的成因和预测提供了较有利的条件。
1.1 官地矿地裂缝形态特征
受到煤层上覆岩体特征、地表出露岩土特征、采煤工艺和工作面布置的影响,官地井田地裂缝的力学特征主要为张性地裂缝,扭性地裂缝主要分布在采空区边界区域,挤压型裂缝不常见。平面分布上,地裂缝延伸近乎于直线形态,呈现中间区域宽度较大、向两边逐渐减小直至尖灭。通过实测研究区内地裂缝的长度和最大宽度,结合过去10 a官地井田地裂缝统计资料发现,地裂缝最大延伸长度为163.0 m,最大宽度为1.8 m,裂缝长宽比一般在10∶1以上。地裂缝典型形态如图1所示。

图1 官地煤矿典型地裂缝Fig.1 Typical ground fissure of Guandi mine
1.2 官地矿地裂缝分布特征
官地矿开采煤层分布范围广,可采煤层较多,采空区分布情况复杂,不同采空区上部地裂缝发育规模差异较大。通过对各工作面采空区上部地裂缝的大数据量采集,而不是对个别地裂缝的单独描述,可以更加准确全面地进行地裂缝成因分析和预测。图2为官地矿典型地裂缝分布图。

图2 官地煤矿典型地裂缝分布图(红色线条表示地裂缝)Fig.2 Typical ground fissure distribution map of Guandi mine
图2(a)-(d)分别代表地裂缝发育程度从低到高的不同工作面区域。可以看出,地裂缝发育规模受到开采煤层数、地形条件、上覆岩层厚度、工作面开采范围、地表出露岩层性质等多方面因素的影响。本文收集了官地矿近10 a采动引起的地裂缝长宽数据,以开采工作面为基本单元,从整体上分析影响地裂缝发育规模的因素及各因素对地裂缝发育的影响程度,在此基础上对不同工作面采动地裂缝发育程度进行分类预测。
2 采动地裂缝的影响因素分析
地裂缝的形成会受到多种因素的耦合影响,如:地表出露岩层物理力学性质,采空区上覆岩层岩性、厚度,开采煤层厚度、范围,地质构造,煤层赋存条件以及地形地貌等[7]。研究显示,开采深度与开采厚度的比值小于30时,地表会出现较多的裂缝[8]。煤层倾角很大时,地表先于采空区出现裂缝;煤层倾角基本水平或倾角很小时,采空区先于地表出现破裂[9]。同一采空区范围内多次高强度的重复开采会使上覆岩层移动变形破坏加剧,增加了采空区地表下沉幅度[10]。
当受到地下采动破坏时,上覆岩层原始应力平衡状态被打破。当采动引起的应力集中超过临界值时,岩层先是发生弯曲变形,然后逐渐产生裂隙、发生断裂;当破坏程度不断扩大传递至地表并超过地表岩土体的抗拉抗剪强度时,岩土体沿着原有裂隙发生非连续变形,形成地裂缝[11]。
本文收集了研究区内的采掘工程平面图、井上下对照图、地形地质图、钻孔柱状图、地裂缝调查报告等地测资料,结合实地调查,将影响因素分成5项一级指标和11项二级指标,如表1所示。

表1 采动地裂缝的影响因素指标划分Table 1 Factors affecting ground fissure caused by mining
3 地裂缝发育程度评价
在采动地裂缝的定量分析中,有些研究通过构建采空区上部岩体力学模型和实测地表土体力学数值,利用数学几何方法和应力分析方法对地表土体水平和垂直方向进行受力分析,提出了计算地裂缝发育宽度和深度的公式[12-13]。
这些研究使用的采动模型比较简单,且其研究对象是地表土体,对于分层开采及基岩覆盖地表产生的地裂缝没有说明。随着开采的推进,地裂缝会发生“开裂—闭合”的动态过程。对于大型工作面来说,仅对个别裂缝进行宽深计算难以反映采动地裂缝的整体规模。
本文通过实测研究区内地裂缝的长度和最大宽度发现,裂缝的长宽比一般在10∶1以上,在平面形态上呈现中间宽、向两边急剧尖灭的特点,因此可将裂缝看作长轴远大于短轴的扁椭圆来估算裂缝面积。通过计算采空区地表所有裂缝的面积与采空区面积的比值ω,对地裂缝发育程度进行分类评价。估算公式为:
(1)
式中:ω为本文采用的地裂缝评价指标;at为采空区地表第t条地裂缝长度;bt为第t条地裂缝最大宽度;S为采空区面积。
本次共调查了研究区中119个地裂缝发育程度不同的区域。按照每个区域计算得到的ω,将这些区域划分为4个裂缝发育级别,如表2所示。
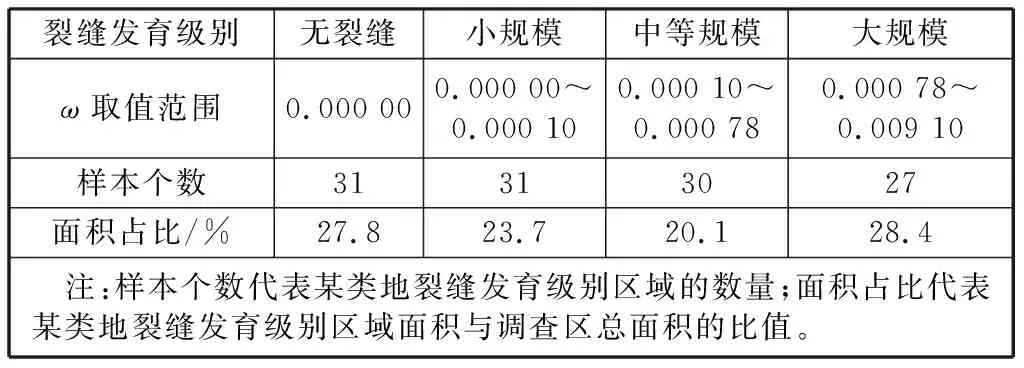
表2 地裂缝评价指标Table 2 Ground crack evaluation index
4 地裂缝发育程度神经网络模型设计与数据处理
4.1 神经网络模型设计
机器学习本质上是解决两大类问题,即回归和分类,通过在函数集合中寻找最佳的方程实现这些目标,见图3.

图3 机器学习过程Fig.3 Machine learning process
深度学习就是将函数集合定义为一个神经网络,这样可以避免大量的人为构建工作,并且具有更大的函数集合空间,容易找到最好的函数模型。
设计中发现,当选择最简单的网络结构,即输入层-一个隐藏层-输出层时,通过调节隐藏层神经元的个数难以使网络的输出在训练集合和测试集合上均有较高的准确率,并且收敛的结果存在不稳定性。所以本文采用两个隐藏层结构的深度神经网络,以减少单层神经元个数的方法提高准确率,其实质是:利用了模块化的思想,将复杂的原始数据输入到第一层神经元中进行初步处理;再将第一层的输出数据输入到第二层神经元中进行进一步分类。这对于处理数据量不足的问题具有较好的效果。整体模型框架如图4所示。
4.2 数据处理
对调查区实测数据和矿井地质测量资料进行整理,共得到119组区域数据。将119组数据中的83组作为训练样本,36组作为测试样本。部分样本数据如表3所示。
将表3中的11维特征依次编号为1,2,3,…,11.对这些不同量纲和数量级的数据进行标准化处理,可以加快梯度下降的收敛速度,有效提高输出的准确率。本文使用Z-score标准化方法,即将输入层各维数据的均值变为0,标准差变为1,使之符合标准正态分布,转化公式为:
(2)
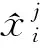
使用One Hot编码,将地裂缝发育程度的四个类别用二进制向量表示为(1,0,0,0),(0,1,0,0),(0,0,1,0),(0,0,0,1).
4.3 神经网络模型参数设计
本文使用Tensorflow构建地裂缝发育程度神经网络分类模型。
模型中输入层维度为11;采用两个隐藏层结构,第一个隐藏层神经元数为20,第二个隐藏层神经元个数为10;输出层维度为4.
网络层数较多时容易导致梯度消失,所以两个隐藏层的激活函数选用Relu.Relu不仅可以有效缓解梯度消失的问题,而且会加快收敛速度。
本文旨在解决四元分类问题,因此采用Softmax将输出层数值映射为(0,1)区间内的四维累和为1的概率值,最后选择概率最大的输出节点即可完成预测分类。
交叉熵损失函数可以计算神经网络的输出(预测样本概率q(x))和真实样本标签(真实样本概率p(x))之间的距离,利用梯度下降不断减小该函数值,以便选择最佳的神经元连接权重和偏置。交叉熵损失函数的表达式为:
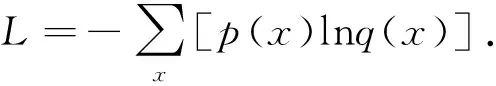
(3)
设初始学习率为0.000 1.使用Adam优化算法对每次梯度下降时的学习率进行自适应调整,以加快收敛的速度和稳定性,并且对参数进行L2正则化处理,惩罚项系数为0.01.迭代次数选择10 000次。
5 特征选择和结果分析
对地裂缝形成的影响因素进行特征选择可以选出主控因素,剔除不相关或冗余特征,有利于优化学习网络结构,降低网络维度,提高训练效率。
本文直接使用分类子集在测试数据上的正确率作为特征重要性程度的评价标准。具体方法、步骤和结果如下。
1) 第1次特征选择时使用单维数据样本。将第i维数据(i=1,2,…,11)单独输入神经网络中进行学习,得到表4所示结果。

表4 第1次特征选择准确率Table 4 The first feature selection accuracy
由表4可见:开采层数、开采总厚、开采宽度、开采深度、砂泥岩比、开采长度这6个特征在单独训练时,在测试集和训练集上准确率明显高于其他特征,并且测试准确率均高于50%,因此可视为研究区内影响地裂缝发育程度的主要因素;地质构造和地表出露两项的训练准确率和测试准确率均不高,但是两者差距不大,介于30.6%~33.7%范围内,这说明这两项特征对于地裂缝的发育有一定影响,但影响程度有限;煤层倾角、地形坡度、相对位置这3个特征的训练准确率和测试准确率都较低,并且训练准确率明显高于测试准确率(差值大于15%),出现了一定的过拟合现象,说明神经网络中从训练集合学习到的参数并不适用于测试集合。
利用6维主要特征的数据对模型进行重新训练,得到的训练准确率为81.9%,测试准确率为75.0%;相较于单维数据,6维的准确率有了较为显著的提升。训练过程中准确率和损失函数的变化曲线见图5.

图5 主要特征的神经网络损失与准确率Fig.5 Neural network loss and accuracy of the main characteristics
2) 以上述6维主要特征为基础,依次增加其他5维数据,将输入维度增加至7维,进行第2次特征选取。结果见表5.

表5 第2次特征选择准确率Table 5 The second feature selection accuracy
由表5可看出,加上地质构造这一特征后,训练准确率从81.9%提高至92.8%,测试准确率从75.0%提高至83.3%;增加地表出露后,训练准确率提高至91.6%,测试准确率提高至80.6%.因此,这两个特征与输出类型相关性较好。
在分别增加煤层倾角、地形坡度、相对位置这3个特征后,训练准确率均超过90%,但增加煤层倾角、地形坡度后的测试准确率分别降至69.4%和72.2%,而增加相对位置后测试准确率没有发生变化。其原因是在这3个维度上,数据与所属类别的关联性较低,训练数据与测试数据的分布相差较大,这些特征对预测结果有所干扰,增加了结果的不稳定性。
3) 将上一次特征选择时相关性较好的地质构造和地表出露这两个特征加入神经网络,输入维度增至8维,进行第3次特征选择。准确率和损失函数变化如图6所示。
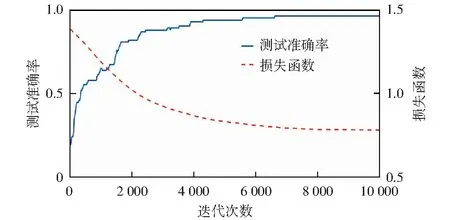
图6 优化神经网络的损失函数与准确率Fig.6 Optimized neural network loss and accuracy
将这8维数据输入神经网络,在训练和测试上分别得到96.4%和89.1%的准确率。结合前两次的特征选择,可以认为地质构造发育程度和地表是否有松散层是该区域地裂缝发育程度的次要影响因素。
4) 在第4,5,6次特征选择中,将余下的3个特征依次按上述方法加入神经网络学习,将输入层维度分别增至9,10,11维。结果如表6所示。选择煤层倾角、地形坡度、相对位置等3个特征后,虽然训练准确率有所提高,但测试准确率没有升高甚至出现下降,且训练神经网络的计算复杂度增加,稳定性变差。
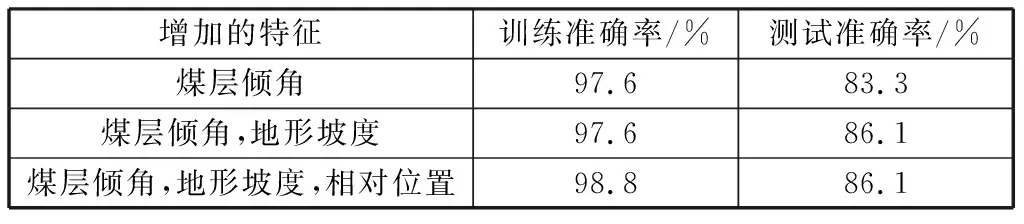
表6 第4,5,6次特征选择准确率Table 6 The 4th,5th and 7th feature selection accuracy
通过对比和分析6次特征选择后的准确率变化(图7),选择开采层数、开采总厚、开采宽度、开采深度、砂泥岩比、开采长度作为主要特征,地质构造和地表出露作为次要特征,剔除煤层倾角、地形坡度、相对位置这3个冗余特征,可以得到最优的神经网络模型。该模型在训练集和测试集上分别得到96.4%和89.1%的准确率。
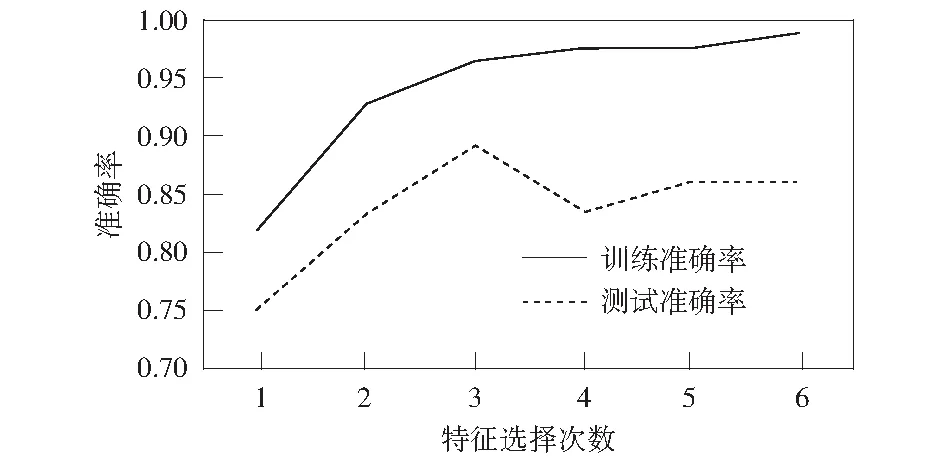
图7 准确率随特征选择次数的变化Fig.7 Accuracy rate change with the feature slection times
6 常用神经网络模型训练结果对比
常用的深度学习网络结构,除了上文中所使用的全连接深度神经网络(DNN),还有卷积神经网络(CNN)及循环神经网络(RNN/LSTM).
CNN适用于输入维度较高、具有一定的模式性或者周期性的场景,比如说图片的目标识别、类周期型传感器信息的处理等。在这些场景中,CNN利用卷积操作来重复利用参数(对模式化信息进行提取),利用池化操作来降低维度,以达到减少模型的参数量的效果。RNN适用于输入具有一定时序性的场景,比如说自然语义处理、文本翻译等。RNN可以综合利用当前输入和之前输入的信息,但是其容易发生梯度消失或者梯度爆炸,训练极不稳定。LSTM是对普通RNN的改进,它虽然可以在一定程度上缓解不稳定的情况,但是在隐藏层维度相同的情况下,会比DNN多使用3倍的参数。
本文基于选择出的8维特征,利用3种网络结构对裂缝发育程度进行了分类。调整各网络参数,使其均具有好的训练效果。其中,DNN的两个隐藏层神经元个数分别为20和10;CNN使用了两次卷积操作,卷积核的维度为(3,1),两次卷积操作的卷积核个数分别为15和10,由于输入维度较低,不使用池化操作;RNN/LSTM使用了两层结构,细胞维度均为10.训练结果如表7所示。
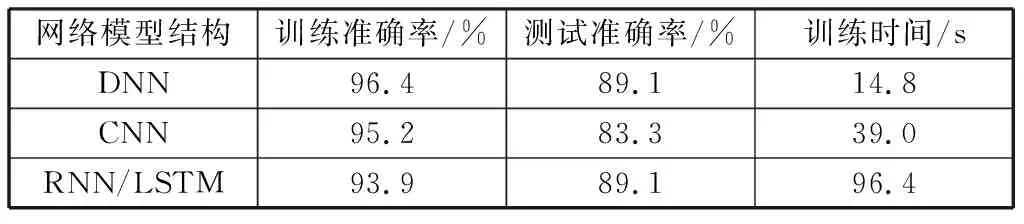
表7 DNN,CNN和RNN/LSTM模型训练结果对比Table 7 DNN, CNN and RNN/LSTM model training results
由表7可见:DNN的训练准确率高于CNN和RNN/LSTM的;DNN的测试准确率与RNN/LSTM的一致,高于CNN的。从训练时间上看,DNN的时间复杂度最低,计算时间是CNN的1/2.6,RNN/LSTM的1/6.5.本文所使用的样本维度较低,各维度之间没有模式性和时序性,CNN和RNN/LSTM无法发挥其优势,并且计算成本较高。DNN结构较为简单,参数便于调整,并且容易进行归一化和正则化操作,在本文的场景中取得了较好的训练结果。
7 结论
1) 结合官地煤矿地测资料和实地调查,将影响地裂缝发育的特征具体化为开采层数、采厚、采宽、采深、砂泥岩比、采长、地质构造、地表出露、煤层倾角、地形坡度、相对位置等11项。以地裂缝面积与采空区面积的比值作为分类依据,将采动引起的地裂缝发育程度分为4类。
2) 构建了预测地裂缝发育程度的全连接深度神经网络模型(DNN)。该模型采用双隐藏层结构,选取合理的网络参数和优化算法,提高了学习效率和准确率。该模型在训练集和测试集上分别得到96.4%和89.1%的准确率。与其他神经网络模型(CNN和RNN/LSTM)相比,DNN可以较为准确地对地裂缝发育程度进行预测,并且运行效率较高。
3) 通过特征选择得出:开采层数、采厚、采宽、采深、砂泥岩比、采长等6项特征为研究区内影响地裂缝发育程度的主要因素;地质构造发育程度和地表出露等2项特征为次要因素;煤层倾角、地形坡度、相对位置等3个特征对研究区内地裂缝发育程度的预测没有明显的相关性。
猜你喜欢
交通世界(2022年27期)2022-10-17
有色金属(矿山部分)(2022年2期)2022-07-13
资源信息与工程(2021年5期)2022-01-15
新疆钢铁(2021年1期)2021-10-14
中国科技纵横(2020年3期)2020-06-11
魅力中国(2016年38期)2017-05-27
山东工业技术(2017年3期)2017-03-16
中国科技纵横(2017年1期)2017-03-10
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
