
基于深度学习的图像修复技术研究
2020-06-02 06:30:48范新刚
江苏科技信息 2020年8期
范新刚
(广州城建职业学院,广东 广州 510925)
0 引言
传统的图形学及视觉的研究主要是基于数学和物理的方法。近年来,深度学习在视觉领域取得了很大突破。视觉领域的研究主要集中在深度学习方面,特别是在图像编辑和图像生成方面,已实现多种场景的应用。
图像补全介于图像编辑和图像生成之间,最初是一个传统图形学的问题。问题本身很直观:在一幅图像上挖一个洞,然后利用破损区域之外的信息将之补全,并且无法肉眼识别。这个问题对人类来说似乎很容易,例如一些有缺陷的图像,人的大脑会自动联想图像缺失的部分,如果有一些绘画天赋,就能凭着想象把缺失的部分补充完整。但是这个任务对于计算机来说显得格外困难。首先,问题的解决办法不唯一;其次,破损区域之外的信息如何利用、如何判断补全后的图像是否完全还原是需要解决的问题。
以深度学习为代表的机器学习,正在逐渐席卷整个图形学研究领域。研究者们逐渐发现,当传统的基于物理的模型发展遇到瓶颈时,机器学习的方法也许有助于解释复杂的数理模型。毕竟只有理解了图像的深层结构,才能更好地指导图像的生成和处理。
1 深度学习理论
1.1 人工神经网络
人工神经网络(Artificial Neural Network,ANN)是一个数学模型,是对动物神经网络的模拟,比较适用于分布式信息处理。神经网络通过大量的内部节点达到信息处理的目的。自我学习能力和自适应能力是ANN的基本特征。通过分析预设的输入和输出数量,可找出两者之间的对应规则,然后利用这些规则,用新的输入推导出输出数据,这种分析的过程称为“训练”。
在ANN中,神经元处理单元可以代表不同的对象,如特征、字母、概念或一些有意义的抽象图案[1]。网络中处理单元的类型分为3类:输入单元、输出单元和隐藏单元。研究表明,输入单元接收来自外部世界的信号和数据;输出单元实现系统处理结果的输出;隐藏单元是一个单元,位于输入和输出单元之间,不能从系统外部查看。神经元之间的连接强度通过连接权重反映,而网络单元的连接关系则反映了信息的表示和处理[2]。
一般情况下,如果只有一个神经元,就算有再多的输入也是不够的。所以,一般需要5~10个神经元,以并行的方式运算,这些神经元被称为“层”。
1.1.1 单层神经网络
由S个神经元构成的单层神经网络如图1所示。单层神经网络通过权值矩阵W,因此,输入向量p的每一个分量都可以连接到每一个神经元。因为每一个神经元都有含有一个偏置值b、一个累加器、一个传输函数f,所有这些输出共同构成了输出向量a[3]。
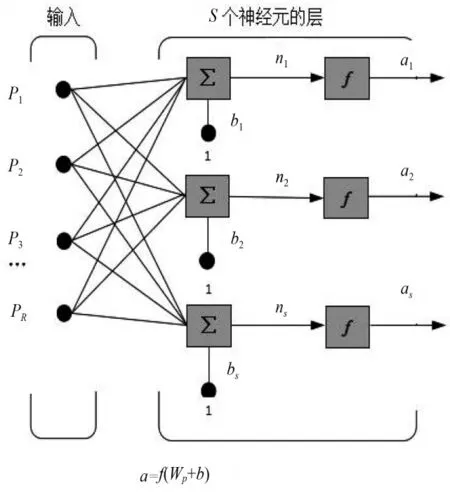
图1 具有S个神经的单层神经网络
1.1.2 多层神经网络
第一层的输入为R,有S1个神经元,第二层有S2个神经元,以此类推,第n层就有Sn+1个神经元。每一层的输出即下一层的输入。三层网络如图2所示。
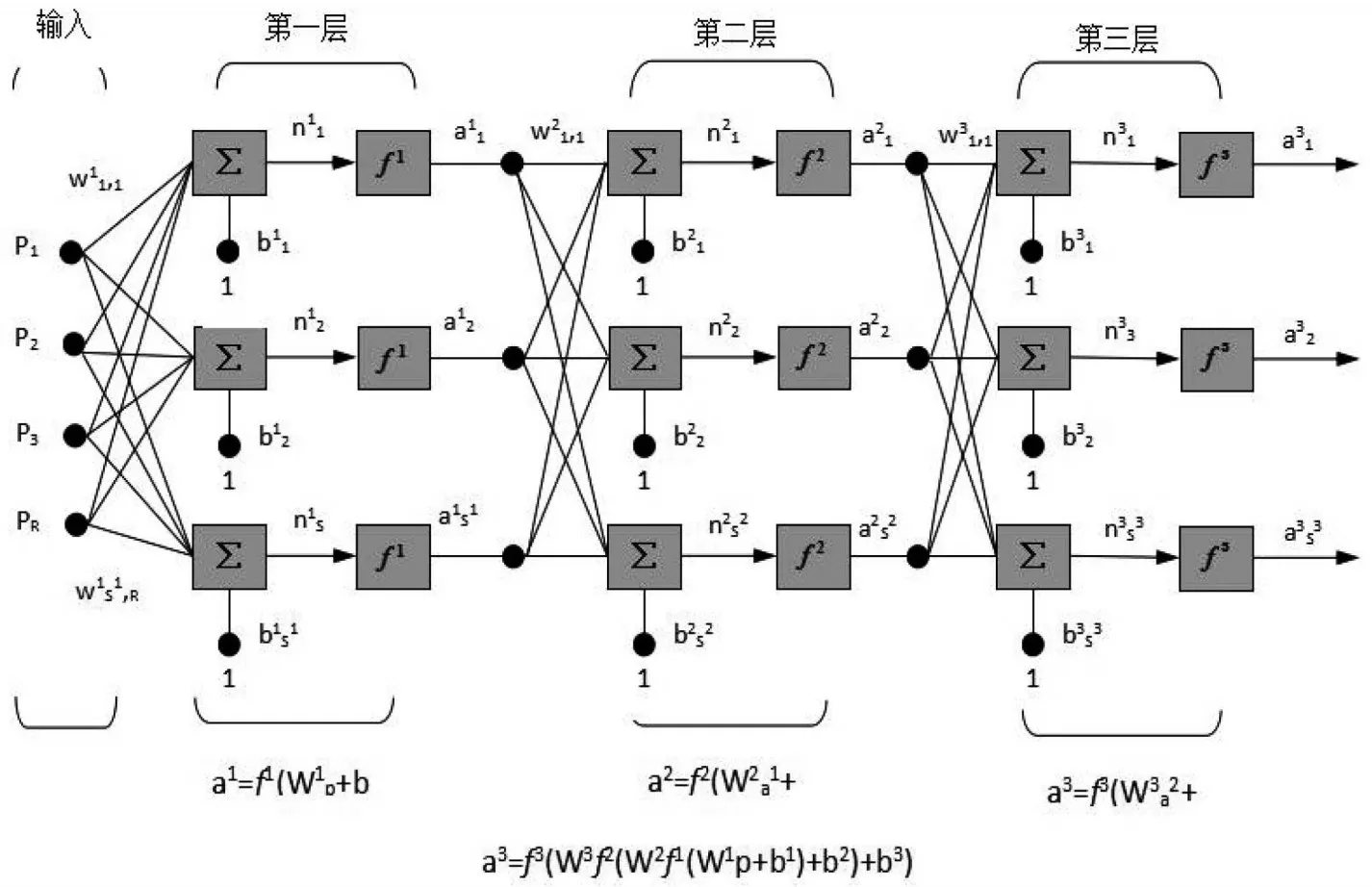
图2 三层网络
1.1.3 学习方式
(1)监督学习。监督学习是将训练好的数据作为神经网络的输入对比期望值和实际输出,得到误差,然后控制差值信号调整权值大小,快速适应新场景。
(2)非监督学习。非监督学习不需要训练后的数据,直接把神经网络放到新环境,通过提取数据特征进行学习。
1.2 深度学习
深度学习源于ANN研究的发展,这一概念在2006年被提出。基于深可信网络(Deep Belief Net‐works,DBN),提出了一种无监督的逐层训练算法,解决深层结构相关优化问题。卷积神经网络由拉科纳提出,是真正意义上的多层结构学习算法,它利用空间相关关系来减少参数的数量,提高训练性能[4]。
深度学习的目的是模拟人脑学习,建立神经网络,是机器学习的新领域,通过模仿人类大脑的机制来解释图像、声音和文本等数据。
1.3 卷积神经网络
深度学习的代表算法是卷积神经网络,是一种包含卷积计算且具有深度结构的前馈神经网络,能够平移且不变分类,因此,被称为“平移不变人工神经网络”。
卷积神经网络可以进行监督学习和非监督学习,其中,隐含层内的卷积核参数共享和层间连接的稀疏性使得卷积神经网络能够以较小的计算量对格点化特征,例如像素和音频进行学习,有稳定的效果而且对数据没有额外的特征工程要求[5]。
卷积神经网络从结构上分为输入层和输出层,其中,输入层可以处理多维数据。很多研究一般都预先假设三维输入数据,即平面上的二维像素点和RGB通道。
输入层又包含卷积层、池化层和全连接层[6]。其中,卷积层完成输入数据的特征提取,产生的特征图传递至池化层进行处理,卷积神经网络中的全连接层相当于前馈神经网络中的隐含层,通常构建在隐含层的最后,并只向其他全连接层传递信号。特征图会在全连接层中失去三维结构,被展开为向量并通过激励函数传递至下一层。
2 基于超分辨率重建的图像修复
2.1 超分辨率重建
很多图像应用程序需要高分辨率图像,即像素密度很高,可以提供更丰富的细节信息。提高分辨率,像素尺寸将减小,光通量将降低。因此,噪声会严重影响图像质量。
像素尺寸的减小不是无限的,因此,增大芯片的尺寸是另外一种提高分辨率的方法,但效率较低,因为大容量耦合的耦合系数很难提高。另外,高精度光学和图像传感器一般价格高昂,因此,为了克服传感器和光学制造技术的局限性,采用信号处理的方法,从多个低分辨率图像获取高分辨率,分辨率增强技术成为热门研究领域,称为“超分辨率”。
信号处理方法的优势是成本低廉,可充分利用现有的低分辨率图像。在医学成像、卫星图像和视频领域存在大量的低分辨率图像,因此,超分辨率图像恢复技术大有可为。
在分辨率提高技术中,通过同一场景获取多个低分辨率的细节图像,每个细节图像代表同一场景的不同侧面。如果各个低分辨率图像之间都有像素偏移,那么它们可提供不同的信息用于高分辨率图像恢复。
2.2 基于深度学习模型的图像修复
实验环境为NVIDIA云计算平台,客户端为Win‐dows10系统,工具为Python-3.7.2-amd64,本团队进行了大量的图像训练,训练次数达到600 000次。在训练过程中,尝试使用了线性插值以凸显图片特征,但是整个过程中需要大量的插值操作,对于经过几十上百万次训练的卷积神经网络来说,几乎不可能完成。
后来发现,增加卷积层的数量,可以提高模型的性能,因此,实验将卷积层数量设定为10。
本次实验准备了4张打码的图像,如图3所示,经过十几个小时的训练模型建立,最终修复的图像如图4所示。
本次实验同时进行了马斯克去除测试,准备了若干带有马赛克的图像,训练模型建立后,测试结果如图5所示(左边为去除之前)。

图3 打码的图像

图4 修复的图像

图5 测试结果
3 结语
文章探讨了深度学习、卷积神经网络、超分辨率重建等相关理论,利用NVIDIA云计算平台进行大量的深度学习,建立修复模型,同时,通过增加卷积层数量,提升了学习训练效率;实验对比可知,图像修复达到了一定效果。但是,尚有许多不足和需要改进的地方,例如训练次数不够。因此,图像修复效果不尽如人意,这是以后继续努力的方向。
(责任编辑 顾培培)
猜你喜欢
红外技术(2022年11期)2022-11-25 08:12:22
电子产品世界(2022年9期)2022-05-30 20:41:07
自然杂志(2021年6期)2021-12-23 08:24:46
数学物理学报(2019年3期)2019-07-23 01:15:40
家庭影院技术(2018年9期)2018-11-02 05:31:32
艺术科技(2018年2期)2018-07-23 06:35:17
现代装饰(2018年5期)2018-05-26 09:09:01
自动化学报(2017年5期)2017-05-14 06:20:52
成都信息工程大学学报(2017年6期)2017-03-16 03:04:32
电源技术(2015年5期)2015-08-22 11:18:38
