
CDN-P2P混合结构中的协同过滤推荐算法
2020-05-30 08:07:14杨毓茹郑佳春彭新哲
莆田学院学报 2020年2期
杨毓茹,郑佳春,彭新哲∗
(1.集美大学 信息化中心,福建 厦门 361021;2.集美大学 信息工程学院,福建 厦门 361021)
0 引言
内容分发网络(CDN)是互联网服务背后的重要支撑者,迅猛发展的互联网给CDN服务质量带来很大压力。CDN与P2P相结合,可在一定程度上减轻CDN的负载。由于用户需求的复杂性,单纯依靠P2P节点的内容共享,还不足以保证CDN的服务质量,需要选取适合的内容预分发策略[1-2]来提升整个网络的服务响应速度。
现今提出的预分发策略多是针对某个服务器上的内容被需求的程度而做出的一个整体预测,并没有对每个用户进行具体的需求分析,针对该问题,本文提出通过智能推荐算法来对用户进行需求的预测,从而进行内容的预分发。在CDNP2P网络中,用户所发生的行为过程与协同过滤推荐算法中使用用户评分表述用户需求是类似的,故可以将协同过滤推荐算法的基本思想应用于CDN-P2P网络的内容推荐服务中。
针对传统的协同过滤推荐算法,国内外诸多学者提出了改进的启发式推荐算法以提高算法的推荐精度。为了提高用户相似性的有效程度,文[3]提出了基于泊松分布的新的相似性度量方法,改善了用户之间的共同评分项对用户相似性计算的影响;为了解决数据稀疏情况下对推荐精度的影响,文[4]提出基于最近邻的协同过滤推荐算法,对有推荐能力的用户的未评分项进行评分预测;有部分学者采用基于模型的算法来提高推荐精度,文[5]关联了数据挖掘技术与协同过滤推荐算法提出基于关联规则挖掘的协同过滤推荐算法,该算法具较强的鲁棒性,代价是推荐精度的降低,同类做法还有文[6];另外,还有部分学者将用户间的信任关系引入推荐过程,并提出信任计算模型,文[7]借鉴社会网络中人与人之间的信任评价方法提出了基于信任机制的协同过滤推荐算法,文[8]融合社会环境信息的推荐算法,将RSTE算法应用到基于隐式信任关系的推荐中,类似的做法还有文[9-11]等。
本文在已有研究的基础上,对协同过滤推荐算法进行改进。通过在节点相似性的计算过程中引入泊松分布概率质量函数对相似性的有效程度进行调整,解决了节点共同需求项数量较小对用户相似性的计算造成较大影响的问题,然后根据节点相似性的大小选择一批最近邻居节点,针对不同的类别计算最近邻居节点的相似性得到个别相似性,然后利用信息熵的原理计算个别相似性的熵值得到节点邻居推荐权值,该推荐权值可以代表一个节点在对其他节点兴趣挖掘过程中的贡献程度,最后生成节点需求预测结果。
1 相关定义
将协同过滤推荐算法应用于CDN-P2P混合网络中,P2P节点代表用户,网络中的文件代表项目,用户共同需求内容代表共同评分项。定义集合P=(p1,p2,...,pn)表示节点的集合,集合C=(c1,c2,...,cm)表示内容的集合,矩阵(rij)m×n表示节点对内容的需求程度矩阵,rij表示节点pi对内容cj的需求程度。
定义1 皮尔森相关系数[4]:
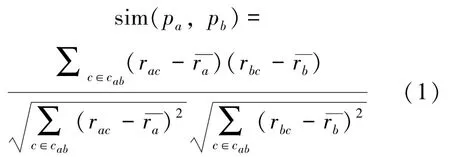
定义2 泊松分布:用来描述单位时间内随机事件发生的次数的概率分布,概率质量函数为:
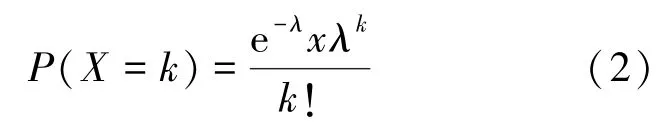
其中,X表示随机变量,k为X的一个取值,P(X=k)为X取值为k的概率,e(e=2.71828…)为自然对数的底,λ为单位时间内随机事件的平均发生次数。
定义3 信息熵:在信息论中用来对不确定性的一种度量,可以通过熵值的计算来判断某个指标的离散程度,指标的离散程度越大,对综合评价的影响也越大,信息熵的计算为(3)式:
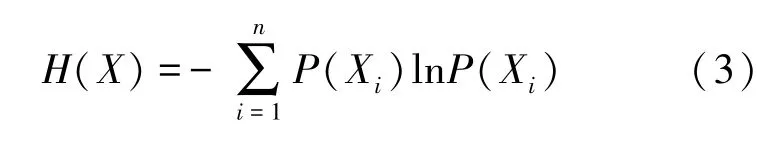
其中,X表示随机变量,其取值为X1、X2…Xn,n为X的取值个数,P(Xi)为X取值为Xi的概率。
2 基于泊松分布和信息熵的协同过滤推荐算法
2.1 基于泊松分布的节点相似性
通过分析节点之间的需求相似性发现,假设节点Pa和Pb的共同需求项数量为1,且需求程度相差较大,若直接利用式(1)计算两者之间的相似性,其值为1.0,则双方就会进入对方的最近邻居集合,这将对预测结果产生重大影响。因此,在相似性计算过程中,需对相似性的有效程度进行调整。
在完全随机的情况下,节点Pa和Pb拥有共同需求内容的数量为CDPab的事件与泊松分布描述的经典例子,即一定时间内进入银行的客户数量类似。利用泊松分布,用户共同需求项目数量出现的概率可调整为:
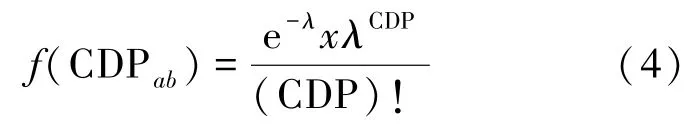
其中,f(CDPab)表示节点Pa和Pb之间相似性的有效程度,λ为取定的时间段内,节点共同需求内容数量的平均值。相应地,基于泊松分布的节点需求相似性度量可表示如下:

2.2 节点个别相似性
在P2P子网中,随着节点共同需求数量的增加,节点需求的相似情况也趋于复杂。当获取的节点内容需求程度信息足够多时,需要区分节点在不同类别内容上的需求相似性。
定义4 个别相似性:针对不同类别的内容文件,按照类别计算节点之间的相似性。节点Pa和Pb在内容类型tx上的个别相似性可表示为:
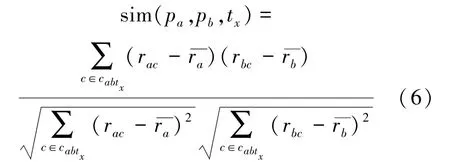
其中,Cabtx是Cab集合中内容类型为tx的子集。
2.3 基于信息熵的邻居节点推荐权值
在表征用户兴趣特征的过程中,拥有较强烈兴趣倾向的用户对其他用户的影响较大,在此可利用熵值法来确定用户邻居的推荐权值,用来衡量一个邻居节点在对该节点用户的内容需求预测过程中的贡献程度。
假设节点Pa为待推荐节点,则节点Pa的邻居节点Pb的熵值为:
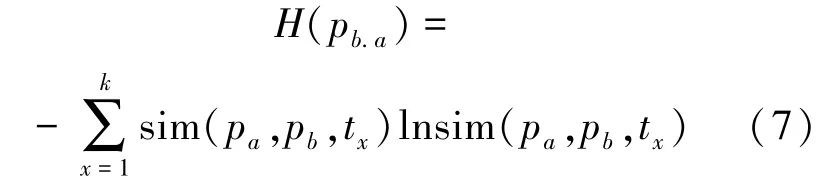
其中,k表示类别的总数。H(pb.a)的取值范围在[-1,1]内,该值越大,则说明节点Pb对各类内容的需求性相近,同时也说明能够表征该用户需求特征的内容很少或者没有,用户兴趣特征的不确定程度较高。
定义5 邻居推荐权值:用来衡量一个邻居节点在对该节点用户的内容需求预测过程中的一个贡献程度,计算方法如式(8)所示:
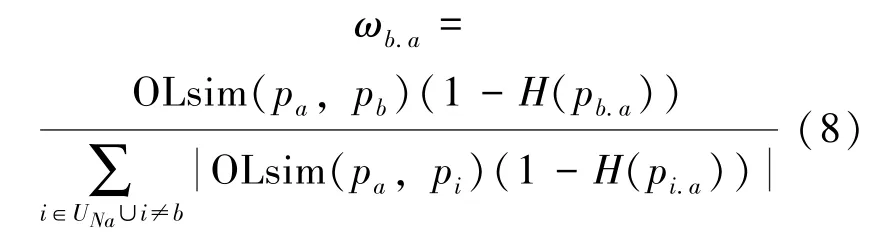
其中,UNa表示节点Pa的邻居用户节点的集合。ωb.a表征了节点Pb在对节点Pa进行需求预测过程中的贡献程度,从式(8)可以看出节点Pb的熵值越小,Pb的推荐权值越大,说明节点Pb对节点Pa的兴趣影响越大。
3 实验与分析
3.1 实验数据与环境
实验使用美国Minnesota大学GroupLens项目组提供的数据集MovieLens-100 K、MovieLens-1 M以及Netflix公司提供的Netflix数据集作为评价数据集,由于Netflix数据集过于庞大,本文在此选取其中2000名用户对4000部电影的评价数据进行实验,具体信息如表1所示。
在下面的实验中,分5次抽取,每次分别随机抽取每个用户的5%、10%、15%、20%、25%的评分数据作为测试数据集,剩下的评分数据作为训练数据集。
实验环境:Intel(R)Core(TM)i3-3210M CPU@3.20GHz,4G内存,Windows7 32位操作系统。采用JAVA实现算法,并利用MATLAB画 出实验图表。

表1 数据集情况表
3.2 度量标准
选用平均绝对误差(MAE)、均方根误差(RMSE)作为评测指标对推荐算法进行评价。计算公式如下,与MAE相比,RMSE对大误差更为敏感。
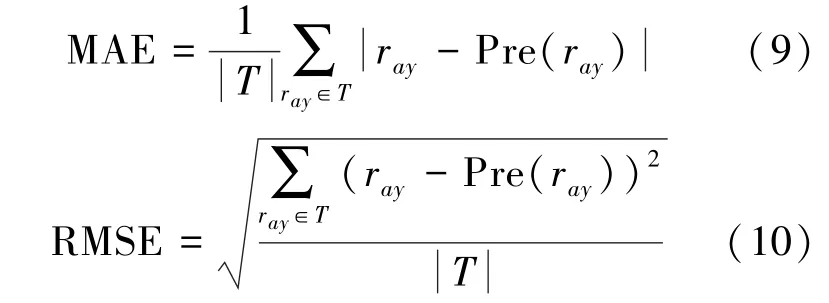
3.3 实验结果
本文对提出的基于泊松分布和信息熵的协同过滤推荐算法(PDIE-CF算法)进行实验验证,并引进了传统的基于皮尔森相关系数的协同过滤推荐算法(PCC-CF算法)、基于余弦夹角相关性的协同过滤推荐算法(VS-CF算法)、基于修正余弦夹角相似性的协同过滤推荐算法(AVS-CF算法)以及文[3]提出的改进的相似性计算的协同过滤推荐算法等进行算法性能的比较分析。
3.3.1 不同最近邻居数的实验效果
本实验选取10个最近邻居数(分别为10~100,间隔为10)来验证最近邻居数对实验结果的影响,实验对相同分组下同一最近邻个数的5个分组的MAE及RMSE值求平均。从图1、图2、图3可知,各实验分组在不同的最近邻个数情况下,由PDIE-CF算法得到的MAE值与RMSE值均显著低于其他算法,并且最近邻居数的变化对PDIE-CF算法的推荐精度的影响较小,在取不同最近邻个数的情况下,MAE值与RMSE值并无显著变化,该算法在较少的最近邻个数的情况下可以保证推荐质量。
3.3.2 不同数据集的实验效果
本实验对相同实验分组下同一最近邻个数的5个分组的MAE值及RMSE值求均值,从PCCCF、VS-CF、AVS-CF 3个算法中选择实验效果最好的PCC-CF算法与本文的PDIE-CF算法比较分析,并将3个数据集的实验结果进行对比,如图4与图5所示。
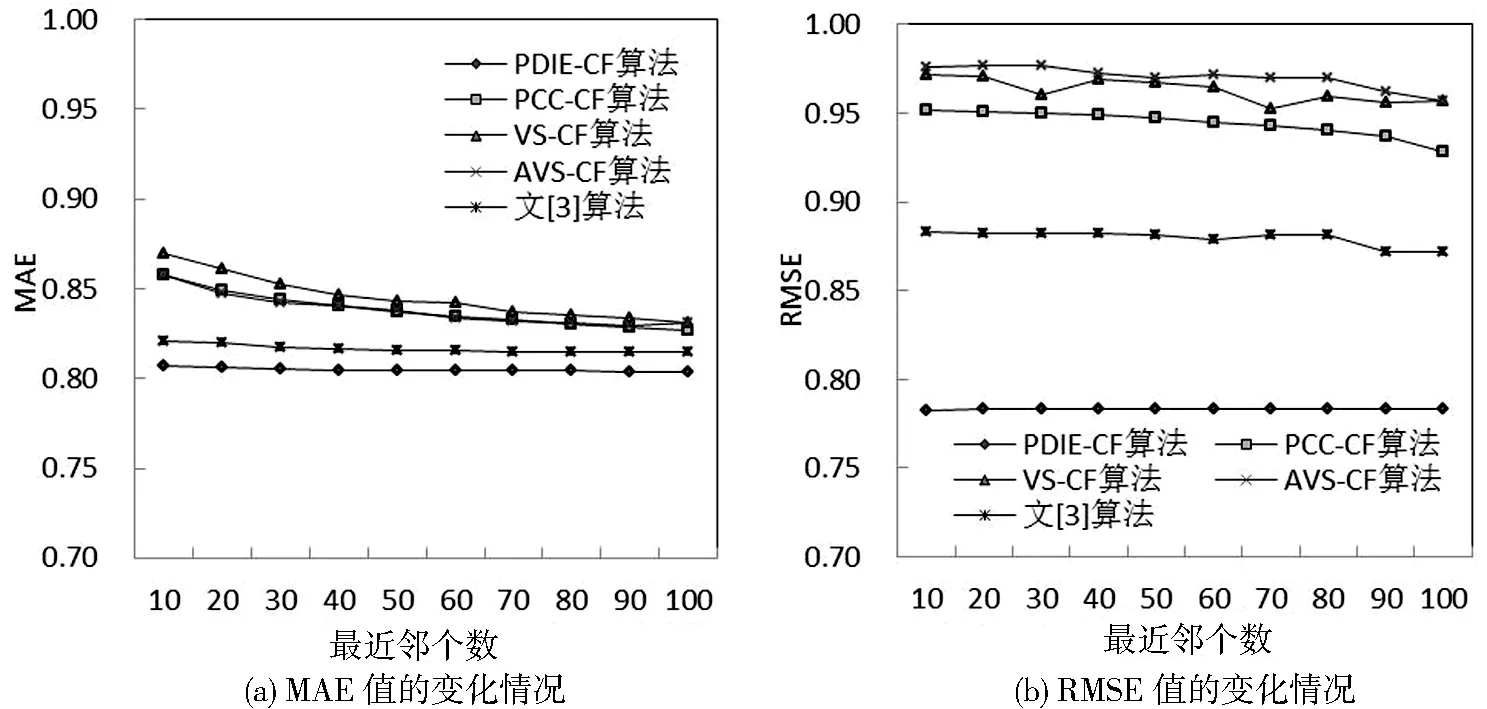
图1 MovieLens-100K实验效果图
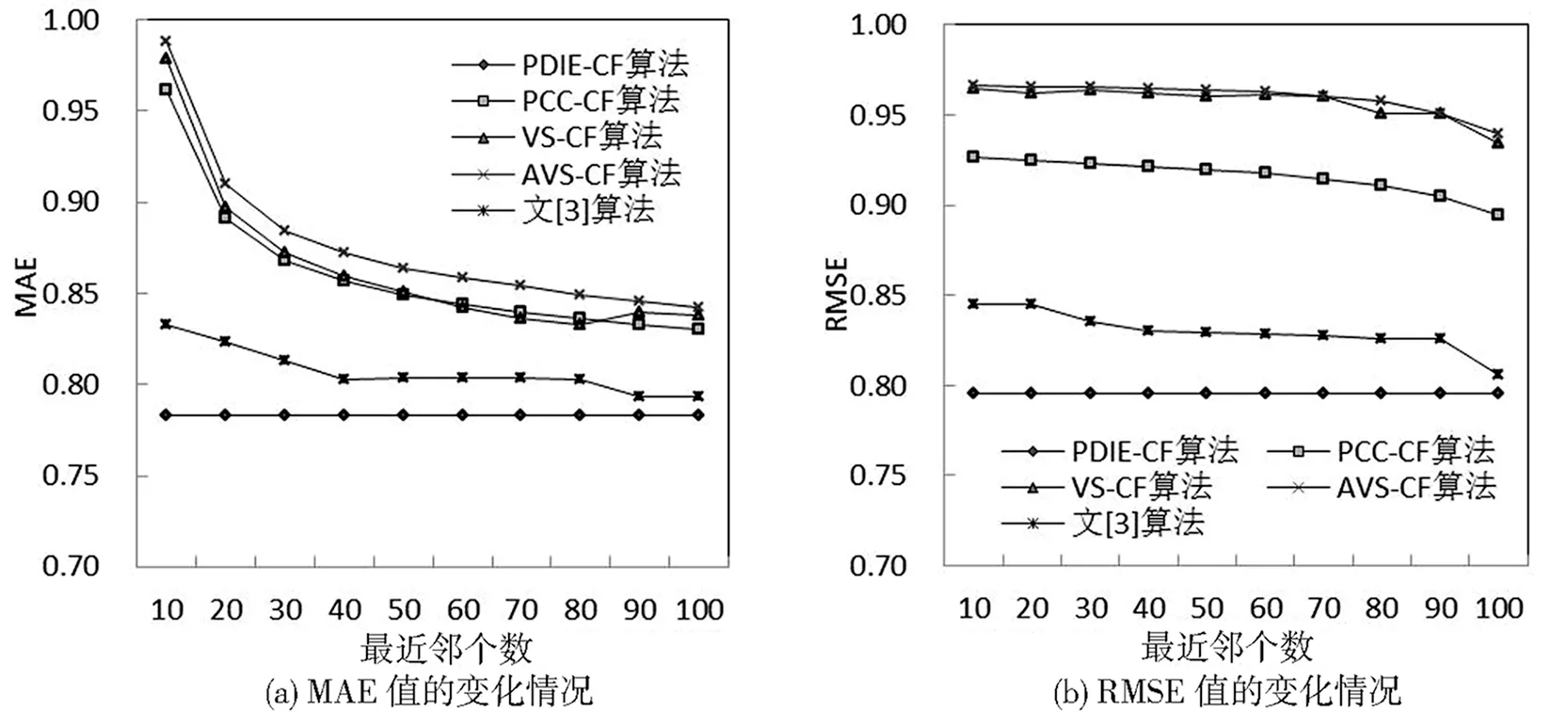
图2 MovieLens-1M实验效果图
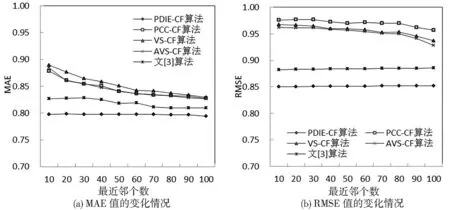
图3 Netflix实验效果图
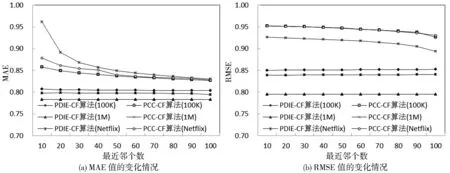
图4 两种算法处理3个数据集实验对比图
图4表明,PCC-CF算法在MovieLens-1M数据集中的MAE值高于MovieLens-100K数据集和Netflix数据集,而RMSE值则较低,PDIE-CF算法在MovieLens-1M数据集中的MAE值及RMSE值均为最好,图4同时也表明PDIE-CF算法与PCC-CF算法相比,算法精度的稳定性较高。从图5亦知,在MovieLens-1M数据集上推荐精度提高的百分比明显高于MovieLens-100K数据集和Netflix数据集。
从以上分析可得出:数据集越大,评分记录数越多,改进后算法推荐的精度越高,故改进后的推荐算法能够很好地适应CDN-P2P网络环境。
3.3.3 不同数据稀疏性的实验结果
为了研究数据稀疏性对实验结果的影响,本实验将同一分组下的不同最近邻个数的MAE值及RMSE值进行均值运算,并将两个数据集的实验结果进行对比,如图6所示。
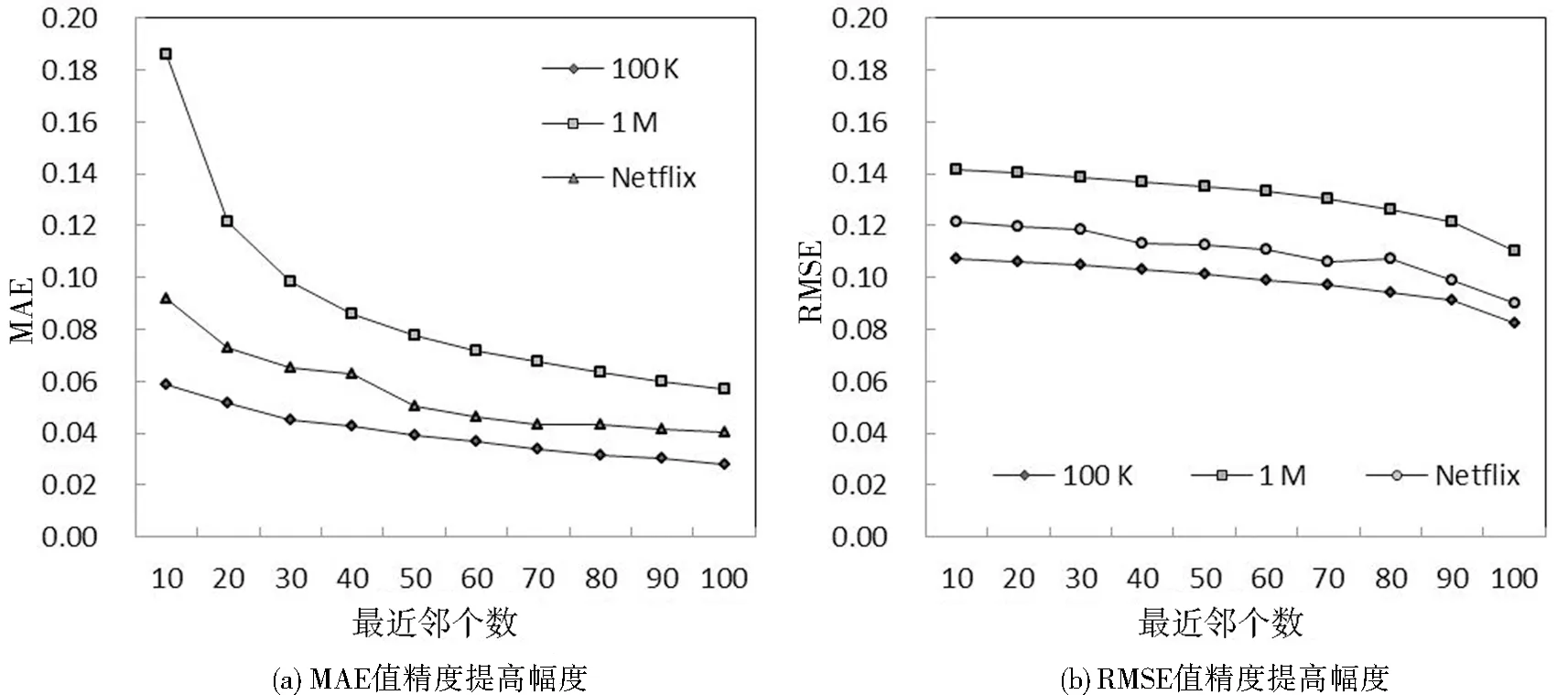
图5 3个数据集精度提高对比图
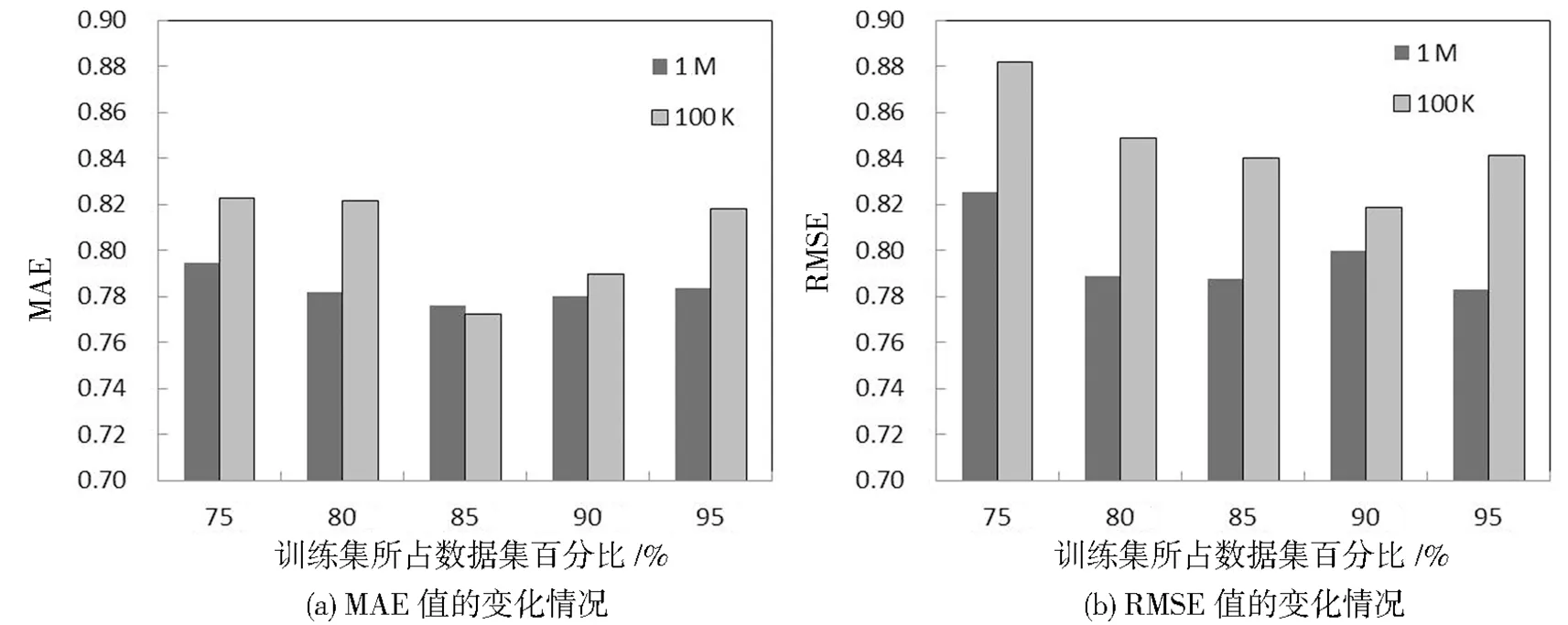
图6 MovieLens-100K和MovieLens-1M抗稀疏性比较
在从实验结果可以看出,当训练集在整个数据集中的比例为85%~90%的时候,PDIE-CF算法的性能最佳,推荐的精度是最高的。当比例低于85%时,用于计算用户之间相似性共同评分数量较少,计算出的相似性具有一定的偶然性;当比例高于90%时,该推荐算法的精度也会降低,用于计算用户之间相似性共同评分数量较多,由于所引进的泊松分布的特性,导致预测值会降低,从而影响推荐效果。另外,从图6可得知,相较于MovieLens-100K数据集,MovieLens-1M数据集受训练集比例影响的变化较小,说明当数据集较大,用户评分数量较多时,改进后的算法具有较强的抗稀疏性能力。
4 结语
本文引入泊松分布和信息熵对传统的协同过滤推荐算法进行改进。实验结果表明,与原始的协同过滤推荐算法相比,改进后的算法具较高的推荐精度,对最近邻居数的依赖较小,并且当用户评分数量越多时,推荐的精度越高,抗稀疏性越好。PDIE-CF算法还存在待研究的问题,比如:如何提升算法的运行效率,如何降低泊松分布函数特性对推荐精度的影响等,这些都是后续要进行的工作。
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:58:18
数学物理学报(2022年5期)2022-10-09 08:56:44
科学大众(2020年23期)2021-01-18 03:09:08
数学物理学报(2020年6期)2021-01-14 01:00:34
河北画报(2020年8期)2020-10-27 02:54:20
汽车观察(2019年2期)2019-03-15 06:00:50
中国卫生(2016年5期)2016-11-12 13:25:26
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
数学年刊A辑(中文版)(2015年2期)2015-10-30 01:56:20
数学物理学报(2015年4期)2015-02-28 16:06:52
