
基于改进蝙蝠优化自确定的模糊C-均值聚类算法
2020-05-29 11:54:50汤正华
计量学报 2020年4期
汤正华
(中共山东省委党校 信息技术部,山东 济南 250103)
1 引 言
聚类实质是一种非监督机器学习方法,通常作为数据挖掘中其他分析算法的预处理步骤,通过聚类使同一类簇内数据具有较大的相似度,而不同类簇数据具有较小的数据相似度,以更好地揭示数据的分布情况[1]。不是所有的数据对象都能按照硬聚类划分方法将其进行聚类划分。Dunn J C[2]提出了模糊C-均值聚类算法(fuzzy C-means, FCM);Bezdek J C[3]将模糊C-均值聚类算法进一步地推广并实际应用到数据聚类分析中。
模糊C-均值聚类算法同K-mean聚类算法一样具有算法简单、聚类快的特点,但该算法也存在敏感于初始聚类中心、易陷入局部最优和算法收敛缓慢等缺点。有鉴于此,国内外学者进行了大量的研究和改进。文献[4]利用密度峰值改进模糊C-均值聚类,使用密度峰值函数找出数据集中密度较大或距离较大的数据点作为初始聚类中心,既解决了算法敏感于初始中心,又确定了聚类数目;文献[5]利用改进的自适应遗传算法优化改进模糊C-均值聚类,有效避免了传统模糊C-均值聚类易陷入局部最优;文献[6]利用改进的人工蜂群算法对核C-均值聚类算法进行优化,取得了鲁棒性强和聚类精度高的聚类结果;文献[7]通过引入差分进化算法中变异和交叉思想对人工蜂群进行改进,利用改进的人工蜂群优化模糊C-均值聚类。群智能优化算法因其实现简单、扩展性强、优化效果突出等优点得到了广泛的应用和推广。蝙蝠算法吸取了粒子群和模拟退火算法的优点,具有算法简单、可操作性强等优点[8]。
本文在原始蝙蝠算法中引入Levy飞行特征加强算法跳出局部最优能力,使用Powell局部搜索加快算法收敛,以此改善蝙蝠算法易陷入局部最优和收敛缓慢等问题,并利用改进后的蝙蝠算法寻最优蝙蝠位置,将此作为模糊C-均值聚类的聚类中心,进行模糊聚类,两个算法交叉迭代多次,以获得最优的聚类结果。
2 模糊C-均值算法
2.1 传统模糊C-均值算法
设数据集X={xi∈Rd,i=1,2,…,n},xi为d维向量即每个数据元素含有d个属性,需要将数据集X划分为c类(2≤c≤n),聚类中心为E={e1,e2,…,ec},模糊C-均值算法目标函数定义如下:
(1)

步骤1:初始化参数,设定模糊加权系数m,聚类数目c和聚类数据集合E;
步骤2:计算隶属度矩阵U,
(2)
步骤3:更新聚类中心数据集E:
(3)
步骤4:若新聚类中心与前聚类中心距离小于给定的容许误差ε时,算法迭代终止;否则转向步骤2。
模糊C-均值算法利用梯度下降法求得最优值,每一次迭代都是趋于目标函数极小值方向,但目标函数可能有多个极值点,假若初始聚类中心只在一个极值附近,极易陷入局部最优;另外,传统模糊C-均值算法需要指定聚类中心数目,对于庞大无序的数据集,很难人为精确地指定聚类中心数目。针对以上问题,本文将基于数据点密度峰值综合衡量聚类中心外围数据密集程度和聚类中心间距离,自动确定聚类中心和聚类数目,以此作为改进蝙蝠算法的初始中心。
2.2 基于密度峰值确定聚类中心
Alex等提出了一种新的密度聚类算法(clustering by fast search and find of density peaks,CFSFDP)[9],该算法通过计算数据点密度,将具有局部密度较大的中心点作为聚类中心,实现大数据对聚类中心自动选取。但算法采用决策图对预期的高局部密度和高密度距离进行手动选择,当单个集群存在多个密度峰值时,难以获得聚类数。有鉴于此,本文通过计算数据点密度峰值综合衡量聚类中心外围数据密集程度和聚类中心间距离,以自动获取较为准确的聚类中心和聚类数目。原始CFSFDP算法中,数据点i的局部密度ρi为:
(4)
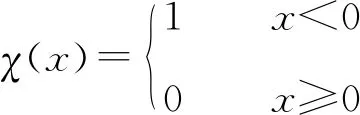
(5)
式中:dij表示数据点i、j间的距离;dcut为截断距离,其值为经验值,一般取距离矩阵dij排序后1%~2%的值。δi表示局部密度大于点i的局部密度的点中与点i距离的最小值:
δi=minj:ρj>ρi(dij)
(6)
原始CFSFDP算法会构造以局部密度ρi为横轴,以δi为纵轴的决策图。根据决策图人工选择局部密度ρi和高密度距离δi的数据点,将明显远离绝大部分样本的右上角区域的密度峰值点作为一个聚类中心。这种采用手动确定聚类中心的方式存在人为的主观性,本文利用数据集的密度程度,客观自动地选取聚类中心和聚类数目。为了全方位体现数据集密集程度,对各数据点计算如下:
ECi=δi≥2σ(δi)
(7)
式中:σ(δi)表示所有高密度距离的标准差; ECi表示数据集i期望的聚类中心。根据CFSFDP算法的思想,聚类中心之间应该具有较大的距离,因此聚类中其他数据点的高密度距离应该不大于2σ(δi);但现实中也会存在具有较大的δi值而低局部密度的噪音聚类中心,这种噪音聚类中心一旦被选中极易干扰其它正常聚类中心定位选取,为此需要将此类噪音聚类中心予以剔除:
LCi=ECi≥μ(ρi)
(8)
式中:μ(ρi)表示ρi均值;LCi表示数据集i去噪后的聚类中心。通过利用式(8)的比较,剩余的聚类都比相邻的数据点具有更高的局部密度和密度距离。
3 蝙蝠算法及其改进
3.1 蝙蝠算法
蝙蝠算法(bat algorithm,BA)通过模仿蝙蝠声呐探物,不断调整频率、脉冲等因素在解空间中搜索最优值。算法对蝙蝠位置和速度按照式(9)~式(11)进行迭代:
pi=pmin+(pmax-pmin)α
(9)
(10)
(11)
脉冲频率pi的取值是随机的,最大最小值分别为pmax、pmin,在进行局部搜索时,每只蝙蝠位置更新为:
Xnew=Xold+δAt
(12)
式中:δ为[-1,1]上的随机数;At为所有蝙蝠在t次迭代上的平均响度。随着迭代的增加,蝙蝠的脉冲发射频率和响度也会更新:
(13)
(14)

在求解无约束优化问题上,蝙蝠算法优于遗传算法和粒子群优化算法[10],但也存在易陷入局部最优、收敛过慢等问题。为此,本文引入Levy飞行特征,以加强算法跳出局部最优的能力;在得到最优蝙蝠值后对其进行Powell局部搜索,加快算法收敛。
3.2 Levy飞行特征局部寻优
Levy飞行过程具有随机游走和随机发现的特性,能够节约活动成本和缩短活动距离,是一种有效提高活动效率的方式;其保持局部搜索能力的同时,可有效避免了陷入局部最优的风险。在智能算法中采用Levy飞行策略可以扩大算法的搜索范围,种群的多样性得到提高。本文将Levy飞行特性引入蝙蝠算法中,利用Levy飞行特性扩展搜索空间,对蝙蝠的位置进行改进:
(15)
式中:“·”表示点乘积;Levy(ξ)是随机搜索路径,步长的大小通过Levy分布随机数产生且1≤ξ≤3。改进后蝙蝠算法的搜索脉冲频率依旧决定蝙蝠移动的速度,与原算法的搜索行为一致,而引进Levy分布后扩展了蝙蝠的搜索空间,能够避免陷入局部最优。
3.3 Powell局部搜索
Powell算法又称鲍威尔共轭方向法或方向加速算法,是直接利用函数值构造共轭搜索方向的一种搜索算法。该方法不需要对目标函数进行求导,当目标函数的导数不连续时也能应用,对于n维正定二次函数,共轭搜索方向具有n次收敛的特性。本文利用密度峰值综合数据集节点外围数据密集程度,自动获取较为准确的聚类中心和聚类数目,提升初始蝙蝠种群的均匀度。鲍威尔共轭方向法步骤为:
步骤1: 将此次迭代搜索到的结果作为初始点c(0),设搜索精度为ε′,给定n个初始无关搜索方向d(i)(i=0,1,2,…,n-1),一般取n个坐标轴方向,j=0。
步骤2: 令c(0)=c(j), 从c(0)开始依次沿d(i)(i=0,1,2,…,n-1)方向进行一维搜索, 可得c(i)(i=1,2,…,n):
f(c(i)+ωid(i))=minf(c(i)+ωd(i))
(16)
c(i+1)=c(i)+ωid(i),i=0,1,2,…,n
(17)
式中:ω、ωi为步长,其中ωi为精确搜索得到的一维最优解。

步骤4: 确定搜索方向,按照式(18)计算指标m:
(18)
步骤5 :若f(c(0))-2f(c(n))+f(2c(n)-c(0))≥2[f(c(m))-f(c(m+1))]成立,说明d(0),d(1),…,d(n-1)线性无关,搜索方向不变,c(j+1)=c(n),j=j+1,返回步骤2,否则执行下一步。
步骤6:说明以上搜索方向线性相关,需调整方向,令d(m+i)=d(m+i+1)(i=0,1,…,m-n-1),保证新搜索方向线性无关,c(0)=c(j+1),j++,返回步骤2。
3.4 适应度函数及蝙蝠编码
适应度函数主要用来评价蝙蝠的优劣程度,适应度函数把蝙蝠算法与模糊C-均值算法联系起来,对于模糊C-均值算法而言,最优的结果就是使目标函数即式(1)的值最小,而对于蝙蝠算法而言,最优解就是使适应度函数值最大,设适应度函数:
(19)
蝙蝠算法采用实数据编码,一个编码对应一个可行解,每个蝙蝠由s个聚类中心构成。设当前数据需要分为s类,每个数据为q维特征,用于实数进行编码,以基于密度峰值模糊C-均值算法获得的聚类中心作为寻优变量,每个可行解是由k个聚类中心构成,由于解的维数是q维,这里可行解的位置为k×q维向量,可行解的编码示例结构如表1所示。

表1 蝙蝠算法编码结构
表1中Zk1,Zk2……Zkq代表第k类的q维聚类中心。
3.5 基于蝙蝠优化的模糊C-均值算法
通过上述三个方面的改进,本文提出了一种基于改进蝙蝠优化自确定的模糊C-均值聚类算法。算法的整体步骤为:
Step1:初始化蝙蝠种群的速度、脉冲频率、脉冲响度和脉冲发射速率等基本参数,模糊系数m,容许误差ε。
Step2:求出数据集中各数据点间的距离dij,取距离矩阵dij排序后2%值为截断距离dcut。
Step3:利用式(4)和式(6)计算各个数据点的ρi和δi。
Step4: 用式(7)和式(8)确定局部聚类中心,然后合并成数据集全局聚类中心,并作为后续蝙蝠算法的初始聚类中心,生成Num个蝙蝠的初始化种群。
Step5: 计算每个蝙蝠的适应度值,找出最优蝙蝠位置;并根据式(9)、式(10)、式(15)生成新的蝙蝠位置和速度。
Step6: 产生一个随机数R1,if(R1>ri)则对当前群体中最优蝙蝠位置进行随机扰动,用扰动得到的位置替换当前蝙蝠位置。
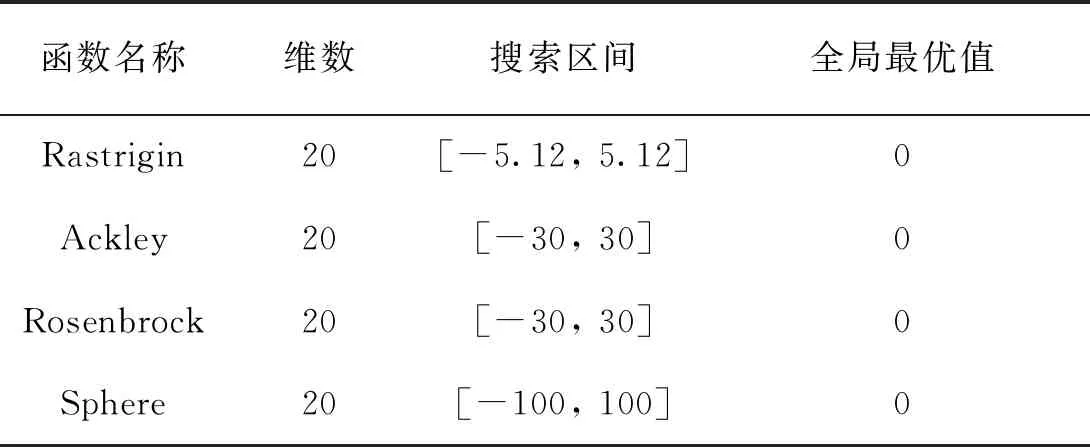
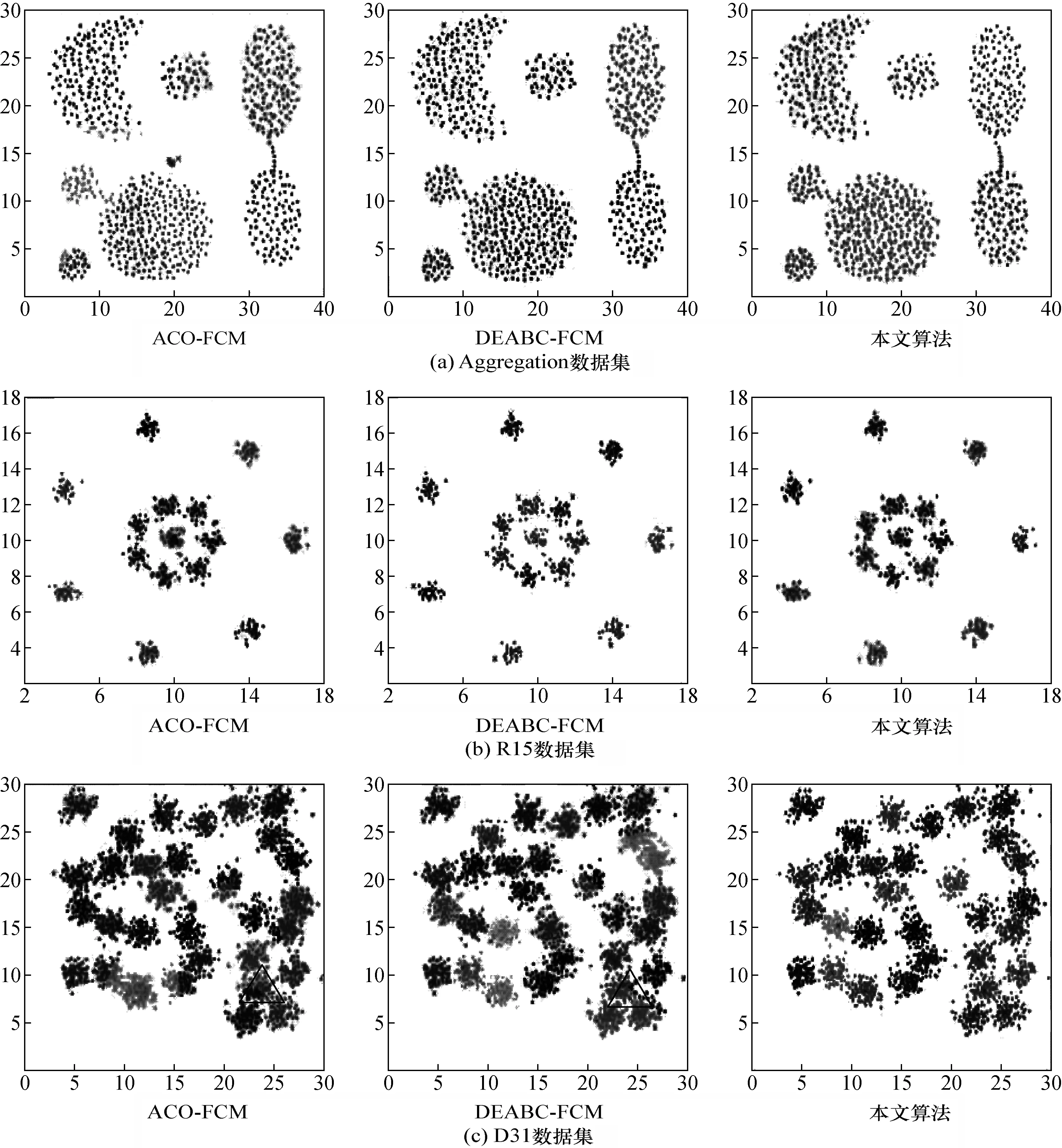
Step7:生成随机数R2,if(R2 Step8:对蝙蝠群体进行评估,将最优蝙蝠位置进行Powell局部搜索。 Step9: 根据Powell局部搜索结果移动蝙蝠群体位置,找出当前最优蝙蝠。 Step10:将最优蝙蝠位置作为新的聚类中心,判断蝙蝠算法是否达到结束条件,若是,执行下一步;否则,Num--,返回Step5。 Step11:将改进蝙蝠算法得到的新聚类中心作为模糊C-均值聚类算法的初始中心进行聚类划分。 Step12: 判断聚类算法是否达到结束条件;若是,执行下一步,否则返回Step2。 Step13: 输出聚类结果,算法结束。 为了验证本文改进算法的优越性,从两个方面进行对比仿真实验:一是选取测试函数与其它智能优化算法对比寻优效果;二是选取经典数据集与其它改进的聚类算法对比聚类效果。仿真是在windows 7系统下使用MATLAB2014a,CPU:i5-6500@3.2G Hz,RAM:4GB。 将本文算法、粒子优化算法(PSO)和蝙蝠算法(BA)在4个标准函数[11]上求解测试寻优效果。BA参数设置如下:r0=0.8,A=0.25,κ=0.02,η=0.9,本文改进算法的基本参数与BA一致,其中飞行尺度参数ξ=1.5,模糊系数m=2。PSO参数设置为[17]c1=c2=1.496 2,ωmax=0.9,ωmin=0.4,种群规模为50,最大迭代次数100次。每种算法运行50次取平均值。 表2 4个标准函数 图1为3种智能优化算法对表2中4个标准函数的寻优收敛曲线。 由3种智能优化算法在4类标准函数上的寻优曲线可以看出:BA和PSO对Sphere、Rosenbrock、Rastrigin 3种标准函数的寻优效果一般;随着迭代次数的增加,在多峰函数Ackley上,PSO收敛速度缓慢,寻优精度不精。随着迭代次数的增加,BA对Rastrigin、Ackley两种多峰函数,表现出收敛速度过快且易早熟的现象;而本文改进的蝙蝠算法,随着迭代次数的增加,不管对Sphere、Rosenbrock两种单峰函数还是对Rastrigin、Ackley多峰函数,都能在一定的迭代次数上得到理论最优值,且寻优精度高。 图1 3种智能优化算法寻优收敛曲线 为验证本文改进聚类算法的聚类效果,将文献[7](DEABC-FCM)、文献[12](ACO-FCM)和本文算法在Aggregation[13]、R15[14]、D31[15]等3类标准数据集上进行聚类对比验证。3个数据集的参数如表3所示。 将本文聚类算法、DEABC-FCM和ACO-FCM分别在3个数据集上进行聚类分析,其中DEABC-FCM和ACO-FCM两种算法聚类数目需要手动确定,而本文算法的聚类数目自动生成。聚类结果如图2所示。 表3 3个数据集参数 图2 3种聚类算法的聚类图谱 由图2聚类图谱可以看出,本文算法、DEABC-FCM及ACO-FCM都能将在Aggregation、R15、D31等3类数据集上将原始数据聚类成型,聚类结果较为准确,但DEABC-FCM及ACO-FCM在处理多类别数据集时聚类边界数据的归类处理上不够精确,比如图2(c)中D31数据集三角标记区域等,而本文算法计算数据集的密度程度,不仅实现了自动选取聚类中心和聚类数目,还利用蝙蝠算法的多次优化得到了更好的分类效果。为了直观地对比3种聚类算法的聚类效果,将3种聚类算法分别运行100次,统计3种算法实现聚类的平均迭代次数、平均使用时间以及平均差错率,详细情况如表4所示。 从表4的统计结果可以看出:本文聚类算法在3个数据集上的平均迭代次数比其它两种算法至少减少了12%,平均差错率比其它两种算法至少降低了26.8%,说明本文聚类算法能快速收敛,寻优聚类精度高;但本文算法耗时没有较大幅度的缩减, 单次算法运行时间较长,这与本聚类算法计算数据集的密度程度和Powell局部搜索有关。 分割有效性是评价聚类算法的重要指标[16~18],本文选取河流遥感图像为实验对象,将本文改进算法与文献[19](AC-FCM)、文献[7](DEABC-FCM)、文献[20](PSO-FCM)和文献[12](ACO-FCM)进行分割试验,对比分析各算法的聚类分割效果,同时在选取的河流遥感图像中人为添加不同等级乘性噪声模拟斑点噪声。利用分割准确率评价各聚类分割算法抗噪能力。对河流遥感图像分割结果如图3所示。 表4 3种聚类算法在数据集上的统计结果 图3 5种算法对河流遥感图像的分割结果 PSO-FCM分割算法和AC-FCM分割算法均能得到大致轮廓,但分割结果中含有噪点,小尺度结构区域识别质量低;ACO-FCM分割边缘模糊,纹理不够清晰;DEABC-FCM分割算法和本文算法都得到了较好的分割效果,边缘清晰,大尺度区域分割平滑,但DEABC-FCM分割中出现了噪点。用式(20)计算分割正确率η: (20) 式中:P为真实标准分割集合;Q为算法分割结果集合;card(·)表示集合中的元素。在河流图像中添加的噪声方差为0.05,0.1,0.15,0.2,0.25,0.3,0.35,0.4,0.45,结果如图4所示。 图4 5种算法对噪声河流遥感图像的分割结果 随着噪声的增强,5种算法的准确率都在下降,ACO-FCM分割算法的效果最差,准确率降低的幅度最大,说明算法敏感于噪声;本文算法的效果最好,随着加入图像噪声等级的不断增大,分割准确率下降的幅度较小,其次是DEABC-FCM分割算法;PSO-FCM和AC-FCM分割准确率下降趋势居中。 本文提出了一种基于改进蝙蝠优化自确定的模糊聚类C-均值算法,算法利用密度峰值综合衡量聚类中心外围数据密集程度和聚类中心间距离,解决了原始模糊聚类C-均值算法手动设定聚类数目的缺陷;在原始蝙蝠算法中引入Levy飞行特征提高蝙蝠算法局部寻优能力,利用Powell局部搜索提升蝙蝠算法收敛的速度,并将利用改进后的蝙蝠算法对数据集进行寻优。仿真结果表明:本文算法聚类精度高,收敛速度快,聚类分割抗噪能力较强。4 仿真实验与结果分析
4.1 对比分析寻优性

4.2 对比分析聚类效果

4.3 对比分析聚类分割效果



4 结 论
猜你喜欢
电子测试(2017年15期)2017-12-18 07:19:27
小溪流(画刊)(2016年12期)2017-02-04 18:34:54
高中生学习·高三版(2016年1期)2016-05-30 05:45:06
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01 03:46:20
智能系统学报(2015年4期)2015-12-27 09:38:39
微型小说选刊(2015年5期)2015-06-05 09:15:29
小星星·阅读100分(低年级)(2015年1期)2015-04-07 07:36:04
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01 02:54:01
电子设计工程(2015年6期)2015-02-27 12:04:53
数学年刊A辑(中文版)(2014年4期)2014-10-30 01:50:38
