
非可控环境行人再识别综述*
2020-05-27 12:22冯展祥朱荣王玉娟赖剑煌
中山大学学报(自然科学版)(中英文) 2020年3期
冯展祥 ,朱荣,王玉娟,赖剑煌
(1.中山大学数据科学与计算机学院,广东 广州 510006; 2.中山大学新华学院,广东 广州 510006)
行人再识别是对不同的、没有视野重叠覆盖的摄像机视域拍摄的行人目标进行身份匹配关联的技术。随着国内高清监控系统的普及,行人再识别在安防监控、疑犯追踪等领域发挥着越来越重要的作用。行人再识别是计算机视觉领域近年来非常热门的一个研究课题[1-3],也是最具有挑战性的研究问题之一。
自从2006年开始研究以来,在过去10多年,研究者们基于主流的机器学习和模式识别理论方法发展了许多行人再识别方法,可以分为手工设计描述子方法[4-6]、度量学习方法[7-10]和深度学习方法[11-14]共三类。2014年以来,随着深度学习理论的发展和应用的成熟,基于深度学习的行人再识别研究成为了当前行人再识别研究的主流,并取得了很大突破。深度孪生网络[15-16]、深度度量学习[17-18]、多尺度神经网络[19-20]、生成对抗网络[21-22]等基于深度学习的方法推动了行人再识别理论的发展和技术进步,显著提高了行人再识别算法的准确率,它们在主流行人再识别数据库譬如CUHK03[23]、Market-1501[24]和DukeMTMC[25]上均已超过了人类视觉的识别能力。尽管行人再识别研究已经取得了许多优秀的成果,但这些研究都是建立在理想的仿真条件下,与实际视频监控的应用条件有很大的差别。实际上,当前的行人再识别技术距离非可控环境的可行应用还有很长一段距离,实现实用化仍然有许多需要解决的技术难题。
1 非可控环境行人再识别挑战
具体地,非可控环境中行人再识别技术面临着以下挑战:
小样本:深度网络的性能取决于训练数据好坏,训练数据不足是限制当前行人再识别算法性能的一个重要因素。以Viper数据库[26]为例,该数据库规模较小,目前主流算法的识别率只有50%左右,而规模更大的Market-1501数据库上主流算法的识别率已经超过了90%。由于监控系统摄像头众多,监控范围大,实际应用中通过不同摄像头获取标签行人图像和对新应用场景进行重新标注的代价很大,很难获取大规模的标注训练数据。因此,小样本将是非可控环境行人再识别的一个主要挑战。在小样本行人再识别方面,所面临的问题如图1所示。其中,图1(a)表示带标签的少量训练样本,图1(b)表示大部分无标签训练样本。

图1 小样本行人再识别挑战Fig.1 Small-sample person re-identification challenge
可见光-红外匹配:当前大部分行人再识别的研究都是基于可见光行人图像进行的,提取的特征大多基于颜色信息,因此这些特征对光照变化的鲁棒性很差,导致识别算法在夜间条件下识别率下降非常大,难以满足全天候监控的需求。针对这个问题,可以通过红外摄像头在夜间提取稳定的行人图像,避免光照变化在成像上的不利影响。但是由于红外图像缺乏颜色信息,怎样实现准确的可见光-红外行人再识别是当前研究的一个难题。在可见光红外行人再识别方面,所面临的问题如图2所示。其中,第一排为可见光行人图像,第二排为红外行人图像,同一列的图像对应同一个行人。

图 2 可见光-红外行人再识别挑战Fig.2 Visible-infrared person re-identification challenge
遮挡:监控场景中,行人目标可能被场景中静态或者动态的其他行人、建筑物等障碍物所遮挡。尤其是在拥挤的场所,如机场、车站、商场、医院等,行人遮挡时有发生。在行人再识别任务中,遮挡不仅会导致部分目标信息的丢失,也导致提取的特征中带有遮挡信息的干扰,给后续的识别带来了不利的影响。在遮挡行人再识别方面,所面临的问题如图3所示。其中,第一排为完整的行人图像,第二排为受到遮挡的行人图像,同一列的图像对应同一个行人。

图3 遮挡行人再识别挑战Fig.3 Occluded person re-identification challenge
开集:由于监控目标的不确定性,行人再识别在应用中需要面临开集测试问题,即测试对象可能来自非目标库的问题。当前的行人再识别的研究大部分都是建立在测试目标来自目标库的假设,缺少有效排除非目标行人对象的手段。在开集行人再识别方面,所面临的问题如图4所示。图中,测试行人图像可能来自目标行人库以外,对识别结果造成很大的干扰。
针对上述挑战,近来研究者们已经进行了初步的探索和研究,并取得了一定的成果。本文将就这些研究做进一步的展开。
2 非可控环境行人再识别的进展
2.1 小样本行人再识别
当前主流的小样本行人再识别方法有两类,分别是基于生成对抗网络的方法和基于伪标签估计的方法。基于生成对抗网络的方法通过生成行人图像弥补训练数据的不足,随着生成对抗网络理论的进步,研究者可以生成带身份标签的行人图像,并通过监督学习的方法训练行人再识别模型。基于生成对抗网络的小样本行人再识别算法结构如图5所示,通常包含一个生成器和一个判别器,生成器用于生成符合目标域特性的行人图像,判别器则用于判别行人图像是真实图像还是生成图像,并通过生成对抗损失提高生成图像的可靠性,以及通过身份损失保证生成图像的身份不变。文献[21]最早尝试通过生成对抗网络产生新的行人图像进行数据增广,该方法用主流的生成对抗网络方法产生新的行人图像,对产生的行人数据进行标签平滑(label smooth)估计,并提出LSRO算法实现基于生成图像的模型训练,有效提高了行人再识别算法的性能。文献[22]通过循环生成对抗网络实现跨数据库行人图像风格迁移,通过源域标注数据产生符合目标域视域特性的带标签行人图像,克服了目标视域缺少标注样本的问题,提高了算法的泛化能力。文献[27]对跨数据库行人图像风格迁移的损失函数进行了深入的研究,除了通过循环损失(Cycle Loss)确保风格迁移以后的行人图像细节不变以外,还提出了一种生成目标图像和源域图像的域不相似性,确保生成的图像与目标域任意行人不相似。文献[28]提出一种基于姿态估计的非监督行人生成算法,学习行人图像的视觉信息特征和姿态特征编码器,对于任意图像,通过输入目标姿态的姿态特征向量,算法能在目标域产生不同姿态的行人图像进行学习。
另一方面,基于伪标签估计的方法通过聚类算法、相似度度量等方式增加标记训练样本的数量,从而提高非监督行人再识别算法的效果。一般地,研究者通过少量样本或者外部辅助数据库对无标签数据进行伪标签估计,并在伪标签估计的基础上进行判别度量学习。文献[29]提出了一种弱监督行人再识别框架,相比监督行人再识别,弱监督行人再识别只需要给出一个视频的行人标签,因此极大地降低了标注的工作量,在此基础上,文章提出了一种跨视角多示例多标签学习方法(Cross-view MIML),通过度量学习提高行人再识别模型的判别能力。文献[30]把行人图像分块的思想用到非监督学习问题上,提出了一种基于图像块特征提取的非监督行人再识别方法,通过设计的PatchNet结构筛选行人图像块,提取图像块特征,并利用图像块的相似性学习判别模型输出。文献[31]提出了一种跨摄像头相似度的一致性损失,通过学习同摄像头和跨摄像头的样本对相似度分布的一致性,减轻摄像头之间场景差异的影响,提高无监督域自适应行人再识别算法的性能。文献[32]提出了一种基于多软标签学习的小样本行人再识别算法,通过外部行人数据计算获得非监督行人数据的伪标签标注,并通过伪标签训练数据进行度量学习,提高行人再识别模型的判别能力。文献[33]提出了一种蒸馏的自学习方法,通过多教师知识蒸馏与摄像头相关的层次聚类进行自学习,增强模型从少量有标签数据中学习的泛化能力和减轻摄像头差异对聚类的影响,从而提高半监督行人再识别算法的性能。

图4 开集行人再识别挑战Fig.4 Open-set person re-identification challenge
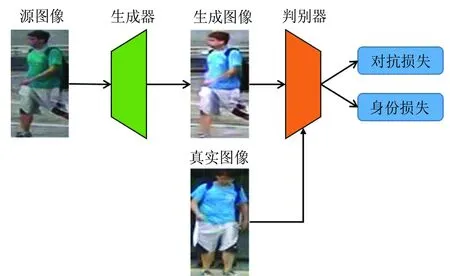
图5 基于生成对抗网络的小样本行人再识别算法结构Fig.5 Structure of small-sample person re-identification methods based on Generative Adversarial Networks
上述研究可以在一定程度上提高行人再识别算法的鲁棒性和泛化能力,但一方面通过生成对抗网络产生的行人图像的真实性和可靠性比较低,很难确保模型训练效果;另一方面,基于伪标签估计的方法很难保证伪标签估计的准确性,错误的标注数据可能导致算法的性能变差。因此,当前非监督行人再识别算法的效果有限,其识别性能还很难和有监督行人再识别算法相比。
2.2 可见光-红外行人再识别
目前的行人再识别算法对光照变化非常敏感,其性能受到光照条件好坏的影响。可见光-红外行人再识别技术能为克服行人光照变化问题提供可靠的技术支持,对全天候的监控系统至关重要。由于跨模态行人再识别任务带来了表观特征剧变、光照变化等问题,可见光-红外行人再识别是一个非常具备挑战性的研究问题。相关的研究表明[36],传统的行人再识别算法在处理可见光-红外行人再识别任务时性能将急剧下降。可见光-红外行人再识别研究仍处于探索的阶段,相关研究还不是很多。最早的可见光-红外行人再识别研究集中于可见光行人特征和红外行人特征的融合上[34-35],并且这种特征融合的目的是为了提高可见光域行人再识别算法的准确率。文献[34]提出了一种可见光图像特征、深度图像特征和红外图像特征等三种模态特征结合的行人再识别方法,通过多模板提取的互补信息进行组合,学习一个联合分类器。文献[35]构建了一个双摄像头系统,能同时采集可见光和红外行人图像,并采集了一个跨模态的数据库RegDB,通过深度网络学习多模态特征。需要指出的是,虽然RegDB数据库创建的初衷是用红外特征提升可见光行人再识别算法的性能,但后来被许多研究者用作衡量可见光-红外行人再识别算法的效果。
可见光-红外行人再识别的主要难点在于不同模态导致的行人图像表观差异较大,因此研究者把精力主要放在如何根据不同模态的特点提取行人特征以及如何减少不同模态之间的特征鸿沟上,主流算法结构如图6所示。真正意义上的可见光-红外行人再识别方法出现在2017年,文献[36]构建了一个大规模的可见光-红外行人再识别数据库SYSU-MM01,并在该数据库上对主流的行人再识别算法进行了评估。评估结果显示主流行人再识别算法在可见光-红外行人再识别问题上出现了明显的性能滑坡。除此之外,作者还提出了基于多模态输入结构的Deep Zero-padding算法,通过把不同模态的输入图像嵌入到模态特定的结构以实现模态融合,学习对不同模态的鲁棒特征。文献[37-38]采用双流网络处理可见光-红外行人再识别问题,提出了层次跨模态度量学习(HCML)和双向约束首位排序(BDTR)算法。HCML和BDTR方法首先在浅层网络采用不同的参数提取模态相关的底层特征,然后共享高层参数学习高层语义特征。其中,HCML[37]是一个独立的两步优化学习模型,首先提取外观特征,然后进行跨模态度量学习以降低类内距离,扩大类间距离;而BDTR[38]模型则采取端对端的网络结构,把特征提取和度量学习结合为一个整体的优化过程,并提出了双向约束首位排序算法以确保同类样本在识别中的排序,尽可能提高模型的判别能力。文献[14]提出了一种基于模态相关特征学习的可见光-红外行人再识别算法,通过构建模态相关网络、提取模态关联的低级特征,在深层共享网络参数、学习模态共享信息,并通过视角损失和度量损失提高特征的判别能力,显著地提高了可见光-红外行人再识别算法的识别准确率。文献[39]提出了一种跨模态生成对抗网络结构(cmGAN),把卷积神经网络作为特征生成器,判别器则将可见光特征和红外特征进行区分,结合分类损失和跨模态距离度量损失学习鲁棒的跨模态特征。文献[40]首次通过生成对抗网络产生可见光和红外行人图像,提出一种双向生成对抗网络方法,对可见光图像和红外图像产生多模态的图像组,从而减少可见光行人和红外行人的表观差异,实现特征对齐,并学习分类特征提取、判别行人信息。
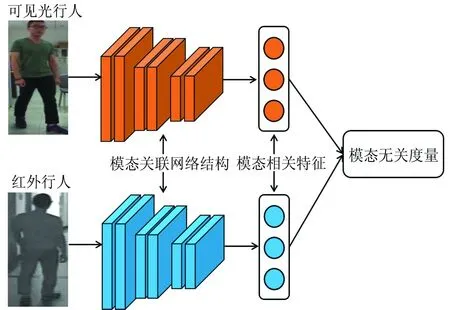
图6 可见光-红外行人再识别算法结构Fig.6 Structure of visible-infrared person re-identification methods
最新的可见光-红外行人再识别研究虽然能一定程度上提高再识别算法的识别准确率,但是由于不同模态行人图像的表观差异较大,其性能仍然难以让人满意。在两个主流的数据库SYSU-MM01和RegDB的实验结果显示,在测试库分别只有100类和200类的条件下,当前的主流算法识别准确率只有50%左右,距离传统行人再识别算法还有很大的差距。
2.3 遮挡行人再识别
外部遮挡会导致局部行人图像缺失,由于主流的行人特征提取过程是基于完整行人图像的,因此很难从遮挡图像提取鲁棒行人特征、进行特征对齐。因此,如何克服行人遮挡带来的影响,实现遮挡行人特征和一般行人特征的对齐,是遮挡行人再识别研究的关键。当前遮挡行人再识别研究主要有2种思路,一种是基于图像对齐的方法,另外一种是基于图像恢复的方法,这两种方法的结构如图7所示。基于图像对齐的方法通过手工标注、显著性检测等方法获取行人被遮挡区域,从完整的行人图像中计算与未被遮挡的行人部分最为匹配的区域,然后提取行人特征进行身份识别。基于图像恢复的方法则对遮挡区域进行处理和修复,用恢复后的图像进行特征提取和匹配。

图7 遮挡行人再识别算法结构Fig.7 Structure of occluded person re-identification methods
最早的遮挡行人再识别源于2015年,文献[41]构造了一个包含60个行人共600张图像的局部遮挡行人数据库Partial REID,并提出了局部稀疏表示匹配和全局空间互补匹配的模型,对人工裁剪去掉遮挡部分的局部图像与未遮挡图像进行匹配,采用局部分块联合高斯计算相似性得分以及整体滑窗计算相似性得分的方法,获得了优于用遮挡图像匹配的结果。遮挡行人数据库的出现极大推动了相关研究的发展,最近几年遮挡行人再识别领域的相关研究明显增多。文献[42]提出了深度空间重建模型,利用全卷积网络提取图像的深度空间特征,并将稀疏编码重建嵌入深度学习重建特征、计算损失,以找到与局部对应区域更加接近的特征,提高了匹配的可靠性。文献[43]提出了空间-通道对应网络,利用空间分块监督指导特征提取,利用每个通道对应关注图像中不同的空间部分,为整体全局特征提供应该重点关注的信息,以此解决遮挡行人再识别的匹配问题。文献[44]提出了一种基于集中学习与深度网络学习的遮挡行人再识别方法,通过遮挡模拟器从原始未遮挡训练样本生成多种类型遮挡训练样本,生成的遮挡训练样本与原始训练样本组成联合训练集用于模型的训练,同时添加遮挡与非遮挡分类损失到行人分类损失中去,有效地应对遮挡下行人再识别的问题,使得深度网络在学习特征时会考虑遮挡与非遮挡的先验信息进行特征的提取。文献[45]提出了可视性感知区域模型,学习不同区域的区域特征并通过自我监督学习了解区域的可见性、判断不同区域特征对匹配的重要性,以此学习局部图像和完整图像之间的共享区域特征,提高遮挡行人再识别算法效果。随着生成对抗网络算法的成熟,最近部分研究者通过生成对抗网络恢复被遮挡行人区域,取得了一些成果。文献[46]提出了一种基于生成对抗网络的视频遮挡行人再识别方法,通过相邻视频帧之间的行人图像进行关联,生成去遮挡后的恢复行人图像,避免了行人遮挡带来的局部区域缺失问题。文献[47]提出了一种基于遮挡定位与图像生成的算法,设计了一个带有去遮挡功能的网络框架来获取完整的行人信息,通过检测算法定位被遮挡的行人区域,并基于遮挡掩膜输出进行去遮挡行人图像生成,基于生成对抗网络获取了完整的行人图像,从而将遮挡行人再标识问题转化为完整的行人再识别问题进行识别。
综上所述,早期的方法提出了一种具体的解决思路,但由于模型学习能力有限,提取的特征判别能力不足;最近的方法大多采用局部特征和整体特征进行匹配,由于匹配的尺度不一致,还很难实现鲁棒的遮挡行人特征提取和匹配;基于生成对抗网络的遮挡图像恢复方法虽然能保证完整的行人匹配过程,但是技术还不成熟,恢复的行人图像区域真实性还很难保证,错误的图像生成可能导致错误的匹配结果。
2.4 开集行人再识别
当前的行人再识别算法在闭集测试中已经取得了比较高的识别精度,但是关于开集行人再识别的研究比较少。由于在监控环境中,行人对象身份不确定,很有可能出现来自目标库外的行人。当外部环境行人对象与目标库行人对象在表观上很相似时,当前算法很容易出现错误的识别结果,因此需要算法来排除相似的非目标行人图像。开集行人再识别的研究始于2012年,文献[48-49]提出了一个基于迁移排序学习的框架,通过学习大量开集样本的类内估计和类间估计,并把这种距离估计迁移到闭集训练库以提高行人再识别算法对开集问题的鲁棒性。文献[50]对不同摄像头仅包含部分重叠行人对象的开集问题展开了研究,并提出了一种基于在线条件随机场推断的开集行人再识别算法,以建立不同摄像机视角之间的关联。但,所提出的算法很难区分非常相似的外部目标。此后,部分研究人员希望通过建立开集行人再识别数据库推动相关研究的发展。文献[51]提出了一个基于无人机拍摄的移动端行人再识别数据库,并就开放环境和开集识别的问题展开了研究,测试了部分主流算法的效果。文献[52]构造了一个开集的行人数据库,但是在加入了错误接受率的约束条件下,当时的主流算法的识别准确率都非常低。需要指出的是,上述数据库的构建在学术界并没有引来很多的研究关注,基于这些开集行人再识别数据库进行研究的工作很少。文献[53]引入生成对抗网络方法进行开集行人再识别研究,通过生成网络产生在闭集目标和开集目标边界之间的样本进行训练,并通过判别器辨别真假行人图像、目标图像与非目标图像,通过零和博弈的方式提高神经网络在开集任务的鲁棒性。文献[54]提出了一种基于多教师自适应相似度蒸馏的行人再识别算法,从不同场景的教师网络中整合知识,使用目标域少量有标签数据自适应选择源域中的教师模型进行知识蒸馏,得到适用于目标域的轻量化模型,增强了行人再识别算法跨场景扩展的能力,得到对新场景和新数据鲁棒性高的行人再识别系统。
总体而言,目前开集行人再识别的研究比较少,而且比较零散、各自为战,没有形成系统的研究体系。与此同时,当前的开集行人再识别算法还很难排除表观相似的非目标行人图像。此外,目前还没有形成一个受到广泛认可的开集行人再识别数据库,因此很难评判不同算法的优劣。
3 非可控行人再识别研究主流数据库
为了研究非可控行人再识别,以及所面临的挑战中的小样本、可见光-红外匹配、遮挡和开集等问题,研究者公布了许多可用的数据库。本节将汇总并简单地介绍一些主流的数据库,关于非可控行人再识别研究的常用数据库如表1所示。
表1 非可控行人再识别研究主流数据库
Table 1 Datasets for unconstrained person re-identification researches

研究类型数据库名称发表时间行人类别数视角数量数据库规模小样本行人再识别VIPER200763221 264CUHK01201297123 884CUHK0320141 4671013 164Market-150120151 501632 217DukeMTMC20171 812836 441MSMT1720184 10115126 441PRID2011201193421 134i-LIDS20111192476MARS20161 26161 191 003可见光-红外行人再识别SYSU-MM0120174916303 420RegDB201741218 240遮挡行人再识别Partial REID201560-900Occluded REID2018200-2 000P-ETHZ20088513 897P-DukeMTMC20161 299824 143开集行人再识别SAIVT-SoftBio20121508-Flight20142814 096OPeRID201420067 413
首先,介绍小样本行人再识别领域的研究。这项研究的关键在于行人数据没有被标注,因此研究者只需把已有的监督行人数据库进行改造就可以得到小样本行人数据库。其中,VIPER、CUHK01[55]、CUHK03、Market-1501和DukeMTMC是比较常用于研究小样本问题的单张图像行人数据库;而PRID2011[56]、i-LIDS[57]和MARS[58]则是常用于研究小样本问题的视频行人数据库。小样本行人再识别的测试协议基本与传统行人再识别的测试协议一致,区别主要在于训练时使用的标签数据占所有训练数据的比例。
当前用于可见光-红外行人再识别研究的数据库主要有2个,分别是SYSU-MM01[33]和RegDB[35]数据库。其中,RedDB数据库是通过1个可见光-热红外双摄像头获取的,共包含412类行人目标,每人20张图像,10张是可见光图像,另外10张是红外图像,识别的挑战主要来自可见光和红外图像的模态差异。RegDB数据集的测试协议如下:随机采样一半类别的行人进行训练,用另外一半行人进行测试。测试时,采用可见光或红外其中一种模态的行人图像作为库图象(Gallery),另外一种模块作为测试图像(Probe),重复10遍测试计算CMC和mAP作为衡量算法优劣的评价指标。SYSU-MM01是一个大规模可见光-红外行人数据库,共有6个摄像头,获取了491类行人的超过30万张图像。需要注意的是,可见光图像和红外图像的比例有一定的失衡,红外图像只有15 792张。因此,使用该数据库进行测试除了需要处理模态差异和视角差异以外,还需要考虑训练时不同模态样本数量的平衡问题。SYSU-MM01数据库的测试协议如下:使用296类行人对象进行训练,99类行人对象进行验证,99类行人对象进行测试,测试过程分为室内搜索和全搜索两类,采用CMC和mAP作为衡量算法的指标。
为了研究遮挡行人再识别问题,研究者构建了Partial REID[41]和Occluded REID[44]数据库,这两个数据库都是用手机摄像头拍摄的。Partial REID包含60个行人目标的900张图像,每个行人有15张图像,其中5张是完整的全身图像,其余10张是局部图像或者遮挡图像。Occluded REID包含200个行人目标的2 000张图像,每个人有10张图像,其中5张是完整的图像,5张是遮挡图像。Partial REID和Occluded REID数据库采用同样的测试协议:随机采样一半类别的行人进行训练,使用另外一半行人进行测试,随机10遍计算CMC和mAP衡量算法效果。除了这两个专门用于行人遮挡的数据库,通过把DukeMTMC和ETHZ[59]数据库的遮挡行人图像挑选出来的方式,研究者建立了P-DukeMTMC和P-ETHZ进行遮挡行人再识别的研究。
在开集行人再识别研究的早期,部分研究者相继提出了用于开集问题的行人数据库,分别是SAIVT-SoftBio[60]、Flight[51]和OPeRID[52]数据库,并基于这些数据库进行了开集行人再识别的探索。受限于当时的技术水平,行人再识别算法在开集问题上的识别精度较低,并没有形成系统的方法体系。最近两年,开集行人再识别的研究热度有所上升,但是更多地是利用主流的行人数据库如Market-1501、DukeMTMC等,通过设置开集测试协议进行研究。
4 总结和展望
本文对行人再识别研究面临的挑战进行了分析,并阐述了小样本、可见光-红外匹配、遮挡、开集等行人再识别关键技术的发展现状、主流方法、使用的数据库和存在的问题。随着行人再识别技术的成熟,通用行人再识别研究会遇到瓶颈,识别能力很难获得较大的突破。另一方面,由于行人再识别数据标记难度很高,也很难借鉴人脸识别研究中通过大量标记数据提升泛化能力的方法。因此,可以预期在未来几年非可控行人再识别的研究热度会进一步提升。当前非可控行人再识别算法的识别性能距离通用行人再识别算法还有比较大的差距,这是因为非可控环境下行人图像的表观差异更大,识别难度更高;且非可控行人再识别的数据库规模较小,譬如遮挡行人再识别的主流数据库的规模都比较小,不利于获得鲁棒的算法模型。在对当前主流的非可控环境行人再识别算法进行归纳与分析之后,我们认为未来的研究可能有以下的趋势:
1)生成对抗网络将在非可控行人再识别研究中发挥越来越重要的作用:随着生成对抗网络技术的进步和成熟,生成的行人图像将越来越接近真实图像,可以用于补充训练样本、生成跨模态图像、恢复遮挡图像和生成相似的非目标图像,因此将在推动非可控行人再识别技术发展方面发挥重要的作用。
2)不确定性研究升温:当前基于贝叶斯估计理论的神经网络特征不确定性估计方法已经在人脸识别等任务中证明了其有效性,而非可控环境行人再识别的研究也有许多方面可以用得上不确定性估计,譬如对行人图像被遮挡的概率进行估计,对测试图像的特征进行置信度估计以避免开集目标的干扰等,因此可以预见基于不确定性的非可控行人再识别研究将有升温的趋势。
3)建立大规模的非可控行人再识别数据库:当前用于研究非可控行人再识别的数据库都比较小,不利于研究者进行深入的研究,因此建立大规模数据库势在必行。
4)集成多个非可控行人再识别问题的研究:当前关于非可控行人再识别的研究都是只关注其中某一方面,而忽视了算法的整体性。但是,在应用中往往是多个问题同时存在的,因此当非可控行人再识别研究进展到一定程度时,将出现同时对多个问题进行研究的课题。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
环球时报(2022-05-23)2022-05-23
昆明医科大学学报(2022年3期)2022-04-19
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
金桥(2021年4期)2021-05-21
意林(2021年5期)2021-04-18
电子制作(2019年7期)2019-04-25
电子制作(2019年7期)2019-04-25
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2017年6期)2017-06-07
