
自动化机器学习在地质灾害损失评价中的初步应用
2020-05-25 11:43曾群芳梁元易朝勇
写真地理 2020年3期
曾群芳 梁元 易朝勇


作者简介:曾群芳(1997年生-),女,硕士研究生,应用统计专业。
通讯作者:梁元(1976-),男,博士,研究生导师,主要从事数学地质和机器学习。
摘 要: 机器学习技术在很多领域得到广泛应用,然而,要得到良好的机器学习模型,必须要有高度专业化的数据科学家和领域专家参与,才有可能构建。自动化机器学习技术的出现,解决了领域专家能够在没有广泛的统计和机器学习知识的情况下,也能够自动构建机器学习的模型,大大方便了领域专家使用机器学习技术的能力。本文就是将自动化机器学习方法运用到地质灾害损失评价中,通过使用scikit-learn中的Grid Search来进行機器学习算法的超参数的最佳网格搜索,得到K-means算法的超参数最优配置,然后建立四川省各市州自然灾害区域评价的指标分类和评价指标体系,对地质灾害损失程度进行分类。该模型的建议,有助于机器学习、尤其是自动机器学习的推广应用,对研究地质灾害对人口、经济等方面造成的损失,探讨自动化机器学习技术在地质灾害损失程度具有一定的应用价值。
关键词: 地质灾害损失;自动化机器学习;自然灾害;K-均值聚类
【中图分类号】X43 【文献标识码】A 【文章编号】1674-3733(2020)03-0164-03
近年来,地质灾害频频发生,每年接近3万起的地质灾害,其中不乏有特大、重大型灾害[1]。人员伤亡每年达数千人,经济损失高达百亿元,不管是对人类还是社会经济发展都有巨大的危害和损失。目前对地质灾害损失的评价仅限于利用损失度量指标或模糊综合评价方法进行评价,地质灾害损失评价与机器学习算法结合起来的研究还相对较少。因此,将机器学习算法应用在地质灾害损失评价中具有重要意义,能够及时在地质灾害发生后第一时间确定灾害损失程度,及时调配救援资源。
本文首先介绍了K-means聚类算法的结构及其原理;接着介绍了AutoML中的Grid Search对K-means的超参数优化的问题;另外基于四川省各市州地质灾害隐患点的数据,采用K-means聚类算法并通过Grid Search确定最优的分类数,对地质灾害损失程度进行了分类;最终对分类的结果进行分析,给出相关建议或措施。
1 基于网格搜索的K-Means算法
1.1 K-Means算法基本原理。K-Means算法,又称K-均值聚类算法,使用欧几里得距离测度,分析人员将N个对象划分为K个不同类别,让每个类别对象的均值作为质心。然后,将前一步形成的聚类打散计算个体到质心的距离,并将第j个个体划入距离最近的聚类来形成新的聚类。持续该过程,直到每个类别的质心不再变化为止,此时的目标函数收敛到最优[2]。该算法最终目的是使聚类在相似的数据尽可能聚集在一起,不相似的数据尽可能分离。不妨假设给定样本集D={x1,x2,..,xm},K-Means(K-均值)算法针对聚类所得簇划分C={C1,C2,..,Ck}定义如下的目标函数:
L=∑ki=1∑x∈Ci|x-μi|2(其中μi为质心)(1)
K-means模型的目的是找寻最佳Ci,使损失函数最小,之后就可以对聚类中心{μi}直接计算了。由此可见,它既是聚类的最终结果,也是需要估算的模型参数。
1.2 K-Means算法框架
给定大小为n的样本集D={x1,x2,..,xm},将样本聚类成K个类别。具体实现过程如下[3]:
1)随机选取K个初试聚类中心μ1,μ2,..,μk∈Rn
2)重复以下步骤直至均值向量不再变化[4] {
第一步,计算样本xj(1SymbolcB@
jSymbolcB@
m)与各均值向量μi(1SymbolcB@
iSymbolcB@
k)的距离:dji=||xj-μi||2;第二步,根据距离最近的均值向量确定xj的簇标记:λj=argmini∈{1,2,..,k}dji;
第三步,将样本xj划入相应的簇:Cλj=Cλj∪{xj};
第四步,计算新均值向量:μ'i=1Ci∑x∈Cix;
第五步,判断新均值向量和当前均值向量是否一样,若不一样则继续更新均值向量。
1.3 网格搜索调参
自动化机器学习的任务是选择算法、超参调整、迭代建模以及模型评价。其中网格搜索(Grid Search),作为一种超参数调整的手段。其原理是在所有候选的参数选择中,通过循环遍历,尝试每一种可能参数,表现最好的参数就是最终的结果。在应用中,K-Means聚类算法能否实现或性能优劣取决于参数的选择,网格搜索取代原有的手动调参,自动实现在数组中寻找最大值,若参数a有3种可能,参数b有4种可能,把所有可能性列出来,可以表示成一个3*4的表格,其中每个cell就是一个网格,循环过程就像是在每个网格里遍历、搜索。通过网格搜索寻找最优参数可以高效实现搜索参数的流程,也减少了网络中的参数和运算次数,因此可以防止过拟合。
在K-Means聚类算法应用中,最终分类的簇数K是网格搜索需要优化的参数,K的选取直接会影响模型的性能。通过网格搜索找到合适的K使得目标函数(L=∑ki=1∑x∈Ci|x-μi|2(其中μi为质心))收敛到最小。随着K的增大,目标函数值会越来越小,而且也会下降得越来越慢,但在一般情况下,我们只用找到目标函数下降一定的稳定程度对应的K值就可以了。
2 地质灾害损失程度分类流程
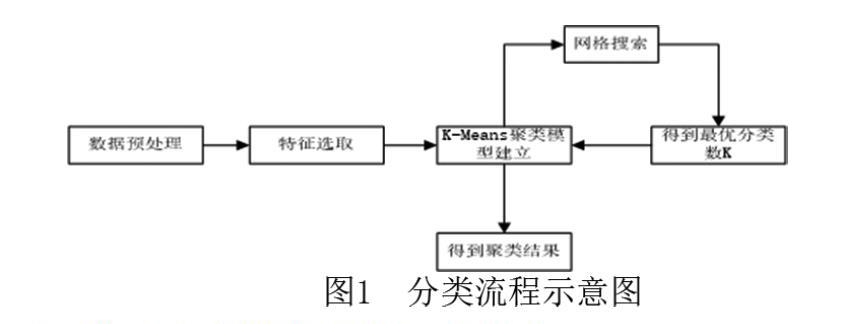
本文采用2010年四川省各市州地质灾害隐患点数据基于Python语言实现整个对地质灾害损失程度分类的流程。因此对数据预处理、模型建立、自动化调参这一流程进行说明,如图2所示:
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
数学小灵通·3-4年级(2021年5期)2021-07-16
今日农业(2019年15期)2019-01-03
电影(2018年8期)2018-09-21
高中生学习·高三版(2016年1期)2016-05-30
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
