
从混沌理念探究AWS数据“洞察”之道
2020-05-25 09:11韩丽佳
软件和集成电路 2020年4期
韩丽佳
杜甫有诗云“昔闻洞庭水”“乾坤日夜浮”,说那洞庭湖水乾坤日月都可包容映照,此种混沌宏大的意境之美在今天的AWS“数据湖”理念上也可窥知一二。
“在当今的企业里面,企业的信息和数据流,就是企业的血液。以数字化转型为例,我们要知道虽然数字化转型包含很多方面的内容,但其中很重要的一个内容就是企业的数据化资产。”AWS首席云计算企业战略顾问张侠一针见血地指出,“从数据到信息再到知识,进而产生洞察力,再指导我们行动,这是数据的意义所在。”
让数据产生其应有的洞察力,是大多数数据解决方案的目标。AWS数据湖方案由何产生?又是如何实现这一目标的?
应和了混沌哲学的数据湖理论
混沌的原意是指先于一切事物而存在的广袤虚无的空间。
我国著名物理学家、混沌学理论创始人之一、中科院院士郝柏林曾指出:“混沌研究的进展,无疑是非线性科学最重要的成就之一。它使复杂系统的理论开始建立在‘有限性这个更符合客观实现的基础之上。”并且,世界各民族几乎都有过从混沌创世到有序再回归到混沌的古老信念。
所以,是不是可以这样认为,我们所处的世界就是一个由无限数据组成的混沌体,其中蕴含的真理、信息包罗万象,我们的数据科学其实就是从这个物质世界混沌体中剥茧抽丝,从无序中寻找有序再回归到数字世界混沌无序的过程。
过去的数据仓库就像一个个分类整理好的仓储小格子,它是把原始数据分类、提炼、整理之后才进行存储的。这可以看做是对混沌数据进行有序的演化阶段。但是随着数据指数生长、数据来源更多、数据更加多元化、数据的使用者更多、数据分析工具更加多样,“有序的”数据仓库已经不能够满足需求。
“传统的方法,是从ERP、CRM、LOB、OLTP或者网站、移动端、传感器等产生的各种各样基层数据中整理成数据仓库,再形成商务智能。但这种方法会导致所谓的数据孤岛,无法满足数据的快速增长,也无法满足大数据数量多、速度快、类别杂、数据真、价值大五个方面的要求。”张侠说道。
混沌理论的基本观点认为:任何系统都有生有灭,有自己演化的起点和终点,并且系统演化的一般模式表现为从无序到有序、最后又回到无序之中。所以,数据湖便应运而生。
数据湖里存储的数据都是未经处理的原始数据,这些数据包括表格、文本、声音、图像等。在数据湖中可以进行数据的处理、分析、建模、加工,处理后的数据仍然可以留在湖中。根据数据湖理念形成的数据平台,相较于传统的数据仓库来说,显得有些“无序”,从无序的物理世界到“有序的”数据仓库,再到“无序的”数据湖,这恰符合混沌理论系统的演化规律。但我们不得不承认这样的数据存储集才具备庞大的数据存储规模、T级别的计算能力、满足多元化的数据信息交叉分析,以及大容量、高速度的数据管道。
2011年,數据湖概念就被福克斯的一篇文章所介绍了,它是针对数据仓库中的开发周期长、维护、开发成本高、丢失细节数据等不足进行的补充。“数据湖就是一个中心数据存储的容器,这个容器可以存储各种各样结构化和非结构化的数据,在数据量层面上,这些数据非常容易快速缩放,我们有各种方法对这些数据可以进行查询、分析。”张侠这样阐述道。
杜甫有诗云“昔闻洞庭水”“乾坤日夜浮”,说那洞庭湖水乾坤日月都可包容映照,此种混沌宏大的意境之美在今天的AWS“数据湖”理念上也可窥知一二。
AWS数据湖中的“混沌序”
数据湖中存储的数据既有结构化数据,也有非结构化数据,既有各种格式的原始数据,也有经过处理之后的数据,可以说是混沌的、无序的,是包容的。
虽说混沌现象表面是无序的,但混沌区的系统行为有严格秩序,存在精致有序的结构,正如AWS针对数据移动、存储、分析所做的产品服务一样,是混沌之下的有序。这种混沌既不是简单的无序,也不是通常意义下的有序,科学家建议将其称为“混沌序”。
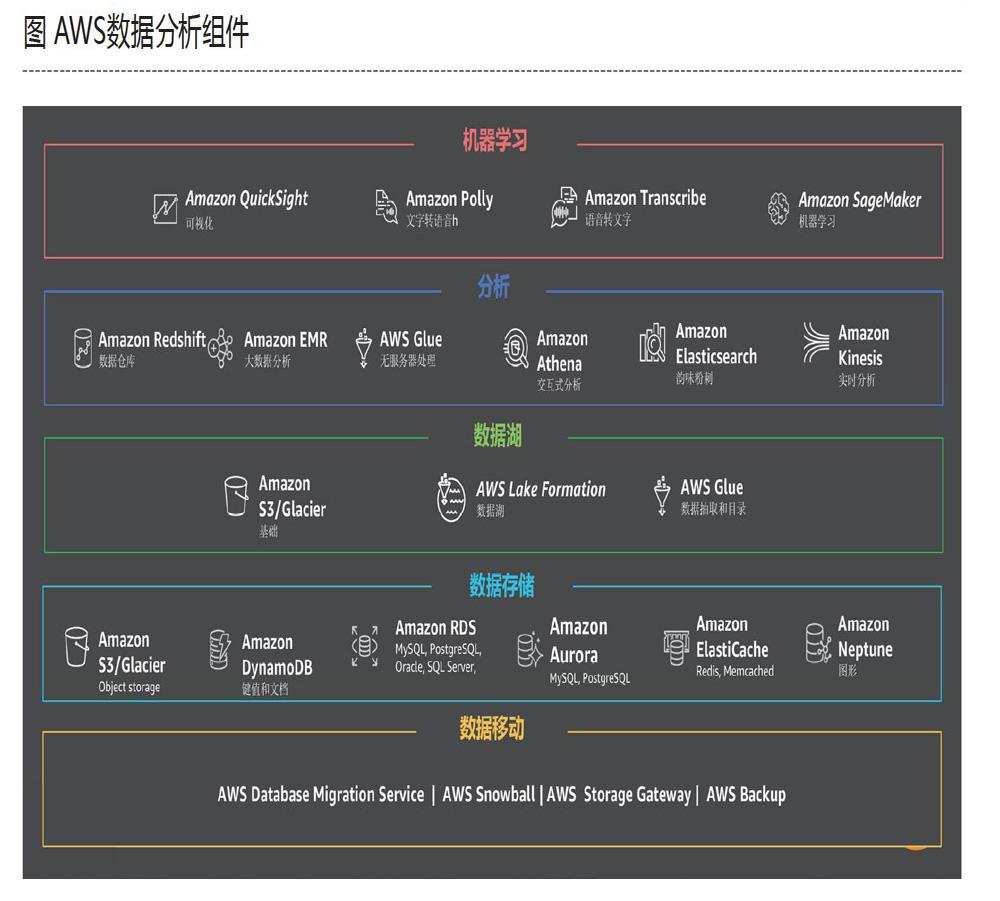
其中AWS数据湖平台主要有三大元素:一是Amazon S3/Glacier;二是AWS Glue;三是AWS Lake Formation。目前,AWS还没有在中国提供Lake Formation服务,但是可以预见这项服务将来肯定会在中国上线。
Amazon S3是AWS的一个最基础的云服务,可以存储以任何二进位为基础的任何信息,包含结构化和非结构化的数据,是容纳数据湖的理想场所。
“Glue是胶水的意思,代表的是不同的数据库服务之间的连接的作用。”张侠形象地引出了AWS Glue的两个主要功能。一是ETL,ETL指的是Extract、Transform和Load,意思是数据的抽取、转换和加载;二是数据目录服务的功能,在从客户选择的数据源中把数据爬取出来之后,会自动识别数据格式和模式(schema),构建统一的数据目录,并为客户提供所选数据的中央视图。这使得客户很容易跨越各种数据存储,检索和管理所有数据,而不必手动搬运它们。
关于AWS Glue的便捷程度,北京壳木软件有限责任公司(Camel Games)服务器主管张华表示:“AWS Glue帮助我们完成了复杂的ETL任务,可以从数百个Amazon RDS数据库中定时提取所需要的数据,供数据分析部门进行迅速而直观的全局统计,大大缩短了原本跨表查询的时间。”
AWS Lake Formation是一项全托管式服务,可以在几天内轻松建立安全的数据湖。只需定义数据源,制定要应用的数据访问和安全策略,Lake Formation就会从数据库和对象存储中收集并按目录分类数据,将数据移动到新的Amazon S3数据湖,使用机器学习算法清理和分类数据,并保护对敏感数据的访问权限。
AWS数据湖洞察力的实现
在上述数据湖三大元素的基础上,AWS部署了一系列的产品和服务,来实现数据仓库、大数据处理、交互查询、运营分析、数据交换、可视化、实时分析、推荐和预测分析等功能,以达到从数据到信息再到洞察再到行动的目标。
在AWS数据湖平台所包含的产品服务中有一个云的产品,叫Amazon Redshift,它是一个云的数据仓库,容量能够被缩放,成本也只有传统的数据库的1/10左右,让数据在云上就能够实现从数据库到数据仓库的迁移。
处理实时数据的服务叫做Amazon Kinesis,该服务能帮助客户捕获、处理、并存储视频流以作后续分析;搭建定制的应有分析流数据;将流数据导入AWS上的数据存储服务;使用SQL分析流数据。
特别值得一提的是,3月24日,AWS宣布Amazon Athena在由西云数据运营的AWS中国(宁夏回族自治区)区域正式上线。
Amazon Athena可以帮助客户使用标准SQL语言,轻松分析Amazon Simple Storage Service(Amazon S3)中的数据。由于Athena是一种无服务器服务,因此客户不需要管理基础设施,只需为他们消耗的资源付费。Athena可以自动扩展,并行执行查询,所以即便是大型数据集和复杂的查询,也能很快获得查询结果。
Amazon Athena在辅助数据传输行业领域的发展上表现亮眼。以茄子快传为例,这是一家全球化的互联网科技公司,它搭建了一个数字内容连接入口,帮助全球200多个国家和地区的用户获取优质数字内容。茄子快传数据运营负责人何诚表示:“茄子快传的数据量大,分析维度多,业务也非常复杂,所以经常需要多维度多颗粒度的高并发分析,AWS的分析工具很好地满足了我们日常的数据提取和分析需求。使用Amazon Athena,我们可以轻松地运行交互式查询,分析数据,不必构建和部署额外的集群。同时,我们运行新数据分析所需的时间缩短了30%,大幅减少了成本与运维方面的风险。”
还有许多数据分析产品服务无法一一介绍,但至此可以看出AWS已经形成了一套比较成熟完备的数据湖技术体系,在未来混沌的数字世界的图景上留下来浓墨重彩的一笔。
猜你喜欢
优雅(2022年1期)2022-01-19
电子乐园·下旬刊(2021年3期)2021-02-08
鸭绿江(2020年5期)2020-06-12
环球时报(2018-11-28)2018-11-28
科学大众·小诺贝尔(2018年7期)2018-10-26
学苑创造·C版(2018年12期)2018-03-04
少年博览·小学高年级(2016年11期)2016-12-01
国外科技新书评介(2016年8期)2016-11-16
中学生天地(B版)(2014年7期)2014-08-21
卷宗(2014年12期)2014-04-02
