
Proximity Based Automatic Data Annotation for Autonomous Driving
2020-05-22 02:55ChenSunJeanUwabezaVianneyYingLiLongChenLiLiFeiYueWangAmirKhajepourandDongpuCao
Chen Sun,, Jean M. Uwabeza Vianney, Ying Li, Long Chen,, Li Li,, Fei-Yue Wang,, Amir Khajepour, and Dongpu Cao,
Abstract— The recent development in autonomous driving involves high-level computer vision and detailed road scene understanding. Today, most autonomous vehicles employ expensive high quality sensor-set such as light detection and ranging (LIDAR) and HD maps with high level annotations. In this paper, we propose a scalable and affordable data collection and annotation framework, image-to-map annotation proximity (I2MAP), for affordance learning in autonomous driving applications. We provide a new driving dataset using our proposed framework for driving scene affordance learning by calibrating the data samples with available tags from online database such as open street map(OSM). Our benchmark consists of 40 000 images with more than 40 affordance labels under various day time and weather even with very challenging heavy snow. We implemented sample advanced driver-assistance systems (ADAS) functions by training our data with neural networks (NN) and cross-validate the results on benchmarks like KITTI and BDD100K, which indicate the effectiveness of our framework and training models.
I. Introduction
AUTONOMOUS driving became popular in the research field in recent years. The information technology and autonomous driving systems can in all be used to promote better commuting choices, provide best route planning, improve bus scheduling and routing and finally reduce travel time and traffic congestion. A safe and robust autonomous driving system could also greatly reduce traffic accidents caused by human drivers [1]. To design a safe and robust autonomous driving system, the ability to understand the driving environment as well as the current vehicle state is essential [2], [3]. The techniques used in environment perception varied from simple object marker detection by hand-crafted rules [4] to recent deep learning approach [5]. The final goal is primarily to have an affordable and robust system applicable under diverse environments.
One of the most frequently used autonomous driving framework among car companies is the modular pipeline approach where expensive LIDAR, high accurate global navigation satellite system (GNSS) and 3-D high definition maps are used to reconstruct the consistent world representation of the surrounding environments [6], [7]. The ego vehicle then takes all the information into account and make further control decisions. However, such a way of perception is costly and raises problems in both storage space and processing speed. Furthermore, as mentioned in [8], a human driver only needs relatively compact driving information to make driving and control decisions. Instead of reconstructing the three-dimensional high definition map with bounding boxes of other traffic participants, a compact set of driving affordance set, or even vehicle states [9], may be enough for control decisions. On the other hand, end-to-end learning [10] and direct perception [8] attempt to mapping directly from camera images to either control inputs or driving scene affordances. The end to end learning for autonomous driving enjoys cheap annotation of training data set; however,it is hard to interpret the control decisions. The direct perception approach proposed in [8] leverage interpret-ability by using compact annotations of driving scene affordances.Autonomous driving systems trained in both ways are highly dependent on the distribution and label accuracy of training data sets. The data collection and attributes annotation for neural network-based training methods raised several problems, e.g., how to collect driving data in a scalable way in a diverse environment, and how to ease the human annotation effort in training data affordance labelling.
An alternative to manual annotation is offered by modern computer graphic techniques which allow generating largescale synthetic data-sets with pixel-level ground truth.However, the creation of photo-realistic virtual worlds is timeconsuming and expensive. Games like TORCS, limited by its development, the image and video in the game is not photorealistic enough. Recently released open-sourced simulation platform CARLA [11] and AIRSIM [12] are built on unreal engine, which the image generated are more realistic and have the flexibility to define various kinds of weather and environment settings. Autoware [13] shares real public roads and region data in Japan for the software test of self-driving vehicles. However, the problem is that the simulator does not represent reality. It is more reasonable to collect and to label the driving data in a distributed approach. Xuet al.[14]published BDD100K data set where the diverse driving data is collected in a distributed way by Uber drivers across California and New York and annotated by human labour. The driving data are collected with a phone camera while the main effort of manual annotation task is not relieved. In [15], the authors deploy the APIs from open street map (OSM) [16] to tag images from google street view (GSV). It is indeed a clever implementation where the training samples are available online (no driver needed) and the labels are free to use from OSM. However, the major drawbacks of this scheme are 1) low diversity of the driving samples due to GSV are collected in sunny day time only; 2) low accuracy of the sample labels due to the calibration between GNSS and OSM and lack of label filtering.
This work provides the following contributions: 1) We present an affordable, scalable driving data collection and annotation scheme, image-to-map annotation proximity(I2MAP) with GNSS calibration and confidence score filtering for autonomous driving system, which provides diverse samples and boosted label accuracy; 2) We propose our driving scene understanding benchmark named Ontario driving dataset-affordances (ODD-A), which is composed of more than 40 000 samples with more than 40 labels under various weather, light-condition and road segments. We provide multiple labels for each image for driving scene understanding with the proposed I2MAP method. The effectiveness of calibration and confidence score filtering are examined with the label accuracy correlation of human-expert labelling; 3) We experiment on sample ADAS functions including traffic flow prediction, and multi-labelling affordance state observer is trained in a single multi-task learning network with our dataset and cross-validated on KITTI [6], BDD100K [17] benchmarks.
The rest of this paper is organized as follows: Section II discusses related work in driving benchmarks, driving-related affordance understanding and multi-task learning. We outline our I2MAP data collection and annotation framework in Section III, the detailed sensory fusion and proximity-based mapping algorithms are discussed. In Section IV, we demonstrate the ODD-A dataset for a typical multi-task learning setting. We demonstrate the network structure and experimental results with recent research works. Finally,conclusion and future work discussion are presented in Section V.
II. Related Works
A. Driving Benchmarks
In the pursuit of understanding driving scenes and driving autonomy, researchers have contributed massive effort to the publicly available benchmarks. Geigeret al.[6] present KITTI benchmark in 2012 containing both camera images and LIDAR sweeps. They focused on local driving scenes in Europe. The published benchmark is quite useful for modular pipeline approach of autonomous driving where typical vision tasks, including traffic agent detection, lane and road mark detection, are demonstrated. In 2016, the Cityscape benchmark [18] collected various urban driving scene across 50 cities for semantic segmentation tasks. Authors opensourced their benchmark for pedestrian, lane and road marking detection under various weather and day time in [19],[20]. However, accurate annotation is time and labourconsuming. Baidu proposed their annotation pipeline along with the Apolloscape [21] benchmark in 2018. At the same time, UC Berkeley released BDDV dataset [17], which provided a semantic evaluation benchmark containing largescale driving datasets distributed collected across four cities.The driving data quality, labelling accuracy is proportional to the human labelling power and sensor equipment costs in most cases.
B. Driving Affordance Understanding
In the autonomous driving setting, the authors in [8] first argue that traditional modular pipeline approach uses redundant information and making the driving task even harder. Typically, human drivers can estimate the affordances of the environment, including the road attributes and relative distances associated with related traffic participants instead of identifying the bounding boxes or segmentation for all instances, appeared in the image. Saueret al.[22] further examined the idea of direct perception by extending the driving scenario in urban driving using more photo-realistic simulation platform CARLA [11]. The images with the affordance attribute attached in both works are collected easily through the provided simulation API. However, affordance annotation is a challenging task in real driving environments since it requires a certain level of understanding of the current diving environment. To annotate the driving affordances such as heading angle, speed limit, road type as well as the distance to the intersection, the human labeller may have to label along the ride instead of following the annotation scheme mentioned above image by image. In 2016, Seffet al.[15] present the affordance learning methods by combining the GSV panoramas and OSM road attributes. They use cropped GSV panoramas to train a CNN model for a list of selected static road attributes. This method was further examined in [23] for various geographical locations. Ideally, we would able to use a compact set of affordances to represent the background and event of the driving scene with enough samples under the chosen driving scenario.
C. Multi-Task Learning
Multi-task learning (MTL) is a sub-branch of supervised learning, which can simultaneously solve multiple learning tasks and make use of the commonness and differences between tasks. The affordance learning task of understanding a provided driving scene is similar to visual question answering (VQA) task [24], where the model needs to extract the common features of the sample and be able to reason the commonsense of the scene representation. Compared with the training various NN models alone, the learning efficiency,model size and prediction accuracy of the specific task model can be improved by utilizing MTL. In the recent review [25],the advantage of MTL with the ability to learn internal representation which can improve the generalization ability of trained NN has been illustrated. The effect of MTL in the context of autonomous driving applications are demonstrated in [14], [22].
III. I 2MAP Framework
In this section, we introduce proposed I2MAP data collection and affordance annotation framework, as shown in Fig. 1. We use Honda Civic LX 2017 as our ego-vehicle for our later driving data collection. In the I2MAP set up, we include a front camera, IPhone and Panda (Gray version)OBDII Interface from comma.ai. All the sensory data are synchronized with coordinated universal time (UTC). Once the recordings are calibrated, we apply the extended Kalman filter (EKF) as sensory fusion method to raw GNSS signal, the phone sensor and CAN bus readings to obtain better positioning result. The estimated pose and UTC are then used as a query for online labels for the image tags. To reduce the auto-labelling error, we propose a confidence score based data filtering post-processing method, which is discussed in this section.
A. Sensor Setup
1) Vehicle Proprioceptive Sensors:Vehicles have many proprioceptive sensors such as steering angle, and throttle input accessible via vehicle CAN Bus. We can access the vehicle dynamics using Panda OBDII Interface and further decoded based on BDC file matching with our vehicle model.The Panda (Gray version) OBDII Interface also come up with a Tallysman GPS antenna as GNSS receiver, the raw GNSS signal can be retrieved in real-time. For our ODD-A data collection, messages of interest such as longitudinal acceleration and steering angle currently capture and save to a separate file at 1 Hz.
2) Phone Data Collector App:We mounted an iPhone on the dashboard of the ego-vehicle as a complement device for vehicle dynamics estimation. We built an App capable of logging the phone position and orientation estimates,accelerometer and gyroscope sensor readings in real-time.Notice that the accuracy of the IMU and magnetometer equipped on the iPhone is relatively low due to the cheap implementation. To compensate for the low accuracy problem, we implemented on-board automatic accelerometer and gyro calibration, where the iPhone is calibrated in an upward portrait plane position demonstrated in Fig. 2. In this regard, we only need to focus on bias estimation, and the accelerometer sensor scaling can be ignored. As a complement source of measurement of CAN bus, we can estimate the vehicle heading by logging the iPhone heading,which is determined using embedded magnetometer sensors.We need to calculate the bias for the calibration process;hence we drove slowly on flat ground for few minutes until the Phone’sx-axis pointing to the true north matching with the device attitude orientation. The biases are subtracted from corresponding measurements in real-time as the driver collects data.
3) Garmin Dash Camera:The Phone Data Collector App can capture driving videos similarly with [14] which using phone camera for recording. However, one drawback is that the horizontal view angle for the captured iPhone videos was only about 60° field of view (FOV). We use Garmin Dash Cam 45 with a 122° FOV to overcome the raw data quality issue in the distributed driving sampling applications in [14],[17]. This camera records videos at 30 fps with a frame resolution ofThe camera gives 3 channels(RGB) and has a night colour mode setting which helps capture relatively good images at night. Hence, the raw image quality is much better than the GSV samples used in [15] as well as the capability to capture more abundant driving scenes. Each frame of the dashcam recording is tagged with UTC, GPS position and movement speed.
B. Proximity Mapping
The main idea of proximity mapping is to overlay road feature attributes to recorded driving scenes. The OSM to image matching algorithm was first proposed in [15] and further examined in [23]. The contributed data in OSM is tied together using location information in a world geodetic coordinate system (WGS84). The tags for road attributes and visibility can then be queried from OSM and online weather API correspondingly. However, the major challenge of this type of proximity mapping-based data auto annotation is how to ensure label accuracy. The accuracy of feature association is directly affected by the location accuracy in both GSV and OSM and weather information in both sources was updated in the same time frame. As highlighted later, we found some mislabeled affordances due to unresolved location differences especially at bridges, intersections and close road networks where a small location deviation would associate features of one road to an image showing a different road.
1) Extended Kalman Filter:Extended Kalman filter (EKF)is an effective recursive filter to estimate the state of a nonlinear dynamic system, which has been applied to vehicle positioning with GPS and vehicle sensors in [26]–[28]. We use the kinematic bicycle model [29] given by the following:


Fig. 1. A framework demonstration of proposed I2MAP driving data collection and automatic annotation pipeline.

Fig. 2. The phone is mounted with its z-axis parallel to the vehicle’s x-axis,ego vehicle forwarding direction is the same as the –z direction in iPhone coordinate system. (a) IPhone coordinate reference system; (b) The phone and dash camera set up in the ego vehicle.


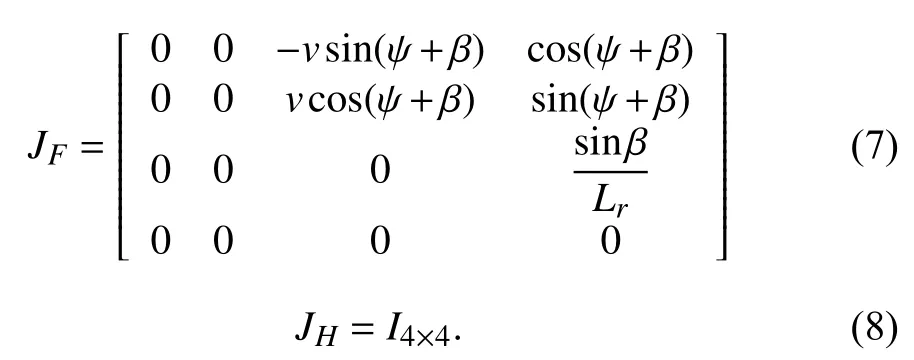
The process noise covariancePand measurement noise covarianceRare chosen based on experimental data

2) GNSS Preprocessing:With a minimum of four satellites,a good position for the GPS receiver is achieved by solving a 4-dimensional trilateration problem [30]. The primary source the GPS error is coming from user equivalent range errors(UERE) relate with the timing and path readings and dilution of precision (DoP) caused by the arrangement of satellites in the sky. The open-sourced Laika package in [31] provides useful sources to get the information about satellites and signal delays from the raw GNSS data. We can obtain the pseudorange delay from the summation of tropospheric delay,ionospheric delay, clock error and DCB corrections in the recording area [32]. The positioning accuracy is then improved by query the position of the nearby continuously operating reference station (CORS) through Laika [31] and make compensation by differential correction scheme with the known pseudorange delay.
Other than the UERE, we can also evaluate the DoP from the raw GNSS data to estimate the error propagation on positional measurement precision. If the elevations and azimuths of the satellites in view are simial, the DOP is high.Simultaneously, a high DoP means that small errors in UERE can cause significant errors in the computed position [33]. In our paper, we use DoP as one feature to specify the correctness of the processed GNSS position result.
C. Confidence Score Filtering
One major issue in autonomous labelling is the label accuracy and data quality. The annotated label needs to be as accurate as possible to avoid introducing bias to the subsequent usage on supervised learning. We have improved the GNSS positioning through proposed raw GNSS compensation and EKF filtering. Instead of the positioning accuracy, the final label accuracy is strongly correlated with the label confidence of the road segment structure complexity.For example, we demonstrate an branching intersection in Fig. 3(a), where at timevehicle is positioned with stateafter some time periodthe true state of the vehicle is portrait asand the estimated state is given asBased on proximity mapping, we find the nearest intersection distance from the corresponding ego-vehicle heading for the ground truth label mapping. Consider the case at timethe image sampled at the real vehicle state atis then tagged with the static road attributes annotated at nearby OSM position (OSM-P2).
Labels like number of lanes, road type, vehicle to road heading are likely to raise error in this case. The problem of intersection label accuracy is inherited from the lack of formal semantic definition of labels at the scenario transitions, which was elaborated in [34]. One popular strategy is to have multiple human labeller to evaluate the image labels and find the final consensus as to the image tag. However, using consensus label with even more human efforts is against the intention of reducing human labelling workload. Moreover,even by reaching a consensus tag, it remains vague and lack of formal definitions. We introduce the confidence score to measure the data label accuracy in the following three categories

D. Performance Evaluation
1) Position Accuracy:To prove the effectiveness of our algorithm, we compare our result with the raw signal positioning from Phone, DashCam, and Raw GNSS data.Since the ground truth position of the receiver is never known,it is hard to judge the filtering algorithms. However, with the same assumption in [31], we can estimate the altitude accuracy of a position by checking the variation of the estimated road height over a small batch. It is reasonable to assume that the vertical and horizontal accuracy is equally correlated for the computed position. Fig. 4 shows the altitude error distribution for position computed with Phone GPS,DashCam, Raw GNSS, EKF-fusion algorithm and the EKF with confidence score filtering algorithm. Overall the positioning error was reduced by 50%–60% using EKF with the following confidence score specification

Notice that the position error can be further reduced by providing more stringent criteriathe downside is that we have to filter out more data.
2) Label Accuracy:To compare the label accuracy, we generated a single set of human labels as ground truth by combining human annotators consensus following [35]. Each human volunteer was first shown fifty example data samples to help them understand the corresponding affordance definition. We choose four classification tasks: number of lanes, heading angle, road type and day or night. Notice that estimating the real heading angle as a regression task is tough for human annotators. We set a pseudo rule that we classify the calculated heading angle corresponding to three types: leftrightcenter (the rest of them). As evident in Fig. 5, the proposed I2MAP label accuracy boosted 8% on average by EKF fusion algorithm; the performance is further improved by confidence filtering with the specification (13)from 5% to 14%. We find that for the affordances have a strong correlation with pose estimation, such as number of lanes, heading angle and road type; the corresponding label accuracy can be greatly improved through our proposed algorithm. On the other hand, tags such as weather, visibility are not very sensitive to the road structure change, and localization error, hence the labelling quality of these affordances are naturally good enough.
IV. Benchmark Analysis and Experiments
A. Data Statistics
Our current dataset consists of about 40 000 images taken during three weeks of driving in Waterloo. In total more than 40 label classes are automatically annotated. The available tags and annotated attributes are shown in Table. I . We recorded the data in various driving scenarios across various road types, day time and night time.

Fig. 3. Label mapping error due to proximity and the proposed confidence score functions to filter the error. (a) An example scenario at branching intersection which induces the proximity-based label mapping error. The black dots are corresponding to the OSM reference location with road attributes annotation in the database; the green dots represent the ground truth state of the ego-vehicle; the red dot is the estimated state at time (b) A set of confidence score computation. Although they share the same x-axis, the meaning of the corresponding depends on the corresponding confidence score function.

Fig. 4. Estimated altitude error distributions comparison for the signal from five schemes. (a) Error distribution comparison between Phone (purple), Dash-Cam (green), and Raw GNSS (red); (b) Error distribution comparison between Raw GNSS (red), EKF-fusion (pink) and EKF with confidence score filtering with our specification (light-green).

Fig. 5. Label accuracy compared with human consensus on selected affordances.
The data balance of selected subset attributes is demonstrated in Fig. 6. Our data set contains 53% secondary roads which are the highest of all road types. The secondary roads mostly indicate a route with two lanes and traffic moving both ways. The recorded high percentage is a true reflection of most road networks that we collected data from.The smallest represented road types with 6% are the service roads which are used to provide access to business areas and public gathering places such as business parks and campsites.The detailed image tags, including the vehicle dynamics and the environmental labels, are listed in Table. I.
B. Affordance Observer Network
One application of our proposed dataset ODD-A is to solve the VQA problem as a multi-labelling problem. We use a single neural network demonstrated in Fig. 7 as a affordance observer. The task blocks corresponding to different sub-tasks on learning the affordances or even control outputs as an imitation learning structure. The network we use here in Fig. 7 can be extended with controller modules as [11], [22], [36].Here, we choose one example implementation on predicting two sets of tasks with the image inputs and the history logs of velocity and driver’s inputs. We use the ResNet50 [37] pretrained on ImageNet [38] as the encoder to extract features from raw input images. The features are extracted from the input sequence and stacked as one set offeature map. The encoded features from images concatenate withframe velocity and driver’s steer and throttle inputs forward pass to task block as an input. The task blocks are task-specific layer which is grouped as texture oriented task and geometric oriented task. A texture oriented task is aiming to focus more on the texture instead of geometric relationships in the image.For example, the features to identify weather condition orvisibility from a front view image are different from those for learning the cross-track error or lane structure. Different weighting combination should be learned corresponding to the extracted features from the auto-encoder. Notice that the two types of tasks can be treated as augmentation noise to each other during the training phase to improve the robustness of the neural network.

TABLE I Current Available Labels From the I2MAP Data Collection Scheme
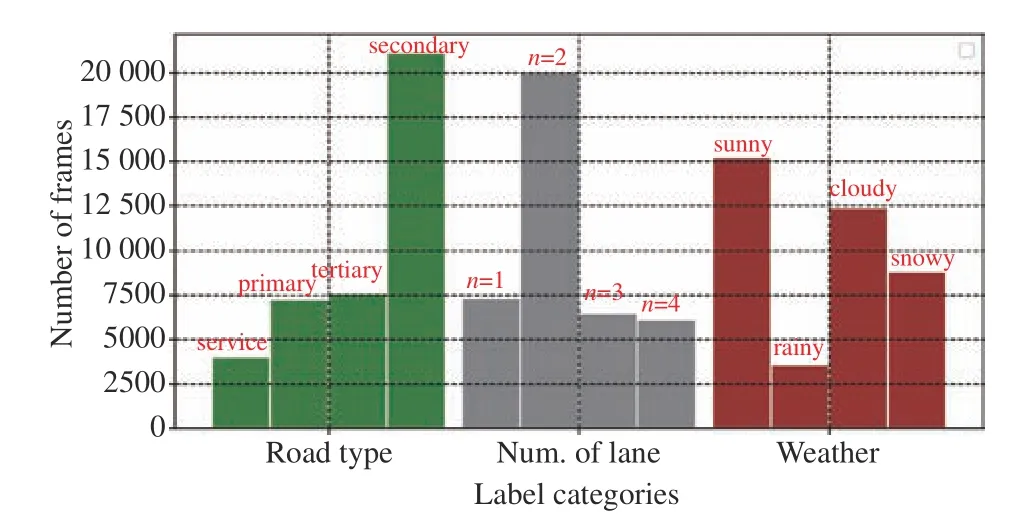
Fig. 6. The sampled driving data distribution over a set of road type, number of lanes and different weathers.

Fig. 7. Overview of the multi-task learning network. The auto-encoder extracts the features from the input image. We store the last N feature maps in memory where N is the length of the image sequence for the designed perception tasks. The N frames velocity and driver’s input are concatenated with the N feature maps from images branched to each task blocks. The defined affordances are predicted from each task blocks.
We choose the following seven affordances as the learning tasks, namely heading angle, intersection distance, number of lanes, intersection type, weather type, moving traffic and road type. The weather task block is a texture oriented block,whereas the rest of the tasks are focus on learning the embedded geometric relationships. We use the sixty per cent of the proposed ODD-A as the training set and the rest for validation and testing. The network is trained on mini-batches of size 32. We use the class-weighted categorical crossentropy loss for classification, where the weights are chosen based on the data balance in the training set. The mean average error is chosen for the regression task. The data augmentation set is different between the weather task and the rest geometric oriented task blocks. Notice that we have an experiment with FCNand LSTMsfor the task-specific layers.
We have evaluated the experimental results in Table. II with the cross-validation on KITTI [6] and BDD100K [17]. To synchronize the labels for comparison, we obtain the image tags for all testing datasets with the proposed I2MAP algorithm. We found that by employing a temporal task block,most of the prediction results improve, which demonstrates the additional temporal information could help to improve the classification and regression ability. However, the number of feature maps stack on memory could affect the prediction result as well. In our experiment, we sample the data in 1 fps,which could result in the additional temporal tracebecomes disturbances in the final network prediction. Almost all the data are collected in clear weather in KITTI [6], hence we list NA in Table. II . Notice that the proposed dataset ODD-A and BDD100K [17] are sampled similarly in terms of driving location (both in North America) and driving scenario(various lighting condition, urban). The ODD-A trained network to generalize well when validating on the BDD100K[17] data. Although a more diligent pre-processing needs to be done for improving the validation result on KITTI [6], we can demonstrate the applicability and effectiveness of the proposed ODD-A benchmark and the multi-task learning network structure as shown in Fig. 7.
C. Traffic Flow Prediction
We used the trained model to suggest actions of stop or drive given the driving scene as a sample ADAS function. By restricting the moving direction of the Moving Traffic task(must same as the ego-vehicle), as well as combining the historical driver's input and the vehicle speed, we can utilize the result from Moving Traffic as the driving aid function.Some of the driving scenes, along with the predicted actions,are presented in Fig. 8. We present scenes of snowy roads in both day and night time. The image on top row in Fig. 8,shows a road a snowy with unclear road geometry. Vehicles ahead of the ego vehicle appear far away. The image was correctly classified, and the model suggested that it is safe to drive. The top middle image in the same figure indicatessnowy road with a vehicle on the left lane but very close to ego vehicle. The model can recognize that such scene-setting suggest a safe to drive action. The top right image and the bottom center image in Fig. 8 indicates that the model does not just associate the green traffic light with clear to move action but also considers the actions and positions of other participants. It is also able to read the intention of the ego vehicle given its orientation on the road. The top right image clearly shows that the traffic lights are green and even another vehicle (white) shown in the scene continued to move straight.However, the model predicted that the ego vehicle intended to turn right and given that there are pedestrians, the prediction is a suggestion to stop action given the learned dynamic affordances. Similarly, the bottom centre image in Fig. 8 shows a scene with clear green lights. However, the model learned the difference in lighting between a moving and stopping vehicle (in road setting). Consequently, it was able to suggest that the correct action at that instance was to stop even though the lights were green — the bottom right image in Fig. 8 indicates a case where the traffic light is red but are obstructed by a large cargo vehicle moving in the adjacent traffic. This scenario represents an obstruction object that the model can recognize. Finally, the bottom left image in the same figure points out the difficulty of driving at night while raining. The traffic lights and of other participating vehicles might be exaggerated and misleading. However, the model can learn the most important traffic flow cues given the intent of the ego vehicle.

TABLE II The Performance of the Multi-Task Network. The Higher the Accuracy (ACC) and the Lower the Mean Average Error(MAE) the Better

Fig. 8. Our model prediction on traffic flow driving suggestion under visibility conditions.
V. Conclusion
In this work, we introduced a scalable driving data collection and automatic annotation framework driving by EKF proximity mapping and confidence score filtering. The collected data from distributed devices are synchronized and annotated with filtered labels for direct perception scheme.The proposed benchmark, ODD-A include vehicle dynamics and road attributes under various scenarios including day time and night time under various weather conditions (no rain, rain,snow). We train and evaluate the affordance observer as a multi-task learning network. One sample ADAS function on traffic flow prediction for harsh weather are evaluated and demonstrate its effectiveness with popular benchmarks. We concluded that the proposed data collection and annotation framework can be further employed in larger scale in order to enhance the trained model generalization ability. Exploring more advanced neural network structures and refining the static OSM labels with dynamic observations is currently under investigation.
 IEEE/CAA Journal of Automatica Sinica2020年2期
IEEE/CAA Journal of Automatica Sinica2020年2期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- Artificial Intelligence Applications in the Development of Autonomous Vehicles: A Survey
- Data-Driven Based Fault Prognosis for Industrial Systems: A Concise Overview
- Review of Antiswing Control of Shipboard Cranes
- Research Progress of Parallel Control and Management
- Influence of Data Clouds Fusion From 3D Real-Time Vision System on Robotic Group Dead Reckoning in Unknown Terrain
- Effect of a Traffic Speed Based Cruise Control on an Electric Vehicle’s Performance and an Energy Consumption Model of an Electric Vehicle