
一种改进的组合方法mBagging*
2020-05-21 05:36:38刘汉明刘赵发郑金萍胡声洲
赣南师范大学学报 2020年3期
刘汉明,刘赵发,郑金萍,胡声洲
(赣南师范大学 数学与计算机科学学院,江西 赣州 341000)
1 引言
有监督的机器学习目标是利用训练集学习一个稳定且在各个方面表现都较好的分类模型,但实际情况往往不理想,大多数时候我们得到的可能是有偏模型(弱监督模型).组合方法(Ensemble Learning,也译为“集成学习”)就是组合多个弱监督模型以期得到一个更好、更全面的强监督模型.其潜在的思想是利用多个弱分类器纠正某个弱分类器得到的错误预测,以达到减小方差(如Bagging[1])、偏差(如ADBOOST[2])或改进预测(如Stacking[3])的目的.Bagging(Bootstrap aggregating)是Leo Breiman于1996提出的一种机器学习算法,它在改善弱分类器的稳定性和精度上有着重要的价值.已被成功地应用于多种形式的随机森林[4-7]、体外药物敏感性预测[8]、生物标记选择与分类[9]及同种型概率估计[10]等研究.Bagging能够提高分类器的稳定性[1]并改善其统计功效[11],同时,它在含噪数据中,对模型的过拟合也不敏感[12].不过,Bagging的重抽样技术使得它通常要消耗比较多的算法时间,在大数据挖掘中表现不够理想.
Liu等在保持Bagging算法良好性能的前提下,对Bagging加以改进,提出了一种改进的Bagging组合方法mBagging(modified Bagging)[13-14],并利用最大信息系数(Maximal Information Coefficeint, MIC)[15]作为基分类器进行组合,应用于全基因组关联研究(Genome-wide Association Study, GWAS),取得了较好的效果.作者的仿真实验表明,mBagging的算法时间仅为Bagging的20%,统计功效提高了15%,同时假阳率也降为Bagging的69%[13-14].明显优于作为对比算法的PLINK[16]、BEAM[17]和BoNB[9].
2 mBagging原理
现有工作已经证明,组合分类器的预测能力通常比单个分类器好得多[11].mBagging是对Bagging的一种改进,其核心思想是,在对原训练集重抽样时,改变Bagging方法抽样后的训练集与测试集个数相同的做法,让抽样所得的袋内数据集(训练集)个数远小于袋外数据集(测试集).其算法思想可以简单地用下式表示[13-14]:
(1)
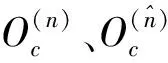
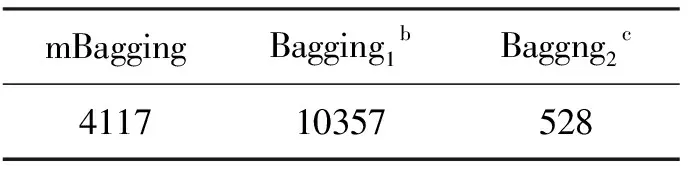
显然,若Bt=Bv,则式(1)表示了Bagging的算法复杂度.mBagging的改进之处就是令Bt 一般来说,组合方法通常采用“投票”法来生成x投至类j的权重Q(x,j),并使用该权重作为重要性度量以组合分类器[4].不过,“投票”法的分类错误率会随测试集个数的增加而增大[18].随机森林则采用“百分增量”的重要性度量以克服此不足.其做法是在测试集中加入“噪声”以测试重要性度量所表示的误分类率的变化[4].考虑到这种加入的“噪声”可能过强而影响算法的性能.mBagging定义了一种新的重要性度量[13-14] (2) 其中,x、xs分别是分类器所有可能的得分和测试集属性“替代”后的得分,x0则是“替代”前的得分.所谓“替代”就是把测试集中随机选取的第i个属性值用随机选取的第j(j≠i)个属性值替换. 我们以GWAS研究中SNP(Single Nucleotide Polymorphism)挖掘为例,利用PLINK工具集,采用参数OR(Odds Ratio)等于1.1~2.0(步长0.1)、MAF(Minor Allele Frequency)为 0.05~0.50(步长0.05)生成了500个独立的仿真数据集.每个数据集包含对照与病例实例各1 000和990个疾病无关SNP及10个疾病风险SNP. 皮尔逊相关系数(Pearson correlation coefficient, PCC)[19]广泛用于度量2个变量之间的相关程度,它由Karl Pearson从Francis Galton在19世纪80年代提出的一个相似却又稍有不同的设想演变而来.PCC具有简单、运算速度快的显著优点,但缺点也很明显——它只用于度量变量间的线性相关程度.由于GWAS的表型与SNP之间几乎不存在线性相关,PCC直接应用于GWAS研究中是一种弱分类器,所以,利用Bagging组合PCC是一个很好的选择.事实上,如果Bagging组合强分类器,则其性能不仅可能无法改善,反而可能退化[1, 11-12]. 使用mBagging组合PCC分类器,并采用上述参数,分析了500个仿真数据集,最后对“替代”结果作Wilcoxon检验得到P值,并对P值作Bonferroni校正.利用校正后的P值以0.05为阈值计算各方法的统计功效(Power)和假阳率(False Positive Rate, FPR).统计功效的计算结果如图1所示,mBagging、Bagging(抽样次数400)、Bagging(抽样次数20)的中位数分别是0.90、0.70、0.10.两种方法的FPR结果如图2,各方法对应的FPR中位数分别是0.010、0、0. 图1 mBagging与Baggging的统计功效 图2 mBagging与Baggging的假阳率(左侧是mBagging、中间和右侧的是Bagging) 实验硬件平台是Intel Core i3-4170 CPU(3.70 GHz)、4GB内存、集成显卡,软件平台Windows 7 x86(单线程).2种方法的运行时间见表1. 表1 算法的计算时间a(ms/数据集) a除数据文件读取时间外的总时间; b参数Bt=Bv=400的Bagging; c参数Bt=Bv=20的Bagging. 从图1可以看出,mBagging方法的统计功效明显优于两种不同抽样数的Bagging方法,高达0.9.但图2的FPR中位数显示mBagging弱于Bagging,与Liu等的实验结果不同,这是因为他们采用的是与本研究不同的基分类器,且通过实验找到mBagging和Bagging 2种方法的最佳抽样数后进行比较实验.不过,虽然我们的实验没使用最佳抽样数,但mBagging的FPR也仅仅0.01,说明它的优势还是比较明显.另外,表1显示mBagging方法的算法时间仅为采用参数Bt=Bv=400的Bagging的一半不到,说明Bt Bagging算法可以通过增加抽样数方法来提高基分类器的性能,但是,随着训练集的增加,过拟合的现象随之加重[20],特别是对于海量的大数据来说,这种情况更为突出[4].mBagging减少了训练集个数,从而降低了过拟合的风险;同时,它又增加了测试集个数,为提高训练后分类器的检验精度带来了可能. mBagging通过调整训练集与测试集的个数平衡了统计功效、FPR和算法时间,取得较好的效果,为组合方法应用于大数据挖掘提供了很好的借鉴.我们通过实验的方法验证了mBagging的可行性,但没有为mBagging和Bagging方法对PCC的组合寻找最佳抽样数,这是今后需要进一步完善之处.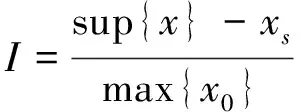
3 基于皮尔逊相关系数的mBagging实验
3.1 数据
3.2 皮尔逊相关系数
4 实验结果
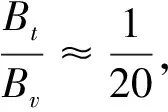
4.1 统计功效与假阳率

4.2 算法运行时间
5 讨论
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02小学生学习指导(低年级)(2021年9期)2021-10-14 07:57:00中学生数理化·七年级数学人教版(2019年10期)2019-11-25 07:34:00数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38小学生学习指导(低年级)(2019年9期)2019-09-25 07:43:28小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:46电子测试(2018年1期)2018-04-18 11:52:35光学精密工程(2016年4期)2016-11-07 09:05:00光学精密工程(2016年3期)2016-11-07 09:03:33
