
选择性集成迁移算法在轴承故障诊断领域的应用
2020-05-21 10:44刘冬冬李友荣徐增丙
机械设计与制造 2020年5期
刘冬冬,李友荣,徐增丙
(武汉科技大学冶金装备及控制教育部重点实验室,湖北 武汉 430081)
1 引言
轴承是机械传动系统中的重要支承部件,受恶劣工况影响,故障频发,严重影响了企业的生产运营[1-2],为保证设备正常运行,轴承的故障诊断至关重要。传统基于机器学习的故障诊断方法如Adaboost[3]、决策树[4]、最邻近结点算法(KNN,K-NearestNeighbor)[5]和支持向量机(SVM,SupportVectorMachine)[6-7]等机器学习方法进行诊断分析时,需面临两个问题:(1)测试与训练数据分布一致;(2)训练样本足够多[8]。但机械设备在实际工作过程中因工况复杂多变,导致产生的状态信息数据分布不一致,进而影响了诊断精度。
迁移学习是运用己存有(源域)知识对不同但相关领域(目标域)问题进行求解的一种机器学习方法,是一种可以有效解决传统机器学习以上两个问题的方法,目的是迁移已有的知识来解决目标域中仅有少量有标签样本数据甚至没有的学习问题。目前已在文档分类、情感分类、计算机视觉、网络搜索排序等领域有着广泛应用[9]。如文献[10]将基于最大间隔的核均值匹配的迁移学习算法应用于文档分类处理;文献[11]将迁移学习应用到语音情感识别,解决了跨库不易识别的难题;文献[12]提出了基于稀疏编码的迁移学习应用于行人检测;文献[13]将迁移学习引入搜索引擎,很好地解决了搜索结果返回排序难的问题等,但在机械设备故障诊断领域应用较少。
为此,将SelecTr迁移学习(Transfer Learning)[14-16]应用于轴承故障诊断中,利用SelecTr迁移方法迁移可用的样本数据应用于故障分类,从而解决因工况多变而产生数据分布特性不同,导致诊断精度低的问题。诊断流程,如图1所示。
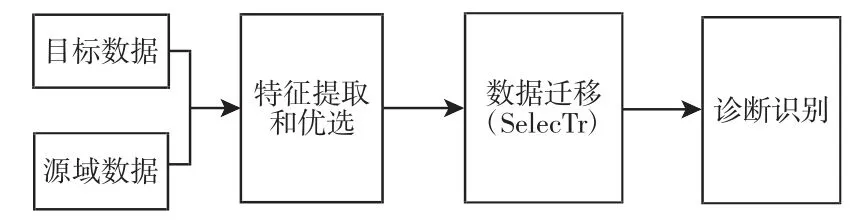
图1 诊断流程Fig.1 Diagnostic Process
2 迁移学习
2.1 迁移学习的原理和优势
传统机器学习对于不同的学习任务,每次都需分别进行学习,学习经验也不能相互借鉴,如图2(a)所示。而迁移学习中的样本迁移法则是从目标域中筛选、迁移出有效的数据样本迁移至源域,为分类模型提供尽可能多的训练样本,从而充分利用已有的知识,实现目标域知识的积累,原理如图2(b)所示。

图2 迁移学习和机器学习的原理Fig.2 The Principle of Transfer Learning and Machine Learning
2.2 SelectTr迁移学习方法
传统的迁移学习方法有Tradaboost[17]和Bagging[18],两者都是将目标域和源域混合组成训练数据,导致目标域训练数据很快地淹没在海量的源域数据中。而SelecTr算法将目标数据与所有源域数据视为具有同等权重,很好地解决了这一问题。为此,将SelecTr算法引入设备故障诊断之中,如图3所示。其具体算法如下:
输入:目标域数据M,和源域数据Y,其中M={(a1,x(a1)),(a2,x(a2)),…,(an,x(an))}和Y={(c1,x(c1)),(c2,x(c2)),…,(cm,x(cm)),且ai和ci是数据的特征矢量,x(a)和x(c)返回数据样本的标签,x(a),x(c)∈{1,2,3,4,5,6},且m>n。
(1)计算源域置信度,并剔除掉置信度后20%的样本。

本数据,S越大,表示源域和目标域样本数据相似度越高。
(2)对筛选后的源域进行N次随机采样,得到N个源域样本子集。
(3)将N个源域子集分别与目标训练数据混合,组成训练数据并得到N个SVM分类器。
(4)集成投票,票多者为最终的诊断结果。
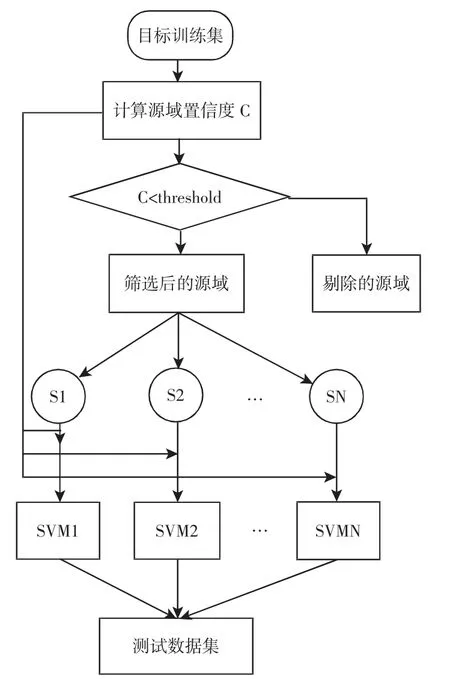
图3 SelecTr算法的流程图Fig.3 Flow Chart of SelecTr Algorithm
3 特征选择
特征参数是描述设备运行状态信息的重要参量。过多的特征参数因冗余或不相关性不仅增加计算时间,也会影响诊断精度。为提升设备故障诊断精度,提出了一种基于类内类间分散度的特征选取方法,具体算法如下:
(1)提取特征参数,描述如下。
Spi,fj,nk表示第i种故障下,第j类特征中第k个特征值。其中i=1,2,…,6,j=1,2,…,10,N=Σnk表示一种特征向量下,特征值的个数。
(2)计算类内中心,并按从小到大排序。

(3)计算重复度Cp,f。

(4)计算每个特征参数类内距离所占总类内距离的比例。
(a)计算类内距离dp,f

(b)所占比例η

(5)最终的影响因子γ。

(6)评价系数β。
γ越大,表明其对应的特征参数越敏感,将β设为评价阈值,大于β则其对应的特征参数视为敏感特征参数,小于β的则剔除。
4 诊断分析
4.1 实验数据
本次实验采用西储大学轴承数据,由图4的轴承测试系统测得。共5种故障状态数据分别是滚动体故障、内圈故障、外圈3点钟方向故障、外圈6点钟方向故障和外圈12点钟方向故障,最后还有一个正常状态数据。共有四种不同负载和转速的数据,分别是转速为1797r/min、1772r/min、1750r/min和1730r/min,实验采用转速相差最大的两种数据1797r/min和1730r/min,其中,1797r/min作为源域数据而1730r/min作为目标域数据。

图4 轴承测试系统Fig.4 The Bearing Test System
4.2 特征提取和优选
为了充分获取轴承状态信息,提取了标准差、峭度、整流平均值、波形因子、峰值因子、裕度因子、均方根、脉冲因子、峭度因子和最大奇异值等10种特征参数,且考虑到特征参数的冗余性或不相关性,利用提出的特征参数优选方法对其进行了优选,结果,如图5所示。其中评价系数β=0.75,从图中可以看出有4个特征参数是敏感特征。

图5 特征选择结果Fig.5 Feature Selection Results
4.3 诊断分析
4.3.1 源域数据样本不变,目标域数据样本增加
为了分析目标域数据样本量对迁移学习诊断精度的影响,对源域数据样本量不变的情况下,通过增加目标域数据样本量,对SelecTr迁移学习的诊断精度进行了分析,并且为了验证该方面的优越性,与SVM和Adaboost两种传统机器学习也进行了对比分析,诊断过程中源域数据样本为40,目标域数据样本分别为5、10、15、20、25、30、35、40、45和50,而测试样本为200,而诊断结果,如图6(a)、图6(b)所示。从图中可看出当目标数据增加到10个时,迁移学习的诊断精度有了大幅提升,且随着目标数据的不断加入,迁移学习的诊断精度不断增大,当样本为45时,精度高达99%。并且从图6(a)可看出,当传统机器学习在诊断过程中无源域数据样本,目标数据样本少于20个时,SVM的诊断精度高于Adaboost,而迁移学习的诊断精度又高SVM约14%,从而说明迁移学习在少样本情况下具有较强的诊断能力。而当传统机器学习在诊断过程中有源域数据样本时,从图6(b)可看出随着源域数据样本的增加,传统机器学习的诊断精度均有提升,但均低于迁移学习,且在目标数据少于20个样本之前,幅值低至45%,从而说明迁移学习在少样本条件下具有较好的诊断精度,且在数据样本分布不一致即工况多变的情况下比传统机器学习具有更强的诊断能力。

图6 改变目标数据下迁移学习和机器学习有无源域数据的对比Fig.6 The Comparison Between the Transfer Learning and Machine Learning with the Change of Target Data when the Source Data Exsit or Not
4.3.2 目标域数据样本不变,源域数据样本递增
为了分析源域数据样本量对迁移学习诊断精度的影响,在目标域域数据样本量不变的情况下,通过对源域数据样本量的增加,对SelecTr迁移学习的诊断精度进行了分析,分析过程中,目标域数据样本为10个,源域数据样本分别为20、30、40、50、60、70、80、90、100和110个样本,而测试数据样本为200,诊断结果,如图7所示。从图中可看出,当目标数据不变,随着源域数据的不断增加,迁移学习的诊断精度也随之增加,且当源域数据样本达到70后,诊断精度达到最大且呈现稳定。并且,从图7(a)可看出,当没有源域数据样本加入时,SVM和Adaboost两种机器学习诊断精度均保持不变,且均低于迁移学习15%;从图7(b)可看出,当源域数据样本达到30时,SVM和Adaboost两种机器学习分类能力达到最大值,而当源域数据样本继续增大时,两方法精度呈现下降趋势,且诊断精度均远低于迁移学习,从而说明源域数据样本增加会提升迁移学习的诊断精度,而源域数据样本对传统机器学习的诊断能力没有明显的促进作用,也进一步说明在工况多变情况下迁移学习具有与传统机器学习无法比拟的诊断能力。

图7 改变源域数据下迁移学习和机器学习有无源域对比Fig.7 The Comparison Between the Transfer Learning and Machine Learning with the Change of Source Data when the Source Data Exsit or Not
4.3.3 特征参数未优选条件下迁移学习诊断分析
为了进一步验证特征参数优选的优越性,结合未优选的特征参数利用SelecTr迁移学习和SVM和Adaboost三种方法对轴承故障分别进行了诊断分析结果,如图9所示。并且通过将图8(a)与图6(b)、图8(b)与图7(b)分别进行比较分析发现,进行特征参数优选后,迁移学习的诊断精度提升了40%以上,而SVM和Adaboost传统机器学习的诊断精度提升达55%以上,从而说明优选后的特征参数不仅有助于迁移学习而且也有助于传统机器学习方法诊断精度的提升,也进一步说明所提出的特征参数优选方法的有效性。

图8 没有特征选择的情况下迁移学习和机器学习的对比图Fig.8 A contrast Diagram of Transfer Learning and Machine Learning without Feature Selection
5 结论
通过将迁移学习应用于轴承故障诊断之中,从而解决了因工况多变导致传统机器学习方法诊断精度低的问题。(1)迁移学习通过对源域数据的筛选和迁移,获得更多目标域可用的分类数据,提升了传统机器学习方法的诊断精度。(2)提出的特征优选方法可有效剔除冗余或不相关特征参数,进一步提升了迁移学习和传统机器学习方法的诊断精度。
猜你喜欢
一重技术(2021年5期)2022-01-18
空间科学学报(2020年1期)2021-01-14
计算机技术与发展(2020年11期)2020-12-04
中国交通信息化(2019年12期)2019-08-13
电子制作(2018年10期)2018-08-04
制造技术与机床(2017年11期)2017-12-18
中国交通信息化(2017年8期)2017-06-06
青年文学家(2015年29期)2016-05-09
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28
振动、测试与诊断(2014年5期)2014-03-01
