
基于粒子群与知识图谱的突发水污染事件溯源方法
2020-05-21 13:46王新龙薛晓鹏孙如飞
水力发电 2020年2期
王新龙,薛晓鹏,孙如飞
(宁波市水利水电规划设计研究院有限公司,浙江 宁波 315000)
0 引 言
水是生命之源、生产之要、生态之基。近年来,我国水污染事件的发生时常见诸报端。如:2014年甘肃兰州自来水苯含量超标,2015年广东练江水污染,2016年安徽池州剧毒污水直排长江,2017年嘉陵江水污染等;接连的水污染事故让人触目惊心。但是一些企业为了自身利益,经常非法偷排污水,不仅严重污染水环境、造成重大经济损失;而且对居民饮水造成严重影响。水污染发现的位置通常不是污染源头,环境监管部门通常需要耗费大量人力、物力和时间,才能确定污染来源,往往已经耽误了水污染控制和治理的最佳时机;其次,即使定位到了污染源,对具体偷排企业的确定也是一个难题。如何在第一时间快速、精确实现污染物溯源、掌握污染源信息、确定偷排企业,最大程度地降低水污染造成的损失,对环境部门辅助决策、偷排企业追究问责,具有重要意义。
目前,国内外学者在水污染溯源方面的研究,可大致分为示踪实验法和数值模拟法两大类。示踪实验法主要包括同位素示踪法[1]、微生物示踪法[2]、水纹识别法[3- 4]、紫外光谱分析法[5]等,这类方法稳定性好,溯源结果精确度较高,但多是在水污染发生后对上游企业污水进行取样分析,工作量大且耗时长;数值模拟法主要包括确定性法和概率法[6]等。这类方法采用反问题思路,基于水污染发生后所检测的污染物信息对污染源相关参数进行反向推导,克服了示踪实验法工作量大、耗时长的问题;但目前数理问题反问题的计算相比正向计算,仍不成熟,计算复杂且计算量大,并容易受到初值和边界条件等因素的影响[7]。
本文针对示踪实验法和数值模拟法存在的不足,提出基于粒子群与知识图谱的突发水污染事件溯源方法。首先构建突发污染预案库,作为突发污染源的初步筛选依据;其次,采用粒子群算法对污染物扩散模型参数进行在线率定,并对初步筛选的污染源进行拟合分析,筛选出拟合度最高的污染源;最后,采用知识图谱法,将拟合度最高污染源附近一定范围内的企业污染物特征数据,与监测的污染物数据进行关联分析,确定排污企业,完成污染物溯源。

图1 突发水污染情景数据库
1 研究方法
1.1 突发水污染预案库构建
为了对突发水污染事件做出快速响应,有必要建立突发水污染预案库(见图1),主要包括:
(1)污染源数据库。污染源数据库主要包括研究区域历史污染源信息,包括污染源编号、污染源名称、污染源坐标、主要污染物、各污染物日常排放浓度、各污染物排放浓度比例、污染物上下游影响距离等。
(2)排污企业数据库。排污企业数据库对应于污染源数据库,包括对应污染源编号、企业法人、联系方式、行业类别、所在地区、附近河流等。
(3)监测断面数据库。监测断面数据库主要包括监测断面相关信息,包括断面编号、断面名称、断面坐标、监测要素、监测频次、监测数据等,为水污染扩散模型的参数率定提供支撑。
(4)水文情景数据库。水文情景数据库涵盖了研究区域河道水位、流量、流速的各种情景组合,为水污染情景方案提供边界条件。
(5)水污染扩散模型库。水污染扩散模型库主要包括模型构建的基本参数、边界条件等。
(6)突发水污染情景数据库。突发水污染情景数据库为各情景组合下的突发水污染方案库,模拟各污染源不同排放浓度与不同水文条件组合下的监测断面污染物浓度变化过程。主要包括污染源坐标、污染物名称、污染物浓度、水文边界、模型参数、监测断面污染物浓度等。
1.2 污染物扩散模型
本文以河流突发水污染事件为研究对象。由于污染物在河流中的扩散会受到河流两岸的影响,污染物在水流中的扩散收到边界限制并产生反射[8];因此,需建立二维污染物扩散模型来模拟污染物在河流中的扩散过程
(1)
式中,C为预测点在t时刻点(x,y)处的污染物浓度,g/L;x(m)、y(m)为以污染物泄露点位坐标原点的坐标位置;t(s)为污染物排放时刻到当前时刻的时间长度;k(s-1)为污染物的降解系数;ux、uy分别为河流的纵向、横向水流平均速度,m/s;Dx、Dy分别为污染物在水体中的纵向、横向扩散系数,m2/s。
若污染源的排放形式为瞬时岸边排放模式,则污染物浓度
(2)
式中,M为污染物排放总量,g;h为河流深度,mm;x、y分别为预测点距离排放点的纵向及横向距离[9],m。
1.3 基于粒子群算法的水动力水质耦合模型参数在线率定
模型参数的率定是模型应用的前提条件。当前模型参数率定大多采用离线率定方法,率定的参数不会随水文、水动力等条件的变化而改变。当发生突发水污染事件时,模型参数往往不适用;尤其是河流出现新的污染物时,还需进行现场实验来重新率定参数,耽误了大量时间。因此,需要对水污染扩散模型参数进行实时在线率定。
优化算法是模型参数率定的一种常用方法,其中粒子群算法相比于其他优化算法,具有快速、简单、容易实现的特点[10]。基于粒子群算法的水动力水质耦合模型参数在线率定步骤如下。
(1)参数敏感性分析。分析污染物扩散模型参数的敏感性,确定需要率定的参数和不需要率定的参数。
(2)参数初值设置。根据上下游监测断面的污染物类型与浓度,以及实时的河流水文、水动力特征,从突发污染预案库中筛选一个和当前污染情况相似的事件,将该事件的模型参数作为参数率定的初值。相似污染事件的筛选采用先验知识和模糊逻辑法,本文不做详述。
(3)模拟污染源构建。现实场景种,一般很难获取一场真实的水污染事件污染物浓度变化的全部过程,因此需要构建模拟污染源,以支撑模型参数率定与验证。模拟污染源的构建可将上游监测断面一定时间内污染物的浓度变化过程,等效为一定总量的污染物瞬时排放,从而替代真实污染源支撑模型预测下游断面污染物浓度的变化过程。通过对比下游断面污染物浓度的实测数据与预测的污染物浓度变化过程,对模型参数实时动态校正。
(4)参数在线率定。采用粒子群算法,基于模型参数初值、模拟污染源(上游监测断面)污染物浓度变化过程、实测污染物浓度变化过程(下游监测断面)等信息对参数在合理取值范围内进行在线优化率定,主要包括以下6个步骤:①初始化粒子群。设置各粒子的初始速度、初始位置、个体极值。②计算粒子适应度。计算各例子的目标函数值,即当前参数情景下,下断面预测的污染物浓度序列与实测值序列的偏差总和,偏差总和越小代表适应度越高。目标函数表达式为

(3)

1.4 基于水污染扩散模型的污染物溯源
(1)污染源初筛。突发污染预案库涵盖了各种污染物的相关信息,当发生突发水污染事件时,根据监测断面污染物类型,从预案库中查询该污染物可能对应的污染源(即疑似污染源)以及相应污染源的信息,包括污染源名称、坐标等。疑似污染源记为x1,x2,…,xi(i=1,2,…,n)。

1.5 基于知识图谱的排污企业确定
上述溯源得到的污染源,只能确定污染源的排放位置、排放时间和排放浓度。如果该污染源位于某工业园区的河道内,且该污染源附近企业排放污染物的类型大致相同,当某一企业偷排污染物时,则很难确定偷排企业。因此,还要将溯源得到的污染源与其周围企业排放的污染物(如各污染物浓度比例等)进行深入分析,才能最终确定偷排企业。
(1)知识图谱概念。知识图谱(Knowledge Graph)又称为科学知识图谱,由Google公司在2012年提出,是人工智能技术的组成部分。其强大的语义处理和互联组织能力,为智能化信息应用提供了基础。随着人工智能的技术发展和应用,知识图谱逐渐成为关键技术之一,现已被广泛应用于智能搜索、智能问答、个性化推荐、内容分发等领域。基于以上特点,本文采用知识图谱对溯源得到的污染源与其周围企业排放的污染物进行智能分析,确定偷排企业。
(2)知识图谱架构。知识图谱的架构包括自身的逻辑结构以及构建知识图谱所采用的体系架构。①逻辑结构:逻辑架构可分为数据层和模式层两个层次,数据层主要是由一系列的事实组成,而知识将以事实为单位进行存储。模式层构建在数据层之上,是知识图谱的核心,通常采用本体库来管理知识图谱的模式层。本体是结构化知识库的概念模板,通过本体库而形成的知识库不仅层次结构较强,并且冗余程度较小。②体系架构:体系架构是指知识图谱的构建结构,如图2所示。其中虚线框内的部分为知识图谱的构建过程,也包含知识图谱的更新过程。若通过知识图谱仍无法分析确定,则需要去疑似企业实地调查走访最终确认。

图2 知识图谱体系架构

表1 实验河段水文要素
2 案例应用
由于现实实际不可能将大量污染物故意倾倒进入河道进行实验,因此,基于现实条件与实验的人力、物力和环境,选取宁波市某水文条件比较稳定的入甬江河段、以少量污染物进行溯源实验。这样,实验中的少量污染物可快速排入甬江,进而排入外海,不会对生态环境造成影响。该河段的水文要素见表1。
根据实验河段水文要素,通过埃尔德法和泰勒经验公式,可计算得出本次实验的初始污染物纵向扩散系数Dx=2.94 m2/s和横向扩散系数Dy=0.016 m2/s。
模拟岸边瞬时排放污染物的溯源实验(见图3):

图3 污染物溯源实验示意
2.1 构建突发水污染预案库
在河段上游两岸虚拟不同的污染企业,根据各企业的不同污染物类型、河段水文要素等信息,构建突发水污染预案库,包括污染源数据库、排污企业数据库、监测断面数据库、水文情景数据库等。部分数据库表结构信息见表2、3。
2.2 污染物排放与监测
(1)在河段起始断面处A1以瞬时投放的形式向河段内投入污染物M,质量为20 g,并将A1标记为位置原点,投放时刻记为零时刻。
(2)通过水质自动监测仪,每隔30 s,在表4所示3个断面处(A2、A3、A4)测定污染物M的浓度,持续测量8 min。其中,A2为虚拟的污染源,A3用于在线率定污染物扩散模型参数,A4用于污染物溯源。通过水质自动监测仪的通信模块,自动将数据发送到网络,同时运用通信解析协议,解析得到污染物浓度变化过程,存入水污染扩散模型库。污染物浓度数据传输、解析、存库的过程涉及水利物联通信,本文不做详述。
2.3 模型参数在线率定
Dx、Dy的初值已经根据经验公式计算得到;纵向平均流速ux与横向平均流速uy通过流速仪测得,分别为0.16 m/s和0.02 m/s;通过查询文献,污染物的降解系数初值k=0.1 d-1。
测得A2、A3、A4的污染物浓度变化见图4。
由于模型中待率定的ux、uy、k初始值可依据河段水文要素及文献计算得到,若由于实际条件限制

表2 污染源信息

表3 排污企业信息
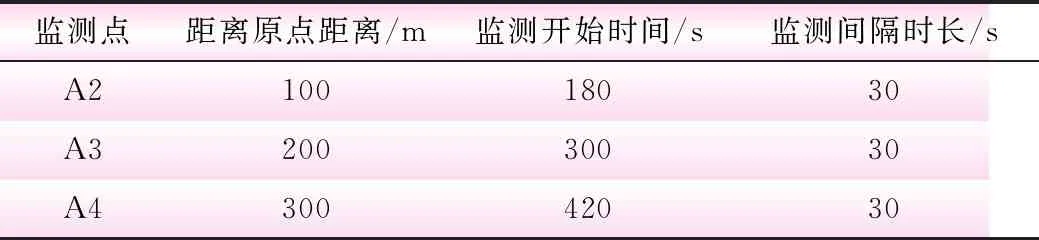
表4 监测点及监测信息

表5 模型参数率定信息

图4 A2、A3、A4污染物浓度变化
无法获取其初始值,可从突发水污染预案库中选取跟当前场景相似的历史事件作为初始值。各参数见表5。
利用A2为虚拟污染源,利用A3污染物浓度变化过程,基于粒子群法对ux、uy、k进行率定,率定结果见图5。
经率定,Dx均值为0.941 m2/s,Dy均值为0.116 m2/s,k均值为0.085 d-1。
2.4 水污染溯源
(1)根据监测断面A4的污染物类型,从预案库中查询疑似污染源。经过筛选,初步确认5处污染源x1、x2、x3、x4、x5。
(2)通过试算法,基于率定过的水污染扩散模型,分别对5处污染源进行模拟计算,并与A4的实测污染物浓度变化过程进行拟合度分析。经计算,5处污染源拟合度分别为0.96、0.73、0.84、0.69、0.89;因此,确定x1为污染源。
2.5 确认排污企业
根据监测断面A4的污染物类型、排放浓度、污染物浓度衰减、排放时间等信息,通过知识图谱与污染源周边企业进行关联分析,确定排污企业E。
3 结论与展望
本文针对现有水污染溯源方法

图5 ux、uy、k迭代计算过程
的不足,提出了一种河流突发水污染事件的溯源方法框架与步骤,并通过实验进行了模拟验证。通过构建突发污染预案库,从而大大缩短了污染物溯源时间;通过粒子群算法,对污染物扩散模型进行实时在线率定,使模型参数能够随时应对水污染事件;采用污染物扩散模型的正向计算,有效克服了反问题计算复杂的缺陷;通过知识图谱的智能关联,确定排污企业,完成水污染的精确溯源,大大提高了水污染溯源的效率。
本文只对岸边瞬时排放的水污染事件进行了实验,下一步需对连续排放的水污染事件进行实验,以验证本方法的适用性与准确性;同时,还需对实际发生的突发水污染事件进行溯源模拟,以验证本方法在现实条件下的适应性。
猜你喜欢
军事文摘(2022年24期)2022-12-30
北京航空航天大学学报(2022年8期)2022-08-31
轮胎工业(2021年5期)2021-12-26
新疆钢铁(2021年1期)2021-10-14
少先队活动(2020年12期)2021-01-14
西部交通科技(2021年9期)2021-01-11
云南档案(2020年4期)2020-12-06
环境(2019年4期)2019-04-20
电子制作(2018年12期)2018-08-01
领导科学论坛(2016年9期)2016-06-05
