
基于改进VGG16的猴子图像分类方法
2020-05-20 01:35田佳鹭邓立国
网络安全与数据管理 2020年5期
田佳鹭,邓立国
(沈阳师范大学 数学与系统科学学院,辽宁 沈阳 110034)
0 引言
随着深度学习技术的不断进步,对于通用对象的类别分析,卷积神经网络已经达到了很高的水平,但对于细粒度图像分类的稳定性目前还有待提升。所谓细粒度图像分类,通常用于描述对同一类事物进行细致的划分,所以待分类图像的区别要更加精准,类内区别大而类间区别小,粒度则更为精细。本文方法基于改进的VGG16深度卷积神经网络。尽管原始的VGG16模型已经拥有了良好的普适性和实用价值,并且在各种图像分类和目标检测任务中都体现了极佳的效果,通过迁移学习改进的VGG16模型,能够将已习得的特征和性能应用到待解决的问题中,极大地节省了训练时间。此外在硬件上选取GPU进行训练,使得速度得到进一步提升。为了改善原始的交叉熵损失函数无法保证提取的特征具有识别度的缺点,在VGG16模型中引入将center loss损失函数与交叉熵损失函数相结合的办法。此外还运用了新型的Swish激活函数,以及拥有自适应学习率的Adam优化器。最后利用不同种类的猴子训练集对改进的模型重新训练,以获得少量微调的参数信息。经验证该方法对猴子图像识别的精准度可提升到98.875%,而原始的VGG16模型在该数据集上的分类仅能达到90.210%的准确率,可以证明改进后的模型具有更好的识别效果。
1 VGG16模型及迁移学习
1.1 VGG16模型
VGG卷积神经网络的层次结构包括卷积层、激活层、池化层和全连接层,其中卷积层起到十分重要的作用,通过实现“局部感知”和“参数共享”的两种方式,达到了降维处理和提取特征的目的[1]。卷积核是卷积层的核心,在卷积核的作用下可以提取位于图像中不同位置同一物体的形状,在起到降维作用的同时也减少了需要训练的参数[2]。
池化层pool中用池化过滤器对输入数据进行降维[3]。最后是全连接层,它的作用相当于“分类器”,由于此次待分类的数据与原先VGG16的分类数据不同,因此将全连接层的参数抹去,通过重新训练确定最后三层全连接层的参数信息,来实现分类目标[4]。
VGG16卷积神经网络模型由13层卷积层和3层全连接层组成。该模型要求输入的图片数据大小为224×224×3,初始卷积核的大小为3×3×3,步幅stride的大小为1,有效填充padding的大小为1,池化层pooling采用2×2的最大池化函数max pooling的方式。模型中卷积的过程为:首先使用两次64个卷积核的卷积处理,接着进行一次池化层pooling,完成后又经过两次128个卷积核的卷积,并采用一次池化层pooling,再经过三次256个卷积核的卷积之后,采用一次池化层pooling,最后重复两次三个512个卷积核卷积之后,进行一次池化层pooling。在卷积层处理后是三次全连接层Fc_layer,此时网络中需要处理的参数已经减少了很多[5]。但传统VGG16的分类速度仍较慢,识别的准确度还有待提高。
1.2 迁移学习
对于新的问题往往需要重新搭建模型,并利用数据集再训练权重参数,成本相对较高且浪费时间,有时还难以实现。因此迁移学习的概念随之而来。在机器学习领域中,传统的机器学习方法局限于只能解决单一问题,无法一次性解决多个问题[6]。所以迁移学习领域的任务,就是将在源域中解决任务时所学到的知识运用到目标域中,结合目标域中已有的训练数据,对模型进行微调从而构造出泛化能力更好的模型。
本文方法中,将在ImageNet上训练好的VGG16模型的结构和参数,迁移到对猴子图形分类的问题中。通过迁移方法有效地减少大量训练参数,再次训练时只需确定微调参数即可,该过程不但减轻了工作量,基于以前的参数经验也可以实现更优化的分类目的。
2 对VGG16卷积神经网络模型的改进
2.1 图片进行去噪声处理
图片中通常会伴随着椒盐噪声,这是由于信号在图像传感器传输、解码处理等操作时,受到突如其来的强烈干扰而产生,属于一种因信号脉冲强度引起的噪声,可能在亮区域中出现黑色像素点或是在黑暗区域出现白色像素点[7]。通常对于椒盐噪声处理的方法有异常值侦测、中值滤波、伪中值滤波,其中常用的处理方式是中值滤波方法,它是一种非线性滤波技术,核心思想是利用该像素点邻域中强度值的中值来代替该像素点的灰度值(计算中值时包括该像素点的原始灰度值),并且能够做到完整地保留图像边缘信息,其利用cv2.medianBlur函数进行处理[8]。
通常使用信噪比SNR来衡量图像噪声,但由于其中所需用到的功率谱难以计算,因此采用信号与噪声的方差之比来近似估计图像的SNR。信噪比越小,图片中所混杂的噪声越多。图1所示是猴子数据库中一张伴随有椒盐噪声的图像,图2则是图像去噪处理后的结果。

图1 带有椒盐噪声的图像

图2 去噪声处理后的图像
2.2 数据标准化
运用数据集对模型进行训练时,通常需要将数据集分为训练集和测试集。前期利用训练集计算权重参数以及每个神经元的偏置,后期利用测试集对训练好的模型的准确率进行验证。为了实现对数据集的统一管理,TensorFlow中提供了一种TFRecord的格式,能够对训练数据实现统一存储。TFRecord格式可以将任意数据转化成TensorFlow所支持的格式,使得数据集更容易应用到相应的网络应用架构中[9]。TFRecord是一种将图片中重要的数据以及标签保存在一起的二进制文件,可以通过调用tf.python_io.TFRecordWriter类,将数据存放到TFRecords文件的tf.train.Example协议内存块中,Example协议块中包含以字典形式存放的特征值和数据内容。
TensorFlow标准化的建议是,一个TFRecord文件中最好仅存放1 000张左右的图片,若在一个包中存放太多的数据,则不利于多线程的读取,因此需要根据相应数据集的数量对图片进行打包。针对本文方法中用到的训练集和测试集的图片数量,将训练集数据打包为两个文件:traindata.tfrecords-000和traindata.tfrecords-001;因为测试集数据量不算多,因此打包为一个testdata.tfrecords-000文件即可。每种集合中不同类型的猴子图片分配情况如表1所示。
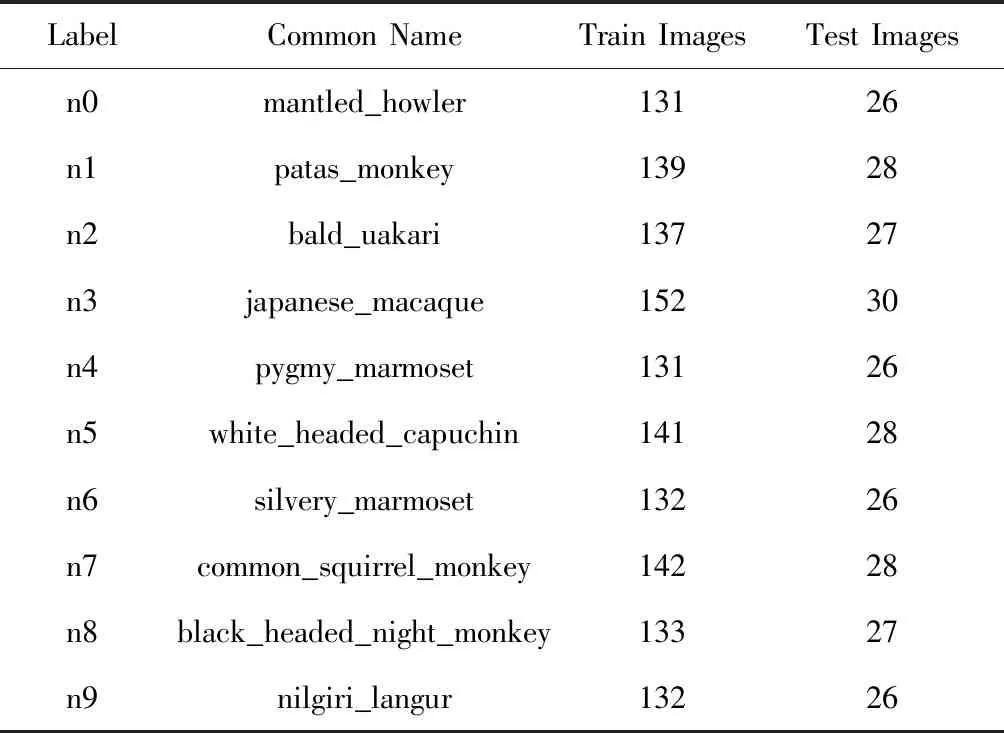
表1 训练集和测试集中10种猴子的图片分类情况
TFRecord文件中存储的是图像经过压缩编码后的结果,因此后续将图片进行恢复时需要进行解码操作[10]。通常训练模型时获取的图片数据集尺寸大小并不统一,为了能够把TFRecord文件中的二进制的数据重新构造为原来的图片,需要记录每张图片的img_width和img_height两个信息,并利用TensorFlow中的reshape函数实现图片重构。在本文方法中对重构的图片以mun_Label_class id(数字_Label_标签)的方式进行命名。重构的标准化图片结果如图3所示。

图3 重构图片形式
2.3 损失函数的改进
损失函数loss描述的是真实值与预期值之间的偏离程度,有利于对模型的学习进行指导,损失函数越小代表该模型的鲁棒性能越好。在本文方法中使用的损失函数是将softmax loss与center loss相结合。
在实现多分类任务的情况下,人们通常会选用softmax激活函数与交叉熵损失函数cross entropy相结合的办法。交叉熵刻画的是两个概率分布的距离,交叉熵越大说明两者的距离越远。由于神经网络的输出结果并不一定都是概率分布,因此用softmax激活函数将多个神经元的输出归一到(0,1)区间内,将前馈神经网络的传播结果转换为概率分布的形式。这种方式对于不平衡的训练集十分有效(文中提到的softmax loss均指代交叉熵损失函数)[11]。
首先在softmax函数的作用下将前馈神经网络的输出结果变为概率分布,假设卷积神经网络的输出为y1,y2,…,yn,经过softmax函数处理后变为:
(1)
采用softmax函数的好处在于计算较为简单。交叉熵的计算公式如下:

(2)
其中,y为真实的输出值,而a为模型求得的模型值。
最终逻辑回归的损失函数定义如式(3)所示,在这个损失函数中Y是真实结果转化为one-hot的向量结果。
(3)
通常希望训练出来的理想数据能够呈现出同类之间紧凑、异类之间分散的效果。上面介绍的softmax loss损失函数,可以有效地实现类间的区别较大,但是无法达到类内较为紧凑的效果,所以类内的间距还是比较大的。
利用经典的MNIST手写体数字识别数据集进行验证交叉熵损失函数,数据集中共有10个数字,利用二维空间展现训练到最后一层的特征分布情况。从图4可以看出使用softmax loss损失函数后能够呈现出较为清晰的类别界限。

图4 MNIST数据集的特征在二维空间的分布情况
为缩小类内差距,本文方法运用辅助函数即中心损失函数center loss。center loss函数的核心意义是,对于每一个分类都需要维护一个类内中心c,即该类所有样本的特征平均值,如果输入样本距离类中心太远就要受到惩罚,从而起到缩小类内距离的作用[12]。并且通过上述实验证明如果只用center loss函数,效果并不是很好,无法有效增加类间差异性。因此可以采用将softmax loss与center loss相结合的方法扬长避短,实现期望特征具有较高的识别度。
center loss的定义为:
(4)
令CenterLoss=Lc。
softmax loss的定义为:
(5)
其中cyi代表每类特征的中心。完整的损失函数为:
L=Ls+λLc
(6)
对参数λ设置不同值,可以调节类内的密集程度,λ越大类内越密集。将改进的损失函数应用到基于MNIST数据集的训练当中,从图5可以看出采用将两种损失函数相结合的办法,能够有效实现类间间距更大,而类内更加紧凑的预期效果。

图5 类间差距大、类内差距小的优化分类效果
2.4 Swish激活函数
在神经网络中数据间的关系通常为非线性关系,因此激活层存在的最大目的在于引入非线性因素,来增加整个网络的表征能力。原始模型中使用的激活函数是修正线性单元ReLU,尽管ReLU具有单侧抑制、相对宽阔的兴奋边界以及稀疏激活性等优点,但仍存在不足。当x>0时,它会一直无止境地“发飙”下去,ReLU属于非饱和的线性函数,这样会导致数值不稳定,计算溢出,变成负值,这时ReLU的输出结果将永远为0[13]。
因此在该模型的改进中引用了Swish激活函数,Swish函数有下界无上界,并且它拥有不饱和、光滑、非单调性的特征。此外在Google Brain的论文中提到在不同数据集上运用Swish激活函数时,准确率都有所提高,并且更适用于大的数据集和更深层的神经网络结构[14]。Swish的定义为:
f(x)=x×sigmoid(βx)
(7)
为了测试Swish比ReLU的性能更优,利用三种不同的模型结构,分别为VGG13、VGG16和AleNet,同时在MNIST和10种不同猴子的两个数据集上进行测试。对于不同种类猴子的数据集,在其训练和测试中准确率、损失函数loss的变化程度上,也能够体现出Swish激活函数的性能比ReLU激活函数要好,因此在改进的模型中选用Swish激活函数。测试结果如表2所示。

表2 检验结果
2.5 Adam优化器
在该模型中引入Adam优化器,这是一种自适应学习率优化算法,是一种对随机目标函数执行一阶梯度优化的算法[15]。Adam算法与传统梯度下降优化器的区别在于,它能够为每一个参数设计独立的自适应性学习效率,通过对梯度的一阶矩估计和二阶矩均值计算来改变学习效率[16]。
Adam算法将AdaGrad算法和 RMSProp算法相结合,分别取二者之长。其中AdaGrad算法能够自动为不同参数适应不同的学习率,根据参数变化的频繁和稀疏程度来调整步长进行更新。RMSProp算法利用梯度平方的指数移动平均数对学习率进行调节,能够有效加快目标函数的收敛速度。此外Adam算法的调参更为简单,通过默认参数就可以解决大部分问题,适应于拥有大规模数据及参数的情况。该算法具有良好的稳定性,能够让网络函数收敛得更快[17]。定义公式如下:
mt=μ×mt-1+(1-μ)×gt
(8)
(9)
(10)
(11)
(12)

3 实验结果与分析
本次试验基于迁移学习,为了实现对细粒度猴子图像的分类达到更优的效果,对传统的VGG16模型进行了改进。数据集采用从kaggle平台上获取的10种不同的猴子图像,首先运用训练集在改进的模型上进行训练(统一将改进的模型称为VGG16_2)。在训练速度方面,通过利用迁移学习已经节省了大量的训练时间,此外在硬件方面运用NVIDIA的GPU对模型进行训练,使得卷积神经网络的训练速度得到了大幅度的提升。原本需要花费一天才能训练完成,改进模型仅需要1个小时就可以达到预期效果。
模型训练的同时需要保存每一步的关键参数、当时的模型结构以及重新训练的权重信息,以便后续再次使用该模型时可以将有用信息直接恢复到所需要的模型当中。对于模型的保存使用Saver类中的save函数,保存时会产生四类文件,包括“.meta”文件用于保存图形的结构;“.data”文件用于保存变量的值;“.index”文件用于标识检查点信息以便于以后的恢复;“checkpoint”文件包含了最近检查点列表的协议缓冲区。恢复模型时使用Saver类中的restore函数,将这些文件加载到当前模型中即可[19]。
最后对训练好的模型进行测试,运用测试集检验VGG16_2的准确率。通过验证得到该模型对于猴子图像分类的准确率可以达到98.875%。图6、图7分别描述了此次训练以及测试时损失和准确率的变化。

图6 损失的变化
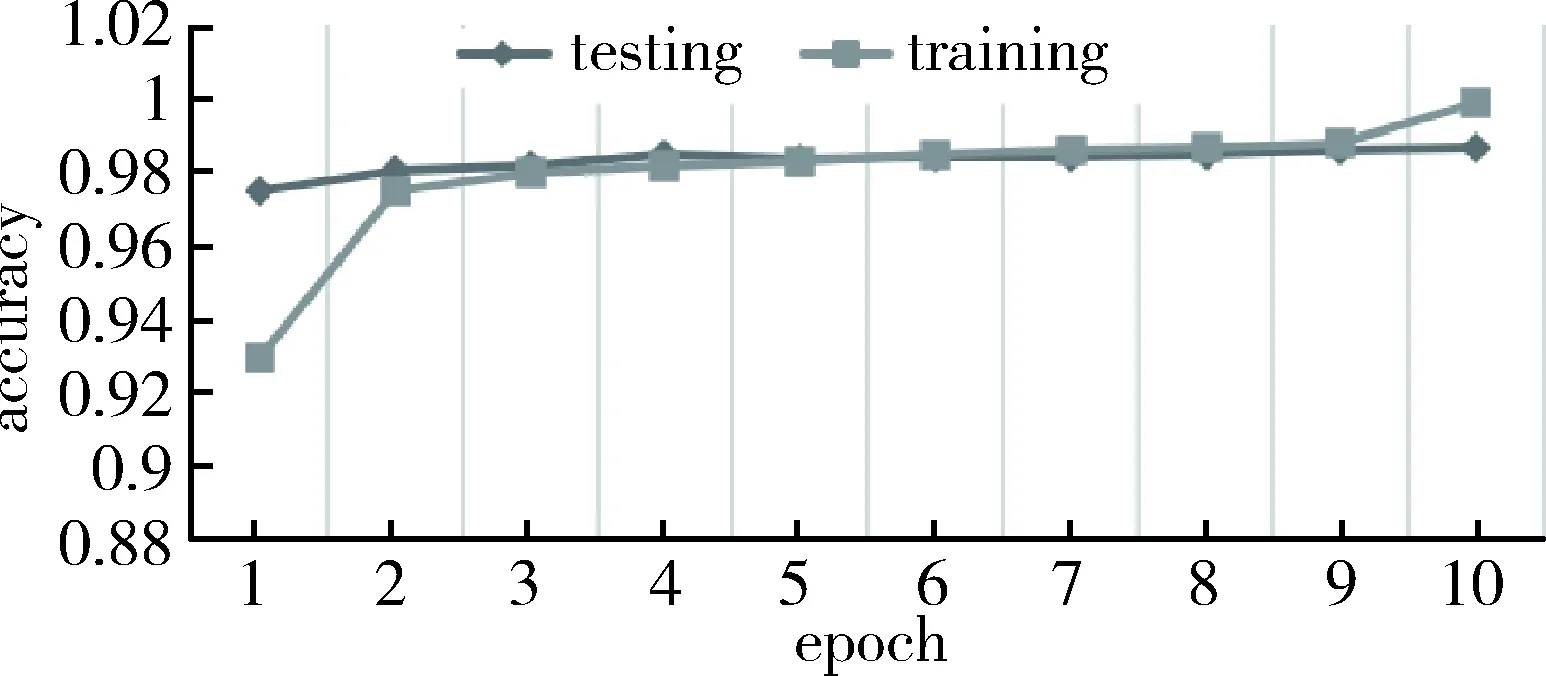
图7 准确率的变化
为了验证改进的VGG16_2模型具有更好的识别性能,利用猴子数据集分别在VGG11、VGG13、VGG16、alexnet、VGG19_bn、inceptionv3、resnet152_v2以及改进的VGG16_2上进行训练。在不同模型上的准确率对比如表3所示,从表中可以看出经过改进的VGG16_2的准确率较高。表4列出了对于不同种类猴子的识别率。

表3 猴子数据集在不同模型上的准确率对比
通过实验可以证明经过改进的VGG16_2模型对猴子图像的分类具有更好的性能。
4 结论
本文基于迁移学习实现了对10种不同猴子图像的识别,并为了适应该数据集使模型达到更好的识别效果,对传统VGG16模型进行了改进,分别从激活函数、损失函数和优化器的角度入手,生成VGG16_2模型。结合各种已有模型,以及在各种不同数据集上的测试对比结果,选取较该数据集来说性能最优的Swish激活函数、center loss与softmax loss相结合的损失函数、Adam优化器对模型进行完善。

表4 10类猴子分别在VGG16_2上的识别率
经最后的测试集验证,改进的VGG16_2模型的总体准确率高达98.875%。尽管如此,模型还有待提升的空间,并且针对这种细粒度图像的识别还需对模型进行完善,以达到最好效果。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
小天使·二年级语数英综合(2019年10期)2019-11-08
小天使·一年级语数英综合(2018年7期)2018-09-12
儿童故事画报(2018年5期)2018-07-02
小学生学习指导(低年级)(2018年4期)2018-03-12
海峡姐妹(2016年2期)2016-02-27
共产党员(辽宁)(2015年2期)2015-12-06
