
基于Star-Gan的人脸互换算法
2020-05-20 01:35易旭,白天
网络安全与数据管理 2020年5期
易 旭,白 天
(中国科学技术大学 软件学院,安徽 合肥 230026)
0 引言
随着深度学习技术的兴起,图像处理相关的研究有了一项强有力的技术支持。人脸互换在图像处理方面作为一个里程碑式的技术,意味着计算机能够理解人脸图像。如何通过对抗生成网络实现人脸互换,提升生成效果是现如今计算机视觉的一大热点。
对于传统的方法Face-swap[1],人脸互换只是把目标人脸截取,粘贴到原始人脸上面,使用图像融合的相关算法(如泊松融合)消除边界,后续的改进一般是在图像融合方面进行突破。
近年来,随着深度神经网络技术的成熟,KORSHUNOVA I[2]提出基于深度学习的人脸互换,将两个人脸的身份信息看成是两个不同图片风格,为一个目标人物训练一个深度神经网络提取人脸特征,换脸其实就是替换人脸的高维隐空间向量,而后再用训练好的人脸生成器进行生成,这种方式要求同一身份大量的人脸数据,其训练得到的模型只适用于这两个身份。YUVAL N[3]提出先使用3DMM模型拟合人脸,再互换人脸,解决了需要大量同一身份人脸图片的问题,但3DMM仍然有人脸匹配失败的问题,最终导致模型出错。NATSUME R[4-5]提出了FSnet和RSGAN,使用编码器学习整体人脸的编码,对所有的人脸只学习一个单一的人脸身份编码器网络,但由于输出的编码是一个高维的人脸身份向量,特征信息依然高度纠缠。
本文借鉴前人的思想,使用Star-Gan模型作为生成器,利用Arcface[6]身份编码器提取人脸高维身份特征,针对人脸细节的生成,使用基于U-net[7]的人脸特征编码器模型为多层级的输入,解决人脸特征纠缠的问题,使用Patch-Gan的思想改造判别器网络结构,引入实例归一化层提升生成效果。
1 Star-Gan模型[8]
Star-Gan模型的目的是解决人脸在多个域之间的转换问题,通过使用循环损失保证生成图像和背景图像的一致性,判别器保证生成图像的真实性,域分类器保证转换的有效性。调节多个损失,在生成效果上当时达到了较优的水平。
Star-Gan可以作为一个不错的条件生成模型框架用于其他的生成任务。即将它的条件输入替换成身份图片的身份编码。该模型包括3个下采样模块、6个残差模块和3个上采样模块。网络的输入是背景人脸图片,在残差层添加身份人脸的高维身份信息。最后端输出换脸图片。图1是整体网络架构图,详细的损失细节见2.4节。

图1 模型整体框架图
1.1 数据预处理
为了增强本模型的鲁棒性及泛化能力,在保证数据标签不变的情况下增大数据集。本文使用图像翻转、添加高斯噪声的方法扩充数据,提高模型鲁棒性。
(1)图像翻转
使用图像水平翻转扩充数据,可直接将数据集扩充一倍。如图2所示,左边的九张图为数据集中的原始图片,右边为水平翻转图片。

图2 图像水平翻转效果
(2)添加高斯噪声
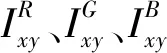
(1)
Ixy=min (0,max (1,Ixy+0.05N(0,1)))
(2)
1.2 实例归一化(Instance Normalization)
传统的GAN使用批归一化(Batch Normalization)的处理方式,虽然能提高收敛速度,但是却会降低最终的生成效果,因为它注重的是一个batch的数据,而更少地考虑单一图像本身的一致性。Star-Gan使用实例归一化,将输入的图像四个维度记为[N,C,H,W],N代表Batch_size,C代表通道数,H和W分别是图像的长和宽。实例归一化是在H和W维度上进行归一化,这样的好处是它更加关注图像本身的一致性,具体处理如式(3)~式(5)所示,三个公式中,t表示batch的数目,i表示通道数,j和k表示图像的像素位置,l和m表示图像的长和宽,式(3)中ε是一个极小的常数,防止出现除以0的计算。通过式(3)处理原始图像x,计算得出归一化后的图像y;式(4)计算得到原始图像x本身像素的均值;式(5)计算得到原始图像x本身像素的方差。
(3)
(4)
(5)
1.3 残差层
Resnet18[9]通过在block的输出增加残差层,使得网络有了逼近恒等映射的能力,解决了网络传播过程中信息丢失的问题,由于残差层的存在,避免了深度乘法对梯度的影响。Star-Gan通过引入残差层训练提升了深度学习训练效果,同时解决了由于网络层数加深,出现的梯度消失现象。具体残差块如图3所示。

图3 Resnet18残差层
图3中,X是上一层的输入,通过两层的卷积层学习到新的特征输出F(x),最后的输出是F(x)和输入X的叠加,梯度可以从两条支路进行传播,避免过深的网络导致的梯度消失。
2 基于Star-Gan的人脸互换模型
2.1 U-net结构编码器
通过一个类U-net的编码解码结构提取人脸身份特征,如图4所示,使用特征重构损失约束编码器学习图片各个维度的特征。X特征是输入图片,X重构是输出图片,中间层的特征输出作为生成器的图片高维特征输入。
2.2 Patch-Gan结构
Patch-Gan与传统的GAN十分相似,不同的是它的判别器是一个全卷积网络,其输出不是一个数字,而是一个二维矩阵,这样的好处是它能够保证图片的局部一致性。判别器具体结构如图5所示。

图4 编码器详细结构

图5 判别器详细结构
2.3 Arcface人脸身份判别器
本文使用Arcface最后一层的特征作为人脸身份信息的特征表示,并将它作为生成器前三层的身份特征输入。
2.4 整体损失函数和训练细节
固定Arcface网络,网络训练时不更新参数,特征编码器损失使用MSE损失训练确保每一层网络能够提取出不同维度的特征。解码后能够还原初始图片。
(6)
为了保证生成器具有生成能力,使用了三个损失函数:对抗损失LD、身份损失Lid和特征损失Latt,保证生成图片Ys,t的真实度。具体公式如式(7)~式(9)所示。
式(7)中X是从真实图片中的采样,来自于Xs和Xt,Zs和Zt是图片分别经过Arcface和特征编码器提取的特征向量。
LD=-Ex~pr[logD(X)]-Ez~pz[log(1-D(G(Zs,Zt,Xt)))]
(7)
式(8)中Ys,t表示换脸后的图片,zid表示将人脸图片输入Arcface得到的身份特征,用两张图片的余弦距离作为身份相似度。
Lid=1-cos(zid(Xs),zid(Ys,t))
(8)
提取多层级的人的身份特征后,使用Latt损失函数评估身份特征的保持。因为使用了5层的身份特征,此时式(9)中n=5。
(9)
为了达到人脸互换的目的,需要最小化上述所有三个损失,最终损失L如式(10)所示,其中λid和λatt是训练时的两个超参数,调节三个损失的比例,这里设定λid=10和λatt=1。
L=LD+λidLid+λattLatt
(10)
3 实验结果及分析
实验环境为:Linux16.04的64位操作系统;显卡型号为RTX1080ti,并行化处理,每张显卡拥有12 GB 显存;使用Pytorch1.0.1环境;Python3.6包括python-open-cv库以及Scipy。
因人脸互换的输出判别较为主观,本文将输出图像与FF++的人脸互换模型中的Faceswap和Deepfake模型进行比较。
3.1人脸互换泛化能力测试
初始训练时使用最新的FFHQ人脸数据集进行训练,Arcface模型使用原Arcface论文提供的预训练模型。为了加速模型训练,将FFHQ的图片缩放到3×256×256进行训练,图6是最终输出结果,最上面一行为身份人脸Xs,最左边是特征人脸,可以看出本文模型在很好地保持背景人脸的背景风格的同时可以很好地保持人脸的身份特征,且较少出现图像失真的情况。即使在双方差异很大的情况下,模型仍然能够保持良好的生成情况。第二列身份图片和背景脸部朝向有很大的差距;第三列、第五列和第六列改变了性别,但生成器仍然能够得到他们的合成图片;第四列和第五列分别测试了年龄上的差异性,结果显示模型在两张图片差异较大的情况下仍然能够处理相应的人脸图片,具有较好的泛化能力。

图6 模型基于FFHQ数据集训练人脸互换结果
3.2 人脸互换效果比较
为了衡量本文模型的生成效果,将模型生成的图片和Deepfake以及Faceswap的生成图片进行比较,此时不使用人脸数据集FFHQ进行训练,仅使用FaceForensics++[10]数据集中视频人脸数据进行训练和替换。训练时对视频帧进行采样,每1秒采样10帧,为了保持背景尽量一致,保持Arcface固定不变,训练时提升L1损失的权重λatt=20,训练效果如图7所示。

图7 模型与Faceswap、Deepfake视觉效果对比
由图7可以发现Faceswap方法的人脸会出现强烈的失真和脸部变形,其主要是由于Faceswap的方法着重于将身份人脸直接替换到背景人脸,导致前后帧不一致从而形成失真。而Deepfake着重于人脸框的替换,这样的好处是其不需要关注背景的信息,但显而易见地,它趋向于模糊化人脸,目标人脸无法很好地融合进背景人脸中。
3.3 使用Face-net[11]比较人脸身份的保持
Face-net是一个人脸识别的框架,它可以通过计算人脸图片的高维特征的余弦距离衡量两张人脸之间的身份相似性。表1是将图7的五种图片分别与身份人脸比较,输入Face-net网络后计算得到的欧氏距离。距离越小表示身份越相似。经过大量数据的测试,可以认为两张人脸是同一个人的阈值约为1.1,即余弦距离低于1.1,则可以认为两张图片是同一个人,当图片完全一致时,距离为0。
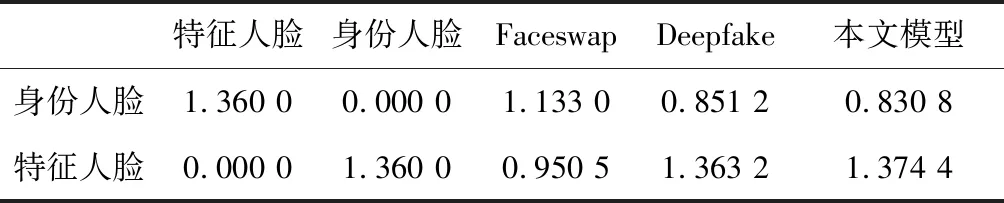
表1 模型与Faceswap,Deepfake身份保持对比
由于人脸互换模型的重点是保持身份特征,所以只需要关注表1第一行身份人脸和其他所有人脸的相似度。本文模型最大限度地保持了人脸身份,Deepfake也比较出色地完成了人脸互换,但是由于它只考虑到脸部中心区域,因此最后的效果比本文模型略差。而Faceswap只用了简单的扣取加替换方式,导致生成的人脸的一致性较低,与身份人脸的相似性较低。第二行显示出本文模型转换的图片与特征人脸的身份差距较大,高于其他两个人脸互换模型,证明本文模型更少地依赖特征人脸的身份信息。
4 结论
本文基于Star-Gan构造了一个人脸互换模型,针对人脸身份独立设计了一个编码器用于提取身份,使用多层级的思想改良了生成器Star-Gan,实现了一个人脸互换的模型。在FaceForensics++数据集上的实验效果表明,该模型在生成效果和人脸身份保持上优于现有的人脸互换模型。但该模型仍有缺陷,其虽然有良好的泛化能力,但针对初始身份人脸数量较少时,模型效果仍然有待提升。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
锻压装备与制造技术(2021年5期)2021-11-13
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
科学技术创新(2021年5期)2021-03-17
北京航空航天大学学报(2020年10期)2020-11-14
——编码器
演艺科技(2020年7期)2020-08-13
北京航空航天大学学报(2019年9期)2019-10-26
