
航迹规划策略学习方法研究
2020-05-18 11:08曹家敏付琦玮周丘实秦筱楲
计算机工程 2020年5期
曹家敏,付琦玮,周丘实,秦筱楲,蔡 超
(1.华中科技大学 人工智能与自动化学院 多谱信息处理技术国家级重点实验室,武汉 430074;2.北京机电工程研究所,北京 100074)
0 概述
航迹规划可分成交互规划和自动规划,其中交互规划是由规划人员对航迹导航点的属性进行调整实现对航迹的规划修改。当前的航迹规划软件在这两方面均存在不足,自动规划过程中规划算法难以兼顾复杂约束以及交互规划过程中缺乏专家经验知识导致规划效率低。传统的自动规划算法主要基于预先确定的代价函数,利用优化算法不断迭代,得到的飞行航迹大多难以满足现代战争中不断变化的任务要求和约束条件[1],如稀疏A*搜索算法[2]采用二维的C空间表示规划环境,不能满足最小爬升/俯冲角、最低飞行高度等约束条件。同时,飞行器执行任务的种类、难度及相应的制导、导航等约束条件数量和耦合程度不断增加[3],导致规划人员在交互规划中对不满足约束的航迹进行调整时,通常会消耗大量时间,使得航迹规划时间过长。规划人员的经验不足以及航迹规划专家的规划经验知识没有得到及时共享及重用,也增加了规划人员无效的调整次数。
为能在较短时间内规划出符合规划人员意图的路径,可将人工智能和航迹规划相结合。20世纪80年代中后期,美国波音航空航天公司开发了基于人工智能的航迹规划软件[4]。文献[5]基于人工智能的基本理论,提出一种适用于航迹规划的生长式推理模型。文献[6]采用基于云模型的模糊方法进行人机协同的航迹规划,实现了规划过程中对禁飞区或威胁区绕行方向的决策。此外,还有学者将强化学习[7-8]、人工神经网络[9-10]、模糊控制法[11-12]等用于求解航迹规划问题。本文对航迹规划系统的智能化进行研究,结合人工智能中机器学习的相关理论和技术,设计基于知识积累和知识学习的航迹规划策略学习方法。该方法能够记录航迹规划过程中有助于解决约束冲突的规划操作,学习其中的规划经验与知识,将其总结为约束问题的对应策略,并通过这些规划策略辅助规划人员进行航迹规划,以降低规划难度及加快规划速度。在策略学习中,对于飞行器环境约束,主要提取样本中的环境信息,建立XGBoost预测模型,将分类和预测结果进行操作映射形成策略;对于飞行器特性相关约束,主要计算样本中航迹数据的导航点属性变化,运用K-prototypes算法进行聚类,对聚类中心进行操作映射形成策略。将分类和预测的结果与约束对应保存于下次约束不满足的情况中,提取策略并反馈给规划软件进行策略引导。
1 航迹规划策略学习的方案设计
航迹规划策略学习的主要步骤为:多方面搜集能够体现规划操作经验的数据,当约束检查结果发生变化时,收集数据并按照约束信息、航迹数据和环境信息这3个方面提取学习样本并存入样本库;对复杂约束进行分类,将样本按照不同约束进行识别区分;逐类别进行策略学习。航迹规划策略的学习流程如图1所示。在策略学习中,对于飞行器环境约束,主要提取样本中的环境信息,建立XGBoost预测模型,将分类和预测结果进行操作映射形成策略;对于飞行器特性相关约束,主要计算样本中航迹数据的导航点属性变化,运用K-prototypes算法进行聚类,对聚类中心进行操作映射形成策略。将分类和预测结果与约束对应保存于下次约束不满足的情况中,提取策略并反馈给规划软件进行策略引导。

图1 航迹规划策略的学习流程
2 样本采集与管理
2.1 样本采集
样本的采集过程依托于航迹规划软件和航迹约束检查模块,主要操作步骤为:1)对当前状态的航迹进行约束检查;2)对不满足约束条件的航迹进行手动规划;3)对操作后的新航迹再次进行约束检查;4)对比两次检查结果,如果检查结果发生变化,则保存样本并存入样本库。样本采集流程如图2所示。

图2 样本采集流程
2.2 样本结构设计
在航迹规划过程中,规划人员的操作行为与环境因素、约束条件、任务需求有关,为便于后续的规划策略学习,本文将操作行为与约束条件相关联。同时,为更完善地记录操作行为所带来的影响,对操作前后的航迹数据也进行保存。航迹导航点的操作还与规划环境有关,在记录操作行为时,同时记录了操作行为所对应的环境信息。样本的结构包括操作前后的航迹数据、约束信息以及被操作点的周围环境信息,结构如图3所示。

图3 样本结构
样本结构具体如下:
1)航迹数据。记录航迹上每个导航点的属性,包括经度、纬度、航程、转弯半径等。
2)约束信息。记录约束检查结果,包括约束类型、与约束条件相关的导航点类型。
3)飞行环境信息。航迹与环境信息密切相关,规划人员在判别如何规避危险时,最直观且重要的衡量指标是当前航迹穿过的危险区域到周边禁飞区或威胁区的空间距离和方向,所以设计如图4所示长度均为R的扫描线检测当前穿过区域的周围环境,并将检测到不同方位上的距离最近的禁飞区或威胁区的距离值dis和角度值dec进行保存。样本的环境特征属性构造如下:
(1)保存航迹穿过区域的自身属性信息{a,b,ang},其中,a为区域长轴,b为区域短轴,ang为长轴与正北方向的夹角。
(2)扫描区域划分。扫描区域以正北方向为基准、45°为间隔,按顺时针方向划分为8个区域块(Env0,Env1,…,Env7)。
(3)周围环境信息标准化。量化环境信息中的角度值dec,并将环境数据向量{dis,dec}填入相对应的区域块中,若在区域块内没有检测到危险,则该区域块的所有属性值为0。
(4)计算穿过危险区域中航迹段的夹角,记为航向偏向角Trackang。
(5)记录规划人员的操作行为,表示为{Opt_dec,Opt_dis},如图5所示,Opt_dec为操作方向,并以45°为间隔量化成8个方向值,Opt_dis为操作距离。

图4 距离扫描线

图5 操作行为示意图
按照上文描述,将飞行环境信息格式设计为如图6所示的形式。

图6 飞行环境信息格式
2.3 样本分类
由样本采集过程可知,在航迹规划过程中采集到的样本数据是能够解决约束问题的有效规划操作。在策略学习前需要针对约束对样本进行分类管理,使后续学习能够专注于提取样本中的规律信息。
影响飞行器航迹的因素分为:1)来源于飞行器自身,包括飞行器自身的性能和导航约束;2)来源于飞行环境,本文主要考虑威胁区和禁飞区的回避问题;3)与飞行任务有关的因素。飞行环境和飞行任务影响着航迹的走向和趋势,本文把这两类约束相关的样本归并为飞行器环境约束样本,获取规划操作的有效特征需要分析航迹与环境的相对关系。满足飞行器特性相关约束的规划操作需要针对不同的具体约束,由规划人员依据自身的经验改变导航点的位置或其他属性。样本分类管理示意图如图7所示。

图7 样本分类管理示意图
3 航迹规划策略的学习算法
3.1 飞行器环境约束策略的学习算法
本文设计的飞行环境信息包含航迹穿过威胁区或禁飞区的属性信息、被操作导航点的周围环境信息、穿过威胁区或禁飞区的航迹偏向角以及规划操作数据,可有效反映出航迹与环境的相对关系以及规划操作特征。因此,将飞行环境信息作为飞行器环境约束策略学习的输入数据。
当航迹不满足飞行器环境约束时,规划人员主要通过调整导航点的位置来规避威胁区或禁飞区。输入数据中构造了规划操作数据向量{Opt_dec,Opt_dis},将规划人员的操作行为映射为导航点空间位置的变化。Opt_dec表示为操作方向,即被操作导航点的移动方向。规划人员对导航点的移动方向要求并不严格,只需给出移动的方位信息,即可正确地进行规划引导,对操作方向进行量化处理,将该类问题看成多分类问题。Opt_dis表示操作距离,即被操作导航点的移动距离,受威胁区或禁飞区自身的属性数据影响较大。当危险区域的覆盖范围变化时,若操作距离不及时更新或表达不够精确,则可能会导致移动后的导航点仍在威胁区域内,使规划策略无效。为保证操作距离的预测精度,将其保留为连续型变量,将该类问题看成回归分析问题。在分类算法中,集成学习方法中的XGBoost算法[13]是一种基于树的能够自动处理稀疏数据的提升学习算法,基本分类器是CART,既可以处理回归分析问题,又可以处理分类问题。
XGBoost算法在目标函数中加入了树模型的叶子节点个数和深度等正则项,有效防止模型过拟合,并且控制模型的复杂度。同时,XGBoost算法对GBDT算法[14]进行扩展和改进,在优化目标函数时引入二阶导数,提高算法的准确度,因其预测的高效性和准确性被应用于指纹定位[15]、雷达辐射源分类[16]、能源供应安全预测[17]等方面。
(1)

模型的目标函数定义为:
(2)

⋮
(3)

(4)
为方便计算,采用泰勒二阶展开来近似定义目标函数,并在正则化中考虑树的深度和叶子节点的权重。最终目标函数可表示为:
(5)

同时,航迹规划软件中的环境信息复杂多变,禁飞区或威胁区的个数存在不确定性,导致样本数据中会有大量的零值,使得样本数据稀疏。XGBoost算法能对稀疏数据进行自动识别,主要思想为:如果某个样本在特征k上的值缺失,考虑将其分别划分到右子节点和左子节点,而且选择最优分裂点时只利用那些非缺失值,按照不同的选择方向分别计算缺失数据的样本属于右子树和左子树的增益,选择增益最大的方向为缺失数据的默认分裂方向。因此,含有缺失值的样本根据训练数据自动学习得到分裂方向。
规划人员的操作行为存在随机性,在生成样本时会造成样本的不均衡。集成学习中个体分类器与过采样、欠采样、选择性采样等数据预处理方法结合,可有效处理类别不平衡数据的分类问题[18-19]。综合以上描述,XGBoost算法快速有效,能较好地处理样本数据稀疏且不平衡的情况,适用于飞行器环境约束的策略学习,学习流程如图8所示。

图8 基于XGBoost算法的策略学习流程
3.2 飞行器特性相关约束策略的学习算法
飞行器特性相关约束包括飞行器自身的性能和导航约束。在解决此类约束时,规划人员依据自身经验改变导航点的位置或其他属性。由于导航点类型与导航点属性的多样性,规划人员可以进行的规划操作存在很多的可能性,因此无法有效地构造分类标签,并且对于每一种约束,可能有多种航迹调整方法使得航迹能够满足约束条件,它们之间所涉及的属性可能相差较大,也给定义样本类别增加了难度。值得注意的是,对于同一约束,不同规划人员的规划操作存在一定的规律性,如果能够收集大量的有效规划操作数据,则有可能利用这些数据生成规划策略。聚类分析能够在没有领域专家的参与下,从样本数据中发现隐含、有价值的知识,适用于飞行器特性相关约束的策略学习。
同时,规划人员的操作行为与航迹上导航点的属性变化相对应,比如对航迹进行高度调整对应航迹上导航点的高度值发生变化。因此,输入数据可表示为样本中规划操作后的航迹数据与操作前的航迹数据的差值,数据格式如图9所示。在输入数据中,设备状态控制点中设备状态值的变化为分类型属性,其余导航点属性的变化为数值型属性。

图9 飞行器特性相关约束策略学习的输入数据格式
在聚类分析中,K-prototypes算法[20-21]借鉴K-means算法和K-modes算法[22-23]的思想,分别计算两种类型数据的相异度,数值型属性采用欧式平方距离进行计算,分类型属性采用汉明距离进行计算,最后对其加权求和作为整体数据的相异度衡量标准。在K-prototypes算法中,令X={X1,X2,…,Xn}表示具有n个样本的数据集,其中,Xi1=(Xi1,Xi2,…,Xip,Xi(p+1),Xi(p+2),…,Xim)表示第i个样本包含的m个属性值,前p个属性为数值属性数据,p+1到m为分类属性数据。令k表示初始聚类个数,对应模的集合为V={V1,V2,…,Vk},聚类迭代过程中类的集合为C={C1,C2,…,Ck},Ci={Ci1,Ci2,…,Cik}。
数值属性数据的距离度量[21]是基于欧氏距离定义样本Xi与模Vl之间的距离,其计算公式为:
(6)
分类属性数据的距离度量[21]的计算公式为:
(7)
其中,(p+1)≤j≤m。相异度计算公式[21]为:
(8)
其中,d(Xi,V)表示样本Xi到其所属集合模的距离。
综合以上描述,K-prototypes算法可解释性强,计算简单,且对混合属性样本数据可进行有效处理,学习流程如图10所示。

图10 基于K-prototypes算法的策略学习流程
3.3 策略表示
一阶谓词逻辑是传统数理逻辑中的概念,是应用于人工智能领域的一种重要知识表示方法,其知识表示规范,逻辑性强,推理过程严密[24-25]。一阶谓词逻辑通过使用谓词、连词和量词来表述各种描述性语句,适合表示事物的状态、属性、概念等事实性的知识,并可有效、合理地转移和存储到计算机中进行处理[26]。对于飞行器特性相关约束,在K-prototypes算法学习结束后得到聚类中心为离散数据向量,需要将数据向量表示模式转换为自然语言表示模式,便于规划人员理解使用,因此,本文采用一阶谓词逻辑将规划策略从数据向量转换为自然语言表达模式。
在航迹规划过程中的规划引导信息采用约束-策略的形式。首先,提取约束信息,可转换成“不满足XX约束,需修改XX导航点”;然后,提取聚类中心数值向量,将数值型属性值代入转换语句,翻译为“导航点数值型属性有/无变化,属性XX的调整趋势:XX”,分类型属性代入转换语句,翻译为“导航点分类型属性有/无变化,属性XX的调整趋势:XX”。将规划引导信息用一阶谓词逻辑的形式语言表示,使规划策略在自然语言表达下逻辑保持一致,具体设计如下:
1)定义描述策略的谓词,如表1所示。

表1 规划策略的谓词表示
在表1中,con∈{AttriYS,RelaYS}表示飞行器特性相关约束包括导航点属性约束和导航点关系约束,导航点属性约束定义为导航点的属性值要满足某一条件的约束,如转弯半径必须在某数值范围内等,导航点关系约束定义为导航点之间依赖或制约的关系约束,如转弯过程与高度变化过程不可重叠,设备A在使用过程中,必须有设备B处于特定状态。state∈{Yes,No}表示“是”或“否”两种状态;tType∈{Turn,Height,PicFit,EquiState}表示导航点包括转弯控制点、高度变化点、景象匹配点和设备状态控制点;CAttri∈{EquiA,EquiB,…},CAttri表示设备A状态、设备B状态等导航点分类型属性;NAttri∈{Dis,R,…}表示距离目标点的距离、转弯半径等导航点数值型属性;adjust∈{increase,reduce}表示调整趋势包括增大和减小。
2)使用谓词、连词和量词来表示一条策略:
CONSTRAINT(con,state)∧CHANGETYPE(tType)∧NUMERICAL_STATE(NAttri,state)∧NUMERICAL_ATTRIBUTE(NAttri,adjust)∧CATEGARY_STATE(CAttri,state)∧CATEGARY_ATTRIBUTE(CAttri,adjust)
4 反馈机制
航迹规划要保证所规划航路的可飞性和安全性,规避禁飞区和威胁区是首要任务,因此飞行器环境约束的优先级高于飞行器特性相关约束,在约束不满足的情况下会优先解决飞行器环境约束问题。
对于飞行器环境约束不满足的情况,将数据转换成对应的样本数据格式,然后直接用训练好的XGBoost分类器进行策略{Opt_dec,Opt_dis}的预测,并将结果以提示框的形式反馈给规划人员。
对于飞行器特性相关约束不满足的情况,在检查结果中可能存在多个约束不通过及一个约束多个策略,因此,需要计算出约束之间的优先级和规划策略之间的优先级。具体步骤如下:
1)统计一次航迹检查结果中各约束不通过的次数,并进行降序排序,取前N1个约束,其权重分别为{N1,N1-1,…,1},剩余约束权重均为0。
2)根据各约束对应策略组中策略对应样本数量计算策略权重,统计各个聚类簇中样本的数量并进行降序排序,取前N2个策略,其权重分别为{N2,N2-1,…,1},剩余策略权重均为0。
3)获得每个约束的约束权重和以及对应策略权重后,挑选权重高的约束和对应策略作为当前反馈策略,转化成自然语言,并以提示框的形式反馈给规划人员。
5 实验结果与分析
5.1 XGBoost算法实验验证和策略反馈结果
对于飞行器环境约束,让不同的规划人员在不同的环境下进行规划,收集1 500条样本数据,样本中的飞行环境信息作为输入数据,并进行数据归一化处理。其中,训练集样本数为1 200,测试集样本数为300。
在输入数据中存在操作方向和操作距离两个标签,操作方向是离散型变量,采用XGBoost模块中的XGBClassifier()分类函数进行学习。操作方向的预测为多分类问题,模型参数Objective为multi:softprob,softprob可返回每个数据属于各个类别的概率。操作距离是连续型数值变量,采用XGBoost模块中的XGBRegressor()回归函数进行学习。在对比实验中,本文采用AdaBoost和随机森林两种分类算法进行比较,并使用过采样的方法处理不平衡样本数据。通过交叉验证分别优化3种分类算法的参数后,利用测试集样本对建模结果进行预测,3种算法的分类结果如表2所示。

表2 分类结果比较
整体上看,XGBoost的预测结果较其他两种算法略高,且运行速度更快,具有更好的分类性能,并且对样本数据进行过采样处理后,提升了算法准确率。操作距离的预测结果如图11所示。
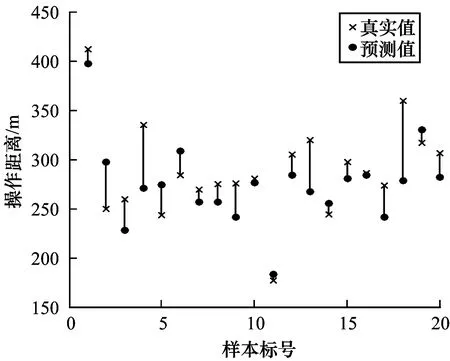
图11 操作距离预测结果
将训练好的XGBoost模型运用于航迹规划软件,并且给出策略反馈结果。表3为规划策略有效性测试结果,使3个规划人员在不同环境下按照模型给出的规划策略对100条不满足飞行器环境约束的航迹进行调整,验证模型的有效性,有效性判断为调整后的航迹是否满足约束条件。

表3 有效性测试结果
图12为策略反馈提示图。图12(a)中航迹穿过了禁飞区,在穿过区域的正西方向和西南方向有禁飞区和威胁区,航迹偏向为东南方向,模型预测的操作方向为向上,操作距离为214 m,按照规划软件中地图的分辨率转换为68个像素点,与规划人员操作相符。图12(b)中航迹穿过了威胁区,在穿过区域的东侧有禁飞区和威胁区,航迹偏向为东北方向,模型预测结果为操作方向向下,操作距离为164 m,按照规划软件中地图的分辨率转换为50个像素点,符合规划人员的操作行为,验证了模型的可行性和有效性。

图12 飞行器环境约束的规划策略反馈提示界面
5.2 K-prototypes算法实验验证和策略反馈结果
在实验中,规划人员可操作的导航点类型和属性如表4所示。为验证K-prototypes算法的有效性,从飞行器特性相关约束中选择一个约束条件,根据航迹规划人员的经验分析得出其对应的规划方法,如表5所示。

表4 导航点类型和相关属性

表5 约束对应的规划经验
在样本采集的过程中,针对不满足约束1的情况,让不同的规划人员分别用相对应的规划经验进行多次规划,共收集了410条样本,将样本中操作前后的两条航迹数据做差值,并对处理后的数据进行归一化处理。输入数据如表6所示,其中,设备状态变化为分类属性数据(设备开机状态为1,关机状态为0),其他导航点属性的变化为数值属性数据。

表6 K-prototypes算法的输入数据
K-prototypes算法是划分式聚类算法,因此在进行聚类之前要先确定聚类簇的个数,本文采用肘部法则来确定最佳的聚类数目,通过计算获得该约束的最佳聚类个数为3,与实际类别数一致。聚类结果的评估采用文献[23]中的轮廓系数法,其轮廓系数为0.86。表7为K-prototypes算法的聚类中心数据向量,在类别2中,导航点类型为2,经度、纬度和航程都发生了变化,即可表示为高度变化点的空间位置发生了改变,航程增大,距离目标点的位置减小,可将高度变化点的位置调后,与规划策略2相符,类别1和类别3的分析过程同上。
在表8中,统计了约束1各个簇中的样本数,类别2的样本个数最多,即规划策略2的权重高于其他策略。因此,选择类别2作为反馈策略,将其转换成自然语言形式。类别1和类别3对应的规划策略均对景象匹配点进行调整。由于匹配区约束条件相对较多且情况复杂,在实际规划过程中,规划人员会尽量避免对匹配点的调整,并且规划人员按照规划策略2调整航迹,调整后的航迹大部分都能满足约束1,在一定程度上验证了策略优先级计算的有效性。将策略2转换成如下自然语言形式:
CONSTRAINT(RelaYS,No)∧CHANGETYPE(Height)∧NUMERICAL_STATE(Dis,Yes)∧NUMERICAL_ATTRIBUTE(Dis,reduce)∧EMPTY(X)∧EMPTY(X)

表7 K-prototypes算法的聚类中心数据

表8 规划策略的权重计算
在图13中,L1、L2表示相邻两个导航点之间的距离,航迹中序号为5的景象匹配点和序号为6的高度变化点不满足约束1,模型给出的提示信息为高度变化点距离目标点的距离减小,即可向后移动高度变化点。转弯控制点与景象匹配点相邻,并且L1小于L2,如果将序号为5的景象匹配点的位置调前,则可能会导致L1不满足转弯控制点和景象匹配点之间的距离约束。相比之下,移动序号为6的高度变化点更符合规划人员的操作行为,验证了规划策略的有效性。

图13 导航点关系约束的规划策略反馈提示界面
6 结束语
本文利用航迹规划专家的经验和先验知识,设计一种基于XGBoost算法和K-prototypes算法的航迹规划策略学习方法。该方法综合考虑了各种复杂约束,针对约束问题的逐类学习,在样本分类过程中,依据约束自身特性和规划人员的操作特点,将复杂约束分成飞行器环境约束和飞行器特性相关约束,对于飞行器特性相关约束,将一个约束对应多种操作行为,进一步对约束进行细分,实现样本的分类管理。实验结果表明,对于飞行器环境约束的策略学习问题,XGBoost算法充分考虑了环境信息对规划策略的影响,提取出有效的样本数据,并对数据进行预测;对于飞行器特性相关约束的策略学习问题,K-prototypes聚类算法能准确地发现航迹规划有效操作中的规律并对其进行提取形成策略。该方法将机器学习相关理论和技术引入到航迹规划软件中,优化交互规划过程,降低规划人员的劳动强度和对知识、经验的依赖,提升交互规划效率和规划软件的智能性。由于航迹约束的复杂性以及不同约束之间的耦合性,本文策略的反馈机制还需进一步完善,以适应更加复杂的约束和环境。此外,如何优化策略学习算法也将是下一步的研究重点。
猜你喜欢
凤凰动漫(军事大王)(2022年1期)2022-04-19
数学年刊A辑(中文版)(2020年1期)2020-05-19
青年歌声(2019年12期)2019-12-17
电子制作(2018年2期)2018-04-18
北京航空航天大学学报(2017年7期)2017-11-24
北京航空航天大学学报(2016年6期)2016-11-16
小朋友·快乐手工(2015年5期)2015-06-06
人生十六七(2015年6期)2015-02-28
舰船科学技术(2015年8期)2015-02-27
计算机辅助工程(2012年5期)2012-11-21
