
有限时间数据下的零售药店药品销量预测研究
2020-05-18 05:47:26梅学聃周梅华
中国矿业大学学报(社会科学版) 2020年3期
梅学聃,周梅华
引 言
根据中国社会科学院发布的《2007社会蓝皮书》的调研结果,“看病难、看病贵”已成为最为困扰国人的社会问题之一。为了应对这种情况,中国政府在医药领域实施了一系列管制价格上限的措施,但是,居民在医药方面的经济负担越来越重的现象不仅没有得到显著缓和,反倒出现了“以药养医”的现象。医疗市场的信息不对称以及“以药养医”现象为医药分离改革的合理性与必要性提供了理论与现实基础(刘小鲁,2011)。中国医药商业协会副会长王锦霞认为,医药分开的本质目标是实现医生开处方、药店销售药品的合理专业分工。2002年,中国政府开始逐步推进医药分离的试点改革,但因政策不配套,试点没能继续。2009年,《中共中央国务院关于深化医药卫生体制改革的意见》提出通过实行药品购销差别加价、设立药事服务费等多种方式逐步改革或取消药品加成政策。2017年,《北京市医药分开综合改革实施方案》正式发布,2017年4月8日起,北京所有公立医疗机构都需取消挂号费、诊疗费,取消药品加成,设立医事服务费。伴随医药系统改革的进展,零售药店逐渐发挥了更大的作用。
药品销量预测有助于药品零售企业有效安排库存,一方面防止药品积压,减少药品过期带来的损失,另一方面可以减少缺货,减弱因无法为顾客提供所需药品而给他们带来的不良体验,药品销量预测是药品零售企业管理的一项重要任务。现有研究提出了许多预测方法,但也存在一定的局限性。对于开业不久的零售药店或者上市不久的新药来说,通过需要长时间数据的ARIMA等时间序列分析进行销量预测非常困难,很可能出现时间序列呈现为白噪声序列的情况,无法进行相应分析。现存的因果预测模型,如神经网络预测模型、支持向量机预测模型以及随机森林预测模型都需要对影响因素进行比较全面的分析才会有比较良好的预测效果,但穷尽所有影响因素是极其困难的。基于此,本文在综合考虑目前已有的预测方法优缺点基础上,将时间序列分析和神经网络结合起来对销量进行预测,力求克服开业不久的零售药店和刚上市的新药没有长时间销售数据进行ARIMA等时间序列分析的困难,同时减弱因果分析时难以穷尽所有影响因素的预测困境。在正式进行预测之前,本文模型利用指数平滑获取销量趋势信息,以将未能穷尽的某些影响因素纳入考虑;之后,利用主成分分析(PCA)对规模变量和价格变量分别消除冗余;最后,利用后向传播前馈神经网络进行预测。
一、研究设计
(一) 变量设定
根据营销组合理论,产品、价格、促销、渠道皆会影响产品需求,下面对可观测影响因素以及季节趋势因素分别进行讨论。
1.药店药品种类数(产品)
产品是任何能够提供给市场供关注、获得、使用或消费,并可以满足需要或欲望的东西。营销人员在3个层次上做出产品和服务决策:单个产品决策、产品线决策和产品组合决策。对零售药店来说,一般需要做出产品组合决策。产品组合由销售者提供或出售的所有产品组成。产品种类数能综合反映零售药店的产品组合。Campo和Gijsbrechts的研究表明,商店货架上的产品种类通过反映店内环境对销量产生影响(2004)。一方面,不同的消费者有不同的购物需求,有的人喜欢治本的中药,有的人喜欢药效快的西药,对同一个药,消费者也会有不同的品牌偏好,一个日益重要的零售策略旨在满足不同消费者的需求;另一方面,药品种类齐全的药店总是会显得更专业,更容易获得消费者的信任,如果消费者总是在一家药店无法购买到自己想要的药品,药店在消费者心中的形象会大打折扣,消费者很可能放弃再到这家药店买药。药店药品种类数影响药品销量。
2.药品价格(价格)
价格就是为了获得某种产品或服务所付出的金额。企业所制定的每种价格都可能导致不同的需求水平,Hoch等发现,商店内的价格影响商店的销量。成功的定价策略的基础是理解消费者的感知价值如何影响他们愿意支付的价格。正常情况下,价格与需求是负相关的,也就是说价格水平越高,需求水平越低。另外,需求对价格有不同的需求价格弹性。对于零售药店来说,首先,虽然药品更偏向是一种必需品,但在同一种药品有如此众多不同品牌替代品的今天,药品的价格会影响消费者的决策,过高的价格可能会使消费者望而却步,转而购买其它品牌的同类药品,而且,相对于竞争对手过高的价格也会将消费者“送”给竞争对手,对于同品牌同种类的药品,理性的消费者为何不选择更为实惠的销售者呢?另外,药品作为一种特殊的商品,承载了治病救人的重任,过低的价格可能使消费者不信任药品的质量,阻碍药品的销售。药品价格影响药品销量。
3.药品价格变动(价格)
根据期望不一致模型,消费者对产品性能的信念建立在以前的产品经验的基础上,这个模型同样可以推广到消费者对产品价格的期望上。药品过去的价格使消费者形成对价格的期望值,当药品的价格表现和消费者的预期一致时,消费者可能不会对它做过多的思考;反之,如果它表现为超过消费者的预期则会带来消极影响;而如果它表现为低于消费者的预期,消费者就会非常满意。价格变动影响药品销量。
4.药店工作人员数量(促销)
药店工作人员是药店同其顾客之间的重要联结。药品是一种特殊的商品,顾客往往需要就药效、服用方法等问题咨询药店工作人员。一方面,药店工作人员不足可能会让购买者感觉自己受到忽视,或者因为关于药品的疑问没有得到很好的解答而放弃在该药店买药;另一方面,药店工作人员过多可能会造成一种紧张的氛围,特别是顾客比较少的时候,过多的工作人员在场可能会让选购者感觉不适。合适的工作人员数量对药店来说是重要的,药店必须按照自身规模合理安排工作人员数量,并且配置适当的专业人员。药店工作人员数量影响药品销量。
5.药店能否使用医保(促销)
定点零售药店是产生于医疗保险制度,通过劳动保障行政部门资格审定,并经医疗保险经办机构确定,为参保人员提供处方外配和非处方药零售服务的药店。一方面,定点零售药店的开设需满足一系列条件,因此,定点零售药店本身具有一定的专业性并反映一定的资质,更容易获得消费者的信任。另一方面,医保的使用使得购药的付费负担得以减轻,从营销的角度去理解,可以被看作一种销售促进手段,对于同样的药品来说,消费者更可能在可以使用医保的药店购买。药店能否使用医保影响药品销量。
6.药店面积(渠道)
零售商是分销渠道中的一个成员,Campo和Gijsbrechts的研究表明,商店的规模通过反映店内环境影响销量(2004)。本文用药店面积来代表药店的规模。一方面,药店的面积会影响购买者选购药品时的情绪,在宽敞的药店选购药品时,对于宽敞的环境本身,顾客的体验往往更积极;另一方面,药店的面积是药店陈列药品种类数的基础,面积大的药店自然能陈列更多的药品,间接通过丰富药品种类促进了药品的销售。药店面积影响药品销量。
7.月份(季节)
很多疾病的发作与季节息息相关,导致药品的销售与季节息息相关。夏季的气温比较高,人们容易患上肠道疾病,止泻类药物的销量相应升高;秋冬季节的气温比较低,人们容易感染呼吸道疾病,感冒退烧药销量相应上升;另外,温暖季节里,一些传染病的病原微生物和媒介昆虫比较容易繁殖,在该季节,相应的传染病易于发生和流行。在本论文中,用月份代表不同季节的影响。
8.趋势
本月的销量往往和前几个月展现的销售趋势关联颇大,本文用指数平滑法获得销量趋势信息,趋势信息中包含了前文未能提到的某些影响因素的信息,如门店形象、门店位置等因素对销量的影响,对于同一药房来说,这些因素往往在比较长的时间内保持恒定。指数平滑法是用以前观测值的加权和作为某一期趋势的估计值,并且各期权重随时间间隔的增大而呈指数衰减,本文的趋势信息由预测月之前六个月销量数据指数平滑而得。将销量趋势纳入考虑应该对提高销量预测的效果有所助益。
针对药品销售特点,在问卷调研基础上,并考虑到现实数据来源的限制,本文以药店药品种类数、药品价格、药品价格变动、药店工作人员数量、药店能否使用医保、药店面积、月份、趋势为影响因素,对有限时间数据下药品销量预测进行了研究,变量定义如表1所示。
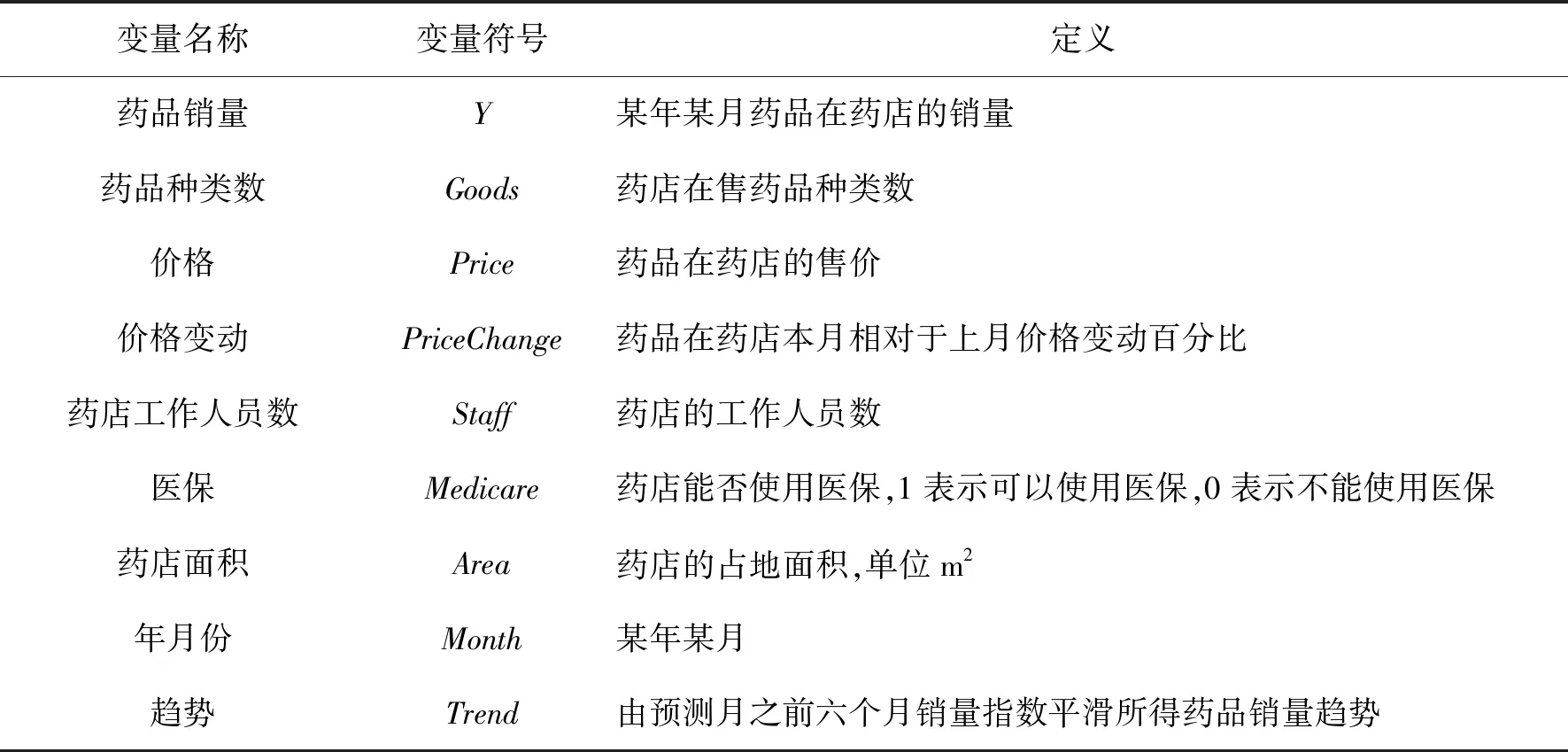
表1 变量定义
(二) 预测方法构建
市场之所以可以被预测,是基于马克思主义哲学的一个基本观点:世界是由物质组成的,物质是在不断运动的,通过不断的观察和实践,物质世界是可以被认识的。虽然有各种复杂的因素影响市场,时而也会有偶然因素作用于市场,但人们可以根据长时间的认识和实践,利用逐渐累积的丰富经验和知识,逐渐探索市场运作规律,借助各种先进的科学技术手段,根据市场发展的历史和现状,推演市场的未来走势。市场预测中的两条重要原理为相关原理和连续性原理。
相关原理是指市场中许多现象是相互关联的,市场预测的开展可以利用这种关联性。例如汽油的需求量和行驶的里程数有很强的关联性,若知道了未来将要行驶的里程数,就可以预测需要多少汽油,这就是市场预测的相关性原则。相关性原则体现了唯物辩证法因果联系的观点,唯物辩证法认为,客观世界的事物总是相互联系的,不存在孤立的事物,一个事物的变化总会引起另一事物的变化,它们构成了因果关系,利用事物的因果关系,就可以进行市场预测。本文选用的神经网络法便是遵循这个原理。
连续性原理是指事物的发展和市场的现象的具有一定的延续性,未来的需求是与过去的发展以及当下的现状息息相关的,可以根据市场的过去和现在预测市场的未来。市场预测中之所以贯穿了连续性原则,是因为一切社会经济现象都有它的过去、现在和未来,任何事物的发展都与过去有所联系,过去的行为不仅影响到现在,还会影响到未来。换言之,一切社会经济现象的存在和发展具有连续性。本文选用的指数平滑法便是遵循这个原理。
本文的研究目的是实现利用有限时间销量数据进行销量预测,在探究性实验中发现,用于预测的30个月的药品销量时间序列多呈现白噪声特征,故传统的ARIMA等时间序列分析模型作用不大;药品销量受到众多因素的影响,既有类型变量,又有数值型变量,且输出变量为数值型,典型的线性回归方法在处理较多的输入特征时不够健壮,故本文选择神经网络进行预测,它是一种能解决回归问题的方法,在处理更高维的输入特征空间时明显更为健壮。神经网络预测需要对影响因素进行比较全面的分析才会有一个比较良好的预测效果,但由于理论和现实的限制,穷尽所有影响因素是极其困难的,本文将趋势信息作为影响变量放入神经网络,以将部分未能穷尽的影响因素纳入考虑。在神经网络预测中高度相关的特征会导致预测损失精确度,故在正式预测之前,本文先利用主成分分析对规模变量和价格变量分别消除冗余。
本文模型由指数平滑、主成分分析和后向传播前馈神经网络三个部分组成。模型首先采用指数平滑获得销量的趋势信息,再采用主成分分析提取富含规模信息和价格信息的主分量,最后输入后向传播前馈神经网络进行预测。所有程序在RStudio中实现。下面将依次介绍模型的各个组成部分。
1.指数平滑获取趋势信息
本文首先利用指数平滑获取销量趋势信息,以此将未能穷尽的某些影响因素纳入考虑,如门店形象、门店位置等的影响,对于同一药房来说,这些因素往往在比较长的时间内保持恒定。趋势信息由预测月之前六个月销量数据指数平滑而得。
指数平滑是一种用过往观测值的加权和计算当期趋势的方法,因为对于一个时间序列{Xt},可以认为在一个比较短的时间间隔里序列值是相对稳定的,是随机波动造成了序列值之间的差异。根据我们的生活经验,对现在影响比较大的是近期的事件,那些远期的事件对目前的情况影响比较小,由于不同时间间隔对事件发展影响的不同,指数平滑法的各期权重是随时间间隔的增大而呈指数衰减的。指数平滑法如公式(1)所示。
xt(1)=αxt+α(1-α)xt-1+α(1-α)2xt-2+…
(1)
其中xt(1)是向前预测1期的预测值。平滑系数的α值一般根据经验给出,经验表明,α的值介于0.05~0.3之间效果比较好。为了取得趋势信息,在本文中,平滑系数取为0.3。
2.主成分分析消除冗余
主成分分析是一种常用的减少冗余信息,对数据进行降维的方法。在神经网络预测中高度相关的特征会导致预测损失精确度,故在正式预测之前,本文先利用主成分分析消除冗余。但是,若对所有变量一起进行主成分分析,相当于人为地以是否线性相关为依据缩减数据,可能会让信息受到过多损失,故本文对影响因素分类进行主成分分析,一方面消除冗余,另一方面尽量减少原有影响因素信息的损失。
主成分分析是通过线性变换把给定的一组变量X1,X2,…,Xk转换为一组两两相关系数为0的变量Y1,Y2,…,Yk。在这种变换中,保持X1,X2,…,Xk的方差之和相等,同时,使Y1具有最大方差,Y2具有次大方差,分别称为第一主成分和第二主成分。依次类推,原来有k个变量,就可以转换出k个主成分。
但在实际应用中,只需要找出小于k的q个主成分即可,找出的q个主成分需要反映出之前k个变量的绝大部分方差。本文参考Cattell碎石检验图选择q值。Cattell碎石检验绘制主成分数与特征值之间关系的图形,图形可以清晰地展示图形弯曲状况,在图形变化最大处之上的主成分都可保留。
本文对规模变量Goods、Staff、Area和价格变量Price、PriceChange分别进行主成分分析,以消除线性相关带来的冗余。
3.后向传播前馈神经网络综合预测
人工神经网络是一组连接的输入和输出单元,其中每个连接都与一个权重相关联,它因形态和作用原理类似于生物神经元而得名。虽然有很多种不同的神经网络,但是每种都可以由以下三个特征来定义:网络拓扑(或结构),描述了模型中神经元的数量以及层数和它们连接的方式;激活函数,将神经元的组合输入信号变换成单一的输出信号,以便进一步在网络中传播;训练算法,指定如何设置连接权重,以便减小或者增加神经元在输人信号中的比例。
本文选择后向传播前馈神经网络进行综合预测,神经网络的使用分为训练和预测两个阶段,相应的,实验中的样本被分为训练样本和预测样本。在训练阶段,调整人工神经元的连接权重 权重,使得它能够预测输入元组的正确输出,获得训练好的神经网络,在预测阶段,使用训练好的神经网络进行预测,并评估预测效果。
多层前馈神经网络由一个输入层、一个或多个隐藏层和一个输出层组成,多层前馈神经网络拓扑如图1所示。每个训练元组的观测属性同时进入到构成输入层的单元,这些输入通过输入层,经过加权同时进入到隐藏层,许多“类神经元”组成了隐藏层,一个隐藏层单元的输出可以输入到下一个隐藏层,诸如此类。最后一个隐藏层的输出加权后输入到构成输出层的单元。输出层输出给定元组的预测值。
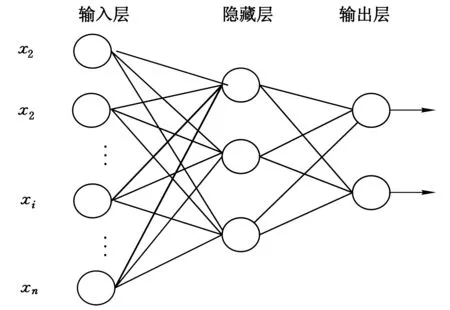
图1 多层前馈神网络拓扑
一个单一的“类神经元”如图2所示,它由一个有向网络图表示,每一个接收的输入信号(变量x)都根据其重要性被加权(w值),所有输入信号由“类神经元”求和,然后该信号被用f表示的激活函数作用并传递,最后得到输出信号(变量y)。

图2 单一的“类神经元”
本研究中使用S形激活函数(logistic激活函数),用公式(2)表示,公式中的e是自然对数的底(约为2.72)。S形激活函数的输出值可以落在0~1的任何地方。
(2)
本文使用的神经网络通过后向传播算法进行训练。后向传播算法通过“前向阶段”和“后向阶段”的多次循环实现。一开始,网络不包含任何信息,因此网络中的初始权重通常是随机设定,在RStudio中,这一过程由设置随机种子点实现,然后算法开始不断循环迭代,直至满足某一停止准则。后向传播算法的两个阶段具体为:(1) 在前向阶段,输入信号激活从输入层到输出层的“类神经元”,沿途应用每一个“类神经元”的连接权重和激活函数,一旦到达最后一层,就产生一个输出信号。(2) 在后向阶段,比较训练数据中的真实目标值和由前向阶段产生的输出信号的值,得到它们之间的差异即在网络中后向传播产生的误差,从而修正“类神经元”之间的连接权重,并减小将来产生的误差。后向传播算法采用梯度下降法确定权重需要改变多少。
由于神经网络要求所有输入是数值型的,对于分类变量,本文创建了一系列指示特征Ii作为输入变量,它的形式如公式(3)所示。变量值在0附近时神经网络的使用效果最佳,故预测前将所有变量标准化到了0~1的范围。
(3)
将价格变量主成分(由Price和PriceChange主成分分析而得)、规模变量主成分(由Goods,Staff和Area主成分分析而得)、Medicare、Month、Trend作为神经网络的输入变量进行预测。在实验过程中,先尝试不同的隐藏层配置,对每一种隐藏层配置种子点为1~50,以尝试不同的初始权重,然后选择各种初始权重下误差平方和(SSE)值最小的模型作为该隐藏层配置下的预测模型,最后,对比不同隐藏层配置的预测模型的预测效果,选择预测效果最好的隐藏层配置作为预测所用神经网络的配置。
(三) 效能测度
本文选用相关系数(R)和标准化均方误差(NMSE)来测度模型的预测效能,它们的定义如公式(4)(5)所示。其中P代表预测值,T代表真实值,Cov为协方差,Var为方差,mean为平均值。
(4)
(5)
相关系数是研究变量之间线性相关程度的量,相关系数越大,预测效果越好。标准化均方误差代表与真实值的平均值相比,预测值的预测效果,标准化均方误差越小,预测效果越好。
(四) 最终模型
综上所述,整体预测模型如图3所示。

图3 整体预测模型
综合来说,在预测中,首先,我们利用每月之前六个月(除去前六个月)的销量数据通过指数平滑获取销量趋势信息;之后,我们分别对价格变量(Price、PriceChange)和规模变量(Goods、Staff、Area)进行主成分分析获得价格变量主成分和规模变量主成分;然后,我们以Trend、价格变量主成分、规模变量主成分、Medicare、Month为自变量,药品销量为因变量,利用训练样本对神经网络进行训练,之后,利用训练好的神经网络对测试样本进行预测并评估效果,对于不同的隐藏层配置和不同的初始权重,对神经网络这一步骤进行重复并选定最好的方案;最后,评估选定的神经网络方案及整体预测方案的预测效能。
二、实证结果
按照前述研究设计,本文分别利用AB药房连锁有限公司的三九感冒灵、江中健胃消食片和苯磺酸左旋氨氯地平片2016年1月至2018年6月两年半的销量数据对2018年7月至2018年12月的销量以月为单位进行了预测。
在预测前,剔除含缺失值的数据,本文认为过大异常值产生于药房与集体的大单合作,根据箱线图剔除含异常值的数据,对于一个月内药价有调整的数据,以销量为权重合并数据,剔除数据缺失太多的药房,共获得24个药房的三九感冒灵、51个药房的江中健胃消食片和49个药房的苯磺酸左旋氨氯地平片36个月的销量数据。剔除了比较多的三九感冒灵的数据可能是因为集体购买这种药的情况比较多。全部数据均来源于AB公司内部数据库。
在预测中,对于每个月的数据(除去前六个月),均以本月之前6个月的销量数据的指数平滑值作为每个月的趋势值,用第7个月到第30个月总共24个月的影响因素数据和销量数据作为训练数据训练神经网络,利用训练好的神经网络根据影响因素数据对第31个月到第36个月的销量进行预测并评估预测效果。
在预测过程中,指数平滑通过R中的HoltWinters函数实现,以获得趋势信息;主成分分析通过R中的principal函数实现,根据主成分分析的结果,Goods、Staff、Area被合成为一个规模变量主成分Scale,Price和PriceChange被合成为一个价格变量主成分PricePlus;本文利用R中的neuralnet函数实现神经网络,经过多次尝试,隐藏层为单层一个节点的神经网络效果最好,这可能是由于将本身就具有预测效果的趋势值放入神经网络导致的,但是,加入其他影响因素的神经网络的预测效果比纯粹的趋势值的预测效果好很多,也比不使用趋势作为变量的神经网络预测效果好很多。各种药品的预测效果见表2。

表2 预测效果
根据实证结果,虽然只有两年半的数据用于预测,模型仍然取得了比较好的预测效果。三九感冒灵的预测值和真实值的相关系数达到了0.77,标准化均方误差为0.48,江中健胃消食片的预测值和真实值的相关系数达到了0.84,标准化均方误差为0.33,苯磺酸左旋氨氯地平片的预测值和真实值相关系数达到了0.85,标准化均方误差仅为0.30。并且由结果可知,训练样本数更多时,预测效果会更好。
三、结论与展望
本文提出了一种集成指数平滑、主成分分析、神经网络的销量预测模型。从整体结构上看,该模型具有指数平滑的趋势提取过程和分类别主成分分析的特征提取过程,是具有创新性的。而模型中的神经网络将影响因素和时间序列趋势同时纳入考虑,既克服了开业不久的零售药店和刚上市的药没有长时间销售数据进行ARIMA等时间序列分析的困难,又减弱了因果分析时难以穷尽所有影响因素的预测困境。为了验证模型的有效性,根据AB药房连锁有限公司24个药店的三九感冒灵、51个药店的江中健胃消食片和49个药店的苯磺酸左旋氨氯地平片2016年1月至2018年6月两年半的销量数据对2018年7月至2018年12月半年的销量以月为单位分别进行了预测,实证结果显示,三九感冒灵的预测值与真实值相关系数达到0.77,标准化均方误差为0.48,江中健胃消食片的预测值与真实值相关系数达到0.84,标准化均方误差为0.37,苯磺酸左旋氨氯地平片的预测值与真实值相关系数达到0.85,标准化均方误差为0.30,对于两年半的预测数据来说,取得了良好的预测效果。
综合来说,整体的预测模型如下:首先,利用指数平滑获得销量的趋势信息;然后,进行主成分分析提取富含规模信息和价格信息的主分量;最后,将趋势、价格变量主成分、规模变量主成分、医保、月份作为自变量,药品销量作为因变量进行神经网络的训练和预测。
文中模型的提出对于医药生产和经营企业具有现实意义。一方面,该预测模型有助于医药零售企业,特别是开业不久或销售新药的企业制定合适的库存量,减少库存积压和库存不足等问题的发生;另一方面,随着经济的不断发展以及供应链体系的不断完善,终端药品销量预测的实现也有助于供应链上每个节点企业相应优化自身的决策。
本文的局限性在于:(1) 所提出的预测模型更适用于连锁药店,药房数量越多,预测效果越好。(2) 由于AB公司数据库已有数据的限制,一些影响因素未纳入模型,例如竞争者价格、营销费用等,相关影响因素考虑得越全面,预测效果越好。在后续的研究中,可以改进神经网络算法,实现只将趋势值输入最后一层隐藏层的神经网络,以消除趋势值与其他影响因素线性相关的影响,这是改进预测效果的一种可能尝试。
猜你喜欢
中国合理用药探索(2022年1期)2022-11-26 00:22:32
肝博士(2022年3期)2022-06-30 02:49:06
当代水产(2021年7期)2021-11-04 08:17:32
汽车观察(2019年2期)2019-03-15 06:00:12
天津诗人(2017年2期)2017-11-29 01:24:31
中国卫生(2016年5期)2016-11-12 13:25:28
家用汽车(2016年4期)2016-02-28 02:23:37
中国卫生(2015年5期)2015-11-08 12:09:48
中国卫生(2014年7期)2014-11-10 02:33:02
健康必读(2012年7期)2012-04-29 00:44:03
