
Data mining-based model and risk prediction of colorectal cancer by using secondary health data:A systematic review
2020-05-17 07:28:26HailunLiangLeiYangLeiTaoLeiyuShiWuyangYangJiaweiBaiDaZhengNingWangJiafuJi
Hailun Liang,Lei Yang,Lei Tao,Leiyu Shi,Wuyang Yang,Jiawei Bai,Da Zheng,Ning Wang,Jiafu Ji
1School of Public Administration and Policy,Renmin University of China,Beijing 100872,China;2Key Laboratory of Carcinogenesis and Translational Research(Ministry of Education/Beijing),Beijing Office for Cancer Prevention and Control,Peking University Cancer Hospital&Institute,Beijing 100142,China;3Department of Public Policy,City University of Hong Kong,Hong Kong SAR,999077,China;4Johns Hopkins Primary Care Policy Center,Baltimore,MD 21205,USA;5Department of Neurosurgery,Johns Hopkins Medicine,Baltimore,MD 21205,USA;6Department of Biostatistics,Johns Hopkins Bloomberg School of Public Health,Baltimore,MD 21205,USA;7Department of Computer Science,Johns Hopkins Whiting School of Engineering,Baltimore,MD 21205,USA;8Key Laboratory of Carcinogenesis and Translational Research(Ministry of Education/Beijing),Center of Gastrointestinal Surgery,Peking University Cancer Hospital&Institute,Beijing 100142,China
Abstract Objective:Prevention and early detection of colorectal cancer(CRC)can increase the chances of successful treatment and reduce burden.Various data mining technologies have been utilized to strengthen the early detection of CRC in primary care.Evidence synthesis on the model’s effectiveness is scant.This systematic review synthesizes studies that examine the effect of data mining on improving risk prediction of CRC.Methods:The PRISMA framework guided the conduct of this study.We obtained papers via PubMed,Cochrane Library,EMBASE and Google Scholar.Quality appraisal was performed using Downs and Black’s quality checklist.To evaluate the performance of included models,the values of specificity and sensitivity were comparted,the values of area under the curve(AUC)were plotted,and the median of overall AUC of included studies was computed.Results:A total of 316 studies were reviewed for full text.Seven articles were included.Included studies implement techniques including artificial neural networks,Bayesian networks and decision trees.Six articles reported the overall model accuracy.Overall,the median AUC is 0.8243[interquartile range(IQR):0.8050−0.8886].In the two articles that reported comparison results with traditional models,the data mining method performed better than the traditional models,with the best AUC improvement of 10.7%.Conclusions:The adoption of data mining technologies for CRC detection is at an early stage.Limited numbers of included articles and heterogeneity of those studies implied that more rigorous research is expected to further investigate the techniques’effects.
Keywords:Systematic review;colorectal cancer;disease detection;data mining
Introduction
Globally,colorectal cancer(CRC)is the third most commonly diagnosed malignancy and the second leading cause of cancer death in the world,accounting for more than 1.8 million new cases and 900,000 deaths in 2018(1,2).The global burden of CRC is expected to increase by 60% by 2030(3).However,the burden of CRC can be reduced through prevention and early detection(4).Screening aims to identify individuals who are asymptomatic for the CRC and refer them promptly for diagnosis and treatment(5).Several screening tests have been developed and implemented to help doctors find CRC early,including both visual examinations(such as colonoscopy and sigmoidoscopy),and stool-based tests(like guaiac-based fecal occult blood test).The US Preventive Services Task Force’s(USPSTF)updated recommendations in 2016 and recommended screening for CRC starting at age 50 years and continuing until age 75 years(6).Despite the availability of several effective options and proven benefit,a large fraction of eligible people does not participate in CRC screening programs(7).Possible reasons included an undifferentiated screening approach implemented to all average-risk persons and relatively greater time commitment over a short period required for examinations(6).
It is conceivable that the all average population could be stratified across a spectrum of predicted risk levels depending on the presence or absence of risk factors(8,9).Multiple demographic and clinical risk factors for CRC have been identified,such as age,gender,race,family history and behavioral risk factors(2).Moreover,several models that use these risk factors have been developed to predict the risk of CRC(8-11),which could be used to tailor the CRC screening schedules of people considered at average risk,and thus to optimize both outcomes and allocation of screening resources(12-14).
With advantages in data sizes and a large number of potential predictor variables,secondary data,such as electronic health records(EHR)and medical claims data,have been increasingly utilized to build and validate risk prediction models(15).The growing availability of health care datasets facilitates the development of analytic tools to stratify the population with average risk and prioritize patients at high risk of having CRC.Simple approaches based on single red flag symptoms,risk scores or indexes built on symptom complexes are likely to miss discrimination and calibration(16,17).Recent advances in population data and data science technologies have offered automated methods to extract information from large secondary datasets to identify individuals at increased risk,thereby potentially enhancing early detection of CRC at primary care settings.
Data mining analysis is the process to extract implicit,previously unknown and potentially useful patterns from data,which is also referred to as knowledge discovery in databases(18-20).Various data mining methods have been utilized for the detection of CRC(21,22).The mining makes powerful algorithms that can model previously unknown relationships in complex secondary datasets,and adapt to dynamic data environments(23).Undoubtedly,data mining approaches in CRC are of great concern when it comes to early detection,prevention,management and other related clinical administration aspects.Hence,in the framework of this study,efforts were made to review the current literature on data mining approaches in CRC risk prediction.
Materials and methods
Search strategy
A systematic search for journal article was conducted in March 2018 on four electronic database:PubMed,Cochrane Library,EMBASE and Google Scholar.The specific search strategy was as follows:(“data mining”[Title/Abstract]OR“machine learning”[Title/Abstract]OR“data driven”[Title/Abstract]OR“algorithm”[Title/Abstract]OR“text mining”[Title/Abstract]OR“natural language processing”[Title/Abstract]OR“support vector machines”[Title/Abstract]OR“decision trees”[Title/Abstract]OR“Bayesian networks”[Title/Abstract]OR“artificial neural networks”[Title/Abstract])AND(colorectal cancer[Title/Abstract]OR oncology[Title/Abstract]OR neoplasms[Title/Abstract]).
Definition of data mining
Data mining is described as the process of selection,exploration,and modeling of a large database to discover unknown models or patterns(21).Typical data mining algorithms include decision trees,naive Bayes classifiers,support vector machine,and artificial neural network,etc.There is an apparent difference between a data mining model and a traditional prediction model.As depicted inFigure 1,in a traditional prediction program,the prediction model is given which will produce the desired output when entering some particular input variables.While in a data mining process,computer algorithms will generate a series of rules when simultaneously specifying input and output variables(22).
Study selection
Figure 2describes the selection process of the included articles.Initial records were transferred to the reference management software Endnote 8.0(Thomson ResearchSoft,Stanford,USA),and duplicates were excluded automatically.Then two independent investigators(HL and LT)identified articles by reading the title and abstract and assessed them according to the following selection criteria:1)articles related to CRC;2)using data mining methods,such as decision trees,random forests and deep neural networks;and 3)theoretical articles are excluded.Any disagreements were resolved through discussion among investigators.
Articles that meet these selection criteria would be kept for the next full-text screening stage.Two investigators read the full texts of the remaining articles to assess them based on the following criteria:1)research should be limited to cancer prevention or prediction,hence we excluded articles aiming at cancer treatment or diagnosis;2)we included studies that use any single or combined aforementioned data mining models;and 3)a prediction model in detecting CRC must use at least one of the three types of features as input variables,including clinic features,imaging features,and molecular features(24).For the data availability in the primary care settings,we only select the models based on clinic and treatment features.
Data synthesis and analysis
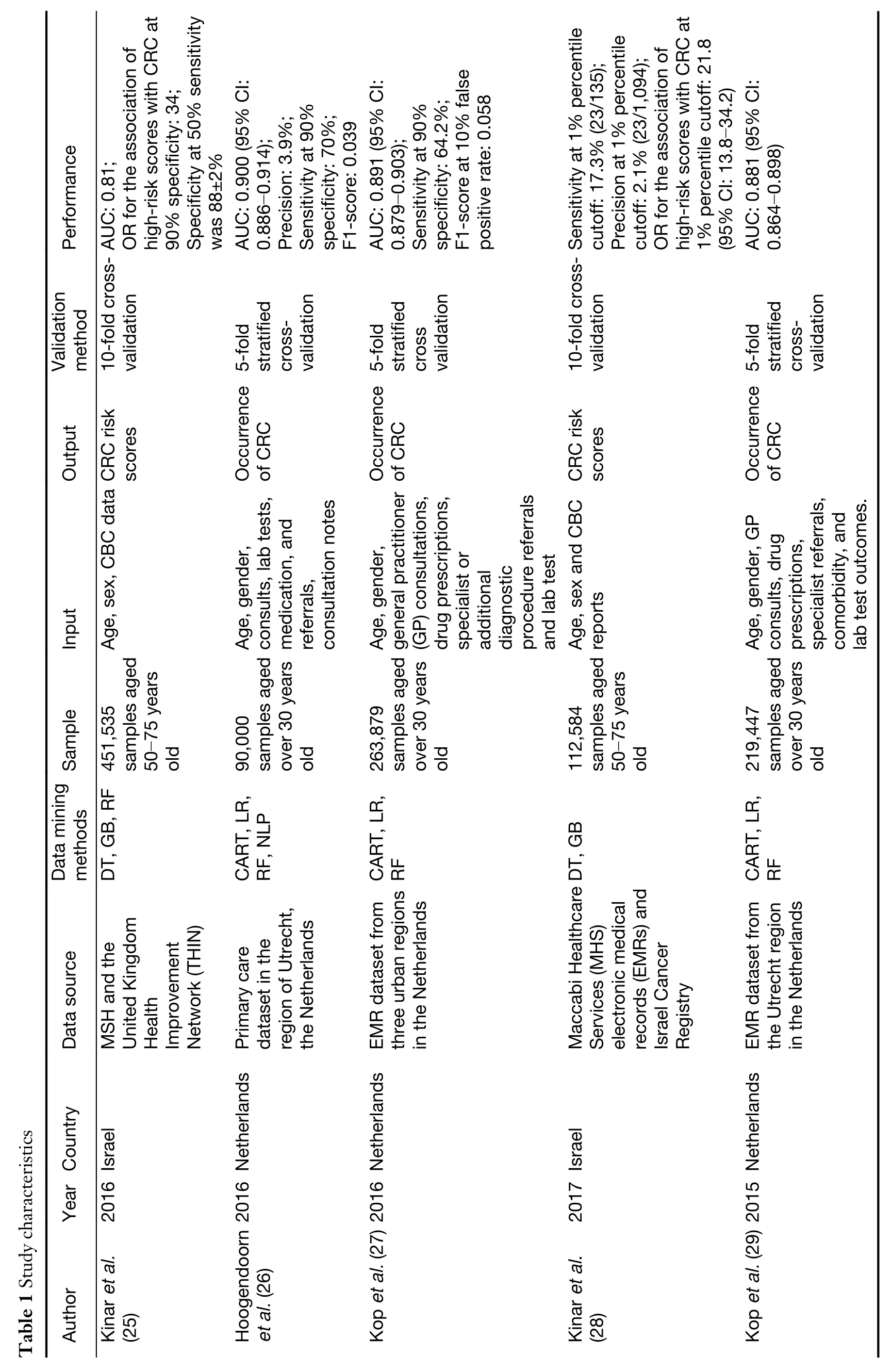

Data extraction was conducted by two investigators(HL and LT).For each article,we extracted information shown inTable 1.Due to the high heterogeneity for quantitative analysis,descriptive statistics were presented for each included study.Moreover,we compared the values of specificity and sensitivity and computed the median of overall area under the curve(AUC)of included studies,which was a common index to evaluate the performance and accuracy of the data mining model(22).We select the AUC value to evaluate the existing data mining model for CRC prediction based on the following considerations:First,although precision and recall are considered as two single indicators in practice,simply employing the above two indicators will cause great robustness problems.That is,when the data mining threshold setting was adjusted,the value of precision and recall indicators will be changed accordingly.However,AUC is not affected by its absolute value,which makes the evaluation of the classification ability of the model more robust.Secondly,the AUC value is obtained by calculating the sensitivity and specificity of each sample,which is independence from prevalence of abnormality.The prevalence of CRC is very small.In other words,the imbalance of positive and negative samples is significant in CRC patients.We believe that using AUC as a comprehensive index for evaluating the prediction performance of machine learning models for CRC is appropriate.In fact,AUC is also the focus of the existing literature.
Results
Results of search
We initially identified 1,043 citations based on our search criteria and obtained 25 citations from other sources,including theses,preprints and working papers.As described inFigure 2(PRISMA form),after removing duplicate articles,a total of 643 articles were left.First,we reviewed the title and abstract of each article,327 were excluded.In the next stage,we reviewed the full text of the remaining 316 articles,and 309 studies were excluded from them,leaving a total of 7 articles.Articles that are unrelated to CRC prevention or prediction,or that use the image and genetic techniques for modeling,or that are unable to identify one of the data mining methods were excluded.
Study characteristics
We finally included a total of 7 articles on predicting CRC using data mining techniques.As shown inTable 1,these articles mainly originated from four countries including the United States,Israel,the United Kingdom and the Netherlands.The sample sized ranged from 90,000 to 451,535,representing more than 500,000 people.The time span was from 2015 to 2017.
With regard to the data mining methods,both supervised learning and non-supervised learning algorithm were employed among the included studies.The most commonly used data mining approaches are decision trees,random forests,and natural language processing.A large number of studies selected more than one algorithm for predictive modeling(25-28).In terms of types of data source,databases were mainly from highly reliable national databases or hospital clinical data systems,such as the Macabbi Health Services(MHS)EHRs,the Israel Cancer Registry,the Kaiser Permanente Northwest Region(KPNW)EHRs,and Clinical Practice Research Datalink(CPRD)dataset.Using the validation process is a common way to increase the robustness of the data mining model.Cross-validation was specified in all articles.The most frequently used validation procedure is the 5-fold and 10-fold validation method.
Overall prediction performance
A total of six articles reported the overall model accuracy(25-27,29-31).Several performance indicators included AUC,precision,recall and odds ratio measure to compare the CRC prevalence of individuals whose model score is above or below the threshold.In this review,we calculated the median AUC of these six studies.Overall,as shown inFigure 3,the median AUC is 0.8243[interquartile range(IQR):0.8050−0.8886;range:0.776−0.900].
Four articles used age,gender and blood data from the complete blood count reports as features(25,28,30,31),and the output was the risk scores to assess the probability of having CRC among the suspected population.And three out of the five articles reported the overall AUC,ranged from 0.776 to 0.810.Three included articles used the same data mining algorithms developed by a Dutch team(26,27,29).Their input features included not only formatted data such as gender,age,but also unformatted forms of physician consultation and notes.The output is the probability for a patient to have CRC.The AUC ranged between 0.881 and 0.900.Due to the different sample sizes,the F1-score was particularly larger than the other two articles,with 0.058 in Kopet al.(27)and 0.074 in Hoogendoornet al.(26).
Model performance by using subsets of samples
Three included articles reported model performance(25,30,32).For the gender subsets,three articles reported performance differences.In Hornbrooket al.(31),the odds ratio for association of a high-risk detection score with CRC was 39.6[95% confidence interval(95% CI):30.3−50.6]for women and 31.5(95% CI:24.3−39.5)for men at 99% of specificity,respectively.Similarly,Kinaret al.(28)found in the Israeli dataset,the odds ratio between men and women is 1:1.15.
In terms of follow-up time subsets,three articles reported performance at different follow-up times.In Hornbrooket al.(31),the odds ratio of detection of CRC in patients with a specificity of 99% was 34.7 in the window of 0−180 days,while was 20.4 in the window of 181−365 days.Birkset al.(30)also detected AUC in the UK dataset was 0.844(95% CI:0.839−0.849)for the 90−180 days’vs.0.813(95% CI:0.809−0.818)for the 180−360 days’window at the 99.5% specificity level.
Comparison with other models
Two articles compared data mining models with different traditional models including logistic regression estimation,Bristol-Birmingham equation and passive learning(27,29).Kopet al.(27)found that the AUC of the data mining algorithm model was higher compared with the traditional model,with a value of 0.891(95% CI:0.879−0.903)and 0.864(95% CI:0.851−0.877),respectively.The similar results were also found in the Kopet al.(29)study.The AUC is 0.881(95% CI:0.864−0.898)and 0.796(95% CI:0.775−0.817)in random forest and regression model respectively,which shows the performance of random forest is 10.7% higher than regression.Overall,in the above two articles,the data mining method performed better than the traditional models,with the best AUC improvement of 10.7%.
Discussion
This systematic review summarizes the available CRC risk prediction models using data mining methods.One of the main strengths of this study is the broad search strategies and the systematic approaches used to identify studies and extract data.A total of six articles reported the overall accuracy of a model.The discriminatory power of the most currently available models is relatively high.The median AUC 0.8243(IQR:0.8050−0.8886)represents,therefore,a summary of overall performance.In the two articles that reported comparison results with traditional models,the data mining method performed better,with the best AUC improvement of 10.7%.In terms of quality of included studies,all included articles were in high quality based on the Downs and Black’s quality checklist,and most models were cross-validated.This may conclude the tendency for current research into CRC risk prediction tools to focus not only on model development,but also validation and impact in clinical practice.
Data mining already has been well studied in many areas of clinical research.Several reviews have evaluated the application of data mining for prediction tasks(32-35).Cruz and Wishart(33)estimated that the data-driven approach substantially improves the accuracy of predicting cancer mortality and recurrence.Abbodet al.(34)reviewed and found that the application of artificial intelligence performed well for improving the diagnosis,staging and prognostic prediction of urological cancers.Kanget al.(35)presented a review of the use of machine learning and data mining to predict clinical outcomes in radiation oncology therapies but did not conclude an overall evaluation of models’performance.For CRC,evidence suggests that high-risk individuals are more likely to adhere to physician recommendations and receive CRC screening.Thus,identifying a high-risk group could optimize both outcomes and allocation of screening resources.The data mining-based risk models identified in this review have the potential to improve the early detection of CRC by helping health care providers to identify those patients presenting with risk of possible CRC,in whom further screening and examination are most appropriate.The potential advantages of risk prediction models in this context were that the included features were risk factors rather than symptoms,which were easily obtainable variables in many secondary datasets.These variables could be easily incorporated into practice.Moreover,these models overcome the limitations of symptom-based models,in which symptoms may present only at an advanced stage of CRC.
In contrast with certain other cancers with a single dominant risk factor,there is no single dominant predictor of CRC risk.In the absence of a single dominant risk factor,data mining is likely to remain the most powerful prediction method to identify the risk of developing the disease for population at average risk.In terms of the features selected through data mining models,gender and age are the most retained CRC risk factors,though no univariate associations have been reported.Three articles reported performance differences between the female and male subset of samples,but the results were mixed with respect to sensitivity and the positive predictive value of an abnormal score.Moreover,features related to blood count also seem to be another very crucial feature utilized in predicting CRC risk,since unexplained iron deficiency anemia due to bleeding is a“red flag”for CRC risk,especially among the elderly.
The overall results implied that a wide variety of data mining algorithms and techniques are used in the field of risk prediction of CRC.Included studies appeared to implement techniques almost all of the common known classification algorithms.However,the most commonly used ones are random forests and decision trees.A lot of articles used supervised learning approaches.More specifically,in all included research articles,the identified subsets of features were evaluated through appropriate procedures as splitting the dataset into train and test sets or through cross-validation.Moreover,after the feature selection,investigators have conducted comparative analysis on different data mining algorithms to compare the predictive performance and finally choose the most efficient one.The possible reason is likely that the accuracy of an algorithm depends heavily on the type of data dimensionality and origin(21).
Our study has limitations.First,non-English language studies were excluded,which could lead to language bias.Additionally,the methodological heterogeneity of the identified studies did not allow for meta-analysis.Furthermore,due to the limitation of the secondary dataset,models concerning the genetic background and environmental factors affecting the onset and progression of the disease were beyond the scope of the current study.Last,it should be cautious when applying our synthetic evidence to guide the real-world practice.AUC,the indicator that we selected to assess the overall performance of data mining model,may not be good enough to meet the needs of the clinical practice,as a high specificity is usually the priority to be secured for CRC screening.
It remains to be defined what role the currently emerging models can have,and what barriers existed to the incorporation of a data-driven CRC risk prediction model into practice.First,it is imperative for data mining studies that a dataset be sufficiently large for the algorithm to be trained appropriately.Furthermore,models are needed to be validated in diverse populations.Current studies rely largely on the health records or clinic data from the hospital,which makes the data mining model in CRC prediction only take effects among the hospital population rather than at the community-level.There is still a big gap between computer simulation based on hospital clinical data and the application of data mining methods in the real community setting.Additionally,ethical frameworks should be created to support the collection of training data and validation on heterogeneous settings before deployment.Although data mining models may become a valuable aid for clinical decision making,we do not foresee that data-driven algorithms replace human judgment.Rather,data mining has great potential as a complementary source of information to help guide the process of trusting decision making.
Conclusions
In this systematic review of data-driven risk prediction models for CRC in asymptomatic populations,a systematic effort was made to identify and review models that have been developed by using data mining to predict CRC risk.Many of these have shown better discrimination and accuracy,and most contain variables are easily obtainable.Moreover,many models have been validated in external populations,indicating that it is robust and applicable to populations from different countries.The current study showed machine learning-based algorithms were superior to the traditional ones,however,further research is still needed before these models can be incorporated into routine clinical practice.The advent of medical science and informatics is expected to give rise to further in-depth exploration toward early detection and prevention of CRC.
Acknowledgements
This work was supported by the National Natural Science Foundation of China(No.71804183).
Footnote
Conflicts of Interest:The authors have no conflicts of interest to declare.
 Chinese Journal of Cancer Research2020年2期
Chinese Journal of Cancer Research2020年2期
- Chinese Journal of Cancer Research的其它文章
- Evaluation and reflection on claudin 18.2 targeting therapy in advanced gastric cancer
- Oncometabolic surgery:Emergence and legitimacy for investigation
- Nomogram for prediction of pathologic complete remission using biomarker expression and endoscopic finding after preoperative chemoradiotherapy in rectal cancer
- Phase 1/2 study of concurrent chemoradiotherapy with weekly irinotecan hydrochloride for advanced/recurrence uterine cancer:A multi-institutional study of Kansai Clinical Oncology Group
- p16/Ki-67 dual-stained cytology used for triage in cervical cancer opportunistic screening
- Analysis and external validation of a nomogram to predict peritoneal dissemination in gastric cancer