
融合多种语言学特征的维吾尔语神经网络命名实体识别
2020-05-16 06:46杨雅婷蒋同海
计算机应用与软件 2020年5期
董 瑞 杨雅婷 蒋同海
1(中国科学院新疆理化技术研究所 新疆 乌鲁木齐 830011)2(新疆民族语音语言信息处理实验室 新疆 乌鲁木齐 830011)3(中国科学院大学 北京 100049)
0 引 言
随着互联网的普及和发展,网络成为了每个人生活中不可缺少的部分,咨讯信息、新闻媒体、社交网络充斥在每个人的身边,维吾尔语文本信息增长飞快,因此维吾尔语自然语言处理研究变得越来越重要。命名实体识别是自然语言处理的基础任务,命名实体识别任务是从自然语言文本中识别出具有特点属性和意义的实体,并加以分类。随着深度学习在自然语言处理中的深入研究,神经网络模型已经开始应用于命名实体识别,相对于统计机器学习的命名实体识别,神经网络模型能够减少人工选择特征、人工构建模板这个复杂的特征工程,并且取得了不错的效果。但是维吾尔语属于阿尔泰语系突厥语族西匈语支,在语法结构上属于黏着语,单词是由词干附加若干词缀构词,形态非常丰富。由于其丰富的形态特征,仅仅通过神经网络模型自动提取的特征,无法获得全面有效的文本表示。相对于仅使用神经网络模型自动提取特征,本文提出的融合多种语言学特征的神经网络模型,在维吾尔语命名实体识别任务上取得了更好的识别效果。
1 相关工作
1991年Rau在第7届IEEE人工智能应用会议上提出命名实体的概念之后,信息理解会议(Message Understanding Conference,MUC)、内容自动提取(Automatic Content Extraction,ACE)的评测推动着命名实体识别研究的发展。国家高技术研究发展计划“中文信息处理与智能人机接口技术评测”以及SIGHAN(计算语言学协会特别兴趣小组,研究中文自然语言处理)的BAKEOFF评测都对中文命名实体识别的发展起到了促进的作用。
传统的基于统计机器学习的命名实体识别算法,例如SVM、HMM、CRF,为了获取更高的识别性能,需要进行大量的特征工程,人工定义特征,生成特征模板,识别算法的成功与否和研究者设置的特征模板息息相关。通常这些人工挑选的特征都是和语言相关的。例如,对于英语来说,文本中的命名实体词需要首字母大写,这一特征就非常重要,但是对于汉字和维吾尔语字母没有大写特征,因此针对不同语种的命名实体识别任务,选择合适的语言学特征就变得非常重要。
随着深度学习在自然语言处理的深入研究,词向量通常作为神经网络模型的输入层,在不同自然语言处理任务中都能够取得非常好的效果。词向量是在无标注大规模文本上无监督训练获取的,能够表达部分语义信息和上下文关系。Collobert等[1]为了减少特征工程的工作量,使用CNN-CRF神经网络模型进行命名实体识别任务,取得了不错的效果。Chiu等[2]在Bi-LSTM基础上,联合词向量和CNN提取的字符特征作为输入向量进行命名实体识别,实验表明CNN提取的字符特征能够更进一步的丰富命名实体的文本表示。但是使用Bi-LSTM进行命名实体识别时,输出层通常使用Softmax作为激活函数,将命名实体识别任务看作一个文本分类任务,这样做的前提假设是输出类别之间相互独立,但是命名实体识别输出的实体类别标签是相互关联的。例如某个单词的输出实体标签是I-LOC,那么它的上一个单词一定是B-LOC或者I-LOC,而不能是B-ORG。为了解决输出实体类别序列间的关系依赖问题,黄志恒等[3]提出了一种使用Bi-LSTM-CRF的网络结构,将Bi-LSTM的输出向量连接到CRF层,取得了不错的效果,但是没有加入CNN进行字符特征提取。Ma等[4]在Bi-LSTM-CRF的基础上,使用CNN提取每个单词的字符特征,然后将字符特征和词嵌入拼接在一起作为输入向量,使用Bi-LSTM-CNN-CRF在CONLL2003数据集上取得了最优的识别结果。
维吾尔命名实体识别研究开始比较晚,从基于规则的人名翻译开始[5-7],到使用规则和统计的方法进行维吾尔语人名识别[8],再到使用统计机器学习的方法进行维吾尔语人名识别[9-10],以及分别针对机构名、地名、和数词进行识别[11-15]。大部分针对维吾尔语命名实体识别的研究者都使用条件随机场作为序列标注算法[16]。近期一些学者也开始使用神经网络的方法进行命名实体识别研究[17-18],但是目前还没有开放的数据集以及公开评测项目。
2 神经网络结构
2.1 词向量
文本使用Word2vec进行维吾尔语词向量的训练,训练语料为298万句维吾尔语单语语料,共1 921 477个单词。使用CBOW计算词向量,词特征窗口大小为8,最小词频为1,详细内容见表1。

表1 词向量参数设置
2.2 CNN抽取字符特征
卷积神经网络(Convolutional Neural Networks,CNN)是一种常用的神经网络结构。在自然语言处理中,常使用CNN来提取文本特征,并且有研究者发现,使用CNN抽取字符级特征,能够很好地表示单词的形态学特征。图1为本文模型中抽取字符特征的网络结构,“suyimen”是拉丁维语“我喜欢”的意思。

图1 CNN抽取字符特征
本文设置字符向量维数为30,并且进行随机初始化。每个单词的最大字符长度为50,如果超过最大长度,就截取前50个字母,如果长度小于50,就使用Padding进行补齐。通过卷积层和最大池化层,抽取单词的字符特征表示向量。卷积核尺寸为30,卷积核长度为3。
2.3 语言学特征向量
维吾尔语属于阿尔泰语系突厥语族西匈语支,在语法结构上属于黏着语,维吾尔单词是由词干附加若干词缀构成,有着丰富的形态学特征。由于这种复杂形态,CNN很难完全抽取所有的形态学特征,并且维吾尔语的每个词缀还有自己的词性特征。借鉴于统计机器学习的维吾尔语命名实体识别研究,我们设计了一组维吾尔语语言学特征,见表2。

表2 语言学特征说明
例如拉丁维语单词oquyalmidim(汉语意思:我不会读),切分成词干附加词缀的形式为:
oquyalmidim->oqu+yala+ma+d+im
其中:oqu是词干,yala是第一个词缀,ma是第二个词缀,d是第三个词缀,im是第四个词缀,每个词缀有不同的词性。这个维吾尔语单词的语言学特征就可以用表3表示。
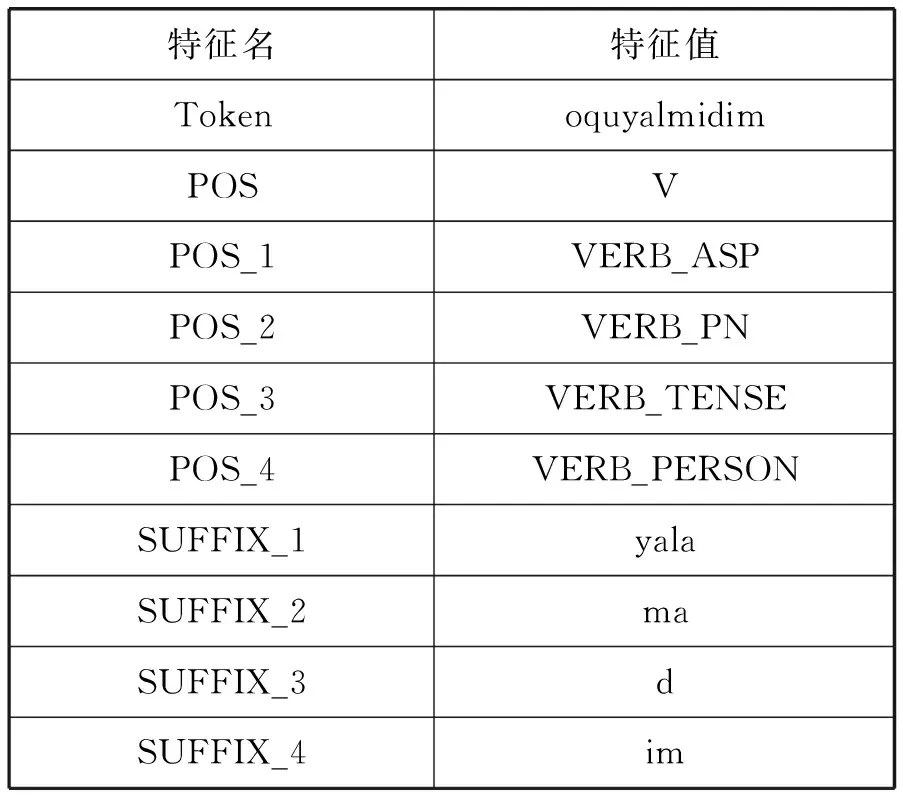
表3 维吾尔语单词语言学特征示例
设置每个语言学特征的向量维数为30,随机初始化向量。
2.4 联合向量表示
将词向量、字符特征向量以及语言学特征向量级联作为神经网络的输入向量表示。假设Vword表示词向量,Vchar表示字符特征向量,Vfi表示表2中的第i个语言学特征向量,整体输入向量就可以表示为V=[Vword:Vchar:Vf1:…:Vf10],结果如图2所示。

图2 联合特征表示
2.5 Bi-LSTM
(1) LSTM。循环神经网络(Recurrent neural network,RNN)的网络结构在自然语言处理中得到了广泛的应用。对于命名实体任务来说,RNN的输入层就是词向量,输出层就是命名实体类别序列。RNN网络有一个很大的缺点就是长期依赖问题,对于过长的神经网络序列,很难保留很久之前的输入信息。为了解决这个问题,Hochreither等设计了长短期记忆网络(Long short term merroy,LSTM),通过三个特殊的门结构来控制输入和输出信息。图3为一个LSTM单元的基本结构。

图3 LSTM单元基本结构
LSTM更新公式如下:
it=σ(Wxixt+Whiht-1+Wcict-1+bi)
(1)
ft=σ(Wxfxt+Whfht-1+Wcfct-1+bf)
(2)
ct=ftct-1+ittanh(Wxcxt+Whcht-1+bc)
(3)
ot=σ(Wxoxt+Whoht-1+Wcoct-1+bo)
(4)
ht=ottanh(ct)
(5)
式中:σ是Sigmoid激活函数;i是输入门;f是遗忘门;c是记忆单元;o是输出门;h是隐层;tanh表示双曲正切激活函数;W是权重矩阵,例如Wxi是输入x到输入门之间的权重矩阵,Whi是隐层到输入门的权重矩阵,b是偏置向量。
2.6 CRF
条件随机场(Conditional Random Fields,CRF) 是在给定一组输入随机变量条件下,另外一组输出随机变量的条件概率分布模型。使用Softmax激活函数作为输出层的前提假设是输出类别直接相互独立,类别之间没有约束。但是对于命名实体识别任务来说,输出类别之间是有约束关系的。而CRF可以很好地对这种类别间关系进行约束,因此使用CRF层和Bi-LSTM的输出向量连接在一起进行命名实体识别任务。
2.7 多特征融合的Bi-LSTM-CNN-CRF模型
将词向量、字符特征以及语言学特征连接在一起作为输入向量,将BLSTM的输出向量和CRF层相连,构成融多种合语言学特征的Bi-LSTM-CNN-CRF神经网络模型,整体结构如图4所示。
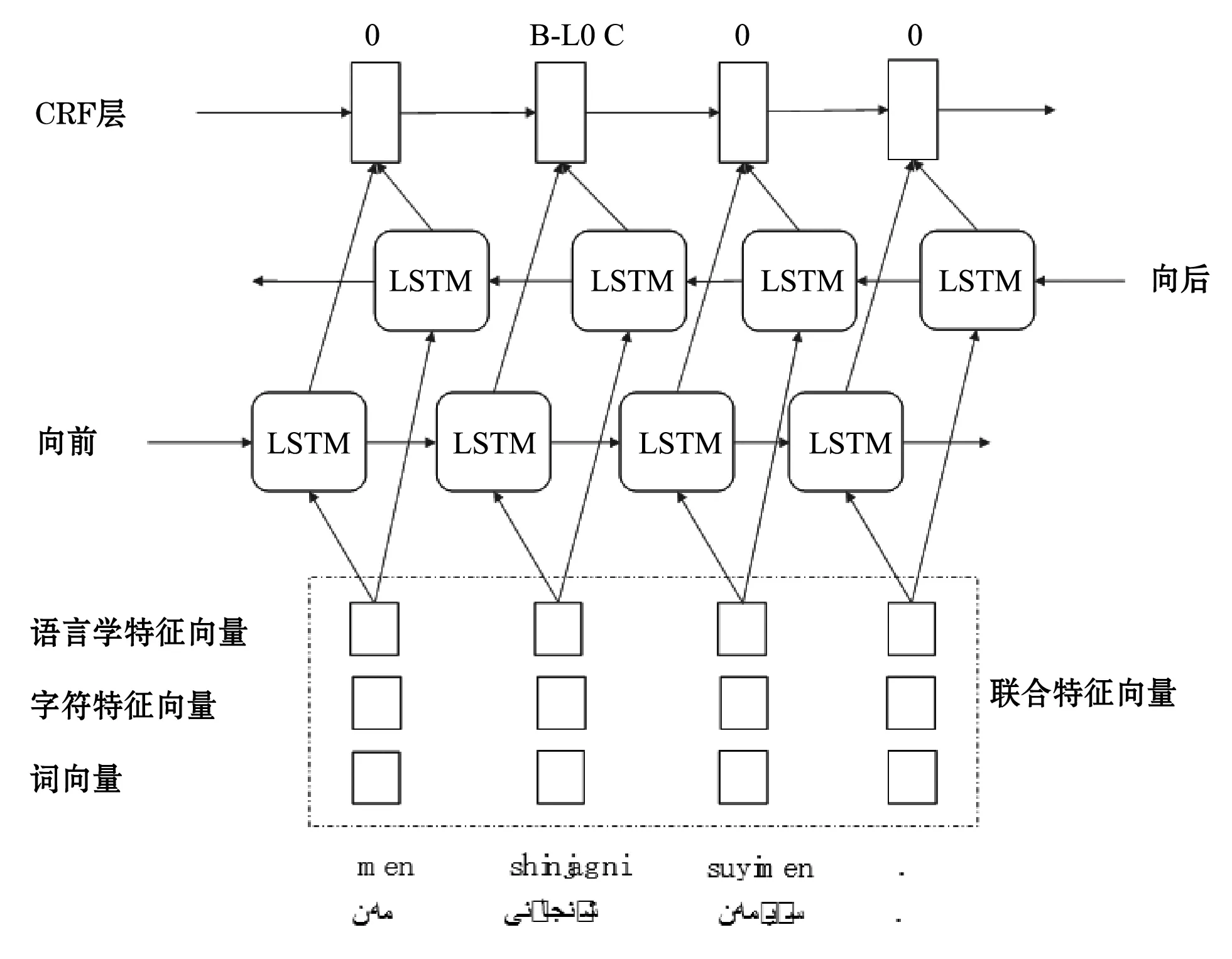
图4 融合多语言学特征的神经网络模型结构
每一个输入的维吾尔语单词,将其词向量和CNN提取的字符特征向量以及经过形态学分析得到的语言学特征向量拼接到一起,作为Bi-LSTM网络的输入向量,最后再将Bi-LSTM的输出向量和CRF层相连。
3 实 验
3.1 标注规范
本文使用BIO标注规范,命名实体类别包括三类:人名、机构名和地名。具体定义如表4、表5所示。

表4 BIO标注含义
表5 命名实体识别类别说明
3.2 训练语料
由于维吾尔语命名实体识别任务,没有公开发布的标注数据集,因此本文使用中科院新疆理化所标注的维吾尔语命名实体识别语料。详细信息如表6所示。

表6 训练语料说明
3.3 评测指标
本文使用精确率P、召回率R、F1值来进行评测。具体公式如下:
(6)
(7)
(8)
3.4 实验结果及分析
为了验证加入语言学特征是否能够提高维吾尔语命名实体性能,本文进行了多组对比实验,使用不添加任何语言学特征的Just_token作为基线系统。
(1) 实验一:分别使用每个语言学特征,将其添加到神经网络模型中进行对比,结果如表7所示。

表7 多种语言学特征对比实验结果 %
从实验结果看,对比不添加任何语言学特征直接使用Bi-LSTM-CNN-CRF,大部分添加的语言学特征的模型可以取得更好的识别结果,但是对于仅使用Pos4、suffix4这两种语言学特征,识别结果并没有基线系统高。为了确定这几种语言学特征是否有效,进一步进行实验验证。
(2) 实验二:对于Pos4特征,为了确定这个语言学特征是否对维吾尔语命名实体识别有用,我们将Pos1-Pos4这四种特征同时添加到神经网络模型中,用来比较添加Pos4特征后,是否对整体命名实体识别任务有帮助,实验结果见表8。
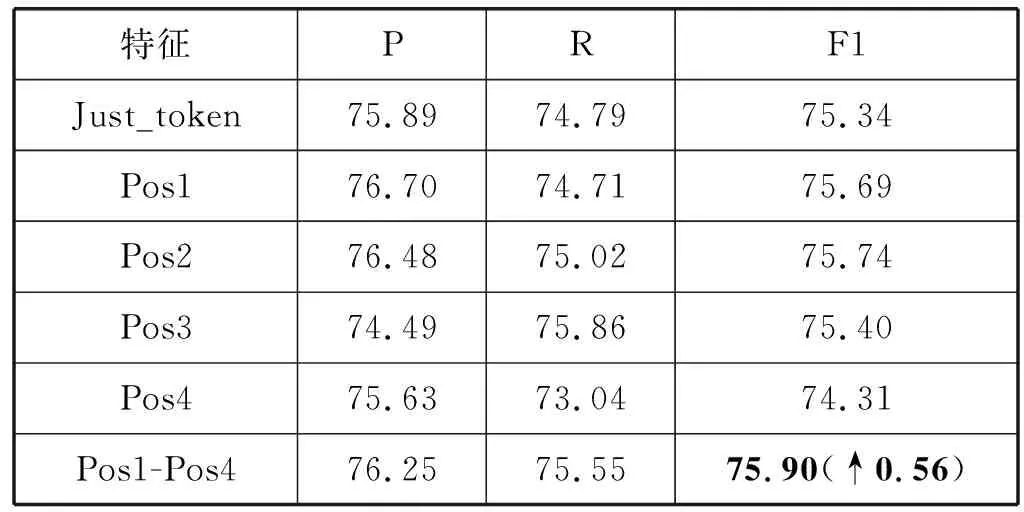
表8 融合所有词缀词性特征对比 %
可以看出,在F1值上,添加全部的词缀词性特征有一定的提高,因此我们决定将Pos4特征加入整体的语言学特征中去。
(3) 实验三:Suffix1-Suffix4分别是每个维吾尔语单词所附加的第一个到第四个词缀特征,可以发现虽然使用CNN进行字符特征提取能够获取一部分形态学特征,但是由于维吾尔语形态复杂,并不能获取全部的形态学特征。通过表7可以看出Suffix1-Suffix3分别添加之后,识别结果都有一定的提升。Suffix4效果不好的原因经过分析发现,测试集中共有20 242个单词,包含4个词缀的单词只有1 086个,过于稀疏,对识别训练造成了负面影响。为了验证Suffix4是否对维吾尔语命名实体识别有负面影响,我们同时添加Suffix1-Suffix4这四个特征进行对比实验,结果如表9所示。
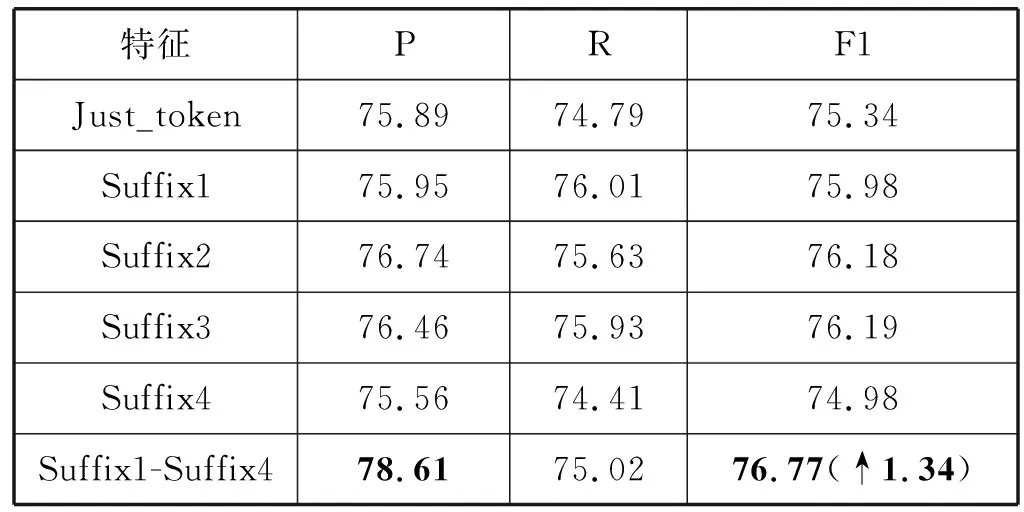
表9 融合所有词缀特征对比 %
通过表9可以发现,虽然单独加入Suffix4没有能够提高识别率,但是同时添加四个词缀特征,可以有效提高命名实体识别精度。
(4) 实验四:通过上述的实验可以看出,语言学特征能够提高维吾尔语命名实体识别精度,因此,我们将加入所有的语言学特征,与实验二中加入Pos1-Pos4特征以及实验三中加入Suffix1-Suffix4特征进行对比实验,结果如表10所示。

表10 融合所有语言学特征对比 %
实验结果表明,融合所有语言学特征后,相对于没有添加语言学特征的Bi-LSTM-CNN-CRF模型,维吾尔语命名实体识别精度有着显著提高,F1值提高了3.98%。同时,相对于仅添加了部分特征的,Pos1-Pos4以及Suffix1-Suffix4这两种模型,全部的语言学特征可以取得最好的命名实体识别精度。
4 结 语
由于维吾尔语的复杂形态特性,仅仅使用字符级CNN网络无法充分提取维吾尔语形态特征。本文提出了一种融合多种语言学特征的Bi-LSTM-CNN-CRF神经网络模型。通过整合词向量、字符特征、多种语言学特征向量作为输入向量,使用Bi-LSTM获取上下文信息,使用CRF作为输出层,约束输出命名实体类别序列。
实验表明,本文提出的融合多种语言学特征的维吾尔语神经网络命名实体识别模型,可以弥补仅仅使用CNN提取字符特征无法充分获取复杂形态特征的缺点,有效提升维吾尔语命名实体识别效果。
现有的神经网络结构还很难充分地自动抽取复杂形态语言的形态特征以及其他语言学特征,下一步将设计新的神经网络结构,能够更充分地自动抽取维吾尔语语言特征,进一步减少特征工程,并且提高维吾尔语命名实体识别精度。
猜你喜欢
电脑报(2021年41期)2021-11-04
时代英语·高二(2021年4期)2021-07-29
大众文艺(2021年12期)2021-07-23
电脑知识与技术(2019年29期)2019-12-16
中国民族博览(2019年10期)2019-11-29
鸭绿江·下半月(2019年7期)2019-11-05
电脑爱好者(2019年8期)2019-10-30
知识文库(2018年16期)2018-05-14
电脑知识与技术(2018年3期)2018-03-21
北方文学(2018年2期)2018-01-27
