
一种循环互作用注意力的属性级情感分类模型
2020-05-16 06:33张周彬邵党国杨嘉林
计算机应用与软件 2020年5期
张周彬 邵党国 马 磊 杨嘉林 相 艳,2*
1(昆明理工大学信息工程与自动化学院 云南 昆明 650500)2(昆明理工大学云南省人工智能重点实验室 云南 昆明 650500)
0 引 言
属性情感分类是细粒度情感分类任务,目的是准确抽取特定属性的情感信息,判断其情感极性[1-2]。例如,评论“Best of all is the warm vibe,the owner is super friendly and service is fast.”含有三个属性“warm”、“owner”、“service”,它们的情感极性分别为正向、正向、正向。因此,属性情感极性的判断不仅依赖于上下文信息,还依赖于属性的信息[3]。特别地,对于含有多个属性的上下文,如果忽视属性的信息,则很难识别不同属性的情感极性。Jiang等[4]对Twitter数据集进行了人工评估,结果表明40%的文本情感倾向性判断错误都源于没有考虑属性信息。
注意力机制最早用于图像处理领域,主要作用是辅助神经网络对图像信息处理时重点关注某些特定的信息。Bahdanau等[5]将注意力机制和循环神经网络相结合应用于机器翻译任务中,验证了注意力机制在自然语言处理领域的有效性。随后注意力机制在文本分类、阅读理解等自然语言任务中都取得了比较好的结果。Wang等[6]提出利用长短时记忆神经网络(Long Short-Term Memory,LSTM)和注意力机制对上下文提取特征时,加入基于属性特征的注意力机制,取得了比较好的结果。Ma等[7]提出利用互动学习注意力机制的方式学习属性和上下文的表示,进行情感分析。这些方法的成功应用都表明了将循环神经网络和注意力机制结合进行属性情感分类的有效性。
GRU(Gated Recurrent Unit)网络是LSTM网络的一种变体,相比LSTM网络更为简单,仅由更新门和重置门构成,用于对神经元信息的读取、写入,减少了模型的参数和复杂度,成为当前比较流行的循环神经网络。由于文本中词与词之间都有依赖关系,使得GRU网络广泛地应用于文本处理领域,并且取得比较好的结果。为了更好地学习属性的情感信息,本文以GRU网络为基础,提出一种循环互作用注意力模型(Recurrent Mutual Attention Model,RMAM)进行属性情感分类。
1 相关工作
属性级情感分类相关研究可分为基于传统机器学习的方法和基于神经网络的方法。传统机器学习的方法中,代表性的方法有:文献[8-9]利用手工定义规则的方式提取属性特征。文献[10-11]利用隐马尔可夫模型(Hidden Markov Model,HMM)和条件随机场(Conditional Random Field,CRF)模型对属性和上下文进行建模。虽然这些方法也能取得一定的效果,但是它们的性能严重依赖人工提取特征的质量,并且耗费大量的人力物力,模型复杂、泛化能力差。由于深度学习能够自动提取有效特征,使得深度学习方法被广泛地应用于自然语言处理(NLP)任务中。一些研究员提出将深度学习和传统的方法相结合处理属性级情感分类问题。Nguyen等[12]将循环神经网络(RNN)和句法分析树相结合。Dong等[13]采用一种自适应的RNN网络处理属性情感分类问题。这些方法相比传统的方法取得了比较好的性能,但是还是依赖了情感词典、句法分析等传统手段。为了彻底摆脱传统的方法,一些研究员对深度学习进行了深入的研究,在属性级情感分类任务取得了比较好的结果[14-15]。Chen等[16]将卷积神经网络应用于属性情感分类任务中。Xue等[17]将门控机制和卷积神经网络相结合应用于属性情感分类。Ruder等[18]提出一种分层的双向长短时记忆神经网络(Bi-LSTM),有效学习句子内部和句子之间的关系。Tang等[19]使用两个LSTM网络对属性左右两侧的上下文进行建模,挖掘属性的情感信息。Tay等[20]通过对上下文和属性建模捕捉它们之间的关系,然后送入神经网络中自适应的捕捉属性词和它的情感词。Wang等[21]提出对词语和从句联合训练的方法。支淑婷等[22]融合多注意从不同角度提取属性的情感特征。
以上的研究工作中,大部分模型忽视了对属性单独建模,以及上下文和属性的相互作用。不同属性的情感极性不仅依赖于上下文本身,还依赖于属性的特征信息。因此,本文提出RMAM模型,将GRU网络和注意力机制相结合,对属性和上下文分别建模,提取有效的情感特征进行属性情感分类。
2 基于循环互作用注意力的模型
2.1 模型构建
本文提出的RMAM模型如图1所示。上下文的输入为上下文词向量,属性的输入为属性向量,两者通过单向GRU网络进行独立语义编码得到上下文隐藏层向量和属性隐藏层向量。接着,将上下文隐层向量做平均池化得到上下文初始表示,利用该上下文初始表示去监督属性注意力权重的计算,该注意力权重和与属性隐层向量相乘获得属性最终表示。然后,利用属性最终表示去监督上下文隐藏层向量注意力权重的计算,该注意力权重和上下文隐藏层向量相乘获得上下文最终表示。最后,将属性最终表示和上下文最终表示拼接得到评论文本最终的编码特征,并利用该特征进行情感分类。
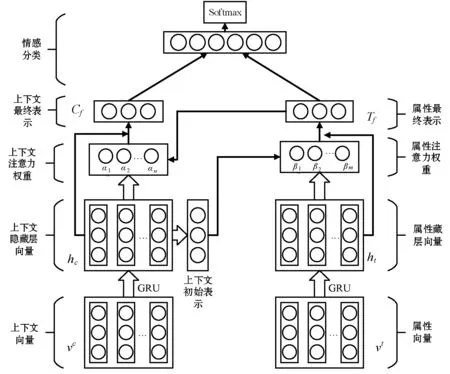
图1 循环互作用注意力模型
2.1.1 上下文和属性的输入
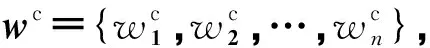
2.1.2 属性表示
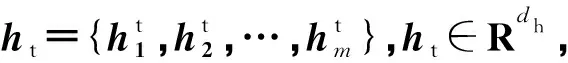
(1)
(2)
(3)
(4)
式中:Wt∈Rdt×dc表示权重;bt∈Rm表示偏置。
2.1.3 上下文表示
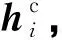
(5)
(6)
(7)
式中:Wc∈Rdc×dt表示权重;bc∈Rn表示偏置。
2.1.4 情感分类
将上下文的最终表征Cf和属性的最终表征Tf拼接S=[Tf,Cf]送入Softmax函数,输出属性最终的情感分类结果。
2.2 模型训练
RMAM模型的训练采用反向传播算法,损失函数利用交叉熵代价函数,为了避免过拟合问题,加入L2正则化,利用最小化损失函数对模型进行优化:
(8)
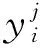
3 实 验
3.1 实验数据和参数设置
RMAM模型在SemEval 2014 Task4上进行了实验。SemEval 2014数据集由Restaurant和Laptop两个不同领域语料构成,数据集的评论中包含正向、中性和负向三种情感极性。表1显示了实验数据的统计情况。
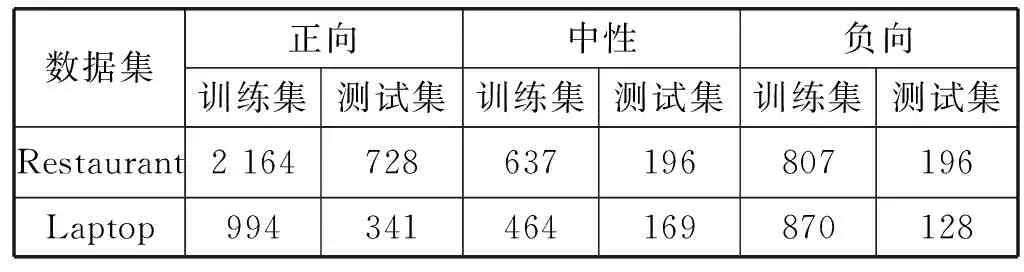
表1 实验数据
本文中词向量使用的是Pennington等[23]提出的预训练的glove的300维词向量,所有权重矩阵的初始值均通过均匀分布U(-0.1,0.1)随机采样给出,偏置的初始值为0。每次训练的batch_size=128,Dropout=0.3,使用Adam优化算法的优化参数,学习率设置为0.01。
3.2 基线模型
为了评估RMAM模型的有效性,将其与一些基线模型进行比较,基线模型如下:
TD-LSTM[19]:TD-LSTM模型通过两个LSTM对属性的上下文信息从正向和反向进行语义编码,然后,将两个隐藏层的输出拼接进行属性情感分类。
AT-LSTM[6]:AT-LSTM模型在LSTM网络的基础上引入注意力机制,重点关注属性的情感信息,取得比较好的结果。
TC-LSTM[19]:TC-LSTM模型是在TD-LSTM模型上的一种改进,将属性特征拼接到上下文作为模型的输入,让模型自动识别和属性相关的信息,提升情感分类的准确性。
ATAE-LSTM[6]:ATAE-LSTM模型是在AT-LSTM模型的输入层引入属性特征,让模型能够在双向LSTM网络语义编码时学习更多与属性相关的特征信息。
IAN[7]:IAN模型是对属性和上下文分别单独建模,利用互作用注意力方式学习生成属性和上下文有效的表示,最后将它们拼接预测属性的情感极性。
3.3 实验分析
3.3.1 与基线模型的比较
本文将6种模型在SemEval2014 task4 Restaurant和Laptop两个不同领域语料上进行了实验,表2给出了6种模型在属性级情感分类三分类和二分类准确率比较情况。

表2 不同模型属性情感分类准确率比较
从表2的结果可以看出,对于属性情感极性三分类任务,ATAE-LSTM和TC-LSTM模型相比TC-LSTM和AT-LSTM模型均取得比较好的结果,说明在模型中引入属性特征能够帮助模型挖掘属性和上下文中不同词语义关联信息,方便模型学习不同属性的情感特征。而ATAE-LSTM模型相比TC-LSTM模型在语料Restaurant上准确率高出0.9%,验证了注意力机制在属性情感分类任务中的有效性。IAN模型通过两个LSTM网络对属性和上下文进行独立编码语义信息,利用互作用注意力方式重点关注和属性相关的情感信息,相比ATAE-LSTM和TC-LSTM模型在Restaurant和Laptop语料上准确率高出1.4%、2.4%和2.3%、1.1%,再一次证明注意力机制和属性的引入对于属性情感分类的有效性。而RMAM模型在这两个语料上获得最好的结果,相比IAN模型提升1.6%和0.6%。
为了进一步显示RMAM模型的有效性,本文将Restaurant和Laptop两个语料中的中性数据剔除,只保留正向和负向的数据进行二分类实验。实验结果如表2所示,可以看出在剔除中性样本后,RMAM模型在Restaurant和Laptop两个领域的语料上的准确率都有明显提升,说明模型对于中性样本分类效果不理想。通过对Restaurant和Laptop两个语料中的中性情感样本进行分析发现,这些样本大都是对属性进行了一个客观描述,并没有表达任何情感。例如“This is a consistently great place to dine for lunch or dinner.”对属性“lunch”和“dinner”没有表达情感。另外,基于评论的随意性和多样性使得大多数的评论并不遵循语法规则,且对情感的表达常采用情感符号、网络用语或者比较含蓄的方式,使得模型不能很好地识别属性的情感信息,从而将属性的情感极性判断错误。通过实验结果的比较,本文提出的模型相比其他基线模型在Restaurant和Laptop语料上均取得了最好的结果,分别为0.925和0.884。比基线模型中最好的IAN模型高出0.9%和0.4%,说明RMAM模型能够比较好地解决不同领域的属性情感分类任务。
3.3.2 属性和上下文互作用学习作用分析
为了验证属性和上下文互作用学习的有效性,本文将上下文和属性之间的互作用学习去掉构建了新的模型(An recurrent attention model,RAM)。RAM模型的思想是:对属性和上下文分别单独建模,它们各自利用自身注意力分别计算注意力权重,提取有效情感特征。RMAM模型和RAM模型分别进行了三分类实验,实验结果如图2所示。
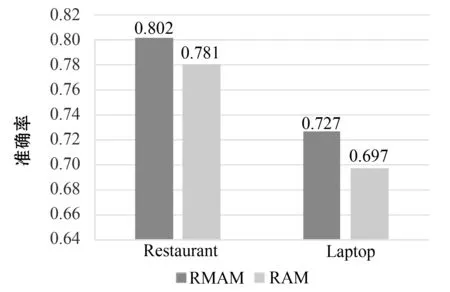
图2 互作用学习对分类准确率的影响
由图2可知,在两个不同领域的数据集上,RMAM模型相比RAM模型取得了更好的结果,在Restaurant和Laptop两个语料上分别高出2.1%和3%,表明属性和上下文之间互作用学习能够学习到更好的情感特征。
4 结 语
针对属性级情感分类任务,本文提出RMAM模型,利用两个GRU网络和注意力相结合网络以互作用对属性和上下文进行建模,提取有效的情感特征。RMAM模型可以密切关注属性和上下文中重要信息,生成属性和上下文的有效表示,解决了以往模型忽视属性信息和对属性单独建模的问题。在SemEval 2014 Task4两个不同领域数据集上进行实验,验证了RMAM模型可以学习属性和上下文的有效信息,相比于其他基线模型在属性情感分类的准确率上有进一步的提升。
RMAM模型主要利用GRU网络和注意力机制对属性和上下文自动提取情感特征,但是对于包含的否定词和一些网络用语是无法识别的,这是导致分类错误的一个主要原因。下一步的任务是在此方法的基础上加入传统的方法(情感词典等),更好地识别情感特征。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
小雪花·成长指南(2022年1期)2022-04-09
煤气与热力(2022年2期)2022-03-09
现代计算机(2021年33期)2022-01-21
北京航空航天大学学报(2021年4期)2021-11-24
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
软件(2017年6期)2017-09-23
第二课堂(课外活动版)(2016年2期)2016-10-21
教学与管理(理论版)(2009年9期)2009-11-04
