
基于混合密度网络的3D人体姿态估计技术研究
2020-05-14 03:30王俊岩
沈阳理工大学学报 2020年6期
王俊岩,祁 燕
(沈阳理工大学 信息科学与工程学院,沈阳 110159)
人体姿态估计课题的发展越来越贴近实际,例如在异常行为检测、步态分析以及行人重识别等领域的应用前景[1]。其中3D的人体姿态估计比2D能更进一步还原真实的姿态,更具挑战性。
目前实现3D人体姿态估计的方法主要有两种:一种直接从图像回归得到3D坐标;另外一种采用两阶段方法,先用预训练好的2D人体姿态估计器从图像上预测出2D骨骼序列作为输入,再根据2D关节点坐标估计出3D关节点坐标,其主要研究内容是从2D坐标如何快速、准确的估计出3D坐标。第二种方法减少了模型在2D姿态估计上的压力,网络结构简单,运算速度较快,占用显存较少[2]。由于从2D关节坐标恢复3D信息是一个逆问题,具有深度模糊性,其中3D关节的深度可能沿着投影到同一个2D关节位置的光线深度存在多种解决方案[3]。本文通过将这一问题看成处理1对N的多个输出结果问题,可以转换为混合多个概率分布来拟合函数,得到多个输出结果。本文通过混合多个高斯分布来构建混合密度网络,获得参数信息,比如高斯分布中的期望和方差,从而提供更准确的预测效果。
在深度学习的研究中,一个好的激活函数可以使梯度有效的传播,在提高网络性能的同时也不会造成过多的计算损耗。最近,可学习的激活函数吸引了很多学者的关注。PReLU利用激活函数的参数化,在训练过程中以端到端方式适应不同的网络体系结构和数据集,比其他的ReLU变体更具灵活性[4]。PAU不仅可以近似通用激活函数,而且可以在学习很少参数的同时,学习新的激活函数[5]。本文引用可学习的激活函数,其参数是全局参数,具有数据自适应性,可以提高网络的性能。
本文通过构建混合密度网络,更改神经网络的输出和损失函数,来预估出多个3D人体姿势假设。在网络结构上,将基于逐元素注意力机制的AReLU激活函数[6]应用到网络层中。实验证明,本文应用的AReLU激活函数提升了网络的性能,进一步降低了平均关节点误差。
1 模型的建立
1.1 混合密度网络
由于2D姿态估计3D姿态具有深度不确定性,根据文献[7],用Bishop提出的混合密度网络[8]可以来估计预测不确定性的情况。通过训练一组混合密度网络,并组合不同混合密度网络的参数,来预测概率密度的参数,得到最终预测结果。
本文的总目标是在给定2D输入的情况下,估计3D空间中的人体关节位置。因为输入是已知的2D骨骼序列x∈R2n(R为实数集),输出的是三维空间中的一系列点y∈R3n,所以可以学习一个函数f:R2n→R3n,使其在N个姿势的数据集中,预测误差最小。该函数将x映射到一组输出参数Θ={μ,σ,α}用于混合模型中。
1.2 模型的表示
在已知2D关节点x∈R2n的情况下,3D姿势y∈R3n的概率密度表示为高斯核函数的线性组合。
(1)
式中:m是高斯核的数量;αi(x)是混合系数,可以看作在给定输入2D关节点下第i个高斯核生成3D姿势的先验概率(以x为条件)。
αi(x)满足下面约束
(2)
式中φi(y|x)表示为第i个高斯核的3D姿势的条件密度,用高斯分布表示为
(3)
式中:μi(x)和σi(x)分别为第i个高斯核的均值和方差,其中混合系数、均值、方差都是输入2D姿势x的函数;d为输出3D姿势的维度。
最后,使用深度网络学习的函数可表示为
(4)
φi(y|x,w)=
(5)
式中参数取决于深度网络的学习权重w。
1.3 AReLU激活函数
注意力机制是让网络专注于找到输入数据中显著与当前输出相关的有用信息,从而提高输出的质量。如基于通道的注意力机制是每个通道中的所有元素共享相同的注意力值。本文引用的基于逐元素的注意力机制是最细粒度的,其使特征向量的每个元素可以得到不同的注意力值。要想每个元素都有一个独立的注意力值,需学习一个与输入特征向量对应的元素注意力图。
激活函数将非线性引入人工神经网络,对于网络的表达能力和学习动态至关重要。引用基于元素注意力机制的AReLU激活函数,其将元素注意力机制与ReLU激活函数相结合,并应用到本文的网络层中。通过设计注意力模块,使预激活的特征图学习基于元素的和基于符号的注意力图。根据ReLU激活函数的性质,注意力模块会导致正元素放大,并抑制负元素,因此注意力图根据其符号缩放元素。这样会使得网络训练更能抵抗梯度消失的问题,从而提高网络结构的性能。
1.3.1 逐元素注意力机制
设输入特征向量V={vi}∈RW×H×C,在整个特征向量上计算注意力图S={si}∈RW×H×C,S表示注意力图,包含每个元素对应的注意力值。使用一个函数ψ来调节特征图和输入特征向量,得到输出ψ(vi,si)。ψ是逐元素乘法,为了执行逐元素乘法,需要先将S扩展到V的整个维度。
Element-wise Sign-based Attention(ELSA)是一种基于元素的注意力机制,用于定义基于注意力机制的激活函数,公式为
(6)
式中:Θ={α,β}是可学习参数;C(·)将输入变量裁剪到[0.01,0.99];σ(·)是Sigmoid激活函数。可以看出,在ELSA中正负元素分别受到α和β不同程度的关注。所以,该注意力机制会根据当前输入的符号值,给出合理的注意力值。
1.3.2 基于逐元素注意力机制的激活函数
ELSA在网络层中可表示为
(7)
在使用ELSA构建激活函数时,将其与ReLU激活函数结合在一起。ReLU函数为
(8)
两者结合后的AReLU激活函数为
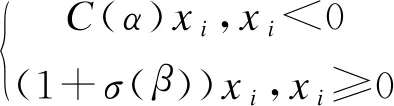
(9)
可以发现,当输入大于零被激活时,由于1+σ(β)>1,AReLU放大了梯度,有助于避免梯度消失。当输入小于零时,ReLU负数部分恒为零,会导致一些神经元无法激活,而AReLU会将其激活,缩小梯度。α和β是可学习的全局参数,会使激活函数更具数据自适应性,提高网络的精确度。所以在网络层上应用AReLU激活函数可以加强网络的训练效果。
2 网络结构
2.1 2D人体姿势估计器
采用Stacked Hourglass网络[9]对图像进行检测,生成16个关节点位置。使用的Stacked Hourglass网络训练模型是在MPII数据集上进行了预训练,并在Human3.6M数据集上进行了微调,从而使该模型在目标数据集上获得了更准确的2D关节检测,并进一步减少了3D姿态估计误差。对Human3.6M数据集进行检测,生成对应的2D关节点信息,并保存为.h5文件,为3D人体姿势估计器的训练作准备。
2.2 3D人体姿势估计器
3D人体姿态估计网络结构如图1所示。首先,将2D关节点坐标输人到3D人体姿态估计器中。其中,特征提取器的第一层线性层把维度为32的输入(16个2D关节点坐标维度是32)提高到1024维的特征空间中,并在该层使用ReLU激活函数。随后,跟着两个残差块进行残差连接,每个残差块里有两个线性层,把AReLU激活函数添加到这两个线性层中。最后,在假设生成器中改变神经网络的输出使三个线性层分别输出3个参数,混合系数、均值和方差。其中,每个高斯核的均值μi代表一个3D姿势假设。分别使用3个不同的激活函数来约束对应的3个参数,对混合系数使用了Softmax函数,用mELU函数来约束方差;对均值使用一个标准的线性层,该层的输出维度是240(16个3D关节点坐标维度是48,本文共设5个高斯核)。

图1 3D人体姿态估计器网络结构
3 实验结果及分析
3.1 实验环境配置
实验运行环境的服务器配置为CPU[Interl(R)Core(TM)i7-9700 CPU @ 3.60GHz],显卡[NVIDA GeForce RTX 2080],系统是64位Ubantu 16.04。深度学习框架是TensorFlow GPU 1.14.0。
3.2 实验数据集
实验数据集采用的Human3.6M数据集是目前最大室内3D人体姿态数据集。该数据集由360万张3D图片,11名受试者在4个不同的视点下执行了15个不同的动作。每个人体姿态有32个关节点,但是仅有17个关节点是移动的,所以本文的训练集中仅有17个3D关节点。本文模型在经过 2D 人体姿势估计器检测过的 Human 3.6M数据集结果上进行训练,并在带有真实 3D 标注的 Human3.6M 数据集上测试。
3.3 实验过程
3.3.1 数据处理
模型在经过Stacked Hourglass网络检测的2D关节点坐标和带有真实标注3D关节点坐标上进行训练。为了加快训练速度,将标准归一化应用于2D输入和3D输出,通过将输入数据减去平均值并除以标准偏差实现。由于输入只有2D关节点坐标,没有深度信息,无法预测3D姿势的全局位置。因此本文将髋关节周围的3D姿势零中心化,使3D 数据围绕在根关节点附近,所以本文把髋关节移除,仅有16个3D关节点坐标参与训练。
3.3.2 网络调参
使用Adam优化训练网络,训练200次迭代次数,初始学习率设置为0.001,最小批次大小为64,用Kaiming初始化来设置线性层的初始权重。在每个线性层后添加批处理归一化层加速神经网络训练。使用log-sum-exp技巧解决因损失函数中包含多个求和值的对数,导致计算值特别小所产生的计算机系统认为这个数太小而无法表示出的问题。
3.4 验证评估
为了对本文所提方法的性能做出评价,采用Human3.6M数据集官方推荐的测试集S9、S11,对测试集中的15个动作分别进行评估。通过比较重建的姿势假设与真实标注数据,计算每个关节点的欧几里得距离。表1表示计算每个动作关节点坐标误差的平均值。本文的方法比基准[2]的平均误差降低了9毫米,比只引用混合密度网络[3]降低了7毫米,这说明本文通过构建混合密度网络和在网络层上应用AReLU激活函数,可以提高3D人体姿态估计的准确性。表2表示基于Procustes分析的平均关节点误差。其先对网络输出进行刚性变换(平移,旋转和缩放)向真实标注数据对齐后,再计算关节点误差的平均值。如表2所示,经过Procustes对齐后的平均误差也比基准的低。这说明本文应用可学习的AReLU激活函数在网络层上具有很好的数据自适应性和缓解梯度消失问题,从而提高了网络的性能,降低了平均关节点误差。

表1 每个动作关节点坐标误差的平均值
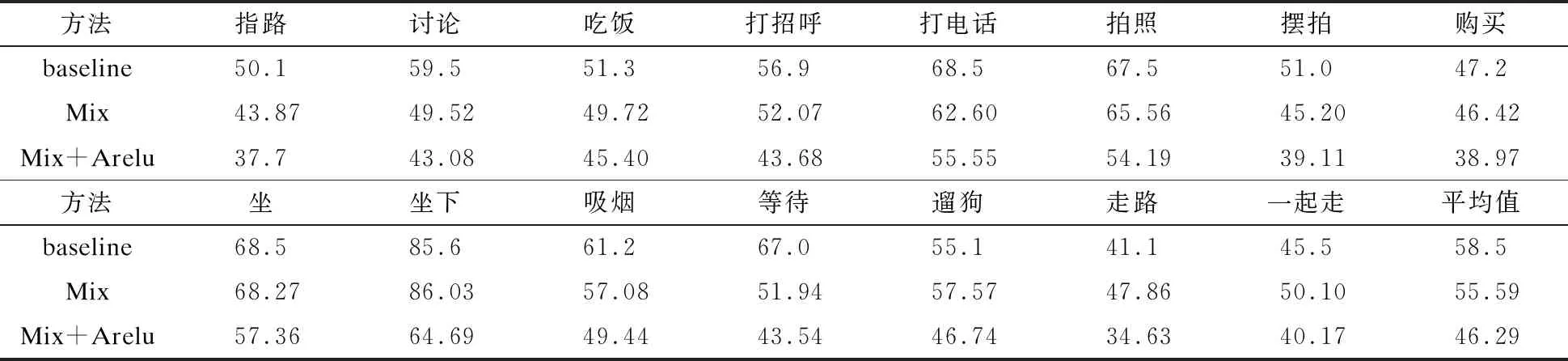
表2 基于Procrustes分析的平均关节点误差
3.5 可视化
图2列举了两个动作的可视化样例。

图2 模型样例可视化
图2中第一列是原始输入的2D姿势,第二列是3D真实标注,余下的5列是通过3D姿态估计器预测出的5个假设姿势。可以看出5个姿势假设都有不同的地方,这样增加了训练的不确定性,使神经网络获得了更多的信息,更有利于模型的学习。图3为3D姿势可视化图。

图3 3D姿势可视化
图3中左图为输入2D人体姿态估计器中的测试图,并在原图上用蓝色的圆点显示输出的16个2D关节点。图3中右图为输入左图2D关节点坐标对应的3D人体姿态预测结果的可视化图,其输出的是17个3D关节点。因为模型在训练时仅有16个3D关节点参与训练,所以在模型训练结束后,本文在可视化过程中把髋关节加入到3D人体姿态的可视化中。结果能准确反映3D人体姿态及三维网格空间中人体各部位所在位置的三维空间坐标。
4 结论
本文根据2D到3D之间的深度模糊性构建了混合密度模型,引用混合密度网络,使网络获取更多参数信息,输出多种3D可行姿势假设;并在网络层上应用了一种可学习的基于逐元素注意力机制的AReLU激活函数,提升了网络结构的性能,提高了3D人体姿态估计的准确性。
猜你喜欢
学习月刊(2022年6期)2022-12-18
沈阳航空航天大学学报(2022年3期)2022-11-08
铁道机车车辆(2021年2期)2021-05-21
沈阳航空航天大学学报(2020年6期)2021-01-27
学生天地(2020年3期)2020-08-25
文苑(2020年5期)2020-06-16
小学生学习指导(低年级)(2020年3期)2020-06-02
汽车观察(2018年9期)2018-10-23
学校教育研究(2017年30期)2017-08-13
诗选刊(2015年4期)2015-10-26
