
5~6年级学生常见错别字诊断测验的编制
2020-05-13 01:30:20范晓玲王梦翔孙梦杰周喜娣邝雨漠
教育测量与评价 2020年5期
范晓玲 王梦翔 伍 慧 孙梦杰 周喜娣 邝雨漠
识字、写字是学生掌握书面语言能力的基础,它不仅是个体获取信息和准确表达信息的渠道,而且是网络信息传播和共享的重要载体。《义务教育语文课程标准(2011 年版)》(文中简称课程标准)指出:按照规范要求认真写好汉字是教学的基本要求。[1]但是,汉字作为典型的表意文字,音、形、义之间的关系错综复杂,致使学生在识字、写字时难度增大,错别字现象严重,极大影响了学生阅读能力和写作能力的提升。而网络时代常使用不规范的语言文字导致错别字现象愈加严重,很多网民由于语音失范而对语言准确性产生误解、因为符号失范使得文字表达日趋复杂、由于词语失范引起语言表达出现歧义、句法失范使得阅读和表达能力逐渐下降。[2]因此,诊断常见错别字,可为减少或杜绝错别字现象提供教学、辅导、干预及研究方面的服务。
错别字是对人们在汉字掌握过程中常见错误的笼统称呼。错别字实际上是读别字和写错字、写别字的总称。读别字是指将甲字读成乙字的音。写错字是指书写中多笔少画,或无中生有的字,如“仰”的右部写成“卯”。写别字则是把甲字当成乙字,字形正确,但用法错误,如将“已经”写成“己经”。[3]小学阶段的重要任务就是掌握汉字规律,形成良好的汉字书写意识。小学高年级处于汉字学习清晰阶段的末端,学生需要清晰掌握字形,并建立起音、形、义之间的联系,这一阶段学生的错别字问题值得关注。
目前,针对小学语文识字写字教学中严重的错别字现象,尚未有单独的标准化测验工具,已有的测量与评价多使用教师自编测验,且主要以教材为中心或教师主观经验命题,极少依据心理、教育测验理论与技术进行编制,测验结果也没有进行信度和效度的分析,难以全面体现课程标准的要求,也缺乏针对性和指导性。本研究通过研读课程标准对识字、写字的各项要求,梳理汉字教学和错别字研究的相关文献,编制5~6 年级学生常见错别字诊断测验,并进行质量分析,以期为小学语文识字与写字教学的评估和诊断提供一份标准化的测评工具。
一、研究方法
1.被试取样
本研究采用随机取样法,在湖南省长沙市抽取城市学校和城乡结合学校进行团体施测,共有5 所学校的1500 名5~6 年级学生参与施测,回收试卷1441 份,回收率96%,远远超过“用于分析与报告非常好”的回收率。[4]剔除未作答和胡乱作答的试卷,获取有效试卷1334 份,有效率为92.60%。其中,A、B 卷分别为 662 人和 672 人,男、女学生分别为687 人和647 人,五、六年级学生分别为693 和641 人。
2.测验编制
本研究遵循经典测量理论(CTT)和项目反应理论(IRT)相结合、定性和定量相结合、理论与实践相结合的原则,综合采用文献分析法、专家访谈法和测量法,搜集人教版小学语文教材生字表中的生字,小学生作文中常见的错字,小学生在期中测试、期末测试、字词小测中错误较多的字词,《小学生易错易混字辨析手册》[5],形成测验项目库。
本研究由语文学科专家和测量学专家共同抽取项目库中的生字和易错字词编制5 类题型(读错字拼音、形近字辨析、近义词辨析、同音字改错、错字填空),组成3 套预测卷并进行测试。预测后,根据项目质量分析结果筛选项目,形成A、B 两套正式卷,每套试卷均由读错、写错和用错3 个分测验构成。读错分测验包括多音字误读、声旁误读2 项内容;写错分测验包括增减笔画,部件、结构错误2 项内容;用错分测验则包括音近致误、形近致误、义近致误3 项内容。易读错字拼音选择题15 项,易写错字填空题30 项,同音字改错题16 项,形近字辨析题10 项,近义词辨析题5 项;每卷均包括76 个题项。
3.效标测量工具
本研究采用范晓玲、龚耀先编制的4~6 年级多重成就测验(MATs)[6]B 卷语文分量表中的注音注字Y1、词汇Y2 这2 个分测验作为效标测量工具。MATs 中2 个分量表的重测信度分别为0.86和0.67,分半信度为0.81 和0.43,α 系数分别为0.86 和0.74。MATs 与学业能力倾向测验的效标效度为0.61。
二、研究结果
1.项目的质量分析
(1)基于CTT的项目质量分析
基于CTT的项目难度分析如表1 所示:A、B两卷难度低于0.20 的项目极少,A 卷仅有2 个,B卷没有;A、B 卷的项目难度范围为分别为[0.14,0.99]和[0.25,0.96];A、B 卷 3 个分测验的平均难度分别为 0.58、0.60、0.80 和 0.58、0.60、0.75。其中,易读错字拼音选择题的难度均为0.58,形近字辨析题的难度分别为0.93 和0.86,近义词辨析题的难度均为0.72,同音字改错题的难度分别为0.74 和0.69,易写错字填空题的难度均为0.60。两卷平均难度分别为0.68 和0.66。

表1 基于CTT的项目难度分布表
基于CTT的项目区分度分析如表2 所示:A、B 卷项目区分度高于0.19 的项目数占总体的80%以上;A、B 卷的项目区分度区间分别为[0.08,0.58]和[0.05,0.64];A、B 卷 3 个分测验的平均区分度分别为 0.27、0.47、0.33 和 0.28、0.47、0.37。其中,易读错字拼音选择题的区分度分别为0.27 和0.28,形近字辨析题的区分度分别为0.21和0.23,近义词辨析题的区分度分别为0.24 和0.23,同音字改错题的区分度分别为0.43 和0.50,易写错字填空题的区分度分别为0.47 和0.48。A、B 卷的平均区分度分别为0.37 和0.40。
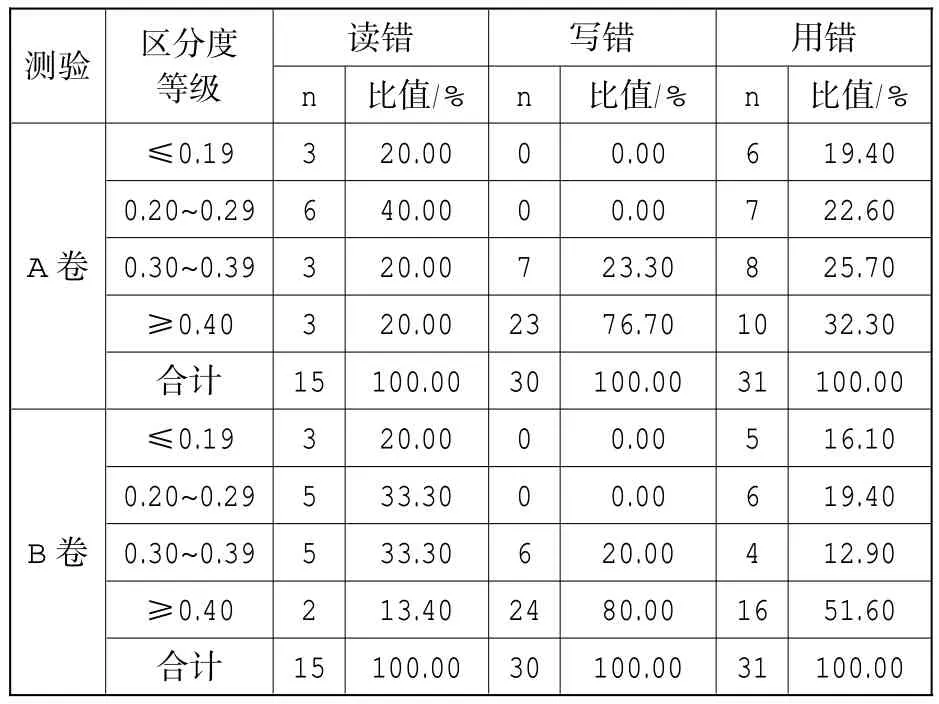
表2 基于CTT的区分度分布表
(2)基于IRT 的项目质量分析
本研究基于IRT,对A、B 两卷的项目质量进行了统计分析。A、B 卷难度参数区间分别为[-4.808,3.580]和[-5.196,4.213],平均难度分别为0.652 和0.494;区分度参数区间分别为[0.246,1.544]和[0.274,1.794],平均区分度分别为 0.844 和 0.882;猜测度参数区间分别为[0.048,0.500]和[0.044,0.406],平均猜测系数分别为0.219 和0.208;5 类题型的猜测系数分别为0.277、0.258、0.263、0.218、0.170 和 0.235、0.271、0.308、0.205、0.160。如表3 所示,A、B 两卷的测验平均难度参数均在0 以下,平均区分度参数均在0.80 以上,平均猜测度参数均在0.30 以下。

表3 基于IRT 的难度参数、区分度参数和猜测度参数表
A、B 两卷的被试能力分布如图1 和图2 所示,能力值区间范围均为[-3,3],符合正态分布,说明抽样质量符合要求。如图3 和图4 所示,A、B卷的最大信息量为19.43 和23.44,对应能力值分别为 0.40 和 0.20。
2.测验的质量分析

图1 A 卷被试能力分布图

图2 B 卷被试能力分布图

图3 A卷最大信息函数图

图4 B卷最大信息函数图
(1)信度分析
关于测验信度的统计分析结果表明:A、B 两卷的α 系数分别为0.92 和0.93;分半信度分别为0.851 和 0.857。两卷α 系数均大于 0.90,分半信度均大于0.80,指标良好,符合团体施测的信度标准,说明测验的项目同质性较好。
基于IRT 的信度分析主要探讨项目信息函数。项目信息函数是IRT 中最重要的指标之一,总体的信息函数是全部测验项目信息量的加成,也是测验的一个信度指标。本研究中,A 卷的最大信息量接近20,B 卷的最大信息量接近24,均大于16,符合团体施测的信度标准。
(2)效度分析
本研究外部效度的验证采用效标关联效度,内部效度的验证则采用结构效度。
本研究在实施小学5~6 年级学生常见错别字诊断测验的同时下发效标测验,计算效标测验与自编测验总分及分测验得分的相关系数。结果显示,自编测验总分及分测验得分都与效标测验显著正相关,相关系数在0.31 至0.50 之间,表明自编测验的效标关联效度良好。
统计分析结果表明:A、B 两卷总分与各分测验间的相关系数分别为 0.70、0.95、0.74 和0.73、0.97、0.62;各分测验间的相关分别为 0.55、0.55、0.80 和 0.60、0.45、0.49;总分与分测验之间的相关明显高于各分测验间的相关,表明两卷结构效度良好。进一步的验证性因素分析结果如表4 所示,两卷的RMSEA 均小于0.05,模型拟合指数CFI、TLI 均大于 0.90。以上数据表明,A、B 两卷的结构效度良好。

表4 测验因子模型拟合指数
3.划界分的确定与检出率
在诊断测验中,划界分数的确定会对测验的检出率和诊断结果产生重要影响。
本研究采用ROC 曲线法确定划界分。ROC线即感受者工作曲线,可提供测验的诊断效果。有研究证明,ROC 曲线的线下的面积值(AUC)在0.40~1.00 之间。当 AUC>0.50 时,值越接近 1,测验的诊断效果越好。AUC 在0.70~0.90 时有一定的诊断准确性,AUC 在0.90 以上时有较高的诊断准确性。[3]如图5 和图6 所示:A、B 两卷的 AUC值分别为0.766 和0.735,且在0.01 水平上显著,说明诊断具有一定的准确性。

图5 A 卷 ROC 曲线图
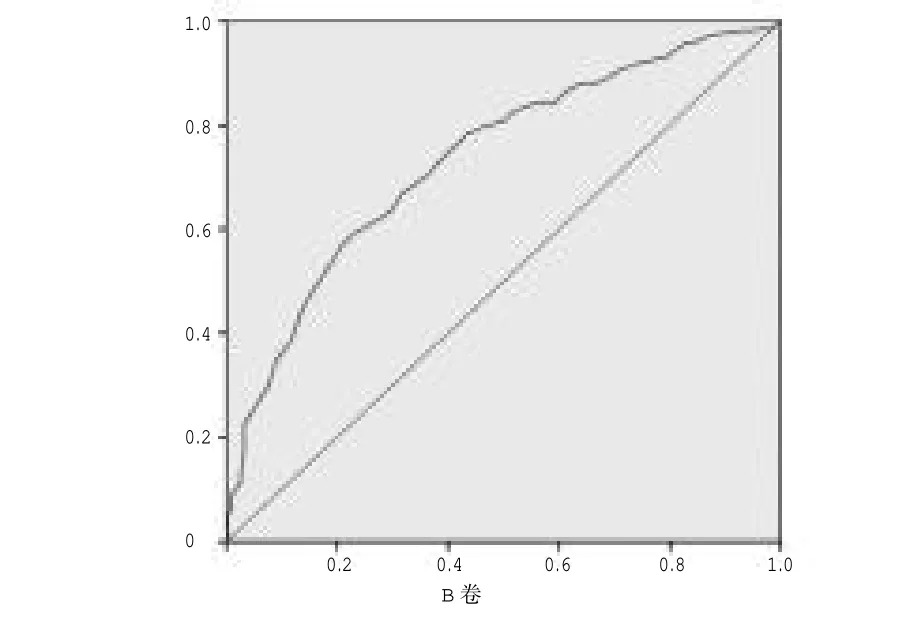
图6 B 卷 ROC 曲线图
笔者通过尤登指数,在ROC 曲线上选出敏感性最大且1-特异性最小的划界分点[7],得到A、B 测验总分的划界分均为48.50 分,检出率分别为58.90%和59.30%。
三、讨论
1.项目的质量分析
(1)基于CTT的项目质量分析
基于CTT的项目质量分析结果表明:A、B卷难度在0.20~0.80 之间的项目分别有47 项和59 项,占全部项目数的62%和78%;5 种题型的平均难度均在0.50 以上,整体偏易,但符合诊断测验要求,因为诊断性测验能够检测出某一方面学习有一定困难的学生,要求项目间的变化较小。[8]A、B 两卷的项目区分度在0.30 以上的分别有56 项和59 项,占全部项目数的74%和78%;区分度在0.20 以上的项目占到了总体的80%以上。因本测验为诊断性测验,项目难度偏易,导致了个别项目区分度较低。读错字拼音、形近字辨析、近义词辨析这3 类题型的平均区分度均在0.20~0.30 之间,区分度尚可,个别区分度较低的项目能够进一步修改更好;同音字改错、错字填空这2 类题型的平均区分度均在0.40 以上,区分度良好,符合CTT 对项目区分度指标的要求。[9]
(2)基于IRT 的项目质量分析
基于IRT 的项目质量分析结果显示:在A、B两卷各 76 个项目中,难度参数在[-3,3]之间的项目均有72 项,占全部项目的95%;两卷平均难度均小于0,符合“诊断测验题目偏容易”的要求,与CTT 结果一致。A、B 两卷项目区分度参数在0.70 以上的项目分别有50 项和51 项,占全部项目的66%和67%,说明A、B 两卷的项目区分度总体良好。A、B 两卷的平均猜测系数分别为0.219 和0.208,小于0.30。根据测验项目三参数模型的可接受范围[10],即难度在[-3,3]之间、区分度大于0.70、猜测度小于0.30,本研究的三参数模型分析结果基本符合测量学要求。
(3)CTT 和IRT 的项目质量分析结果比较
已有的关于学绩测验和人格测验的研究结果都显示,在进行项目质量分析时,IRT 分析结果较CTT 分析结果更为精确和有效。[11][12]其原因在于:CTT 题目参数计算依赖于被试样本,对能力的估计也依赖于测验题目的难度,因而在编制适应性测验和标准参照测验的过程中会存在一些限制;而IRT 的局限则在于假设条件要求严格,局限于单维反应模型且对测验条件要求严格等。[13]本研究结果也表明,基于CTT与IRT 的项目质量分析结果间存在较明显的相关,且难度、区分度划分优良项目标准的比例显示,基于IRT的分析结果更为精确,对测验的要求更高。为此,我们认为,自编测验的A、B 两卷能够满足IRT 的各项假设和测验条件的要求,且测验应归属于标准参照测验,因而采用基于IRT 的结果报告各项参数指标更合适。
2.测验的质量分析
(1)关于测验的信度
本研究中,同质性信度和分半信度的分析结果显示:A、B 两卷的同质性信度均在0.90 以上,分半信度均在0.85 以上。Gay 认为,若信度系数在0.90 以上,则表示测验或量表的信度良好。[14]当信度系数大于0.70 时,可用于团体间比较,大于0.85 时,可用于鉴别个人。[15]本研究A、B 两卷的同质性信度和分半信度均较高,说明测验的信度指标良好。
在IRT 中,测验信息函数作为信度的其中一项指标,通常要求测验的最大信息量应大于25,标准误应小于或等于0.20,当信息量为16~25 时则需要对其项目进行修改或直接增加项目数,以提高测验的信度。[16]本研究A、B 两卷的最大信息量为20~24,对诊断性测验而言其信度是可以接受的,当然也存在少许需要修改的项目。测验信息函数受到项目数、项目质量和被试能力水平的影响,项目数越多、区分度越高、猜测系数越小,被试能力水平与测验难度水平越接近,信息函数越大。[17]本研究A、B 两卷的信息函数稍低,其原因有3 个:一是诊断性测验的项目难度偏易,部分项目的区分度较低,导致信息函数只能接近标准;二是部分题型的项目较少,小学生的常见错别字数量繁多,但考虑到学生的注意力、耐心等影响因素,加上经过预测的筛选,所剩项目数量较少;三是测验项目的评分等级较少,导致猜测系数较高。信息函数还受到项目评分等级数的影响,项目评分等级数增多,总体信度会逐渐增大;评分等级越少,信息损失越大,总体信息函数就越小。[18]
(2)关于测验的效度
效标关联效度的统计分析结果显示,5~6 年级常见错别字诊断测验总分及分测验得分与效标测验呈显著的正相关,相关系数在0.31 至0.50之间,说明本测验的外部效度优良。[19]
结构效度分析结果显示,A、B 两卷的分测验与总分间的相关为0.45~0.97,达到中高度相关。进一步的验证性因素分析结果显示,A、B 两卷的各项拟合指标均符合测量学要求[20],说明模型拟合优良,测验结构比较合理。
以上结果表明,本测验的内、外部效度均符合测量学要求,具有良好的诊断效果。
猜你喜欢
学生天地(2020年34期)2020-06-09 05:50:52
学生天地(2020年24期)2020-06-09 03:08:56
作文小学中年级(2020年2期)2020-04-26 05:22:48
意林·少年版(2019年19期)2019-11-13 15:56:58
中国校外教育(2019年12期)2019-04-15 11:14:34
趣味(语文)(2018年9期)2018-12-23 02:19:58
江淮论坛(2018年4期)2018-08-24 01:22:30
趣味(语文)(2018年7期)2018-06-26 08:13:54
福建中学数学(2016年5期)2016-11-29 02:45:52
课堂内外·创新作文高中版(2016年7期)2016-08-19 06:09:04
