
基于改进YOLO深度卷积神经网络的缝纫手势检测
2020-05-08 11:25:20王晓华姚炜铭王文杰李鹏飞
纺织学报 2020年4期
王晓华, 姚炜铭, 王文杰, 张 蕾, 李鹏飞
(西安工程大学 电子信息学院, 陕西 西安 710048)
视觉与机器人技术在纺织业的应用促进了纺织业的发展[1-2]。在对柔软织物进行缝纫时,人与机器人协作完成生产任务,能够更充分融合机器人与熟练工人各自技术优势,比机器代人方式更具有研究意义。机器人对工人准确、高效的缝纫手势识别,是实现人与机器人协作互动的关键。机器人依靠视觉信息的手势识别一般分为传统人工设计、提取特征方式的识别和深度学习手势识别2类[3-4],具有代表性的研究中:文献[5]通过手工设计特征方式将手部几何特征与掌纹、手部静脉等特征进行融合来表示手势;文献[6]通过方向梯度直方图提取手势特征,并通过神经网络进行手势识别,但人工特征方法难以适应手势的多样性,尤其在环境复杂或者光照导致图像中存在肤色相近区域或者阴影时,识别率变差。
深度学习方法能够更好地获取图像高层次、多维度的特征表示并实现复杂环境下的检测识别[7-8]。 快速区域卷积神经网络(faster R-CNN)[9]、掩膜区域卷积神经网络(mask R-CNN)[10]等基于区域的目标检测算法有较高的检测精度,但检测速度较慢;YOLO(you only look once)[11-12]、单次多盒检测(SSD)[13]等基于回归的目标检测算法,采用端到端的检测,具有较快的检测速度,但这些方法在检测速度和精度方面还具有一定提升空间。
缝纫车间中,24 h作业环境中的光照变化较大,工人手部动作速度变化不一,尤其是内包缝、卷边缝、裁剪布料、抽褶缝等手势相似度大难以检测。针对上述问题,本文构建了缝纫手势数据集并提出了一种基于YOLOv3的缝纫手势检测网络。通过对原始YOLOv3网络结构改进及参数微调,以适应特定缝纫手势识别任务,进一步提高模型精度。在不同光照条件、背景复杂场景下,研究改进后的模型的检测识别效果。
1 YOLOv3目标检测算法
YOLOv3目标检测算法将检测问题转化为回归问题,相比其他算法,在实时性方面表现突出,可满足机器人对缝纫手势实时交互理解的需求。该网络使用多尺度预测来检测最终目标,网络结构上比YOLOv2更复杂,检测速度、精度均有显著提升。多尺度的预测能更有效地检测小目标。YOLO检测过程如图1所示。

图1 YOLO检测过程Fig.1 YOLO testing process
网络将每张图片划分为多个网格。如果缝纫手势的中心落入网格中,则该网格负责检测目标。每个网格预测边界框及其置信度分数,以及类别条件概率。当多个边界框检测到同一目标时,使用非最大抑制(NMS)方法选择出最佳边界框。
2 YOLOv3改进模型
YOLOv3虽然在目标检测领域有较好的检测效果,但其主要是针对通用数据集实现的,对于缝纫手势识别特定场景需再进行调整,以适应缝纫手势实时检测任务。在实际缝纫作业中,4种缝纫手势(内包缝S1、卷边缝S2、裁剪布料S3、抽褶缝S4)之间相似性高,手势间差异往往存在于小目标区域,识别难度大,因此,需在满足实时性要求下,通过采用高分辨率特征图输入,减少YOLOv3在检测小区域出现的漏检、误检现象。原始的YOLOv3网络采用由残差网络(ResNet)构建的Darknet-53网络作为基本网络实现特征的提取,更深的网络则会使得底层特征信息逐渐消失。受密集连接网络(DenseNet)启发,在Darknet-53网络基础上,通过在较低分辨率的原始传输层增加DenseNet密集连接,缩短前后层网络之间连接,可增强手势特征的传递并促进特征重用和融合,进一步提升检测效果。
改进后的YOLOv3网络结构如图2所示。首先将输入图像调整为512像素×512像素,替换原始416像素×416像素的图像。然后采用由4个密集层组成的密集结构替换原始第10层(分辨率为 64像素×64像素)和第27层(分辨率为32像素×32像素)采样层。在密集结构中,输入特征图为之前所有层的输出特征图的拼接。
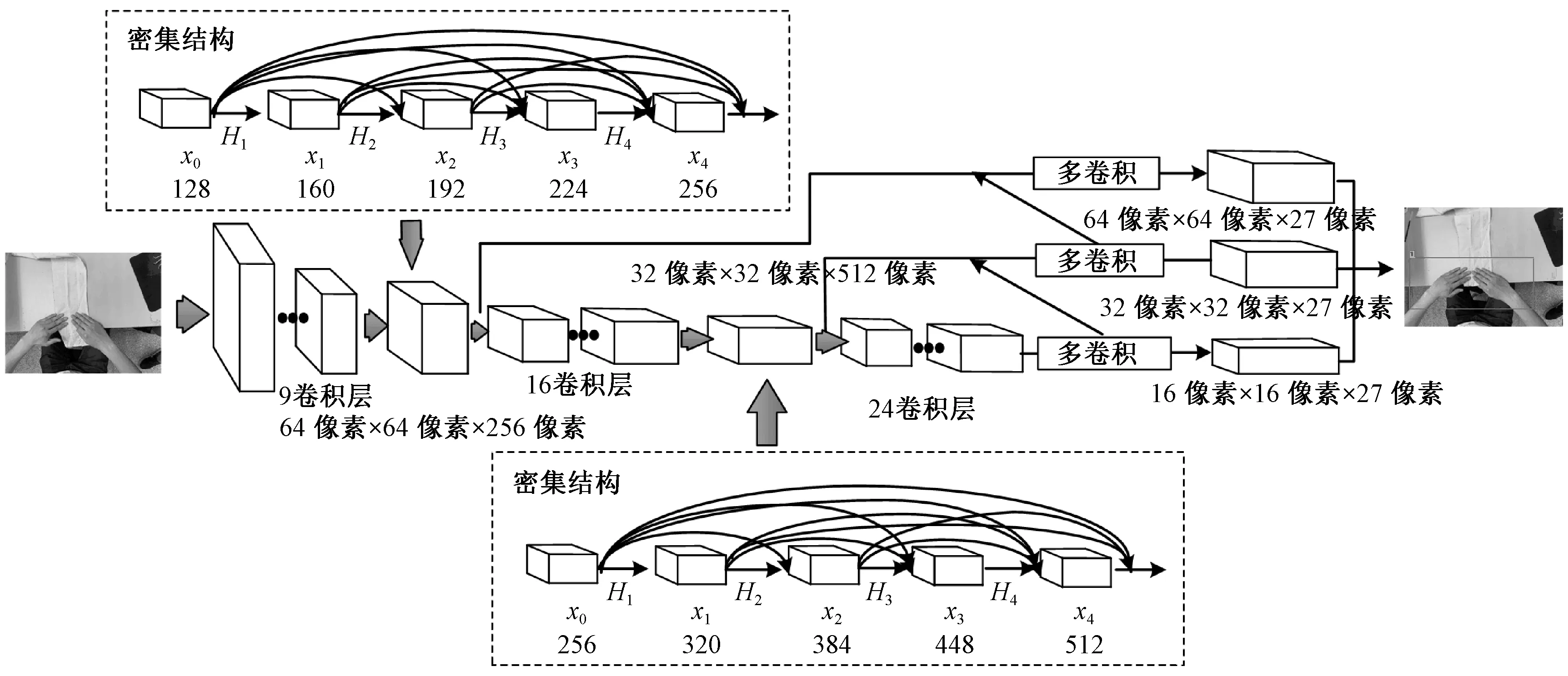
图2 YOLO改进的网络结构Fig.2 YOLO improved network structure
本文传递函数采用BN-ReLU-Conv(1×1)+BN-ReLU-Conv(3×3)的形式。其中1×1卷积核用于降维,防止输入特征图通道过大。
在64像素×64像素分辨率和32像素×32像素分辨率的层中:由输入x0和输出x1拼接的特征图[x0,x1]作为H2输入;x2和[x0,x1]被拼接成[x0,x1,x2]用作H3的输入;x3和[x0,x1,x2]被拼接成[x0,x1,x2,x3]作为H4的输入;最后,拼接成64像素×64像素×256像素和32像素×32像素×512像素尺寸特征图向前传播。在训练期间,当图像特征被转移到较低分辨率层时,深层特征层可在密集结构中接收其前面的所有特征层的特征,从而减少特征损失,增强特征复用,提高检测效果。本文输出采用3种不同尺度的边界框(64像素×64像素、32像素×32像素和16像素×16像素)对缝纫手势进行检测。
3 模型训练与调整
3.1 数据预处理
3.1.1 缝纫手势数据集采集
缝纫手势数据集样本主要来自制衣厂收集与网络爬虫。样本图像由多位缝纫工采集,每幅图像的分辨率约为512像素×512像素,通过数据增强后样本总数量6 670副,包含4种缝纫手势类别,其中内包缝手势目标 1 600 个、卷边缝手势目标 1 660个、裁剪布料手势目标1 700个和抽褶缝手势目标 1 710 个。数据集中训练集、验证集和测试集样本比例约为6∶2∶2。
3.1.2 数据集增强
为增强实验数据集的质量与丰富性,消除在同一时间采集图片光照强度不均匀的情况,本文通过传统的图像增强技术方法对采集的4种缝纫手势图像分别在颜色、亮度、旋转和图像模糊方面进行预处理来增强训练数据,并将同一类别图片添加至同一类别数据样本中。数据集增强数量如表1所示。
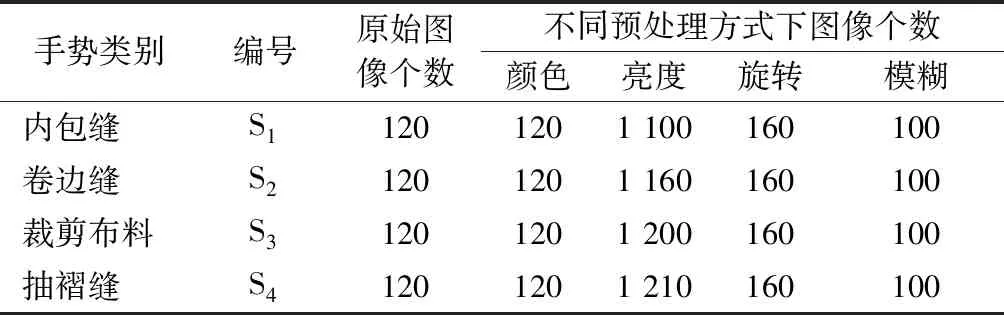
表1 数据增强方法生成的图像数量Tab.1 Number of images generated by data enhancement method
颜色校正:在不同的照明条件下,采集的图像颜色和真实颜色之间存在一定的偏差,采用灰色世界算法(gray world)消除光照对显色性的影响,并将处理后的图片添加到训练数据集中。
图像亮度:车间24 h生产时,不同光照强度对图像的影响可通过图像亮度变换模拟。亮度值变换过高或过低会影响手动标注边界框的精度,抑制模型性能,选择亮度变化的范围控制在0.6~1.5倍,以范围为0.9~1.1倍随机生成多幅图片供训练使用。
图像旋转:为增强训练模型对不同成像角度的鲁棒性,随机旋转原始图像90°、180°、270°以及镜像操作,并将140个变换图像附加到训练图像集。
图像模糊:考虑相机调焦以及移动等情况导致的模糊问题会影响检测结果,通过颜色、亮度和旋转增强等方法随机模糊图像,以进一步增强检测模型对模糊图片的检测能力。
3.1.3 数据集标柱
在缝纫手势数据集构建中,目标的类别和边框数据信息通过lambel软件获取,并保存为PASCAL VOC 数据集的格式,具体格式分别包含label(类别序列),x(目标中心点x坐标),y(目标中心点y坐标),w(标注框宽),h(标注框高),如下式所示。
式中:xmax、ymax为边框右下角坐标;xmin、ymin为边框左上角坐标;a、b分别为图像宽和高。对标注数据进行归一化处理,便于训练不同尺寸的图像及更快地读取数据。
3.2 模型的训练参数设置调整
所有的训练和测试均在深度学习工作站进行,工作站的主要配置为 PC Intel Core(TM) i7-6800k CPU3.80 GHz、12 GB 的 GPU GeForce GTX 1080Ti显卡 和 128 GB 的运行内存。程序在 Windows10 系统下,采用 C++语言编写并调用并行计算架构(CUDA)、英伟达神经网络库(Cudnn)、开源计算机视觉库(OPENCV)运行。
模型训练使用官网预训练权重文件初始化网络权重参数,加快模型收敛。训练参数部分根据经验设置,训练参数值如表2所示。为减轻显卡压力,寻求内存效率和内存容量之间的最佳平衡,训练时采用64个样本数量作为一批样本数量,每批样本更新一次参数,并将每批样本数量分割8次分次送入训练器。

表2 网络训练参数Tab.2 Network training parameters
训练时采用随机梯度下降(SGD)算法对网络模型进行优化。学习率(learning rate)按迭代次数调整策略,初始学习率为0.001,当模型迭代到 8 000 和 9 000 次时学习率衰减10倍。在开始训练时设置burn_in参数用于稳定模型,burn_in设置为 1 000,在更新次数小于1 000时,学习率策略由小变大,当更新次数大于1 000时,则采用设置的学习率从大到小更新策略。
YOLOv3中合适的先验框维度直接影响到手势检测的速度和目标框定位精度,为得到最佳先验框维度,对所有样本数据集的边界框采用K-means聚类分析来找到适合本样本数据的9组先验框维度。训练时使用的9组先验框维度为(121,82)、(163,98)、(158,154)、(205,119)、(239,150)、(203,218)、(302,179)、(316,253)、(324,351),将其尺寸从小到大排列,均分到 3 个不同尺度的特征图上,其中,尺度更大的特征图使用更小的先验框。最后,将用此先验框维度进行检测实验。
3.3 模型的训练
最终模型共训练5 000次,耗时6 h,共训练使用了4 000幅图像(在4 000幅图像中随机抽取并重复使用)。在训练过程中,通过绘制模型损失曲线观察训练动态过程,其对应的损失值变化曲线如图3 所示。可看出:模型在前期迭代中损失值快速缩减,模型快速拟合;当迭代训练2 000次后,损失值下降放缓;当迭代至5 000次时,损失值收敛至 0.002 5,结束训练。
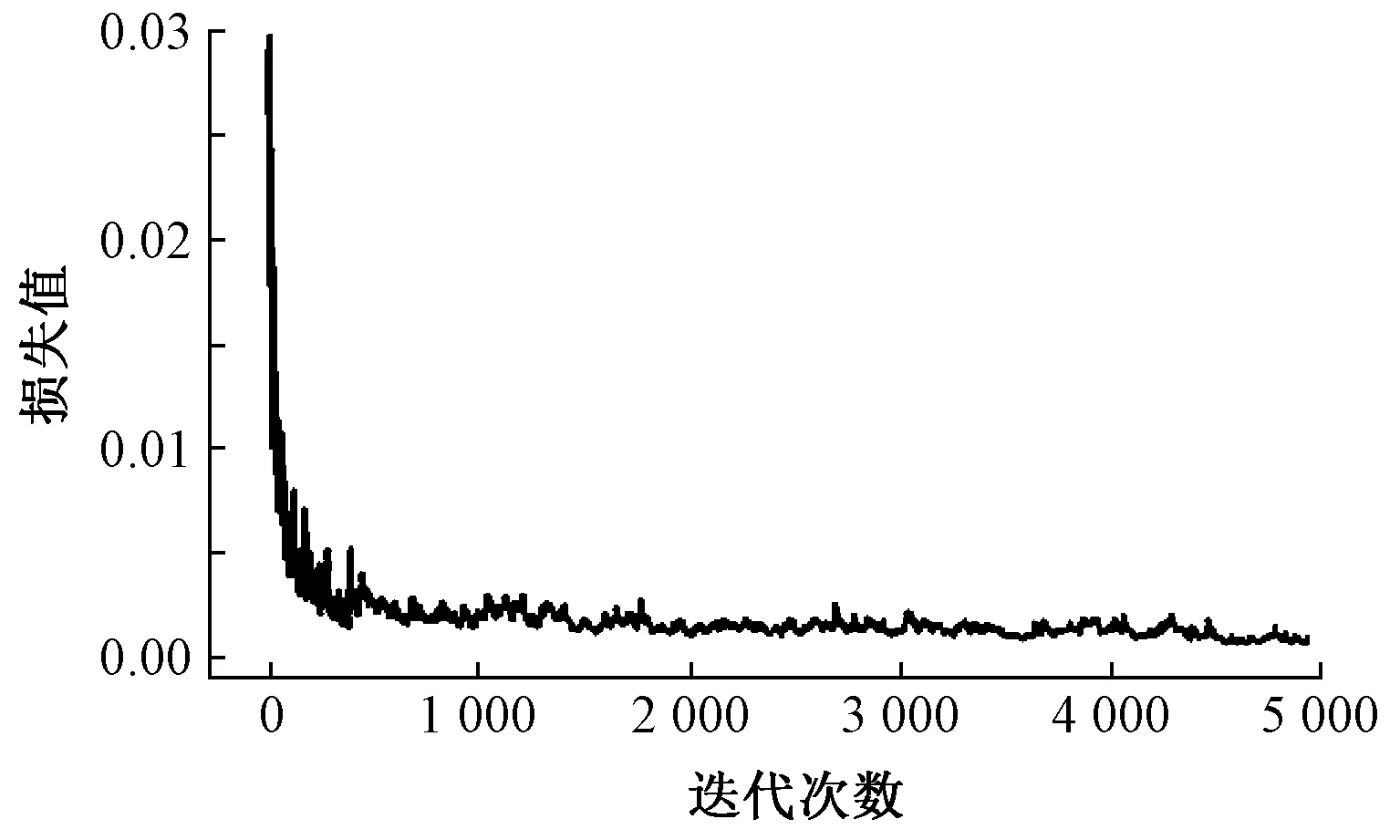
图3 模型损失曲线Fig.3 Model loss curve
通过计算预测边界框和真实边界框之间的平均交并比(IOU)来进一步评估模型的检测性能,结果如图4所示。可知,随着模型迭代次数的增加,真实框与预测框的模型平均交并比在不断提升,在迭代次数为5 000时,模型交并比趋于0.9。

图4 平均交并比变化曲线Fig.4 Average cross-sectional ratio curve
4 实验结果与分析
4.1 模型评估指标
本文实验采用精确度、召回率、平均精度均值(mAP)和基于精确率与召回率的调和平均值(F1)客观评价标准来评估模型的泛化能力。
4.2 最佳模型选择
在训练时每迭代100次输出一次权重,共获得50个权重模型,通过计算每个权重的mAP值筛选出最佳模型,结果如图5所示。可看出,在迭代次数达到2 000左右时,mAP值趋于稳定,进而选择最高mAP值(91.80%)作为最佳的权重模型。

图5 平均精度均值随迭代次数的变化Fig.5 Average accuracy as a function of iterations number
对训练好的模型进行最佳置信度阈值选取,以保证模型具有最佳表现。实验通过在不同置信度阈值下计算准确率、召回率、F1值和交并比筛选出最佳阈值模型,结果如图6所示。

图6 置信度阈值Fig.6 Confidence threshold
通过在(0,1)的阈值区间内每跨度0.05计算一次值,共计算出20组数据。比对优先级:准确率>召回率>IOU,阈值达0.6后准确率逐步趋于稳定,阈值最优范围约在0.6~1.0内。在此范围内,最佳召回率为0.85,对应的置信度阈值为0.6, IOU值约为0.71,因此,采用0.6为最佳阈值。
选出最佳模型后,通过使用准确率作为垂直轴,召回率作为水平轴获得最佳模型P-R曲线,如图7所示。观察P-R曲线可知,平衡点(度量召回率等于准确率时的取值)约维持在0.80。

图7 模型P-R曲线Fig.7 Model P-R curve
4.3 不同数据量结果分析
不同的缝纫手势数据量影响着模型表现,从数据集中随机选择图像,形成500、1 000、2 000、3 000、 4 000 个图像的训练集,分析图像数据集数量大小对YOLO v3密集模型的影响。表3示出对应的模型数据量与F1值的关系。

表3 不同数据量条件下F1实验结果Tab.3 Experimental results of F1 at different data conditions
从表3可看出,随着训练集的数据量增加,模型的F1值不断提高,模型性能得到不同程度改善。当训练数据量少于1 000个图像时,模型性能会随着训练集的增长而迅速提高;当训练数据量超过 1 000 时,随着图像量的增加,增强速度逐渐降低;当图像数量超过3 000时,训练集的大小没有显著影响模型的性能。
4.4 不同光照环境下结果分析
在实际缝纫工厂中,工人工作时长几乎覆盖全天,因此,在不同时刻的光照影响下,准确的缝纫手势检测尤为重要。为验证不同光照条件对训练模型的影响,实验通过对未使用亮度变换的数据集A与采用亮度变换的数据集B进行IOU值和F1值的评估,验证模拟全天候亮度变换的有效性,结果如表4所示。最后在工人工作时间内选择3个不同的光照时刻,对模型进行实际检验效果评估。实验将拍摄时的光照条件作为控制变量,分别有早晨光照、中午光照和灯光。实际检测效果如图8所示。
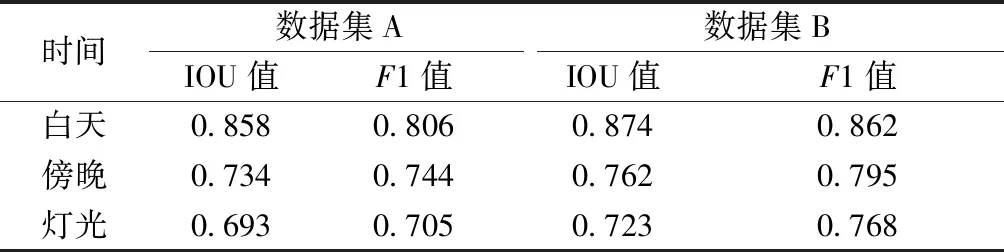
表4 不同光照条件下实验结果Tab.4 Experimental results under different lighting conditions
通过表4可看出,数据集B在训练时增加亮度变换,其检测结果比未增加亮度变换数据集训练的模型的检测结果更好。从增加亮度变换训练后的模型检测效果中可看出,4种缝纫手势在白天光照均匀时检测精度最好,其次是在亮度较低的傍晚。在灯光环境下,亮度明显增强,检测难度增大,部分手势纹理特征丧失。由于本文模型在训练数据集中增加了亮度变换,因此,可在光照复杂条件下准确检测出不同的缝纫手势类别。
4.5 不同算法的检测效果对比
为验证本文提出的模型的性能,将所提出的模型与R-CNN、YOLOv2、原始YOLOv3在实际采集的缝纫手势数据集上进行对比实验,结果如表5所示。

注:图片a1~a4为白天光照环境下;图片b1~b4为 傍晚环境下;图片c1~c4为灯光环境下。图8 不同光照条件下4种手势的检测效果Fig.8 Detection effect of four sewing gestures under different lighting conditions

表5 不同算法对比实验结果Tab.5 Comparison of experimental results with different algorithms
通过对比模型的F1值、IOU值和平均检测速度,本文改进的YOLOv3算法与其他算法相比,mAP值、IOU值均高于其他3种算法,其mAP值为94.45%,IOU值为0.87,F1值为0.885。由于改进YOLOv3模型比YOLOv3模型具有更高的图像特征复用率,因此,与原始YOLOv3对比平均精度提升了2.29%。在检测速度方面,改进后的模型速度达到43.0帧/s,远高于R-CNN,与YOLOv2、YOLOv3检测速度基本持平。模型检测效果如图9所示。

图9 不同算法4种手势实验检测效果Fig.9 Experimental results of different algorithms for four sewing gestures.(a)R-CNN;(b)YOLOv2;(c)YOLOv3;(d)Modified YOLOv3
从实际检测效果中可以看出,采用R-CNN与YOLOv2均有不同程度的漏检现象,原始YOLOv3与改进后的模型均能准确检测出4种不同的缝纫手势类别,但改进后的模型在边框重合度上更加准确。综上所述,改进后的模型不仅在准确率上有提高,且在检测速率上有显著提升,同时完全满足缝纫手势检测的实时性要求。
5 结 论
为解决服装加工中快速准确的缝纫手势识别问题,本文提出了基于深度神经网络 YOLOv3 算法的多种缝纫手势检测方法。首先通过对YOLOv3网络进行改进,增加模型输入分辨率,提高模型识别能力,然后在具有较低分辨率的YOLOv3原始传输层中嵌入密集连接网络(DenseNet),以增强功能扩展并促进特征重用和融合。
研究结果表明,改进后模型的检测精度高,速度快,在复杂环境下鲁棒性高,改进的深层网络在真实环境下进行检测,交并比和调和平均值分别为0.87和0.885,实时检测中速度达到 43.0帧/s,基本满足人机协作中对工人缝纫手势动作检测的准确性和实时性需求。
猜你喜欢
湘潮(上半月)(2023年5期)2023-06-14 05:42:42
学与玩(2022年6期)2022-10-28 09:18:32
中国机械工程(2022年8期)2022-05-09 12:32:02
中国机械工程(2021年8期)2021-05-07 05:49:10
红领巾·萌芽(2019年9期)2019-10-09 03:42:56
音乐教育与创作(2019年8期)2019-05-16 04:06:34
小学科学(学生版)(2018年12期)2018-12-19 05:13:50
小学阅读指南·低年级版(2017年6期)2017-06-12 01:39:24
消费导刊(2015年11期)2015-11-15 07:59:38
河南科技(2014年4期)2014-02-27 14:06:59
