
三维荧光光谱结合GA-SVM对多环芳烃的分类鉴别
2020-05-07 09:18王书涛车先阁李明珊王玉田
光谱学与光谱分析 2020年4期
王书涛,刘 娜,程 琪,车先阁,李明珊,崔 凯,王玉田
燕山大学河北省测试计量技术与仪器重点实验室,河北 秦皇岛 066004
引 言
随着现在生活水平质量的提高,人们现在更加关注自身身体的健康和生存环境的好坏,因为这与人类的未来息息相关。 多环芳烃(polycyclic aromatic hydrocarbon, PAHs)作为一类长时间难以降解的污染物,大致上都具有一个以上的苯环[1],广泛存在于大气、水中,长期积累会对人的呼吸系统或肝脏系统造成一定的损伤,更严重的可能会致癌。 研究表明,有机物的不完全燃烧是导致PAHs的根本原因,一般可以分为两类[2]: 一类为天然源,主要为一些像森林失火、火山爆发等自然灾害。 而另一类为人们在生产生活中制造的一些烟气废料,产生的原因比较广泛,可以在石油燃烧和交通运输过程中大量产生,并通过干湿沉降、污泥农用和污水灌溉等方式在土壤或是水中不断积累,影响人们的生产和生活环境[3]。 由于多环芳烃在环境中难以被分解,且持久性强[4],因此国内外的学者对如何检测多环芳烃做了很多努力,以便找到能扼制多环芳烃对环境污染的方法。 目前我国主要河流中都不同程度的受到PAHs的污染,刘小雪[5]通过对松花江干流沉积物中重金属和多环芳烃污染特征的检测,从空间和时间尺度上考察松花江沉积物中多环芳烃含量及其分布特征分析,了解到多环芳烃的组成多以NAP,FLU和ANA等比较常见的低环芳烃为主,而这三种物质荧光光谱会产生重叠[6],容易融合,所以采用一种针对这三种物质混合物的快速鉴别的方法具有现实意义。
目前用于PAHs种类检测的方法主要有气相色谱法、高效液相色谱法、气相色谱-串联质谱法[1, 7]等,但这些方法存在前期处理比较繁琐、价格昂贵、不能实时检测等缺陷。 而FS920荧光光谱仪具有单次检测的成本低,操作简单,可以实时检测物质变化,具有丰富的信息含量等优点[8],因此适用于各种可以发出荧光物质的液体检测。 Yang[9]等实现了用荧光光谱法中荧光激发发射矩阵检测水体质量的好坏,刘婷婷[10]等实现了用三维荧光光谱结合小波压缩与APTLD对水中多环芳烃的测定,吴兴[11]等实现了用平行因子结合支持向量机实现了对水中多环芳烃单质物质的检测,多环芳烃在自然界中多以混合物的形式存在,支持向量机作为一种比较好的分类模型,本文采用荧光光谱结合优化的支持向量机实现对多环芳烃混合物的分类与鉴别。
支持向量机(support vector machine, SVM)由Vapnik首先提出,最早可以用于模式分类,后来Vapnik将支持向量机加以改进并且适用于非线性回归上。 在模式分类问题中,为避免因数据训练过程过于完美而造成的过拟合,支持向量机能提供较好的泛化性能。 将遗传算法优化的支持向量机和三维荧光光谱技术相结合,可以快速准确的辨别混合多环芳烃物质中的种类。
1 基本原理
1.1 SVM分类
支持向量机(SVM)作为单层感知机的一种延续和发展,区别在于感知机学习算法时会因采用的初值不同而得到不同的超平面,而SVM试图寻找一个最佳的超平面来划分数据。 SVM的主要思想是建立一个分类超平面作为决策面,使得需要被分离的物体之间的隔离边缘被极限的拉开; 支持向量机的种类比较多: C-SVC,H-SVMs,DAG-SVMs(有向无环图支持向量机)等,其中C-SVC是比较常见的二分类支持向量机模型,其具体形式如下:
1)设已知训练集
T={(x1,y1), …, (xl,yl)}∈(X×Y)l
(1)
其中,xi∈X=Rn,yi∈Y{1, -1}(i=1, 2, …,l);xi为特征向量。
2)选取适当的核函数K(x,x′)和适当的惩罚参数C,构造并求解最优化问题
(2)
(3)
(4)
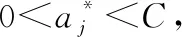
(5)
4)构造决策函数
(6)
由于惩罚参数C与g的选择决定着SVM分类的准确率与精度,传统支持向量机需要靠经验寻找最佳参数,因此,使用GA参数优化方法来优化参数对比传统支持向机。
1.2 GA优化SVM对参数的选择
遗传算法(genetic algorithm,GA)作为一种优化算法,是对达尔文生物进化论的自然选择和遗传学机理生物进化过程进行的模拟,在模拟自然进化过程搜索从而寻找最优解的方法,它最初由美国Michign大学J.Holland教授于1975年提出,根据自然界中优胜劣汰的选择规律,可以应用于很多领域,本文依据遗传算法来寻找最佳的支持向量机的参数,使训练和测试的结果达到最优。
遗传算法主要特点是直接对结构对象进行操作,操作简单,搜索范围大,应用范围广泛。 运用GA来寻找最佳的参数C和g,可以不必像网格划分那样遍历网格内的所有参数点,也能找到最优的答案[12]。 遗传算法作为一种适用性很强的优化技术,近几年的发展极为迅速,掀起了一股遗传算法研究的热潮。 利用GA算法对SVM参数选择优化的建模流程如图1所示。
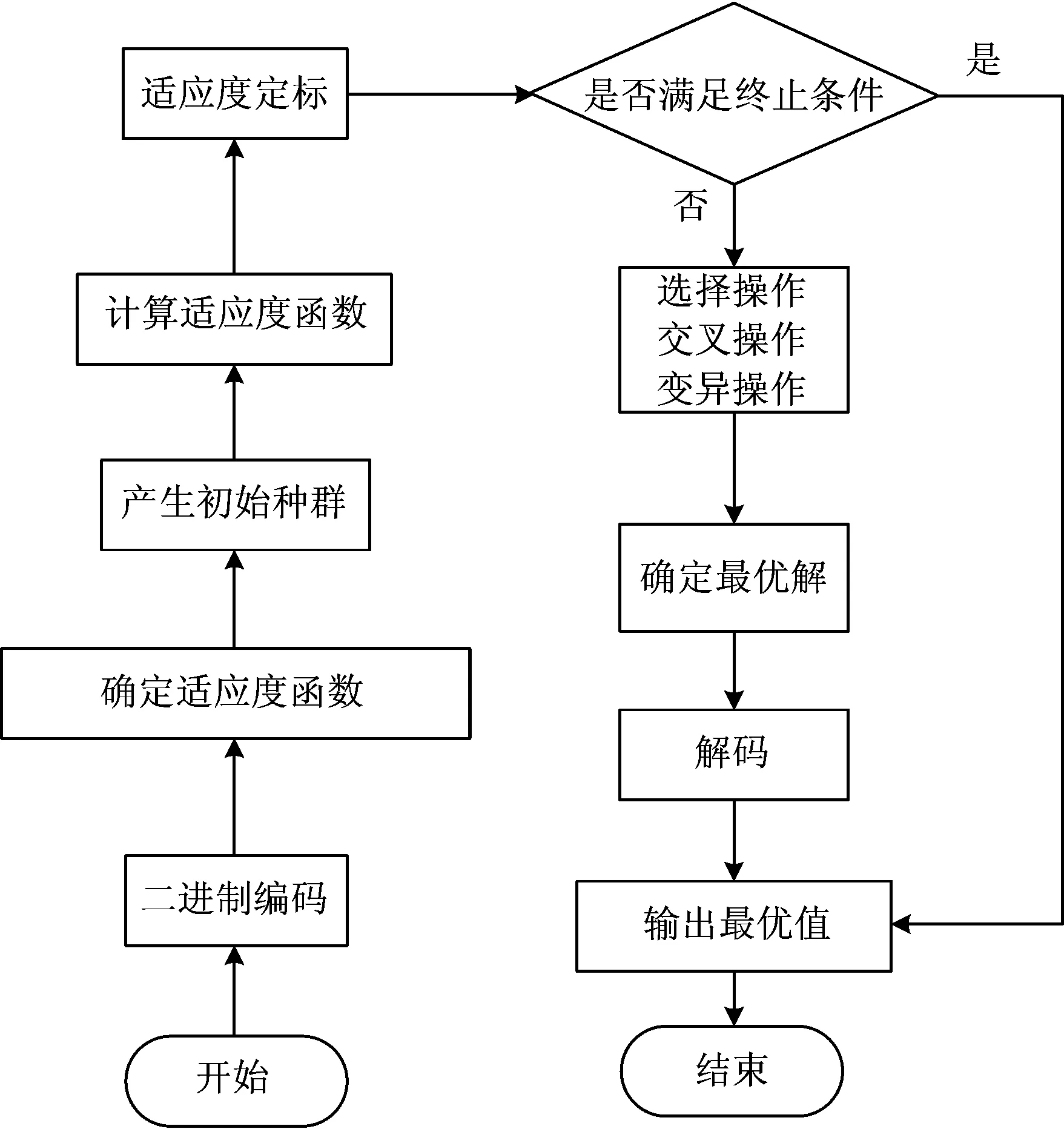
图1 利用GA优化SVM参数的算法流程图
2 实验部分
2.1 样品光谱的采集
多环芳烃的种类多种多样,例如苊烯(ANY)、芘(ANT)、荧蒽(FLT)等27种。 本实验根据常见的多环芳烃类型,选取3种多环芳烃作为实验样本: 萘(NAP)、芴(FLU)、苊(ANA)固体粉末状物质,购买自上海阿拉丁生化科技。 称量仪器为天津天马横基仪器有限公司生产的FA1004型,取NAP,FLU和ANA粉末各1 g溶于少量的甲醇(光谱级)溶液,然后转移到100 mL的去离子水溶液中,配置PAHs标准溶液。 实验过程中保证使用甲醇的浓度为99%,体积分数低于1%,避免在实验中对多环芳烃的测量造成影响。
在测量过程中,采用的检测仪器为英国Edinburgh Instruments公司生产的FS920荧光光谱仪,扫描范围为200~900 nm,比色皿为石英材质,光程10 nm; 实验中设置激发波长200~370 nm,步长为10 nm,发射波长为240~390 nm,步长为2 nm,狭缝宽度为2.8 nm; 为避免荧光光谱仪本身产生的瑞利散射影响,设置起始的发射波长滞后激发波长10 nm。
为得到多环芳烃的原始光谱,将配置的PAHs标准溶液放入比色皿中进行测试,图2为实验中10 g·L-1多环芳烃单质水溶液的原始荧光光谱图。
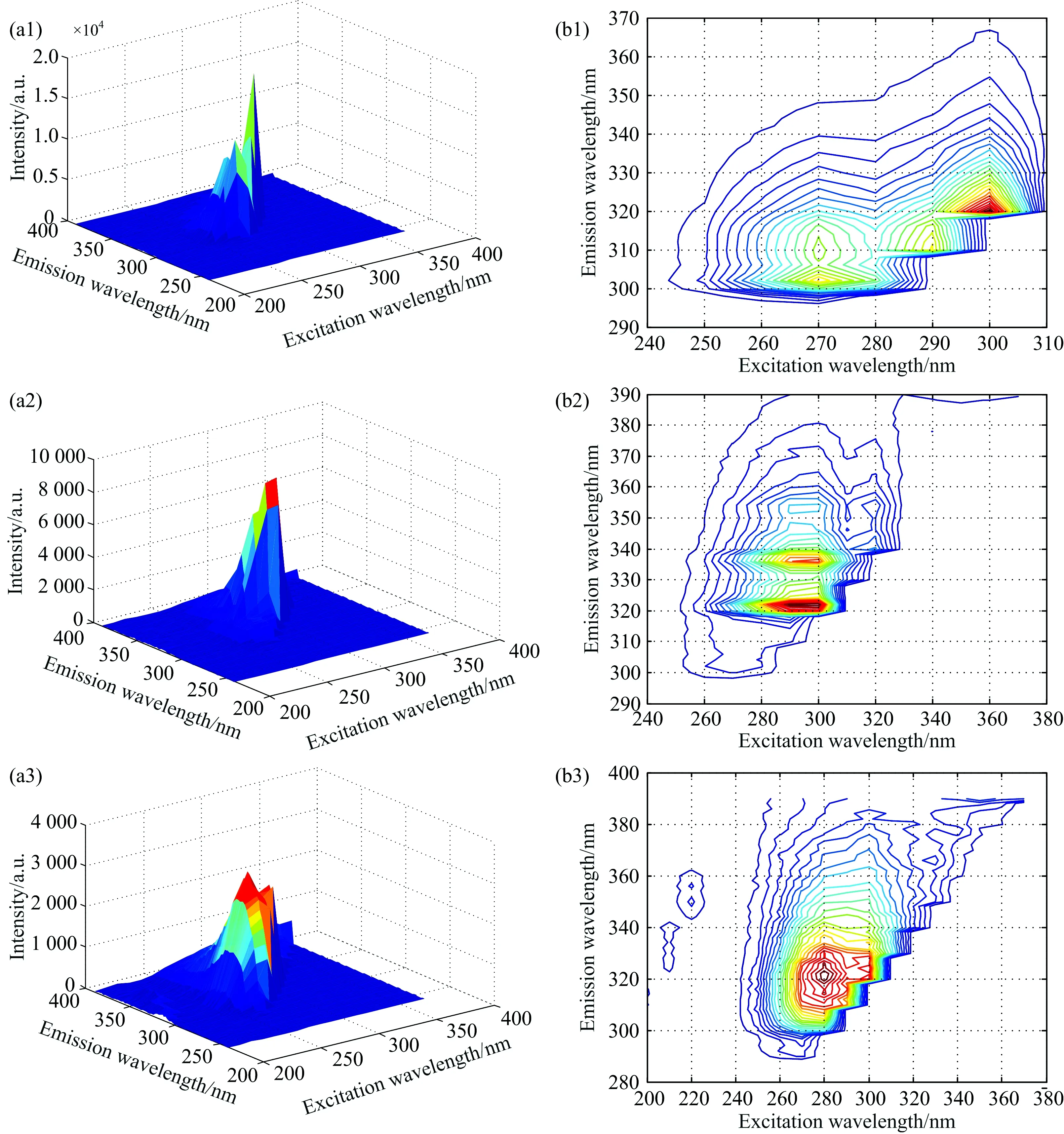
图2 芴(FLU)、苊(ANA)、萘(NAP)的水溶液荧光光谱图
由图2中三种多环芳烃的荧光光谱图可知,FLU的荧光峰值位置在激发波长300 nm,发射波长322 nm,ANA较强的荧光光谱范围是激发波长为285~310 nm,发射波长为320~340 nm,NAP的荧光范围在激发波长260~290 nm,发射波长在310~330 nm之间,而NAP的光谱范围较为广泛,涵盖了ANA的荧光光谱和NAP的荧光光谱,考虑到在自然界中,多环芳烃多为痕量物质不易被检测,而且以混合物的形式存在,以标准溶液为基准,配置了浓度为0.1 mg·mL-1的单质水溶液。 实验将ANA与NAP,FLU分别取不同的体积相互混合形成两种混合溶液,各自形成16种不同浓度比例的混合溶液,然后再取不同体积的三种溶液相互混合,摇匀震荡,共形成48种不同比例的混合溶液。 图3为不同体积分数混合溶液的部分荧光光谱图。
通过分析混合溶液的荧光光谱图可知,ANA、NAP的混合溶液和ANA、FLU的混合溶液最佳发射波长的位置相同,荧光峰对应的激发波长也有大部分重叠,ANA,FLU和NAP混合溶液的荧光峰也包括320 nm,激发波长范围也和前两类混合物相近。 荧光光谱范围集中在激发波长260~300 nm,发射波长320~360 nm之间,仅从光谱图特性上并不能及时准确的辨别是哪种物质的混合物,因此,采用GA优化的SVM算法来进行辨别,为提升水流域中多环芳烃类混合物种类的测量效果提供一种简单有效的方法。

图3 ANA∶NAP体积比为1∶9、ANA∶FLU为1∶9、ANA∶FLU∶NAP为2∶1∶3的混合溶液
2.2 GA-SVM模型设计
GA-SVM模型处理过程就是对数据进行的选择和重构矩阵,为了增加实验的准确性,避免人为因素造成的不确定因素,因此增大了荧光光谱的取值范围,取荧光光谱范围差别较大的波段: 激发波长为260~320 nm,发射波长为300~380 nm,3种苊萘、苊芴和苊芴萘的混合溶液分别标定1,2和3。 每组16个样本,共48组,在GA-SVM模型中,将数据随机打乱,然后被分为训练组和预测组,训练组设为36组,预测组设为12组。 其中,遗传算法需要提前设定的参数群体大小为20、交叉概率为0.9、变异概率为0.01、遗传算法的终止进化代数为200。
3 结果与讨论
将重构好的数据输入GA-SVM模型进行训练,模型经过200次迭代后,较好的实现了多环芳烃光谱的模式识别,训练好的模型测试结果如表1所示,共测试10次,取平均值。

表1 多环芳烃的分类测试结果
从表1可知,GA-SVM对三种多环芳烃混合物的识别率为95.42%。 这表明,GA-SVM模型能准确识别不同种类的多环芳烃混合物三维荧光光谱。
3.1 GA-SVM模型与BP神经网络对比
实验中设计得GA-SVM模型输入的训练集与测试集分别为随机取的36个和12个,所以,BP神经网络的输入层神经元个数为259(数据构成的为259×24矩阵),隐层神经元个数为5,输出节点个数为3。 激活函数为sigmoid函数,学习率取0.1,为保证实验的可靠性,采用36个作为训练集,12个作为测试集,训练次数为100。 训练好的模型平均测试结果如表2所示。

表2 PAHs光谱的分类测试结果
由表2可知,在对多环芳烃荧光光谱的分类中,GA-SVM模型的光谱分类精度更高。
3.2 GA-SVM模型与普通SVM的对比
实验中设计得GA-SVM模型输入的训练集与测试集分别为随机取的36个和12个,所以传统支持向量机的输入也为36个,将训练集和测试集的数据进行归一化处理后输入模型中,经过几次试验后,发现在惩罚参数C为2,g为2时,准确率最高,得出结果如图4所示。
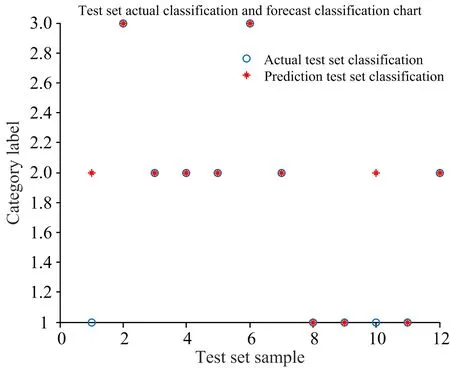
图4 SVM测试集的实际分类和预测分类图
将传统SVM的测试结果与GA-SVM对比如图5所示。
由图4可知,SVM的分类结果中,测试的12个分类样本中有2分类错误。 而从图5中可以看到,GA-SVM没有分类错误。 说明GA的优化作用在寻找惩罚参数C和g中比人为寻找的更为准确、可靠。
GA-SVM的适应度曲线如图6所示,从图中可以看到,当进化代数大于8时,最佳适应度值达到最大并在一定范围内震荡,保持稳定的波动并且与自家适应度之间的距离较小,总体收敛速度较快,适应度较好,能够快速检测多环芳烃种类。
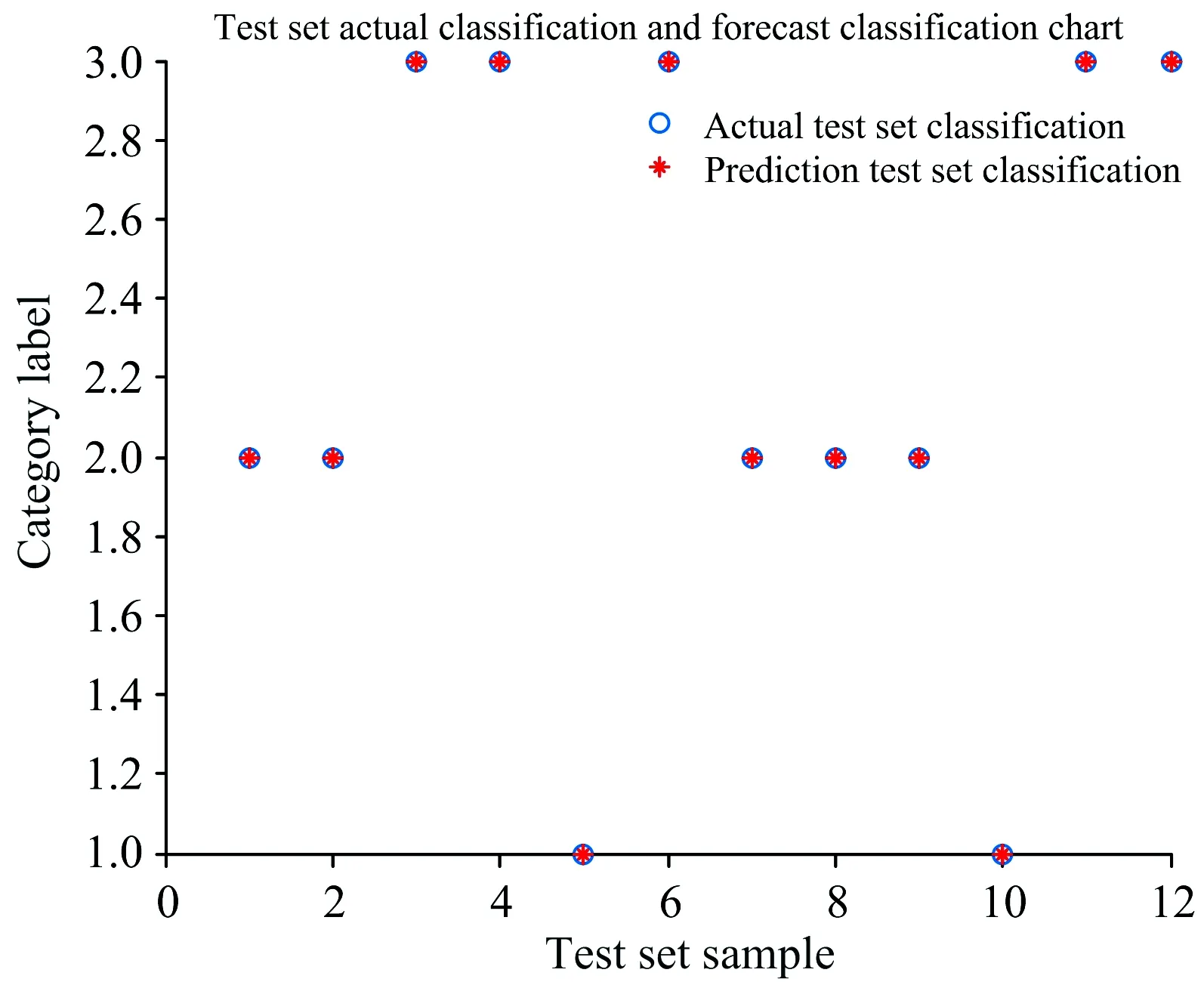
图5 GA-SVM测试集的实际分类和预测分类图
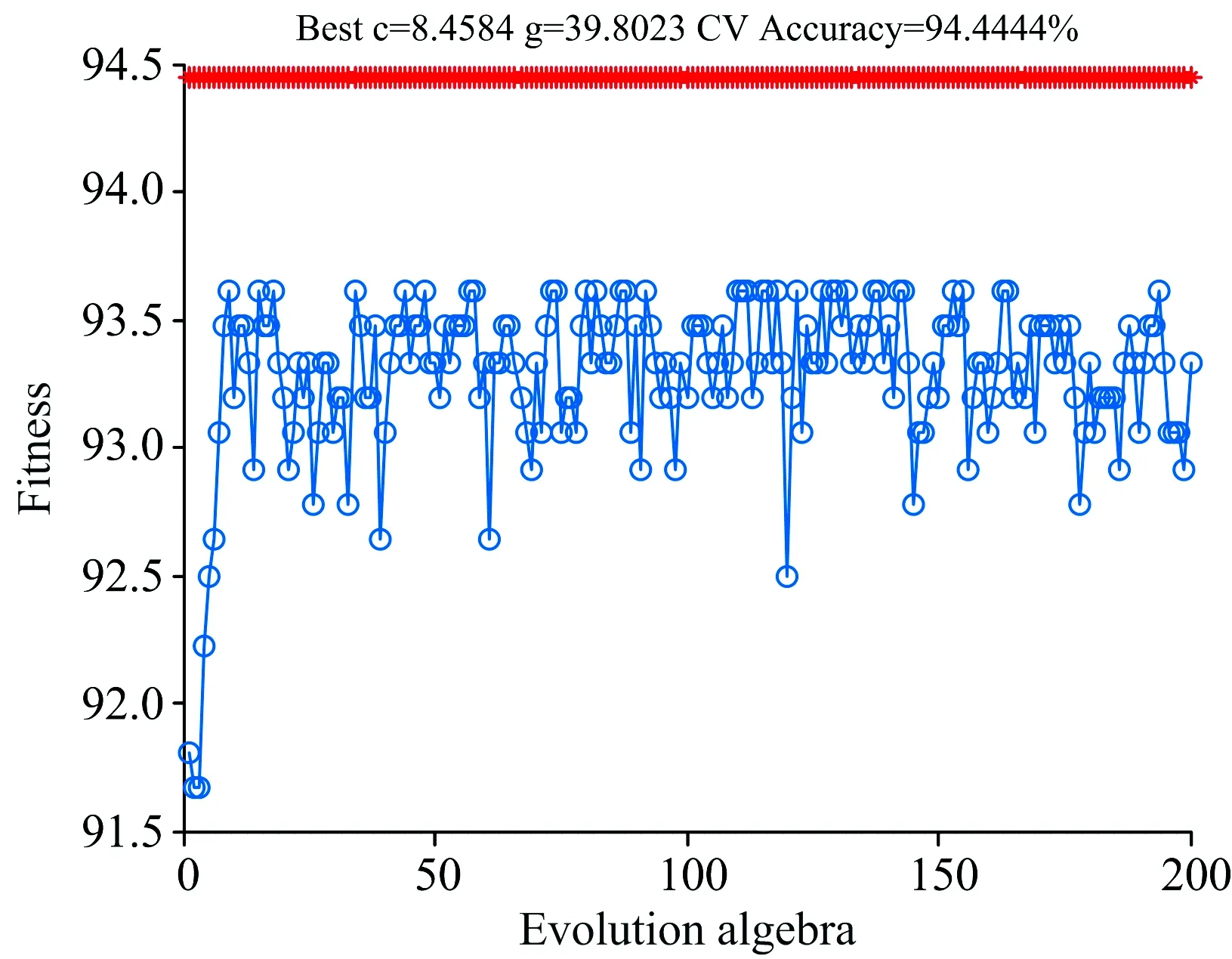
图6 GA-SVM参数的适应度曲线
运行得到最优的惩罚因子C=8.46,g=39.80。 将得到的优化后的参数输入GA-SVM训练,运行模型训练,得到ANA,FLU和NAP的混合物的分类模型。
4 结 论
利用三维荧光光谱技术快速获取了3种多环芳烃混合物的荧光光谱,从光谱图特性中发现不同体积比例混合的多环芳烃单质物质,在激发波长在260~320 nm、发射波长300~380 nm范围内发射波长位置相近,荧光峰对应的激发波长范围有大部分重叠,然后利用GA-SVM对不同种类的多环芳烃进行分类,实验中,3种混合物的平均分类正确率为95.42%。 实验结果表明,三维荧光光谱结合GA-SVM技术能准确识别不同种类的多环芳烃混合物,虽然这种方法在更多种类多环芳烃混合的情况下的运用有待进一步研究,但是为水流域中多环芳烃混合物的种类鉴别提供了一种新思路与新方法。
猜你喜欢
纺织标准与质量(2022年3期)2022-08-10
承德医学院学报(2022年2期)2022-05-23
科学家(2021年24期)2021-04-25
中南大学学报(自然科学版)(2016年2期)2017-01-19
中国照明(2016年4期)2016-05-17
橡胶工业(2015年9期)2015-08-29
橡胶工业(2015年6期)2015-07-29
橡胶工业(2015年4期)2015-07-29
中国当代医药(2015年26期)2015-03-01
中国洗涤用品工业(2015年9期)2015-02-28
