
高铁大风预警模式挖掘*
2020-05-06 01:44刘鉴竹祝锦烨勾红叶
国防科技大学学报 2020年2期
滕 飞,刘鉴竹,祝锦烨,勾红叶
(1. 西南交通大学 信息科学与技术学院, 四川 成都 611756; 2. 西南交通大学 土木工程学院, 四川 成都 610031)
截至2017年6月,我国已建成73条线路的高铁防灾减灾系统,其中风力监测点2612处,形成了能够实时监测铁路沿线大风情况的高铁防灾网[1],为灾害情况下的行车预警提供了数据支持。目前高铁大风预警采用基于风速预测的人工调度处置模式,但由于风力监测系统与指挥调度系统物理隔离,效率较低,与高速铁路遇大风行车的预警需求还存在一定差距[2]。日本的京叶线引入了大风预警系统,主要根据风速计的监测值预测短期内风速的上限值,当任意监测点预测风速的上限值或检测值超出报警阈值,即发布列车运行限速命令[3],德国高铁也采用了相似的风速短时预报系统[4]。近年来,铁路沿线风速预测的研究受到关注[5-10],但基于单值预测的方法时效性较差,预测的时间粒度在分钟量级,不符合由《高速铁路自然灾害及异物侵限监测系统铁路局中心系统暂行技术条件》规定的高铁行车遇大风的报警事件规则[11-12]。根据《铁路自然灾害及异物侵限监测系统工程涉及暂行规定》,风速持续10 s在15~20 m/s时,行车时速不高于300 km/h;风速持续10 s在20~25 m/s时,行车时速不高于200 km/h;风速持续10 s在25~30 m/s时,行车时速不高于120 km/h;风速持续10 s大于30 m/s时,禁止动车组进入风区,而解除报警则需连续600 s低于超限值[13-14]。
总体来说,现施行的高铁大风预警技术,依赖于预测的准确程度和时效程度,难以达到秒级粒度条件下的高精度预测,不符合现有的高铁遇大风事件的报警规则,易发生误报和漏报。故此,本文提出基于序列模式挖掘的预警方法,将单值预测问题转化为序列状态的判定问题,对发生在报警事件前的序列集合进行模式挖掘,找出有意义的预警序列模式,用于预测报警事件的发生。频繁序列模式代表了序列集合的特征,是该序列集合中频繁发生的子序列[13]。频繁序列模式曾在很多领域得到应用,如在气象领域对高温、大风、暴雨等报警事件的预警,能够识别出发生在报警事件前的序列特征,进而做出有效的预警提示。值得注意的是,序列模式虽然能够有效地提前识别出报警事件,但由于非预警序列与预警序列存在一定的相似度,易造成误报,给调度人员传递出不必要的预警信息。因此,去除冗余和无效的频繁序列模式成为解决此问题的关键。
此外,监测系统采集的风数据体量巨大且源源不断。以兰新高铁线为例,每个风监测点一年的采样数据超过100亿条,数据量超过1 TB。序列模式挖掘算法复杂度较高,无法在单机完成计算。因此,预警模式挖掘方法需要支持并行化,增加频繁序列模式的长度[14]。本文选用并行计算框架Spark,实现了基于内存存储的预警模式挖掘并行化算法,相较于传统磁盘阵列存储,可以在极大降低I/O操作时延的同时,保持良好的横向扩展性,适合用于处理实际应用中的工业数据[15]。
针对上述问题,本文提出了基于序列模式挖掘的高铁大风预警方法。通过寻找预警频繁序列和非预警频繁序列的最长公共子序列,剔除频繁序列模式中的冗余和无效模式,构建了预警模式库。利用兰新高铁沿线实测数据对预警模式挖掘和预测方法进行了实验,验证了该方法的有效性、区域适用性和执行效率。该方法在提高预测准确率的基础上降低漏报率,同时减少了模式匹配所需的时间,为提前预警预留充分的时间窗口,更加符合实际应用的需求。
1 相关工作
目前,我国高铁行车指挥采用人工调度处置模式,存在方式落后、效率低下等问题[2]。近年来,有学者研究了如何提高大风预警的准确性。Liu等[5-6,10]先后提出了基于递归经验模态分解的自回归积分滑动平均模型(AutoRegressive Integrated Moving Average model, ARIMA)预测方法和基于小波神经网络的预测方法,在预测精度和时效性方面都取得了较好的结果。然而ARIMA模型的参数定阶问题难以自动化得到结果,而基于小波神经网络方法的预测误差会随着时间的推移而增大,不符合实际需求。针对传统神经网络对非平稳风速的预测精度较差的问题,路学海等[7]提出了改进的量子粒子群算法结合小波神经网络的滚动预测方法,优化了小波神经网络的初始参数;王瑞等[8]利用Kalman滤波去除了数据冗余,提出基于径向基函数(Radial Basis Function, RBF)神经网络的滚动预测方法。上述两项研究均是仿真研究,未能利用铁路沿线的实测风速数据进行实验。Li等[9]将风向引入高铁大风预警问题中,研究了基于Kalman滤波的风速、风向预测,进而输出高铁行车的综合风险系数。
上述基于风速预测的预警技术存在以下两个问题。首先,以上研究侧重于提高风速预测的准确性,而非针对实际的报警事件进行预测。事实上,高铁沿线的风速值预测问题与高铁大风预警问题并不能完全等价。其次,现实中高铁大风报警规则精确到秒,而以上研究中风速序列的时间单位为分钟或小时,难以满足秒级粒度的实际需求。故此,本文将高铁大风的单值预测问题转化为更细粒度的序列状态判定,通过挖掘报警事件前序数据中的频繁模式,找出报警事件的变化规律,符合高铁大风报警规则这类持续超限报警的应用背景。
序列模式挖掘被广泛应用于许多领域的事件预测。严兆斌等[16]针对公路隧道交通事故问题,利用PrefixSpan算法生成了隧道交通事件序列模式,反映隧道交通事件的序列特征,并用于建立隧道交通事件规则库。冯钧等[17]针对洪水预报问题,提出构建适用于待预报流域的暴雨洪水模式库的思想,通过对历史水文数据进行符号化模式挖掘处理,完成中小河流暴雨洪水模式库构建。张光兰等[18]针对通信网络的报警预测问题,提出一种基于拓扑约束的序列模式挖掘方法来发现有意义的报警序列模式以实现报警预测,从而保证通信网络的稳定性和可靠性。Niyazmand等[19]针对报警泛滥问题,利用改进的PrefixSpan算法对天然气加工厂的报警数据做序列模式挖掘,利用得到的频繁序列模式定位造成报警泛滥的原因。Yasmin等[20]对基于序列模式挖掘的分类算法进行改进,在提高分类速度、可扩展性的同时,保持了分类的准确性,解决了高精度的数值数据难以挖掘的问题。此外,序列模式挖掘用于预警的研究还涉及库存采购预警[21]、交通堵塞预警[22]、传感器故障预警[23]等领域,但在列车行车报警预警方面还鲜有涉及[24]。
上述基于模式挖掘的预警研究,均是从报警事件前的序列集合中挖掘出有意义的模式,以作为预测报警事件的依据。然而,预警数据和非预警数据在一定程度上是具有共性的,若只考虑预警状态到报警状态的模式,会在实际应用中造成大量的误报警。对此,本文不仅针对预警数据做序列模式挖掘,还分析了非预警数据的频繁序列模式,通过去除冗余提高了预警的准确率。
2 问题定义
首先对预警模式挖掘方法所涉及的符号及名称给出相关定义:
定义1 超限报警事件。根据报警规则(超限值OverVal、超限持续时间Tper)确定以起点索引si和终点索引ei的n条报警序列(i∈[1,n]且i∈Z,n≥ 1),如图1的序列c所示。
定义2 预警序列。给定固定窗口大小为Tew,预警序列是截取每条报警序列数据前Tew个值组成的序列,即序列索引在(si-Tew)~(si-1)对应的值构成的序列,如图1的序列b所示,虽然该序列含有超限数据,但其超限持续时间小于相关阈值,并不符合报警事件规则。
定义3 非预警序列。非预警序列是序列索引在(si-Tinter)~(si-Tew)的值构成的序列,如图1的序列a所示。为使预警序列数据和非预警序列数据在相同的窗口大小下进行序列模式挖掘,应将每条序列长度大于Tew的非预警序列进行数据分段,以每段序列长度为Tew的序列集合形式组成非预警序列集,以保证模式挖掘的结果均是Tew内发生的频繁序列模式。
序列模式挖掘是指从序列数据库中寻找频繁子序列作为模式的知识发现过程,即输入一个序列数据库和支持度阈值,输出所有不小于支持度阈值序列的过程[25]。序列模式挖掘算法可分为基于Apriori和基于模式增长两类。本文涉及序列模式挖掘算法,并以基于模式增长类的PrefixSpan算法为例给出相关定义。
定义4 子序列。对于序列a=
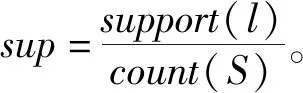
定义6 前缀。设每个元素中的所有项目按照字典顺序排列,给定序列a=

图1 预警序列及非预警序列Fig.1 Alarm sequence and non-alarm sequence
定义7 投影。给定序列a和b,如果b是a的子序列,则a对应于前缀b的投影a′需满足b是a′的前缀;a′是a满足上述条件的最大子序列。
定义8 后缀。设序列a关于子序列b=
定义9 投影数据库。设a为序列数据库S中的一个序列模式,序列b以a为前缀,则a的投影数据库为S中所有以a为前缀的序列相对于a的后缀,记为S|a。
例:考虑表1中的序列集合,设置支持度阈值sup为0.75。
1)对数据库中的所有项进行支持度统计,将支持度低于阈值的项从数据库中删除,得到前缀长度为1的频繁序列模式{ ∶4, ∶2};
2)对于每个长度为1满足支持度要求的前缀进行递归挖掘,以为前缀投影数据库的结果为{<(_B),B>,<(AB),B>, ,<(_B),A,B>},满足支持度要求的有{B∶4,_B∶3},即以为前缀挖掘到的前缀长度为2的频繁序列模式有{
3) 递归执行2),得到前缀长度为3的频繁序列模式有<(A,B),B>。若投影数据库为空或投影数据库中各项支持度计数都低于阈值则递归返回。综上,在该例中由PrefixSpan算法得到大于支持度阈值0.75的频繁序列模式集为{,,

表1 序列数据集示例Tab.1 An example of sequence dataset
3 预警序列模式挖掘方法
为了除去预警数据和非预警数据的公共频繁序列,降低将非预警序列识别成预警序列的概率,本节提出预警序列模式挖掘方法,其流程如图2所示。主要步骤有:①根据报警规则生成预警序列数据和非预警序列数据;②利用序列模式挖掘算法生成预警频繁序列和非预警频繁序列;③采用最长公共子序列算法去除预警数据和非预警数据的公共频繁序列,以生成预警模式库;④在测试或实际应用中,将目标序列与预警模式库中的模式进行模式匹配,若能匹配成功则表示在这段时间后将发生报警事件,应及时通知相关人员发布预警信号。
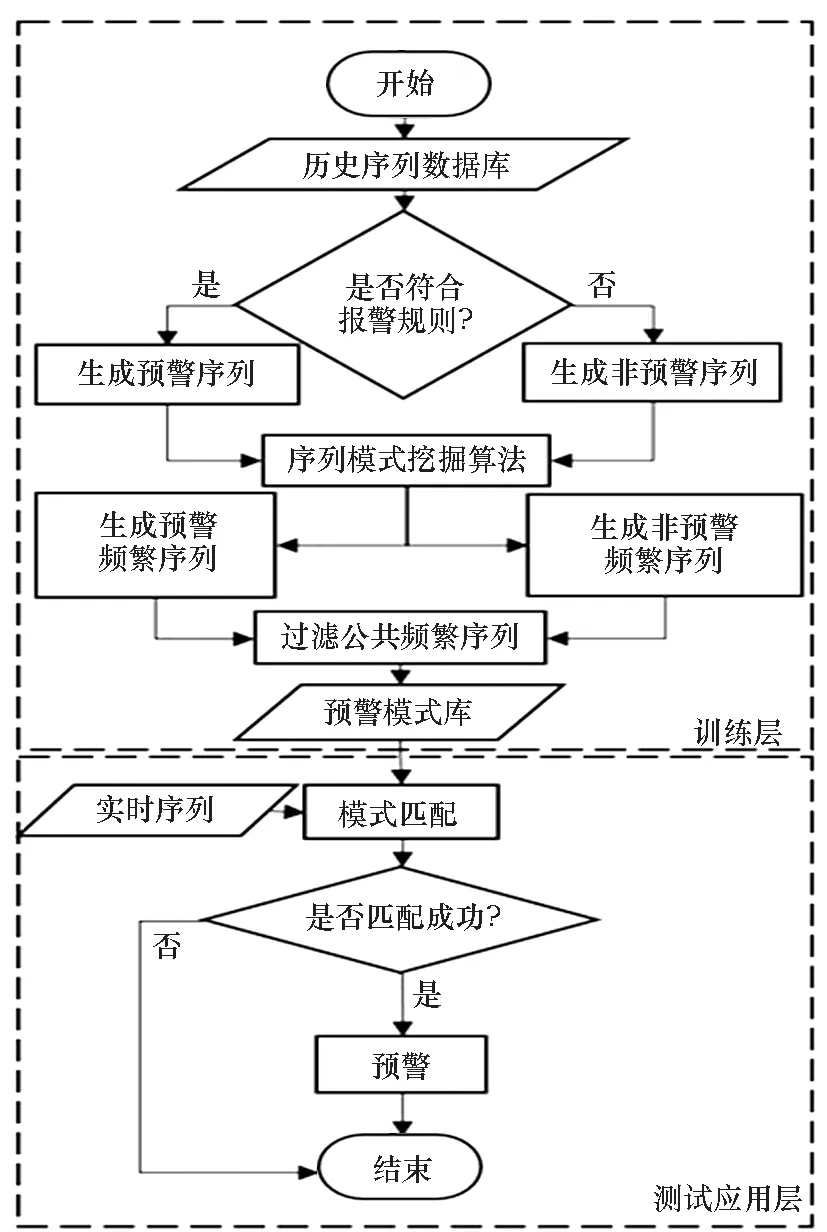
图2 预警序列模式挖掘方法流程图Fig.2 Flow chart of sequential pattern mining for early warning
3.1 预警模式库构建
首先根据第2节中对于预警序列和非预警序列的定义,在原始的时间序列数据中筛选出报警事件数据、预警序列数据和非预警序列数据。考虑到时间序列普遍维度很高,不能直接进行模式挖掘,且对于需要对每个前缀做投影操作的序列模式挖掘算法而言,若存在大量的单项,会直接增加算法的时间复杂度和空间复杂度。为解决时间序列的高维特性,通常会进行时间序列符号化操作,该操作能提高存储的效率,加快处理速度。
为了降低将非预警序列识别成预警序列的概率,分别对预警序列和非预警序列做序列模式挖掘,进而得到两者的公共频繁序列模式,即不能明显区分是否预警的序列特征,在预警序列的频繁模式集中除去包含非预警频繁序列的特征,仅保留能准确辨识预警的分类依据,完成预警模式库的构建。
3.2 预警模式匹配
最长公共子序列(Longest Common Subsequence, LCS)算法旨在求得两个或多个已知序列的最长子序列[26]。此处的子序列是指从序列中得到各个元素属于原始序列(顺序且不一定连续的序列)。如字符串序列“aabcd”和“abcabc”中,两者的公共子序列有顺序且相邻的“abc”,也有顺序且不相邻的“aabc”,所以两者的最长公共子序列为“aabc”。该算法在预警模式挖掘方法流程中,应用于去除预警序列和非预警序列的公共频繁序列模式和验证是否预警,其实现的功能均为在目标序列中检测是否存在非预警频繁序列的特征。
当序列的数量一定时,LCS求解可以采用动态规划方法,以空间换时间的思想,用数组保存中间状态,方便后续计算。记序列X的前i个元素为Xi={x_1,x_2,…,x_i},序列Y的前j个元素为Yj={y_1,y_2,…,y_j};序列X和序列Y的最长公共子序列为LCSXY;序列X的前i个元素和序列Y的前j个元素的最长公共子序列为LCSXiYj。设置二维数组C[i,j]记录X和Y子序列的最长公共子序列长度,则可得到式(1)的状态转移方程。根据式(1),可通过递归计算出每个子序列的LCS,并依据二维数组C回溯得到最长公共子序列LCSXY。通过基于LCS的模式匹配方法,求得预警模式和测试集中每条窗口序列的最长公共子序列,若最长公共子序列与该预警模式相等则表示匹配成功。
(1)
在第2节中,从基于PrefixSpan算法的频繁序列模式挖掘的示例中可以发现,原始算法的结果集为所有满足支持度阈值的频繁序列模式集,而对于预警模式库来说,长度较短的频繁序列模式不宜作为预警模式,由相同前缀组成的非最长频繁模式会造成结果集的冗余,且模式库中会因此类频繁序列模式的存在而增加模式验证的运行时间[27]。算法1给出了预警序列模式挖掘算法,分别以相同支持度阈值挖掘预警序列数据库和非预警序列数据库中大于模式长度阈值且由相同前缀组成的最长频繁序列模式,并采用LCS算法在预警频繁序列中除去包含非预警频繁序列模式的特征,完成预警序列模式库的构建。

算法1 预警序列模式挖掘算法Alg.1 Early warning sequence pattern mining algorithm
4 实验结果与分析
4.1 实验环境
本文数据存储介质为Oracle 11 g,在Spark2.7.0搭建的完全分布式环境下进行实验。Spark集群总节点数为3,每个节点的配置为:Intel(R) Xeon(R)四核E5-2620 2.10 GHz处理器;8 G内存;Ubuntu 16.04LTS的操作系统。
实验采用兰新高速铁路沿线风基站2017年实测数据,其采样频率为1 Hz。在模式挖掘实验之前对原始数据进行了缺失值、异常值等数据预处理。
4.2 预警模式挖掘实验
选用兰新高铁沿线位于百里风区的5696风基站实测的共15 638 400个风速值构成的时间序列。根据高铁行车限速规定,设置风速超限值OverVal=15 m/s;超限持续时间Tper=10 s。根据《客运专线防灾安全监控系统总体技术方案》,对风速变化快的强对流短时大风,预警时间不少于2 min;而对风速变化慢的季节性大风,预警时间不少于5 min。因实验数据属于百里风区,故设置预警时间Tew=120 s,非预警时间Tinter=7200 s。
在上述实验过程的符号化阶段,考虑到大风报警事件规则要求风速超限具有持续性的特点,将某一范围的风速值映射为某一符号,表2为符号化映射规则(风速单位为m/s)。风速小于OverVal超限值(15 m/s)按照风力等级对照表划分,大于OverVal超限值(15 m/s)按照报警事件的临界风速划分。
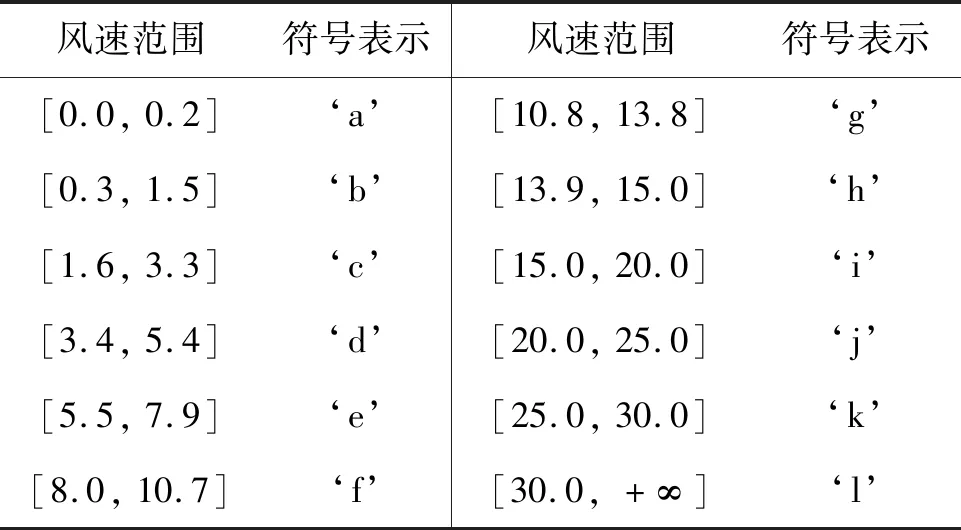
表2 符号化映射规则Tab.2 Symbolic mapping rules
为了检验该预警模式挖掘方法的有效性,据二八定律,将预警序列集按报警时间先后顺序以8 ∶2的比例分为预警训练集和预警测试集,并在非预警序列集上以相同比例划分为非预警训练集和非预警测试集。为使得序列模式挖掘算法得到的频繁模式均发生在一定的时间内,固定窗口大小为预警时间(本实验中Tew=120 s),将非预警序列集中大于窗口大小的序列划分长度为Tew子序列。本实验利用训练集中的预警序列和非预警序列做预警模式挖掘,在测试集中进行预警模式验证实验。预警模式挖掘算法中的输入参数sup,Lmax,Lmin分别设置为0.3、120、60,一共得到15 442条序列长度大于Lmin的频繁模式,经过滤相同前缀组成的非最长频繁模式后,保留8009条由前缀组成的最长频繁模式作为预警模式库。部分具有典型的预警模式见表3(由于模式长度较长,在表3中将预警模式库的结果表示为[‘符号’ ∶持续出现的次数]的字典集合),表中风速单位为m/s。
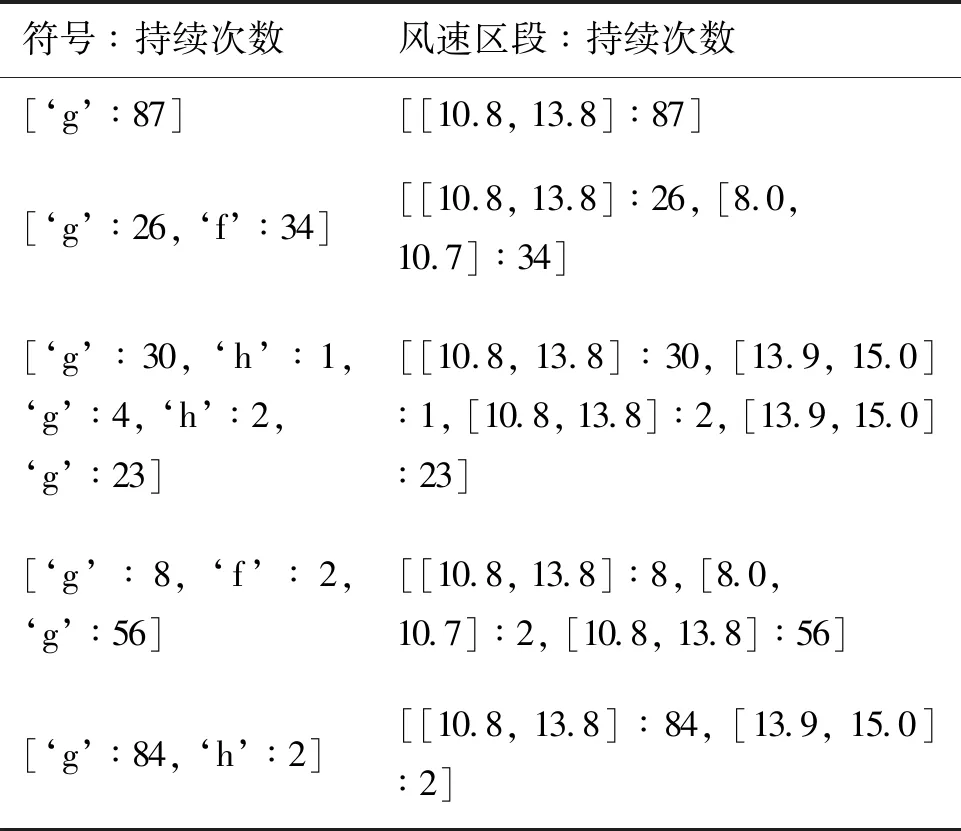
表3 部分典型预警模式Tab.3 Partial typical early warning patterns
由预警模式库可知,在1级报警事件发生前风速不会发生大幅度的突变,且风速在8~15 m/s范围内变化。图3的五种典型预警模式,其“典型”在风速在不同区段间的趋势变化规律,“非典型”的预警模式与这五种的区别在于风速在不同区段持续的次数不同,其形状规律与以上五种相似,如图3所示。
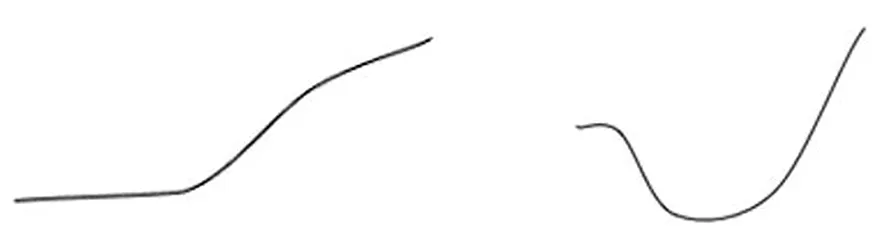
(a) 稳定变化型 (b) 先降后升型(a) Stable (b) Fall-rise

(c) 波动型(c) Fluctuant

(d) 先降后阶梯型 (e) 阶梯型(d) Fall-step-up (e) Step-up图3 预警模式大致形状总结Fig.3 Shapes of early warning patterns
4.3 预警模式验证实验
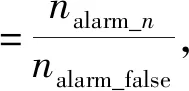
本实验的验证指标如下:
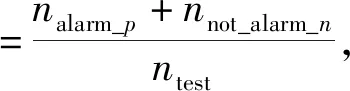
本实验分别选用FPGrowth、PrefixSpan两种不同的模式挖掘算法进行验证,序列模式挖掘算法FPGrowth需要反复循环扫描数据库,复杂度较高。而PrefixSpan挖掘算法,无须生成候选序列,数据量较大的情况下只需扫描2次数据库进行递归计算,效率更好。选取兰新高铁沿线位于百里风区的5696风基站在2017年实测的风速序列,该实验旨在验证去除非预警频繁序列对预警准确率的影响。
表4中,传统方法只考虑预警序列模式,而本文方法剔除了非预警频繁序列。实验结果表明,基于序列模式挖掘的预警方法能够识别出报警前的序列特征,起到预警作用,对比传统序列模式挖掘方法,其准确率和漏报率都有所改进,原因是传统序列模式挖掘方法不能有效区别预警序列和非预警序列共有的频繁模式,这一点在FPGrowth上表现得尤为明显。FPGrowth算法特殊的数据组织形式,要求一个序列中的元素最多出现一次,使得挖掘得到的序列模式的种类少于PrefixSpan算法,但却包含了更多的公共频繁模式。因此,FPGrowth极易产生假预警,将非预警序列预测为预警序列,导致准确率很低。由此可见,预警模式挖掘方法可对冗余和无效的模式进行有效过滤。

表4 模型性能Tab.4 Model performance %
为了验证本文算法的区域适用性,选取兰新高铁沿线多个风基站进行该验证实验。表5显示了兰新高铁沿线的8528、8496、8512三个风基站在2017全年数据的预警结果,准确率和漏报率这两个指标均保持较好的一致性,说明本文提出的方法具有较好的区域适用性。
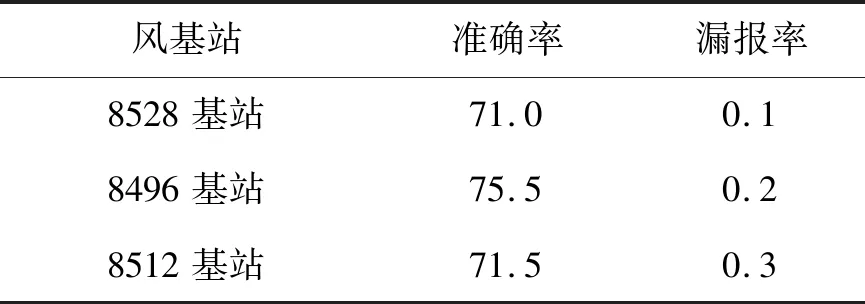
表5 区域适用性Tab.5 Regional applicability %
4.4 执行效率实验
由于单机上计算超时,本文采用3个节点的Spark Cluster进行并行计算。不同长度预警序列的匹配时间对比情况如表6所示。基于模式序列的预警方法旨在在较短的时间内相对高精度地预测出未来的报警事件。由于模式匹配算法复杂度较高,需要留出充分的时间窗口才能达到预警效果。期望的预警时间越早,预留给匹配的时间就越长。本文提出的预警方法较传统方法可降低匹配时间。对于2 min预警序列,本文方法可将预警窗口从113.2 s延长至116.6 s。对于20 min预警序列,采用传统方法,匹配时间消耗19.5 min,实际有效预警窗口仅为0.5 min,而本文方法可将有效预警窗口延长至9.1 min,这说明本文方法具有较高的工程实用性。

表6 任务运行时间比较Tab.6 Runtime comparison
5 结论
本文针对兰新高铁动车组列车遇大风行车限速报警事件进行了预警方法研究。针对单值预测法精度不够且不符合高铁大风事件的报警规则,提出了基于序列模式的预警方法。考虑到非预警序列模式对预警准确率的影响,提出了预警和非预警序列的公共频繁模式过滤方法,从而得到预警序列独有的序列特征,完成了高铁行车遇大风预警模式库构建,并使用兰新高铁沿线的多个风基站数据验证了该方法的有效性,证明了该方法具有区域适用性。该预警模式挖掘方法从实际应用出发,可在提高预测准确率的基础上降低漏报率,同时有效地减少了模式匹配所需的时间,为提前预警预留更长的时间窗口,符合实际应用的需求。
猜你喜欢
鸭绿江(2021年17期)2021-10-13
海洋通报(2020年5期)2021-01-14
中国电业与能源(2020年5期)2020-06-16
铁道通信信号(2018年5期)2018-06-28
幼儿100(2017年31期)2017-11-27
幼儿100(2017年28期)2017-10-27
小雪花·成长指南(2016年9期)2016-10-12
汽车维护与修理(2016年10期)2016-07-10
西南交通大学学报(2016年4期)2016-06-15
风能(2016年11期)2016-03-04
