
基于RFM 模型的电子商务客户细分
2020-05-02 05:35:46陈子璐
市场周刊 2020年4期
陈子璐
一、 引言
随着互联网技术的不断成熟,电子商务在各国都快速发展,但同时也面临着激烈的市场竞争。 在中国有淘宝、京东、聚美优品等电子商务平台,在国外有亚马逊、eBay 等。 在这种条件下,电子商务领域需要像传统的市场营销一样进行客户细分,客户关系管理(Customer Relationship Management,CRM)通过探索客户和商家之间潜在的关系来评估和维护客户关系,从而满足客户日益增长的个性化需求,以便通过差异化服务、针对性策略吸引客户,形成长期购买行为,提高客户忠诚度,在激烈的市场竞争中立于不败之地。 本文通过RFM 模型,用两种方法对客户进行细分并比较两种方法的优缺点,企业可自行选择。 徐翔斌等通过引入总利润属性,建立RFP 模型,对电子商务客户做了客户细分。 刘慧婷等提出了基于经验模态分解方法( Empirical Mode Decomposition,EMD)和K-Means 的客户行为聚类方法,为商家提供了促销依据。 包志强等通过引入平均单次订单消费金额,建立RFA模型,对百度外卖进行客户细分,但在K-means 聚类确定cluster(簇)的个数和计算客户价值时,权重的确定有些主观,本文通过肘部曲线与四分位法改进了以上不足。 通过上述研究表明,RFM 模型和企业客户细分结合研究,可以针对细分结果的不同,使客户拥有更好的产品体验,使商家得到更多的利润和有价值的客户。
本文以一家线上公司客户数据为例,通过RFM 模型,用两种方法进行客户细分,第一种采用K-means 聚类算法进行客户细分。 第二种,是本文提出的四分位法计算确定客户的个人价值,达到对不同价值的客户分别采取针对性策略的效果。 最后对两种方法进行比较。
二、 RFM 模型
在众多客户关系管理的客户分析模式中,RFM 分析是比较受欢迎的分析方法,是衡量客户价值的重要评价指标。RFM 模型最初由Hughes 于1994 年提出,曾被广泛应用于直销领域,它包括R(Recency)、F(Frequency)、M(monetary)3个变量。R表示最近一次购买时间,也叫近度(Recency),理论上最近一次购买时间越近的用户对提供即时商品或服务也最可能有反应,因此R越小越好;F表示消费者在某个时间段中的购买次数,也叫频度(Frequency),经常购买的消费者越有意向再次购买,客户忠诚度高,因此F越大越好;M表示某个时间段中客户购买的总金额,也叫额度(Monetary),购买金额越大,给企业带来的价值越大,因此M越大越好,即客户的价值与R成反比,与F、M成正比。 企业可以使用RFM模型测量客户价值,并使用RFM 模型指标对客户进行分类。RFM 模型计算客户价值公式如式(1):

其中RFM 指客户的综合RFM 值,ωR、ωF和ωM分别是R、F和M在计算客户价值的权重,R、F和M在本文中的含义如表1 所示。

表1 RFM 模型及各指标在文中的含义
三、 权重分析
对于RFM 各变量的指标权重选取问题,Hughes 于1994年提出应该同等看待3 个指标,为其赋予相同的权重。 Stone于1995 年对客户信用卡相关信息进行研究分析时,结合行业特殊性,认为RFM 模型中的消费频率最为重要,其次是最近消费时间,最后是消费金额。 传统的权重的计算大多采用层次分析法和专家咨询相结合的方式来确定,这种方法带有很强的主观色彩,是不精确的, 本文用四分位法,使权重选取更加科学。 本文用两种方法来计算客户价值与细分客户,一种方法为K-means 聚类,另一种方法称为四分位法,来计算客户价值。
(一)K-means 聚类
K-means 聚类是最著名的划分聚类算法,由于简洁和效率使得它成为所有聚类算法中最广泛使用的。 K-means 聚类算法是一种迭代求解的聚类分析算法,其步骤是随机选取k个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。 聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算,这个过程将不断重复直到满足某个终止条件。
K-means 算法支持没有任何先验知识情况下,对多个属性进行聚类分析,算法分为以下几个步骤:
第一步:随机选取k个样本均值点,本文用肘部法则发现k为3,记第i个均值为
第二步:计算各个样本点到各均值点的距离,距离最短的归到一类。 本文使用欧几里得方法计算距离,如式(2)所示:
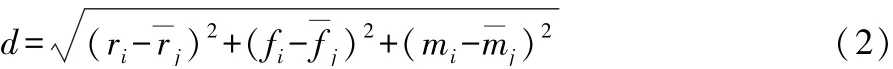
j=1,2,…,k,i=1,2,…,n,d是第i个样本点到第j个均值的距离,ri、fi、mi分别是第i个样本点的R、F、M的值。
第三步:对第二步得到的新的k类,分别求取期望,得到新的均值点,计算方法如式(3):
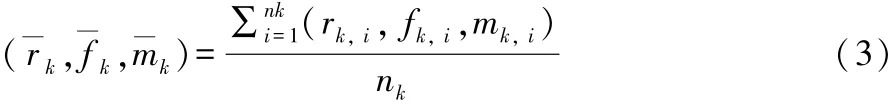
第四步:重复二、三步,直到操作得到的样本均值点不再显著变化为止。
本文将使用Python 软件,进行K-means 聚类,再通过肘部曲线,更加科学地确定了k为3。
(二)四分位法
本文把R、F、M按照大小平均分成四份,即按四分位分成四份,R、F、M的四分位数如表2 所示。
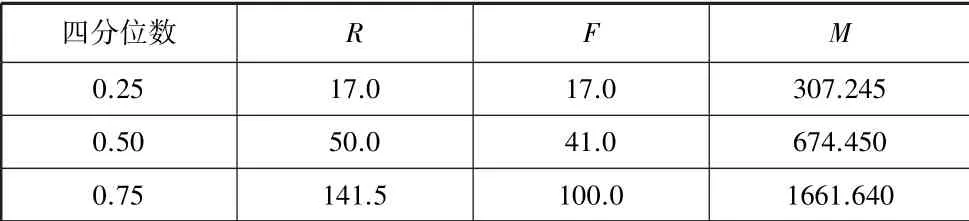
表2 R、F、M 的四分位数
因为F与M越大,客户价值越高,本文把F与M的四份从小到大排列,分数依次为1,2,3,4;而R越大,客户价值越低,本文把R 的四份按照从小到大排列,分数依次为4,3,2,1。 最后得到的分数如表3 所示。

表3 RFM 中各个值代表的分数
本文的分数表现形式有两种,一种是把所有的分数排列在一起,表现形式如表4 中RFM score 一列,如“最佳客户444” “快丢失客户421”;另一种表现形式是把所有分数相加,总分数在3 至12 中间,表现形式如表4 中Total_score一列。
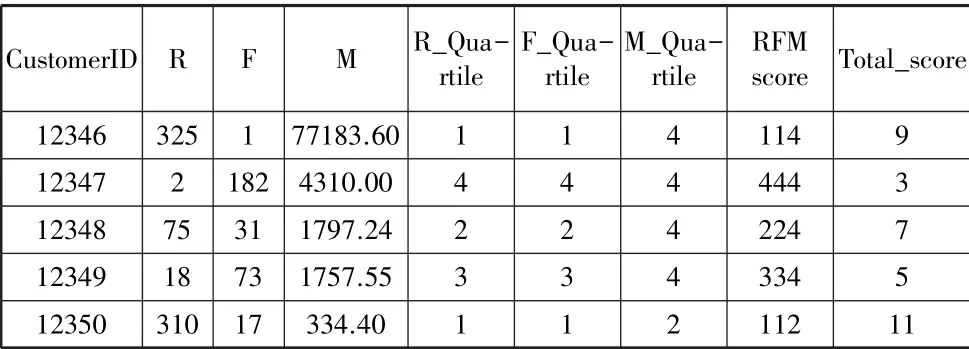
表4 RFM 模型的顾客价值分析结果
四、 数据整理
本文利用Kaggle 网站上提供的一家礼品线上公司从2010 年12 月1 日至2011 年12 月9 日的397924 个订单数据。 其中某客户订单交易样本为表5 所列。表5 原数据中某客户的交易订单

数据来源:https:/ /www.kaggle.com/carrie1/ecommerce-data.WHITE HANGING HEART T-LIGHT HOLDER 白色悬挂爱心图像的T 型灯架。
数据选取的时间是2010 年12 月1 日至2011 年12 月9日的数据,那么把2011 年12 月9 日设为现在时间,用现在时间减去购买时间可以得出最近一次购买时间(R)。 计算每个顾客代号重复了几次,重复的次数则为这段时间的频率(F)。购买总金额(M)可以通过产品单价与购买数量得到,如公式(4)所示:
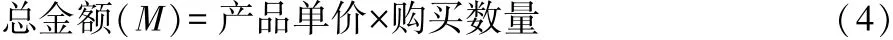
使用Python 进行数据分析,从中可得到共有客户4339位,并且可以统计出每位客户的近度(R)、频度(F)、额度(M)。 某客户的订单交易样本数据如表6 所列。

表6 整理后的某客户的订单交易
五、 数据分析与结果
(一)K-means 聚类结果
R、F、M变量作为聚类变量,基于Python 语言,采用Kmeans 聚类方法对数据进行数据分析。 本文用肘部法则(Elbow Method)来得到K值,肘部法则可以追溯到Thorndike在1953 年提出的推测,K-means 是以最小化样本与质点平方误差作为目标函数,将每个簇的质点与簇内样本点的平方距离误差和称为畸变程度(distortions),那么,对于一个簇,它的畸变程度越低,代表簇内成员越紧密;畸变程度越高,代表簇内结构越松散。 畸变程度会随着类别的增加而降低,但对于有一定区分度的数据,在达到某个临界点时畸变程度会得到极大改善,之后缓慢下降,这个临界点就可以考虑为聚类性能较好的点。 从Python 中得到肘部曲线,如图1 所示,可以发现临界点为A点,则K=3。
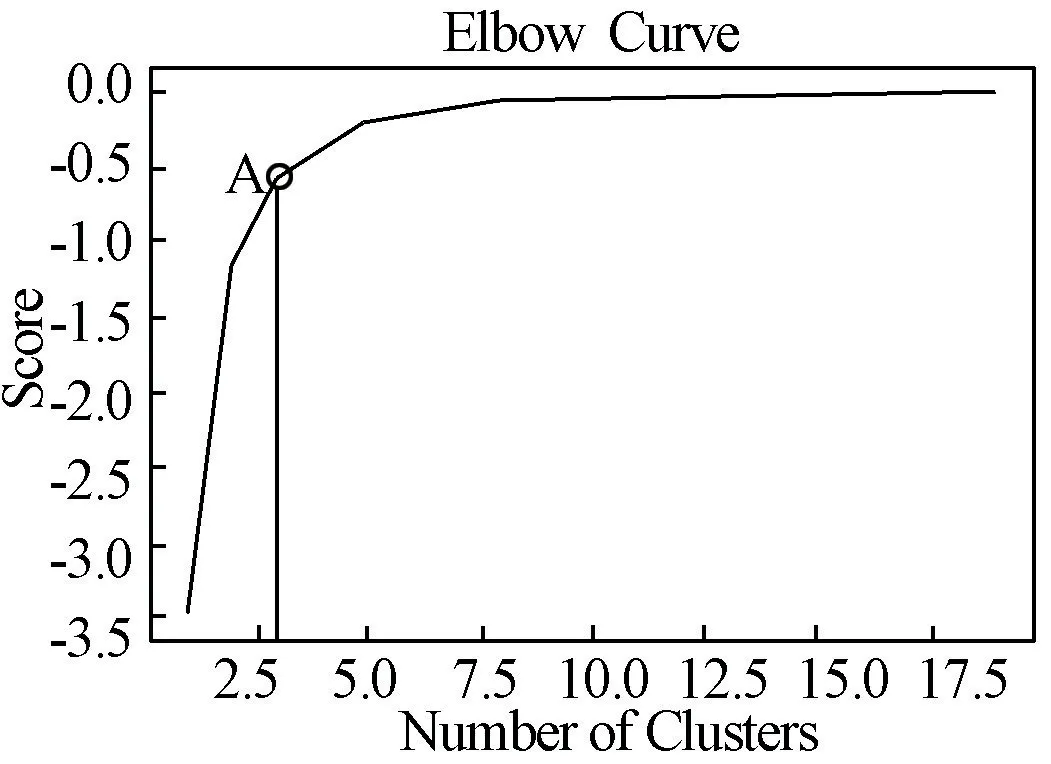
图1 肘部曲线
对这三个Cluster(簇)分别命名为0,1,2,可以得到客户的数据如表7 所列。

表7 对Cluster 进行命名后的某个客户的交易订单
从图2~4 可以看出1 簇的购买金额最大,频率最高,且最近购买时间最短,是企业的大客户;2 簇的购买金额较大,频率也较高,且最近购买时间也较近,是企业的潜在客户;0 簇的购买金额最少,频率也最低,且最近购买时间较长,可以看作是企业的临时用户。 若把这三类客户从重要性上分成铂金会员、黄金会员和一般会员,可以得到Cluster 1 为铂金客户,Cluster 2 为黄金用户,Cluster 0 为一般用户,如表8 所示。

图2 Recency 的箱型

图3 Frequency 的箱型
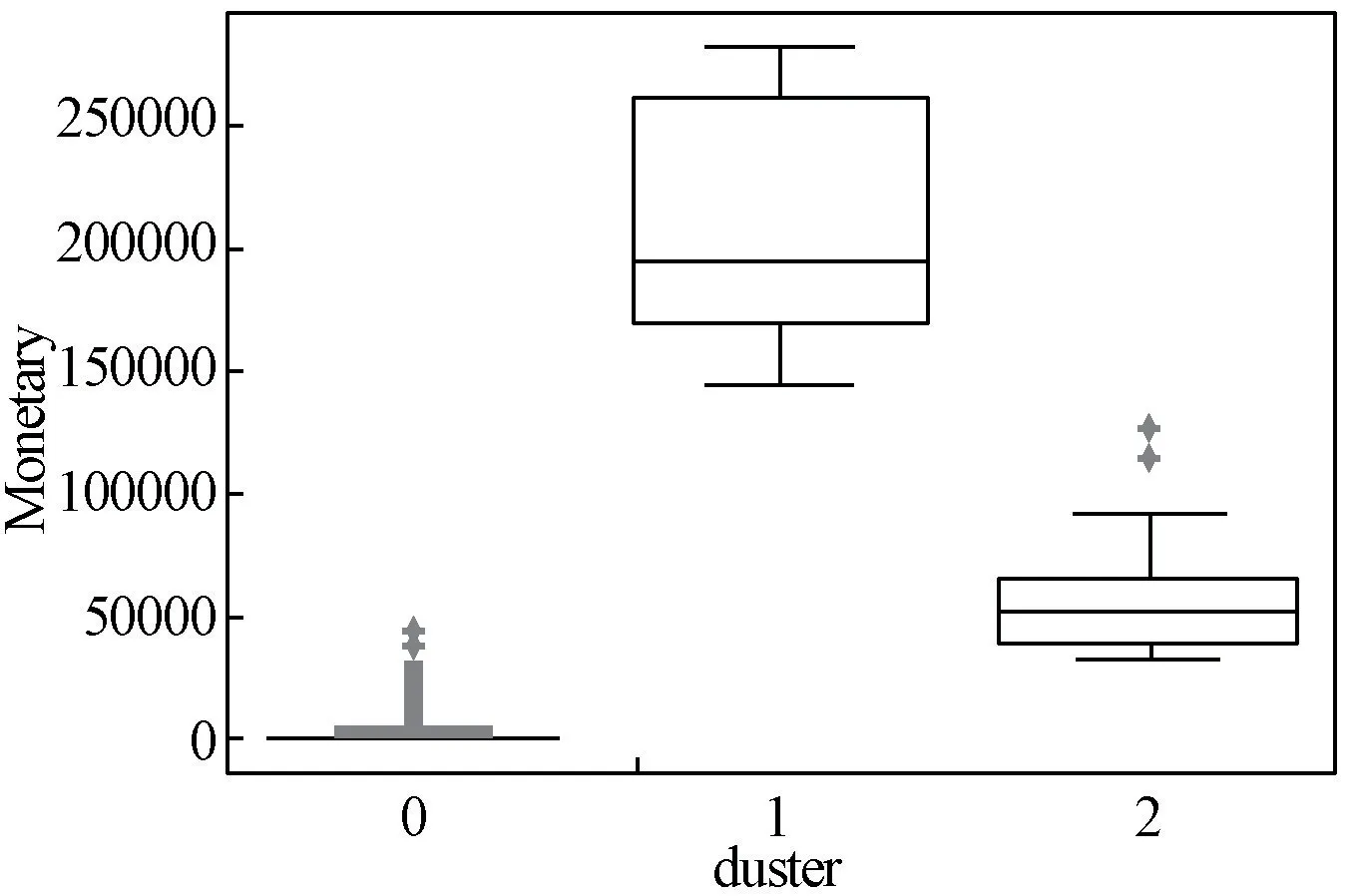
图4 Monetary 的箱型
(二)四分位法细分的结果
本文把R、F、M按照四分位数分成四份,F与M的四份从小到大排列,分数依次为1、2、3、4; R 的四份按照从小到大排列,分数依次为4、3、2、1。R、F、M的四分位数如表2。 本文的分数表现形式有两种,一种是把所有的分数排列在一起,如“444”“421”;另一种表现形式是把所有分数相加,则总分数在3 至12 中间,如表4 所示。
从上面的分数公司可以更详细的细分客户与找到潜在客户,如最优客户“444”,共有440 人,占所有客户的10%,这类客户的金额、频率都是最高,且最近购买时间最短,公司针对这类客户可以以送积分兑换礼物,或者开放更多的特权来提高这些客户的黏着度。
“411”“412”“421”“422”这类客户都可以看作快丢失的客户,这类客户的数量是187。 这类客户的特点是最近购买的时间短,且购物金额与频率较低。 针对这类客户,公司可以推送商品、广告或折扣来吸引顾客重新回购商品。
“144”“134”“133”“143”这类客户频率高、金额高,但是最近购买时间长。 这类客户有127 位,可以看出这类客户对产品满意度较高,但是可能有更好的替代品或者对最近的商品不满意。 针对这类客户,公司可以以问卷调查或者访问的形式,找到客户为什么最近不愿购买商品,从而更好地改进商品,吸引顾客。
公司可以忽略“111”类客户,这类客户金额少、频率低,且最近购买时间短,共有人数384 人。 可能这类客户对这类产品并不感兴趣。 为了节省人力成本或生产成本,公司可以不用特别注意这类客户。
(三)两种模型结果比较
K-means 聚类方法分类科学,采用的是肘部法则,有理论基础,但是研究人员并不了解每一类所代表的意义,需要进一步的分析数据,研究人员需确定,Cluster 0 为一般会员。
四分位法把客户进一步细分,企业可以找到自己想要的大部分性质的客户,如最优客户“444”,但是四分位法只是简单粗暴地把各个用户按照性质分成12 份,其中客户的区别可能很小,如“411”与“412”,都可以看作快丢失客户。
六、 结语
本文基于RFM 模型采用K-means 聚类和四分位法对客户进行细分,帮助企业找到优质客户、潜在客户,对客户价值进行识别,识别结果客观可信。 K-means 方法通过肘部法则,科学的找到分类数量k,而本文提出的新的方法四分位法,则对客户进行了进一步的细分。 企业可以根据自身的需要进行客户细分,其结果可以用于会员的精细化管理和精准营销,与高价值会员建立稳定的关系是企业得以更好发展的有效途径。
猜你喜欢
中老年保健(2021年2期)2021-08-22 07:29:02
中老年保健(2021年4期)2021-08-22 07:08:46
中老年保健(2021年3期)2021-08-22 06:50:46
华人时刊(2020年23期)2020-04-13 06:04:12
中华肩肘外科电子杂志(2019年4期)2019-08-24 06:39:16
电子测试(2017年15期)2017-12-18 07:19:27
专用汽车(2016年9期)2016-03-01 04:17:02
智能系统学报(2015年4期)2015-12-27 09:38:39
专用汽车(2015年2期)2015-03-01 04:05:42
电子设计工程(2015年6期)2015-02-27 12:04:53
