
面向社交媒体的反讽识别
2020-04-29 10:55罗观柱赵妍妍
智能计算机与应用 2020年2期
罗观柱, 赵妍妍, 秦 兵, 刘 挺
(哈尔滨工业大学 计算机科学与技术学院, 哈尔滨 150001)
0 引 言
随着社交媒体(Social Media)的高速发展, 如Twitter、Reddit、微博等已经是人们日常生活中的一部分,网民倾向并擅长在社交媒体中使用某些修辞方法来宣泄情感,比如使用幽默、讽刺或反语等表达方式来强调个人情感。在社交网络上这种发表观点或表达情感的修辞方法丰富着人类语言,但同时修辞方法的添加,给多项自然语言处理(NLP)任务带来了明显的困难。比如在情感分析任务中,以往传统的技术则难以正确检测含反语讽刺文本等修辞成分的真实情感。修辞方法的广泛运用随之带来的副作用会严重影响社交媒体文本的情感计算或观点挖掘的检测准确性,故而研究反语、讽刺或幽默等修辞方法,对于多项自然语言处理任务,尤其是情感分析、观点挖掘等具有重要意义。在社会媒体的常用修辞方法中,反语(可译作Irony)或者讽刺(可译作Sarcasm)的应用较为普遍。具体来讲,前者常使用跟作者心中原意不一致的词来强调情感,往往隐含有否定、反对、讽刺或者自嘲等情感,是一种带有强烈感情色彩的修辞方法,以“I just love being ignored ▯”为例,作者显然想表达一种被人忽视的负面情感,但字面上却使用了强烈的褒义词“love”。后者常用夸张或比喻等修辞对某对象进行一种揭露,或者批评嘲笑等,以“Good thing Trump is going to bring back all those low education high paying jobs.”为例,作者通过这种文字来表达对Trump的批判。反语与讽刺的关系[1],从某种意义上可以认为讽刺是包含作者个人情绪(比如包含攻击抨击等情绪)的反语形式的一种。为了方便表述,在本文中会将反语和讽刺统一表达为反讽一词,反语和讽刺的区别在此忽略。
反讽的类别可以进一步划分,在SemEval2018 任务3[2]中将反讽分为3类,即:前后情感矛盾(ironic by clash)、场景反讽(situation Irony)和其他反讽(other irony)。前后情感矛盾反讽比如“I justlovebeingignored▯”中的{love,ignored}为极性相反的两词,正因为这两个词的使用导致了该句话为反讽修辞;场景反讽比如“Just saw anon-smokingsignin the lobby of atobaccocompany”,“non-smokingsign”在“tobaccocompany”这种场景下才是一种反讽的说法;其他反讽为不含明显极性相反词的类型,比如“Human brains disappear every day. Some of them have never even appeared”。经统计前后情感矛盾反讽约占69.9%。本文针对反讽中的前后情感矛盾形式,设计了一种词对注意力(word pairs attention)模型,可以捕捉{love,ignored}这种极性相反词,从而可以推断一句话是否是反讽修辞。
1 相关工作
反讽是一种常用的修辞方法,国内外众多研究者对反讽理论及其识别方法做了很多工作。国内外学者对反讽检测提出了若干算法,大多数的研究都将反讽识别看作一种文本分类任务。这些算法可分为3类,分别是:基于规则的反讽识别、基于传统机器学习的反讽识别和基于深度学习的反讽识别。对此可做阐释分述如下。
1.1 基于规则的反讽识别
Tsur等人[3]提出的讽刺检测算法用到了少量标注的种子句子,但没有使用未标注数据,通过网页搜索自动扩展种子集作为训练集合(train set),然后使用拓展后的训练集合来学习并分类,学习时使用的特征包括2类:基于模板的特征和基于标点的特征。对于前者,每个模板是一个高频词的有序列表,类似于数据挖掘技术中的列表模板。后者则包括叹号、问号和引号等标点符号的数量,以及句中首字母大写和全大写的单词数量,最后使用k-近邻进行分类。
1.2 基于传统机器学习的反讽识别
Gonzalez-Ibanez等人[4]用tweets数据研究了直接表达正负面观点的讽刺和非讽刺的推文。过程中采用了基于SVM和逻辑回归的监督学习方法。特征为unigram和一些基于词典的信息,包括词类、感叹词和标点符号等。其中也用到了表情符号和恢复标记。
1.3 基于深度学习的反讽识别
基于深度学习的方法最近在NLP研究中的众多领域引起了轰动并成果显著。在反讽识别任务上,Bamman等人[5]使用待检测文本的上下文信息,并进一步挖掘社交用户的行为信息 , 设计基于深度学习的讽刺识别模型。Zhang等人[6]使用双向递归神经网络捕捉目标推特文本的句法和语义信息,同时利用与目标推文相关的历史推文自动学习特征进行讽刺识别,并取得较好的性能。Chen等人[7]和Gui等人[8]从表示学习的角度切入,提高文本分类情感分析模型的效果。Ghosh等人[9]提出的一种卷积长短时记忆网络(CNN-LSTM-DNN)取得了最好的性能。
2 词对注意力模型
针对前后情感矛盾式反讽(占比69.9%),研究提出了一种上下文无关的反讽识别模型。例如“I justlovebeingignored▯”, “Shittydrivers are alwaysfun.”,对于词对(word pairs) {love,ignored}与{Shitty,fun}在情感、状态或行为上“相反”,从这一点出发研究可以构造一种基于注意力机制[10](Attention Mechanism)的深度学习网络模型,以此用来查找矛盾词对。对此拟展开研究论述如下。
2.1 词对矛盾模型
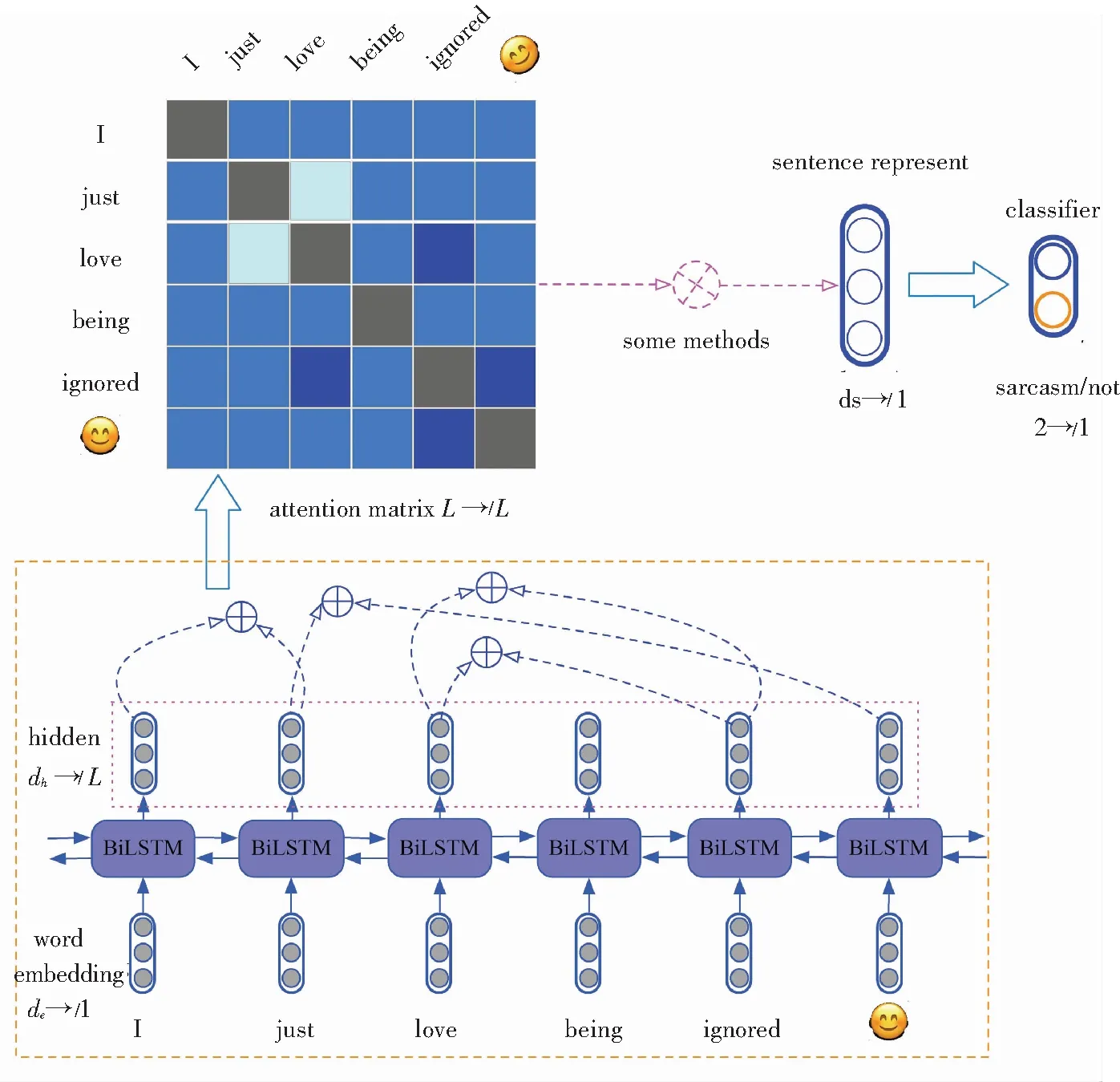
一般来说,已有的反讽识别算法往往依靠较深的序列上下文神经网络模型来对要检测的反讽句子进行表述,较常用的序列模型有GRU[11]门控循环单元、LSTM[12]长短时间记忆网络等模型提取上下文信息特征。这类网络模型共同的不足是使用中常常难以准确地捕捉目标反讽句子的“词对不一致(word pairs clash)”或者称之为“词对矛盾”这一鲜明特征,因为直接使用GRU、LSTM表征句子意味着忽略了目标反讽句中的明显特征,该特征的缺失可能会影响模型的效果。针对反讽识别的模型应该能够关注到前后不一致(矛盾)的词对,而且模型的准确性也会得到提高,更重要的是通过这种思路模型还会具有一定的可解释性。本文提出的模型使用了注意力机制来实现上述目标。该模型的整体框架如图1所示。
由图1可知,为了捕捉两词之间的“矛盾性”,研究构造了一种word pairs attention模型(WPA),即再将句子经过BiLSTM层表示后,任意两词的隐层向量做attention,这样对于一个长度为L的句子可得到L×L的注意力分数矩阵,然后使用某种方案利用该注意力分数矩阵得到句子的向量表示 ,最后使用softmax概率归一化函数对句子表示向量进行二元分类可得相应的类别。其中,de为word embedding的维度,L为句子长度,dh为隐层向量维度,ds为句子表示向量的维度。为此,研究还提出了2种利用注意力分数矩阵的方案,一种是使用max pooling[13],对应的模型称为WPA-P;另一种是二次attention[14],对应的模型称为WPA-A。前者是对矩阵的每一行进行max pooling操作得到L×1向量,在此基础上进一步得到句子向量;后者是将L×L的注意力分数矩阵看作L个L×1向量,进一步得到L个以词为基准的句子表示,再对其做self-attention得到句子向量。
2.1.1 word pairs attention计算
简单来讲,word pairs attention模型(WPA)是一种基于词对(word pairs)关系的模型,可以引导模型训练中刻意关注{love,ignored}这种不一致的词对关系,WPA模型框架如图2所示。
想要计算任意词对的注意力分数,研究使用的是线性感知机来计算注意力分数,具体的计算公式为:
sij=Wa([wi;wj])+ba.
(1)
其中,wi,wj∈Rdh为句子中的任意两个词的BiLSTM隐层表示;符号“;”代表两向量拼接;Wa∈R1×2dh为感知机的系数矩阵;标量ba为感知机的偏置;标量sij即为这两个词的注意力分数。
word pairs attention
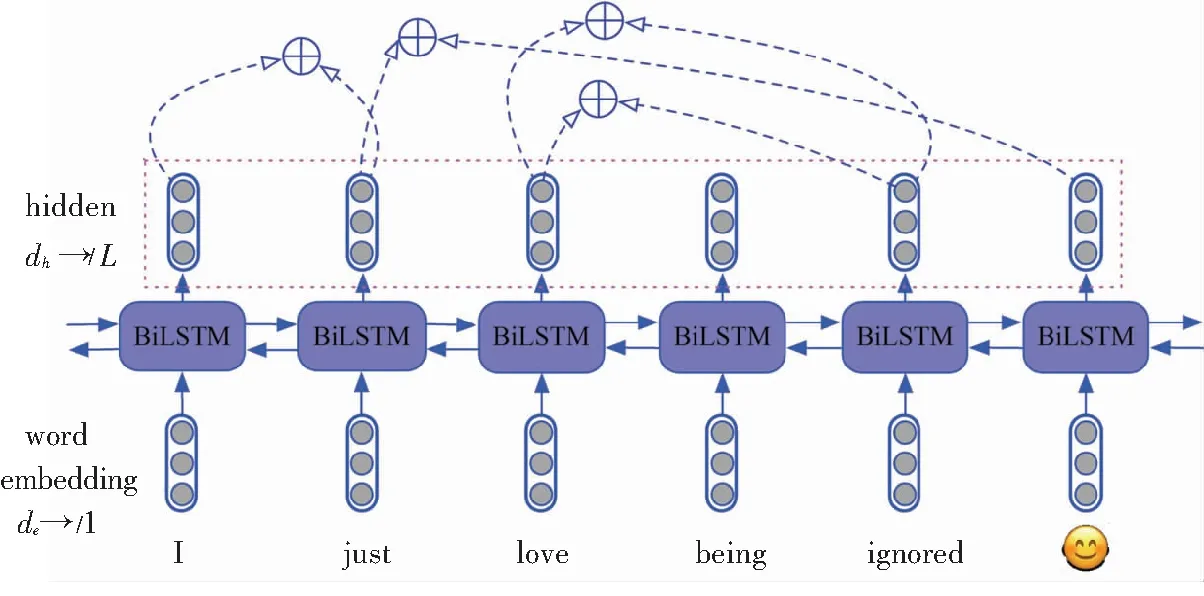
图2 Word pairs attention计算
显然,一句话中任意两个词做attention操作可得到L×L个注意力分数,这里需要注意的是,其中一词与该词本身的注意力分数手动设置为0,考虑到词与自身不可能存在词对矛盾关系,因此无需计算注意力分数。
2.1.2 注意力分数矩阵的池化处理
由2.1.1节研究得到了一个L×L的注意力分数矩阵,接下来考虑如何利用该矩阵。一种最简单的思路是借鉴计算机视觉中的卷积神经网络(CNN or ConvNet)的池化(Pooling)技术。Pooling操作常用于CNN网络中,是对卷积操作后产生的特征图(feature map)的一种降维操作,常用的有最大化池化(max pooling)、平均化池化(average pooling)等。Pooling操作可以极大地减少参数数量和计算量,减小内存消耗,保持平移不变性,增大感受视野。对于二维L×L注意力分数矩阵,可以使用Pooling技术将其降为L×1的一维向量。这里研究采用的是max pooling技术,因为相对于average pooling而言,max pooling更适合捕捉矛盾词对,比如对于“I justlovebeingignored▯”来说,“I”与某个词的注意力分数越大,可以认为“I”与该词相对于其他词而言更具有矛盾性。max pooling技术,即对于每一行的attention值取其最大作为该行的attention。从直观上来讲,研究只关心与当前词最相关的另一个词,这就是使用max pooling的原因。具体见图3。

图3 按行取max pooling
由图3可知,对任意的两词做注意力操作,从而得到了注意力分数矩阵(attention score matrix)。在该矩阵中,每一行取最大的分数,这样即可得到L×1的一维向量,接下去还要使用softmax函数做归一化处理,如此一来就可以得到注意力分数的概率形式,具体公式如下:
a=softmax(maxrows),
(2)
其中,s为注意力分数矩阵,a∈RL。
由此,研究得到了注意力分数向量a∈RL,与原始的BiLSTM隐层向量相乘即可得到本句的向量表示,即:
(3)
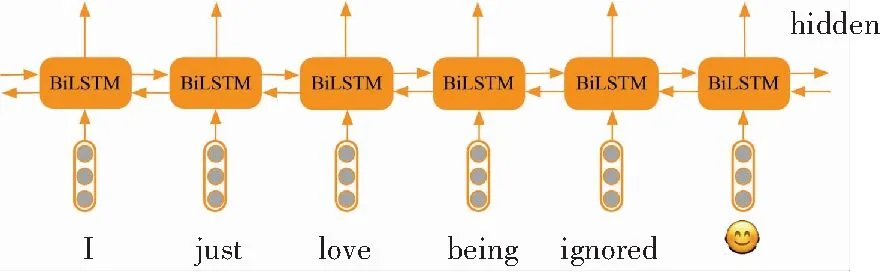
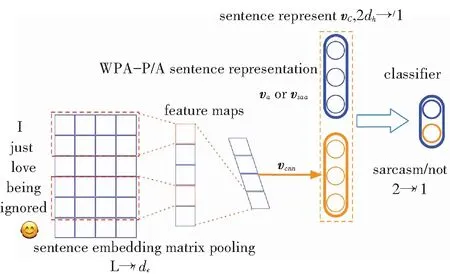
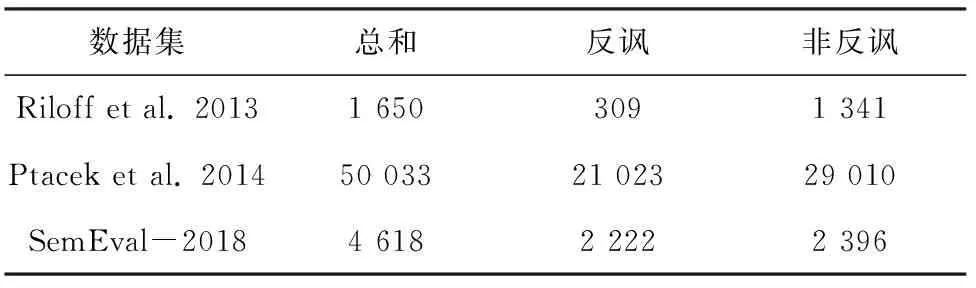
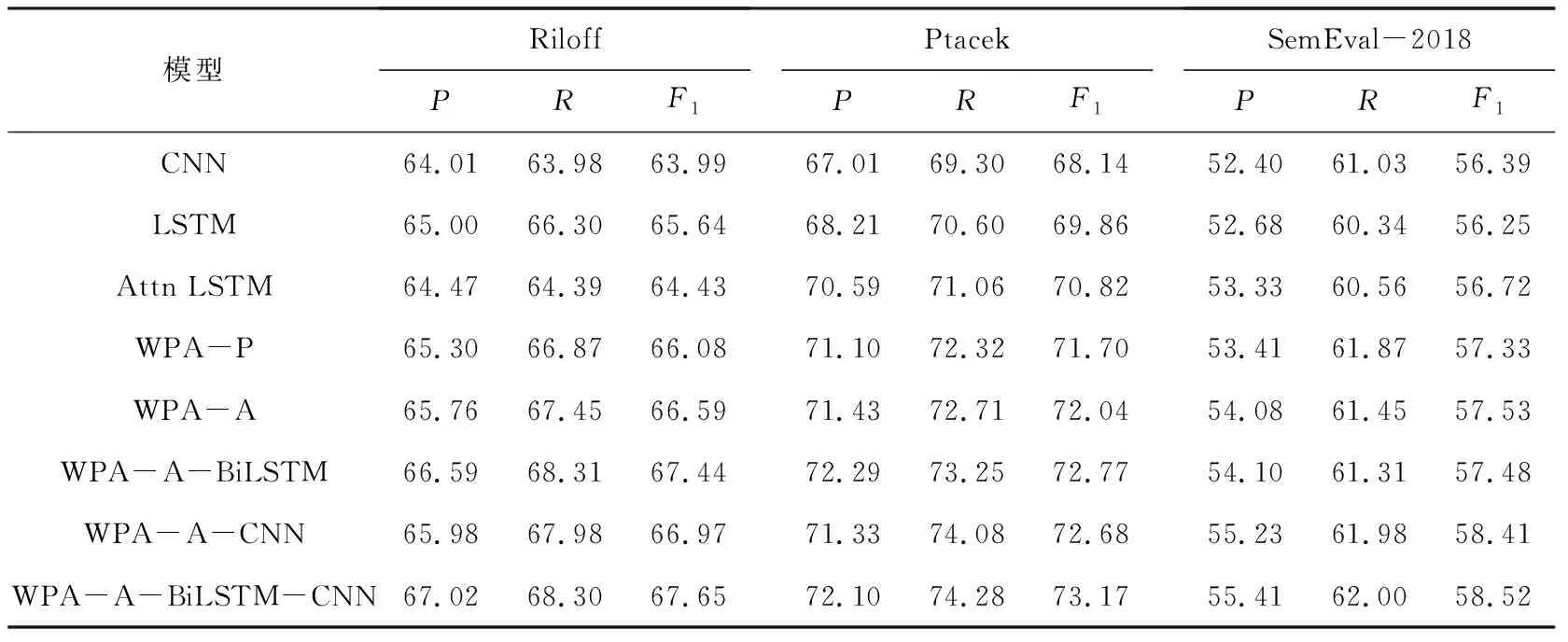
其中,L为句子总长度,标量ai表示输入句中第i(0≤i 图4 句子表示 2.1.3 注意力分数矩阵的二次attention处理 在2.1.2节中使用了max pooling技术将L×L注意力分数矩阵降为L×1的一维向量,在本节将使用另一种方式来处理注意力分数矩阵,如图5所示。 由图5可知,L×L注意力分数矩阵s中的第i行(0i vTsa=vhssoftmax(s), (4) 其中,s∈RL×L是二维注意力分数矩阵;vhs∈Rdh×L是BiLSTM的隐层向量组成的矩阵;vsa∈RL×dh是L个句子attenion向量表示。 然后将vTsa使用self attention机制(使用感知机算法加tanh激活函数),计算出二次attention的注意力分数sa,可将其转为dh×1的二次attention向量表示vsaa。至此,可推得vsaa计算公式为: sa=softmax(ωTtanh(WaavTsa)), (5) vsaa=vhssTa. (6) 其中,Waa∈Rdh×dh,ω∈Rdh是权重矩阵;sa∈R1×L是二次attention的注意力分数;vsaa∈Rdh×1就是经过二次attention后的句子向量表示。 图5 注意力分数矩阵的二次attention处理 2.1.4 句子向量的分类 研究使用了2种方式(见2.1.2节,2.1.3节)获得句子表示。前者使用max pooling生成句子表示va,后者使用二次attention生成句子表示vsaa,后续将分别用这两种表示进行分类任务,见图6。 图6 句子表示做分类 通过线性变换将va或vsaa映射为二维向量,而后使用softmax进行概率归一化处理,得到相应标签的置信度。其公式为: 或者 (7) 因为该模型是端到端(End-to-End)训练的,就使得交叉熵(Cross Entropy)损失函数或者对数似然(log-likelihood)损失函数可以用作训练时的优化目标(两个函数在二分类情况下具有一致性),即: (8) 2.1节中基于词对注意力得到了句子表示,该句子表示含有矛盾词对信息,这些信息则是判断反讽的重要特征。此外,还应利用原始的序列信息,在这里使用了BiLSTM做句子的序列表示,并将该表示与2.1节中的句子表示组合作为新的句子表示。因此用作句子分类的句子向量由WPA-P / WPA-A和BiLSTM的句子表示组成。这样前者可以发现句子内的矛盾词,比如例句中的love与ignored;后者可以表征句子的序列信息,如原始的上下文信息等。 BiLSTM的句子表示可以看作是普通句子序列化的一种建模表示,模型如图7所示。 图7 BiLSTM做句子表示 BiLSTM句子表示用最后一个隐层输出表示该句的语义信息。该部分的输入为word embedding,输出为各个词的隐层向量,这里取隐层中最后一个词的隐层作为BiLSTM句子表示。 将BiLSTM 句子表示vhlast和WPA-P/WPA-A句子表示拼接得到最终的句子向量表示vc∈R2d×1,以此可以做分类预测,这里是二分类任务,正例是反讽,负例是非反讽。研究得到的WPA-BiLSTM模型如图8所示。 图8 WPA-BiLSTM模型 在2.1节中使用了BiLSTM作为原始句子的序列信息,本节将使用卷积神经网络(CNN)捕获句子的N-gram信息,并与2.1节中的WPA-P/A句子向量拼接作为分类器输入。与BiLSTM的序列建模不同,CNN在NLP任务中常被认为会捕获句子的N-gram[15]特征,而N-gram特征是自然语言处理中的一项极其重要的特征,广泛应用于各项文本的分类任务中。CNN与WPA-P/A结合的示意图如图9所示。 图9 WPA-CNN模型 研究中,采用5个模型(WPA-P, WPA-A,WPA-A-BiLSTM,WPA-A-CNN,WPA-A-BiLSTM-CNN)在3个数据集上做了对比实验,分别是Rilff、Ptacek、SemEval-2018,数据集规模见表1。 表1 数据集规模 研究中又采用了3个基线模型做对比,分别是CNN、LSTM、Attention based LSTM,实验结果见表2。 由表2可知,无论是WPA-P模型、还是WPA-A模型都要好于3个基线模型,WPA-A效果要略好于WPA-P。再加入额外信息(BiLSTM,CNN)后,效果均有提高,尤其是同时加入BiLSTM和CNN后,P,R,F1提升明显。最终,研究得到的WPA-A-BiLSTM-CNN 模型的word pairs注意力分数如图10所示。 由图10可以看到,WPA-A-BiLSTM-CNN中的WPA部分确实捕获到了“矛盾词对”,比如{love, ignored},{sore, fun}等。 表2 实验结果 图10 WPA-A-BiLSTM-CNN 模型的word pairs注意力分数 Fig. 10 word pairs attention score of WPA-A-BiLSTM-CNN model 反讽修辞方法在社交媒体中应用广泛,这同时给情感分析和观点挖掘等带来了挑战。针对前后矛盾形式的反讽修辞,本文提出了一种word pairs attention模型(WPA),其主要思想为计算句中任意两词的注意力分数,这样可以助推模型在训练中着重关注某重点词对,因此该模型可以捕捉文本中的前后矛盾词对,也正是该词对是导致反讽的重要原因。除此之外,还使用了BiLSTM来做句子的序列表示,使用CNN提取句子N-gram特征,实验证明,WPA与BiLSTM或CNN结合可以提升模型的整体性能。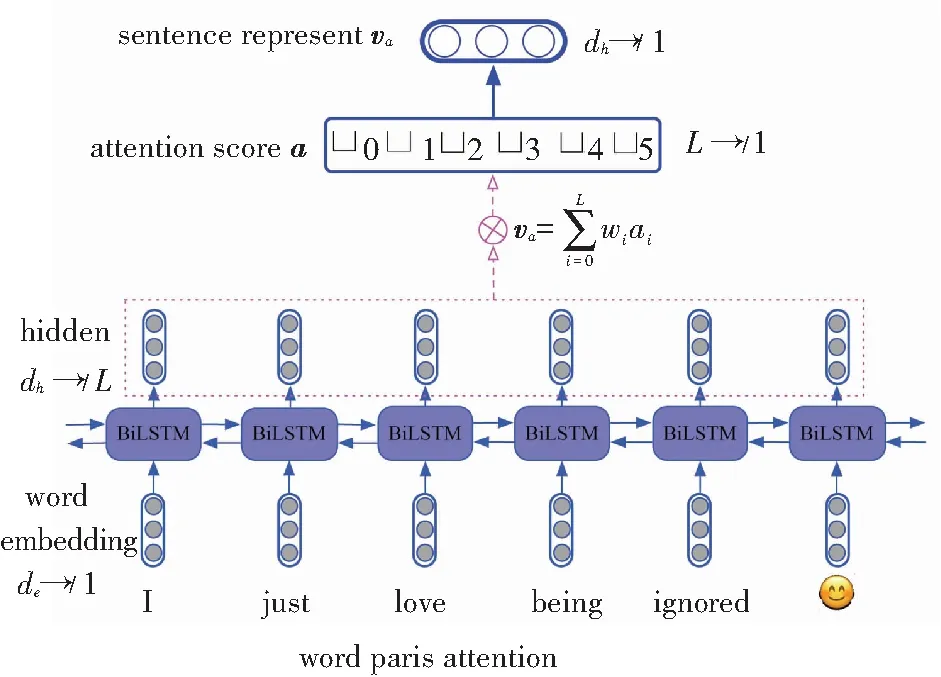


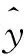

2.2 结合LSTM的词对矛盾模型

2.3 结合CNN 的词对矛盾模型
3 实验

4 结束语
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28中学生数理化(高中版.高考数学)(2021年1期)2021-03-19小溪流(故事作文)(2018年7期)2018-09-27读与写·教育教学版(2017年10期)2017-11-10高中生学习·高三版(2016年9期)2016-05-14新高考·高二数学(2015年11期)2015-12-23南都周刊(2015年4期)2015-09-10南都周刊(2015年3期)2015-09-10南都周刊(2015年1期)2015-09-10名作欣赏(2012年24期)2012-08-15
