
一种基于树搜索的层次多标签乳腺疾病分类诊断方法
2020-04-29 10:55金程笑张敬谊俞春儒
智能计算机与应用 2020年2期
金程笑, 潘 乔, 张敬谊, 俞春儒
(1 东华大学 计算机科学与技术学院, 上海 201620; 2 万达信息股份有限公司, 上海 201112)
0 引 言
近年来,乳腺疾病的发病率正在逐渐上升,严重影响了妇女和少数男性的生命安全和生活质量,据统计,全球每年查出患乳腺癌的人数约有120万,其中50万人死于乳腺癌[1-2]。所以,积极寻找有效的乳腺疾病诊断方法,尽早对诊断结果作出预防,提高乳腺病患的治愈率在目前的研究中尤为重要。随着现代化临床医疗信息系统的快速发展,电子病历系统中积累了越来越多的医疗数据,其中乳腺疾病数据占据了一定的比例,对乳腺疾病的诊断、预测和治疗等有着重要的研究价值[3]。
人工智能中常用的预测方法一般都归结为二分类或多分类问题,对于疾病的预测方法有例如甲状腺良恶性的预测方法,阿尔兹海默症的多分类诊断方法等[4]。但是在实际的临床上,患者的患病情况较为复杂,同一名患者可能会有3~4种疾病,例如患有乳腺肿瘤疾病的患者,可能还伴随转移、高血压以及骨质疏松等疾病,各个大类疾病分类下会存在很多的小类疾病分类,小类疾病分类下可能还会有更细粒度的疾病类别标签存在,例如,乳腺良性肿瘤这一大类会分类为纤维瘤、脂肪瘤、乳头状瘤这三个小类。但是,传统的分类问题往往会忽略各标签之间存在的依赖关系,并且分类算法输出数目呈指数级,占用空间过大,造成预测性能不佳,因此,多标签分类成为解决该类问题的主要方法[5-6]。
多标签分类指的是一个样本可能同时属于多个类别(即有多个标签),并且这些类别之间可能存在一定的相关性[7]。针对同一个样本进行多标签分类相较于单标签分类要复杂得多,而在实际生活中存在较多的多标签分类的问题[8],例如电影分类、图书分类和疾病分类等。
多标签分类算法通常分为2个类别。一类是通过数据集分解,将多标签分类问题分解为多个单标签分类问题处理。给定n个元素的标签集合L=(L1,L2,…,Ln),将L中的任意2个标签Ln,Lm组合病构建一个分类器,该分类器中只含有对应标签Ln,Lm的类别的数据。如果将L中所有标签进行组合会有n*(n-1)/2个分类器。因此,多标签分类问题可以转化为通过构建n*(n-1)/2个二分类问题进行处理,如Goldstein等人[9]在i2b2 2008数据上实验,使用一对一策略将肥胖症及其他15种并发症进行多标记分类问题转换为多个二元分类问题;另一类是通过基于单个优化的多标签分类算法,如耿丽娟[10]提出基于域数的加权KNN算法,针对9 980篇的医疗相关文本进行多分类,构建内、外层体系结构分别通过KNN算法进行分类,该算法的优点是不需要更改数据集的结构,根据近邻域数进行选择性文本加权,保留了标签之间的依赖,有效地提高了分类精度。
上述两类算法的问题在于基于数据集分解的算法无法保证类别之间存在的依赖性,而基于单个优化的算法虽然保留了标签之间的依赖,但是又因为多标签分类问题的输出空间过大会出现计算效率较低的问题。因此,一些研究者根据多标签问题的2个主要缺点提出了层次多标签分类算法,如Clare等人[11]利用分层多标签分析微生物突变表型生长实验的数据,以预测新的基因功能,使得准确率超过80%。该算法通过将数据集分层可以保证类别间的依赖关系,通过将标签分层在训练时可以将数据集进行分类,减少输出空间,很好地提高计算性能。
本文提出了一种基于树搜索的层次多标签乳腺疾病分类预测方法。按诊断结果之间的层次关系构建了层次多标签树,通过对标签树的路径搜索,最终实现乳腺疾病的多标签分类。该方法的特点是利用树结构可以充分考虑到标签集之间的层次结构的依赖关系,达到规范化诊断结论的目的。
1 具体方法
本文提出的基于树搜索的层次多标签分类诊断方法的总体流程如图1所示。首先,通过对所要预测的诊断疾病进行层次标签树构建。然后,对每个层次标签树的非叶子节点进行基分类器的训练。最后,对层次标签树的路径进行打分,选取高于某设定阈值的路径进行反馈,实现对乳腺电子病历的层次多标签分类诊断。

图1 基于树搜索的层次多标签分类诊断算法的流程图
Fig. 1 Flow chart of hierarchical multi-label classification and diagnosis algorithm based on tree search
1.1 构建层次标签树
1.1.1 获取实体标签集
本文的实验数据均来自上海某三甲医院提供的真实的乳腺电子病历数据,主要采用电子病历中的出院小结和首次病程记录作为研究对象。根据i2b2(2010)电子病历标注规范中5类实体的描述对乳腺电子病历进行标注,实体名称及其标注见表1[12]。采用了乳腺电子病历的实体和关系联合抽取模型,对乳腺电子病历进行建模,同时完成乳腺电子病历实体识别与关系抽取,获得了最终的实体标签集[13-15]。
1.1.2 疾病实体分类
在乳腺电子病历中,患者的患病情况较为复杂,同一名患者可能会有3~4种疾病,例如患有乳腺肿瘤疾病的患者,可能还伴随转移、高血压以及骨质疏松等疾病,各个大类疾病分类下会存在很多的小类疾病分类,小类疾病分类下可能还会有更细粒度的疾病类别标签存在,例如,乳腺良性肿瘤这一大类会分类为纤维瘤、脂肪瘤、乳头状瘤这三个小类。疾病的划分见表2。

表2 疾病类别
1.1.3 构建层次标签树
通过表2可以发现这些标签(疾病)之间存在树形层次结构关系,将上表划分的疾病构建为层次标签树,疾病关系层次结构映射如图2所示,标签树包括非叶子节点和叶子节点两类。非叶子节点作为疾病大类一般包含多个子类标签,即疾病子类,在标签树上从根节点至叶子节点,也表示了从大的疾病分类逐渐缩小到疾病小类的过程。
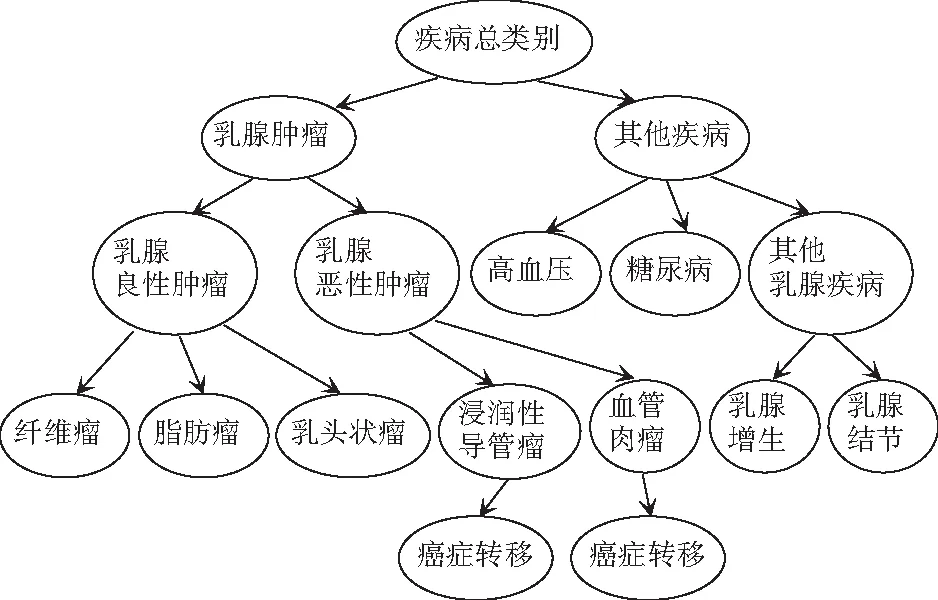
图2 疾病层次多标签树结构体
1.2 基分类器训练
1.2.1 训练集筛选
由于在层次多标签树中,每个非叶子节点对应作为一个分类器对其所对应的孩子节点进行分类。每一个分类器ci的训练集分为2个部分。一部分由对应距离非叶子节点ci最近一层的子节点sub+(ci)组成,记为train+(ci),用于训练属于节点ci的分类器;另一部分由不含有ci子节点的所有标签组成,用于训练完全不属于ci节点的分类结果,记为train-(ci)。若ci没有兄弟节点,则在层次标签树中向上搜索,找到离ci最近的含有兄弟节点的非叶子节点bro(parent(ci)),并且将这个节点不包含ci的样本加入train-(ci)。
例如,当前节点y为乳腺良性肿瘤,则ci这个节点的训练集由正样本训练集ci下所有包含子节点的样本组成,同时,负样本由乳腺恶性肿瘤这个节点的样本组成且负样本中不含有ci的节点和ci的子节点。
1.2.2 基分类器训练
模型的训练算法描述如算法1所示。
算法1 乳腺电子病历层次多标签分类训练算法
输入:乳腺电子病历未标注数据集U,疾病分类标签Y
输出:学习模型L
initialize:U' ∈U
/*训练集初始化,进行标注*/
LabelTree=createTree(UJ')
/*创建层次多标签树*/
ForciinLabelTree:
Ifciis not leafnode
/*判断节点ci是否为叶子节点*/
train+ =train+.add(sub+(ci)) /*把ci最近的子节点加入train+集合中*/
Ifcihas brother node /*如果ci有兄弟节点*/
train- =train-.add(sub-(ci)) /*把ci兄弟节点最近的子节点加入train-集合中*/
Else
train- =train-.add(bro(parent(ci)))
/*找到离ci最近的含有兄弟节点的非叶子节点bro(parent(ci)),并且将这个节点不包含ci的样本加入train-(ci)*/
End If
modelL=train(train+∪train-)
/*训练学习器*/
End If
End For
returnL
算法1是根据乳腺电子病历的特点,先通过表2的分类构建层次多标签分类树,再将训练集按照树中的每一个非叶子节点的标签进行分类,最后形成乳腺电子病历层次多标签分类训练算法框架。该框架也可根据数据的实际需要更换合理的基分类器进行训练、分类。
1.3 多标签分类诊断
层次标签树中一条路径的得分是通过每个非叶子节点上基分类器的预测结果进行加权求和获得的。层次标签树中的权值如式(1)所示:
(1)
式(1)的主要作用是反映路径中层次对于节点的影响,即越靠近根节点的非叶子节点的分类准确性对整个分类起到的影响更大。如果高层的节点出现分类错误,则对整个路径上的分类会出现较大的影响,产生的错误损失也会越大。
非叶子节点标签yi的高度由level(y)表示,层次标签树中树的最大高度通过maxlayer表示。层次标签树中的每条路径的得分通过式(2)来计算:
(2)
路径得分si计算流程是:给定第i条路径,节点个数为m,首先计算每一个基分类器所预测概率p,然后再与每一层的权值w(ci)进行加权,最后通过计算预测概率的加权和。计算路径得分如算法2所示。
算法2 乳腺电子病历层次多标签分类算法
输入:乳腺电子病历测试数据集U,疾病分类标签Y,基分类器Classifier阈值σ
输出:预测标签集Labels
initialize:U'∈U
/*训练集初始化,进行标注*/
LabelTree=createTree(UJ')
/*创建层次多标签树*/
ForciinLabelTree:
Ifciis notleafnode/*判断节点ci是否为叶子节点*/
p(ci) =classifier(ci) /*计算非叶子节点ci的预测概率 */
/*计算ci所在层次节点的权值*/
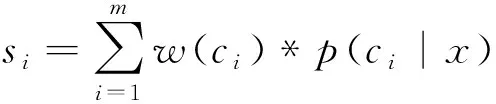
/*计算ci节点的得分*/
End If
End For
Forsinscore:
scoreTree=SumTree(s)
Ifs>=σ:
Labels.add(ci)
End If
End For
returnLabels
算法2首先计算了每一个节点的概率和节点所在层的权重,再通过式(2)计算该路径的得分,比较选取不同的阈值对结果的验证、比较,将得分大于阈值的路径中的节点加入分类结果的集合中,作为最终结果返回,每个返回节点对应的标签则为最终的预测标签集合。
2 实验
2.1 实验数据
为了对本文提出的层次多标签方法进行有效性评估,首先将电子病历原始数据经过上述的实体识别与关系抽取,得到同时含有TeAS(因症状而采取检查)和TeRD(检查发现某种疾病)这两种关系的乳腺电子病历数据作为训练数据集,然后将含有症状的电子病历语句筛选出作为输入数据,将疾病作为对应的结果集。数据集中部分数据见表3。
除了乳腺电子病历入院简要病史数据外,还额外加入体检摘要和生命体征指标共同作为特征,作为基分类器的输入。症状为乳腺电子病历实体识别后提取的结构化数据,体检摘要为患者进行B超、MRI等检查的报告,生命体征为患者检查过程中各项指标的记录,对疾病的诊断同样有重要的参考意义,所以把体检摘要、生命体征和症状集合的数据一并加入作为特征。在此基础上,可得设计研发内容分述如下。
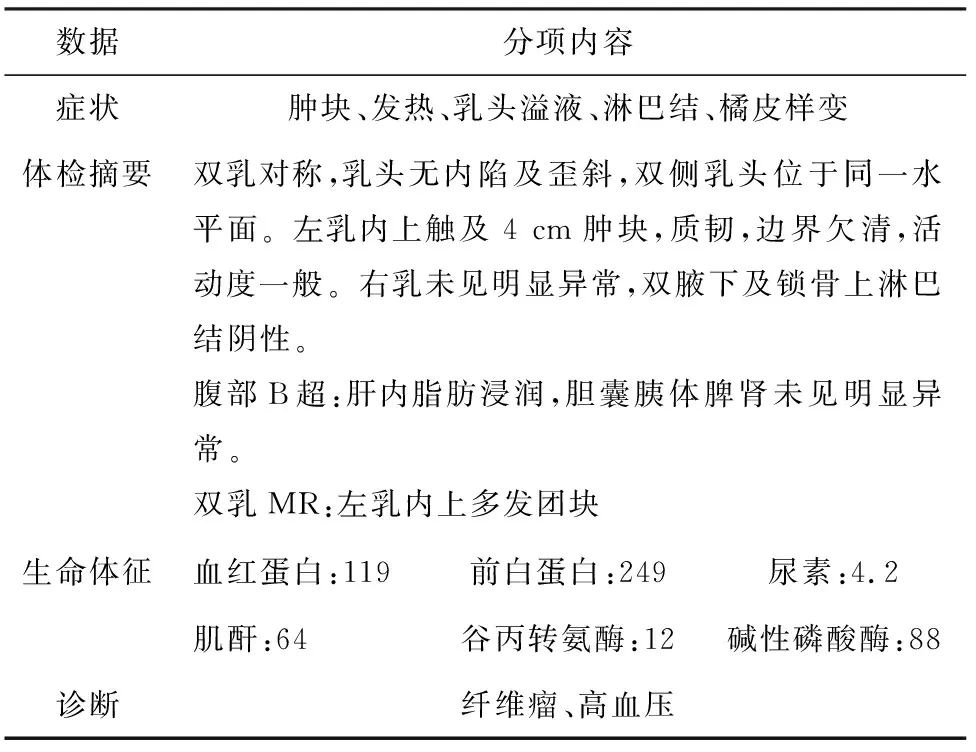
表3 乳腺电子病历数据
(1)词语编码。首先,将症状中的词语映射为一个数字,当输入至基分类器时,这个词语对应的数字和词语所在词向量表lookup table中对应的向量将会共同作为基分类器的输入,词语的编号由词语在句子中的起始位置决定。
(2)标签编码。给定大小为n的疾病的多标签分类集合为L=(L1,L2,...,Ln),当某样本x含有Li时,则Li=1,否则Li=0。在本文中,标签的总数为19,标签集合编码顺序则按从上到下,从左到右进行排列。如果样本x包含乳腺纤维瘤和高血压这两类疾病,则x在L中会对应5个标签,对应的多标签分类的集合对应的诊断属性见表4。
表4 乳腺电子病历结构化数据编码
Tab. 4 Structured data encoding for electronic breast medical records

数据分项对应数据编码症状(12,16,20,29,35,42)生命体征(119,249,4.2,64,12,88)诊断(1,1,1,0,1,0,0,1,0,0,0,0,0,0,0,0,0,0,0)
2.2 实验评价标准
给定大小为n的标签集合Y=(y1,y2,…,yn),集合中yi表示某样本含有第i个标签,分别用1和0表示样本含有标签yi和不含有yi。本文中,yi表示目标集合,yi′表示预测集合。这里,对研究中选用的设计评价指标将做阐释表述如下。
(1)预测标签在子集中的准确率(subsetaccuracy)。表示测试集中预测的标签集合完全正确的样本占全部样本的比例,如式(3)所示:
(3)
(2)准确率(accuracy)。如式(4)所示:
(4)
(3)精度(precision)。如式(5)所示:
(5)
(4)召回率(recall)。如式(6)所示:
(6)
(5)F1值。如式(7)所示:
(7)
2.3 多模型实验对比
子集准确率(subsetaccuracy)判断为真需要满足算法预测的标签集合等于目标集合。由于多标签分类的输出空间较大,完全准确地预测每一个集合中的标签并不容易,所以子集准确率通常提升不明显。首先,通过本文层次标签树多分类方法,这项指标提升至70.3%。同时,由标签树的分层结构,保留标签之间的依赖关系,可以对训练数据集进行有效划分,从而减少计算性能。通过对比逻辑回归模型和KNN模型分别提高了16%和8%,所以使用标签树有效避免了传统多标签分类样本空间过大导致分类效果欠佳的问题。准确率、精度、召回率和F1四类指标同样也作为算法常规的评价标准,层次多标签与其他模型进行比较的结果见表5。
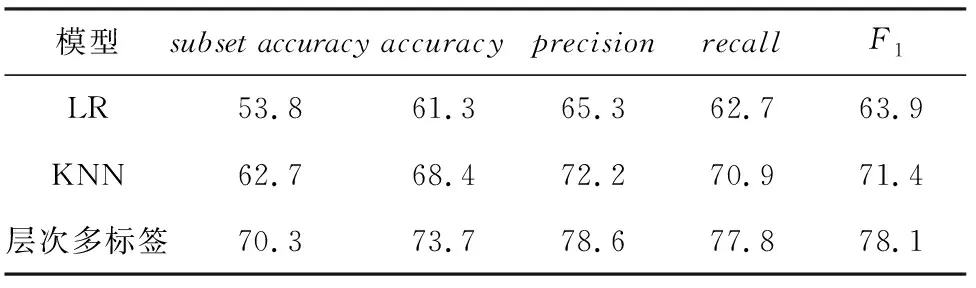
表5 多模型实验对比结果
2.4 多分类器实验对比
本节通过实验来对比多种基分类器对基于层次多标签分类算法的效果,并选择性能最优的基分类器来测试本文的方法。根据4种不同的分类方法来比较不同的分类器对该层次多标签分类算法的性能。使用4种常见的方法作为基分类器。见表6。
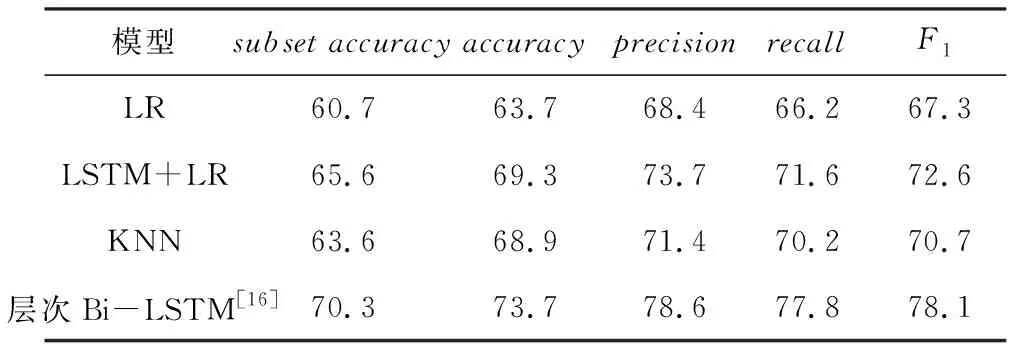
表6 多分类器结果对比
通过实验的对比,将4种基分类器应用于层次多标签分类方法,在训练数据的维度都为300维时,LSTM+LR对比KNN算法在相同输入的情况下,效果略好于KNN,各项指标普遍提升约2%。层次Bi-LSTM模型对比LSTM+LR与KNN模型的精确度提升明显,准确度高出约5%。层次Bi-LSTM算法的分层提取特征的特点,将一个较长维度的输入进行分层特征提取,有效地降维。通过实验对比,本文选择层次Bi-LSTM作为最终的基分类器。
2.5 多阈值σ实验对比
本节中通过模型简化测试方法对多阈值σ条件下模型的训练效果和性能进行定量分析。采用逐步增加阈值的数量检验模型的分类能力通过汉明损失进行对比,如式(8)所示:
(8)
对比各算法输出的汉明损失,汉明损失表示多标签分类模型精度,首先计算每个样本中标签对预测错误的个数,计算yiΔyi′,Δ为异或操作,再与对应预测标签yi′的预测概率相乘,最后计算每个预测标签乘积和的均值。
如图3所示,当选取词向量作为网络输入时,通过逐步增加阈值使得各算法最终输出的路径得分超过所设定的阈值。通过实验对比发现,当阈值设定在0.50~0.70之间汉明损失趋势总体呈现逐步下降,而当阈值大于0.70时,accuracy的趋势稳定或者呈现出略微上升的趋势。接下来,通过十折交叉验证进行试验,经过LSTM进行初步语义特征提取的逻辑回归算法比LR逻辑回归算法的汉明损失降低0.2,而LSTM+LR算法与树层次标签算法普遍相差0.1。
当阈值为0.65时,LSTM+LR算法的汉明损失最小,多标签分类的效果较好。当阈值为0.7时,层次多标签算法的分类效果最为显著,整体汉明损失低于前述2种算法。

图3 不同大小阈值在层次多标签算法的汉明损失对比
Fig. 3 Comparison of Hamming loss of hierarchical multi-label algorithm with different thresholds
3 结束语
本文提出了一种基于树搜索的层次多标签乳腺疾病分类诊断方法,实验数据是来自上海某三甲医院提供的真实的乳腺电子病历数据,通过引用实体和关系联合抽取方法提取出的疾病实体作为实体标签集。首先介绍了层次多标签分类总体流程,然后对疾病的类别进行详尽分类,并阐述了根据分类结果构建层次标签树的过程,提出了基于树搜索的多标签分类诊断的计算方法,最后进行实验对比。
通过在真实数据集上进行对比实验,使用准确率、召回率等多组评价指标对模型结果进行评估,证明了对已有模型的改进并且有效地提高了电子病历实体识别以及关系抽取的准确性。通过多模型和多个基分类器进行对比,证明了基于树搜索的层次多标签乳腺疾病分类诊断方法的有效性。
接下来的研究工作可以从这2个方面展开。首先,使用网络上的公开训练集作为实验数据,为后续多标签预测提供更准确的训练集做模型训练。其次,将电子病历中的其他因素作为特征进行多标签分类,从而提高辅助诊断的真实性与全面性。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
科学家(2022年3期)2022-04-11
重庆大学学报(2022年2期)2022-02-28
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
计算机系统应用(2021年2期)2021-02-23
智能计算机与应用(2020年4期)2020-08-31
作文评点报·低幼版(2020年25期)2020-07-23
软件导刊(2017年4期)2017-06-20
