
基于改进BRISK算法的图像特征提取方法研究
2020-04-29 10:55朱鸣镝
智能计算机与应用 2020年2期
陈 婵, 管 启, 朱鸣镝
(上海理工大学 光电信息与计算机工程学院, 上海 200093)
0 引 言
视觉SLAM(Visual Simultaneous Localization and Mapping)[1-2]是基于视觉的同时定位和建图系统,该系统分为前端和后端,前端也称为视觉里程计(VO)。研究时是根据相邻帧图像的信息,估计出粗略的相机运动,给后端提供较好的初始值。基于特征点法的前端,长久以来被认为是视觉里程计的主流方法。而且运行稳定,对光照、动态物体不敏感,是目前比较成熟的解决方案。
获取场景图像中的特征点信息通常包括特征点检测与特征点描述两个步骤。首先特征点检测算子检测出场景图像中的那些包含丰富结构信息的特征点。然后使用描述子对检测到的特征点进行描述。对特征点的描述主要是对特征点周围像素信息的描述,最终将产生一个和特征点一一对应的描述符。
视觉SLAM中常用的特征点提取算法有SIFT[3]、SURF[4]、ORB[5]等,由于SIFT、SURF算法的复杂度,无法满足视觉SLAM系统对实时性的要求。实时特征提取算法ORB算法在SLAM中被广泛使用。由文献[6-8]得知,ORB特有的二值描述符大大加速了特征提取与匹配算法的运行效率。类似的二值描述子特征提取算法还有BRISK[9],FREAK[10]等。
根据文献[8,11-12]了解到,BRISK算法在尺度不变性上表现较差,如果使用BRISK算法作为视觉里程计中的特征点检测算法,在尺度变化较大的情况下,常常不能为后端提供准确的位置信息。本文提出的BRISK算法通过细化尺度空间的尺度间隔为BRISK建立新的尺度空间,使得尺度尽可能接近理想的连续尺度,并使用灰度质心法来代替原来使用长距离匹配点对为关键点分配主方向,经过多次实验后发现改进的BRISK在匹配准确率上有很大提高,在尺度不变性上表现优异,同时具有很好的抗噪声干扰性能。
1 BRISK检测与描述
1.1 尺度空间的构建
BRISK算法中,尺度空间金字塔由n个普通层图像octaves(用ci表示)和n个内层图像inttra-octaves(用di表示)组成,通常n=4,i={1,2,......,n-1}。其中,原始图像ci-1和di-1作为基准层图像,普通层图像ci(i≠0)均由ci-1层不断2倍降采样生成,内层图像di(i≠0)均由di-1层不断降采样生成,每个内层图像di都位于ci和ci+1之间,可以构建一个2n层金字塔,如图1所示。其中内层图像d0是由原图c0的1.5倍降采样得到。如果使用t来代表尺度,则有:t(ci)=2i,t(di)=2i·1.5。

图1 尺度空间特征点检测
1.2 特征点检测与定位
(1)BRISK算法在尺度空间中每个octaves和intra-octaves上使用AGAST9-16[13]算子进行关键点检测(额外增加的d-1层使用的是FAST5-8[14]算子),在此基础上对每个关键点计算AGAST得分。对检测出来的角点在上下两层使用非极大值抑制来筛选响应较强的点,这里使用AGAST得分作为每个角点的响应值。
(2)对已经粗筛选出的特征点进行插值,这种插值是利用最小二乘法对x、y方向的二维二次插值,以得到准确的特征点坐标位置,并在尺度方向上进行抛物线插值,以得到极值点所在尺度,用这个尺度根据上下层极值点与关键点位置的偏移量再次对特征点位置进行二次修正,把这个位置作为特征点的位置。
1.3 构建描述子
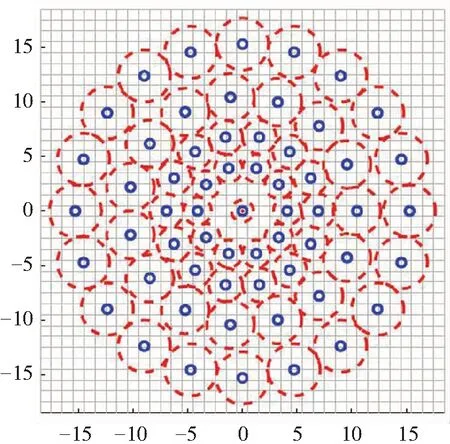
BRISK描述符由简单亮度比较测试构成的二进制字符串组成。这种方法在文献[15]中证明是非常高效的,BRISK描述符的关键概念是对关键点的邻域进行采样的思想,如图2所示。在图2中,小蓝色圆圈表示采样位置;红色虚线圆圈则以半径σ绘制,该半径σ正比于平滑采样点的高斯核的标准偏差。图案定义了在与关键点同心圆上等距间隔的N个位置。把N个采样点两两组合成一对,将所有组合方式的集合称作采样点对集,用A表示,则有:
A={(Pi,Pj)∈R2×R2|i≤N,j (1) 其中,(Pi,Pj)表示采样点对,将经过高斯滤波后的采样点Pi、Pj分别标记为I(Pi,σi)与I(Pj,σj),用g(Pi,Pj)表示采样点对的局部梯度集合,则有: (2) 根据采样点对间的距离,定义短距离点对子集S、长距离点对子集L,即: S={(Pi,Pj)∈A|‖Pj-Pi‖<δL}⊆A, (3) L={(Pi,Pj)∈A|‖Pj-Pi‖>δS}⊆A, (4) 其中,δS为短距离阈值,通常取9.75t;δL为长距离阈值,通常取13.67t;t是特征点所在的尺度。 根据长距离子集计算特征点的方向,这里将用到如下数学公式: (5) 其中,g为特征点主方向;l是长距离点对子集L中所有采集点对间距之和;g(Pi,Pj)为(Pi,Pj)的梯度;gx与gy分别为L中各采集点对在x方向和y方向梯度。在生成描述子之前,需要将模板沿中心顺时针旋转θ度,即: θ=tan-1(gy,gx), (6) 按照公式(6)在短距离点对子集S中对比采样点对灰度值,最终生成二进制描述子。其对应公式可写为如下形式: (7) 细化尺度空间金字塔由n个普通层图像octaves(用ci表示)、n个内层图像intra-octaves(用di表示)和n个上层图片up-octaves(用ui表示)组成,通常n=4,i={1,2,……,n-1}。其中,原始图像c0,d0和u0作为基准层图像,普通层图像ci(i≠0)均由ci-1层不断2倍降采样生成,内层图像di(i≠0)均由di-1层不断降采样生成,上层图像ui(i≠0)均由ui-1层不断降采样生成,因此构建一个3n层金字塔。其中,内层图像d0是由原图c01.25倍降采样得到,上层图像u0是由原图c01.5倍降采样得到。如果使用t来代表尺度,则有:t(ci)=2i,t(di)=2i·1.25,t(ui)=2i·1.5。 图2 采样点N=60的BRISK采样模式 本文引入细化的尺度空间,一方面原因是,在视觉信息处理模型中通常引入一个尺度的参数,就是要通过连续变化尺度参数获取不同尺度下的视觉信息,然后综合这些信息才能够深入挖掘图像的本质特征。在图像的特征匹配中,研究中同样也希望通过连续变化尺度参数获取不同尺度下的图像,获取连续尺度下检测到的特征点,特征匹配才能真正达到尺度不变性,本文对原算法尺度空间的ci和di层之上增加了ui层,更细化了尺度间隔,增加了更多尺度下的视觉信息;另一方面这样的改变会更加细化特征的选择,原因是在特征点粗定位时,会将中间层的特征点与上下两层的特征点使用非极大值抑制,增加了ui层同时也增加了更多的中间层,拓宽了特征搜索范围,增大匹配的概率,有利于粗定位的改善;也有助于通过插值得到特征点精确位置,在精度上也有一定程度上的提升。从2个方面出发提高整个系统鲁棒性,为后续准确的匹配提供了良好基础。 (1)在一个小的图像块中,定义图像块的矩为: (8) (2) 通过矩可以找到图像块的质心,其对应公式可表示为: (9) (10) 这样就为每个关键点确定了主方向,使得AGAST角点具有了旋转不变性。 通过以上步骤,AGAST角点就具有了尺度与旋转不变性,显著提高了其在不同图像中检测性能。 综合前述研究可知,推得2种算法的设计流程如图3所示。 (a) 原算法流程图 (b) 改进算法流程图 本文的硬件环境为Windows10,64位操作系统,工作站型号:intel(R) Xeon(R) Silver4116,实验平台为VS2015+OpenCV3.4。本文采用牛津大学网站(http://www.roborts.ox.ac.uk/~vgg/affine)的标准Oxford数据集作为测试图像[16]。研究中使用不同的几何和光度变换以及不同的场景类型来评估真实图像上的描述符。本文拟将评估4种图像变换:旋转+尺度变换(boat/bark数据集);视点变换(graff/wall数据集);图像模糊(bikes/tree数集);光照变换(leuven数据集)。 为了验证本文算法在提高匹配质量和匹配效果上的有效性,从数据集中随机选取一组旋转+尺度图片(boat数据集),和使用手机拍摄实验室杂乱场景下的图片进行试验,将本文算法与SURF、ORB、BRISK进行比较。实验效果如图4所示,在实验室拍摄的图片中,对比图4(a)和图4(c)可以发现SURF与ORB算法几乎没有正确匹配,相比之下本文算法匹配效果最好。对比boat数据集,本文算法在成功匹配点个数与BRISK算法相差不大,实验验证了使用灰度质心法为关键点确定主方向的有效性。进而,研究求得算法运行时间的结果比较见表1。 图4 2组图片在4种不同算法下的匹配效果 Fig. 4 Matching effect of two groups of pictures under four different algorithms 表1 算法运行时间比较 3.2.1 评估标准 本文使用类似于文献[17]中提出的标准。该标准提出了3种不同的指标:假定匹配率(PutativeMatchRatio),精确度(Precision)和匹配得分(MatchScore)。对此研究内容可详述如下。 (1)假定匹配率。能够体现描述符的独特性,并描述检测到的特征的哪一部分最初将被识别为匹配(尽管可能不正确)。具体数学公式如下: (11) 其中,PutativeMatch表示在所有的匹配对中,最近邻与次近邻比值小于0.7的匹配对数,且保证匹配是一对一的匹配;Features的大小为2幅待匹配的图像中检测到关键点个数较少的那个。 (2)精度。定义了一组假定匹配中的正确匹配数(inlierratio)。具体数学公式如下: (12) 在该等式中,正确匹配的数量是基于已知相机位置几何验证的假定匹配。文中使用牛津数据集中提供的GroundTruth数据。通过2幅图像间的单应性矩阵,将配对的关键点映射到一幅图像中,如果彼此的距离在2.5像素内,则该匹配对是正确的。 (3)匹配得分。是假定的匹配率和精度的乘积。具体数学公式如下: (13) 该指标描述了正确匹配的初始特征的数量,并且与前两个度量一样,匹配分数可能受到描述符独特性和匹配标准的影响。 3.2.2 实验结果分析 图5展示了本次研究对4种算法的描述子性能评估的结果。 在图5中,横坐标为以每个场景数据集中的第一张图像与其余的5幅图像组成的匹配对,节点形状含义: ‘-*-’代表PutativeMatchRatio标注中简写为PMR;‘…Δ…’Precision标注中简写为PRE;‘--—’代表MatchScore标注中简写MS。经过观察图5(a),研究发现在图像发生较大程度的模糊变化时,本文算法综合表现最好,说明构建细化的尺度空间可以使算法在尺度上具有更强的鲁棒性。经过观察图5(b),分析发现在旋转和尺度变化的数据集中,4种算法的假定匹配率和匹配得分普遍偏低。其中,SURF算法综合表现最好,BRISK算法与本文算法效果相当,说明SURF算法、BRISK算法和本文算法的描述子具有较好的独特性。经过观察图5(c),分析发现4种算法描述子对光照的鲁棒性相差不大,对图像光照变化均有较强的鲁棒性。经过观察图5(d),进一步发现在较大的视角变化时,ORB和SURF算法在img1/3到img1/5之间精度出现急剧下降,说明这两种算法对较大视角变化没有较好的鲁棒性,综合来看,BRISK算法表现最优,本文算法与BRISK算法表现相差不大,能够达到一定程度的有效匹配。 (a) 模糊变换数据集上不同匹配指标的结果测试 (a) The test results of different matching indices on ambiguity change datasets (b) 旋转+尺度数据集上不同匹配指标的结果测试 (b) The test results of different matching indices on rotation+scale change datasets (c) 视点变换数据集上不同匹配指标的结果测试 (c) The test results of different matching indices on viewpoint transformation datasets (d) 光照变换数据集上不同匹配指标的结果测试 (d) The test results of different matching indices on illumination transformation datasets 图5 仿真测试结果 Fig. 5 Simulation test results 算法匹配速度比较:在相同的匹配环境下,使用同样配置的计算机,对相同的一对图像进行比较,测试算法的执行时间。研究得到的同一对图像匹配100次的执行时间统计结果见表2。结果显示本文算法执行时间略大于原算法执行时间。 表2 算法运行时间比较 本文提出了一种改进的BRISK算法,有效地解决了BRISK对尺度不变性表现欠佳的缺点,同时继承了BRISK的快速检测的特性。此外,使用灰度质心法为关键点分配主方向,有效地减少了描述子构建过程中的计算时间。实验结果表明,本文提出的方法大大提高了BRISK的特征点匹配性能。与使用BRISK方法的视觉里程计相比,使用本文方法能有效改善视觉里程计的位置估计和方向估计。此外,本文所提算法在特征点匹配精度和计算时间方面表现良好,可以实际应用于实时单目视觉里程计。2 改进的BRISK算法
2.1 细化尺度空间金字塔的构建
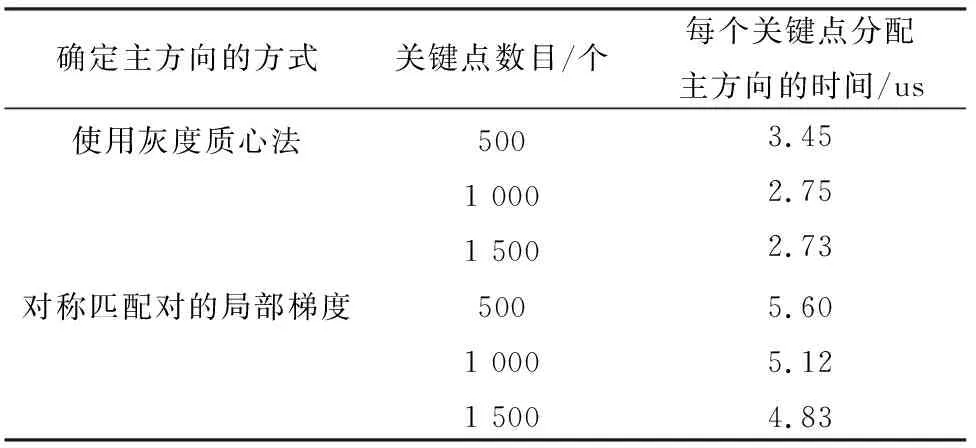
2.2 灰度质心法确定关键点主方向


2.3 2种算法的流程图

3 实验
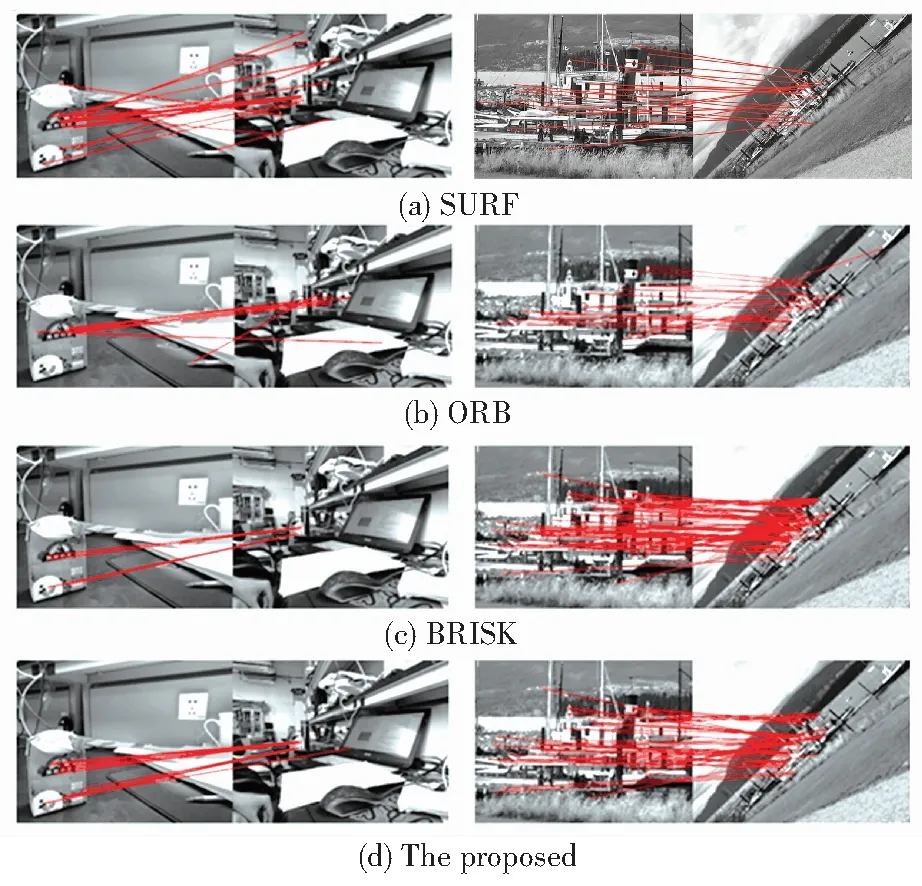
3.1 实验效果
3.2 鲁棒性测试




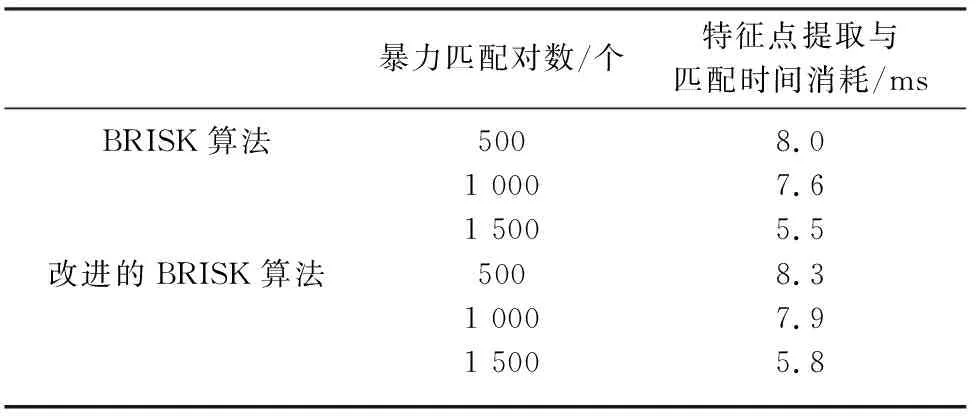
3.3 时间评估
4 结束语
猜你喜欢
社会科学战线(2022年7期)2022-08-26
建材发展导向(2022年3期)2022-04-19
建材发展导向(2022年2期)2022-03-08
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
广东教育·高中(2017年10期)2017-11-07
新高考·高一物理(2015年5期)2015-08-18
读者(2015年9期)2015-05-04
中国信息化周报(2015年1期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
