
基于深度学习算法的人脸活体识别门禁系统设计
2020-04-28 08:00王学花刘兆春
贵阳学院学报(自然科学版) 2020年1期
王学花,刘兆春
(安徽大学 江淮学院理工部,安徽 合肥 230001)
由于具有非接触性、简易性、非强制性、易检查性等优点,人脸识别已经成为应用最为广泛的生物特征识别技术。而由于人脸自身和环境等很多复杂的因素,人脸识别技术仍然面临着巨大的挑战。对于人脸本身,由于在整体结构上,不同个体的人脸轮廓和器官外形区别不大,导致不同人脸的差异性不大。而对于环境和外界因素,由于光照、表情、角度、饰物、遮挡、化妆等很多不确定因素会对图像产生一定的影响,进而加大了人脸识别的难度。为了将人脸识别技术应用到更多更复杂的实际场景,因此对于提高人脸识别技术精准性和稳定性以及增强鲁棒性和使用的便捷性的研究具有十分重要的意义。[1]
本文设计了一种基于多通道特征融合与动态样本权重的卷积神经网络,并将其应用于人脸识别中。该方法使用多个通道同时提取人脸图像抽象性和细节性的特征,解决 CNN 特征提取不充分的问题;另外,在训练过程中使用动态样本权重对损失函数进行改进,进而使得模型更快地朝着减少错误率的方向训练,加快收敛速度。
1 多通道特征融合
CNN 在每次卷积层的结果输入给池化层之后,其特征图的维数就会降低,而一般 CNN 都会有多层卷积层,这也意味着最后全连接层获得的是经过了多次降维和抽象的特征图。[2]本文设计了多通道特征融合的网络结构,多通道表现在使用了两个深度不同的卷积通道进行特征提取。如图 1 所示为多通道特征融合的CNN 框架图。如图所示,该网络同时训练两个相互独立且层数不同的卷积层通道,深浅不同的卷积层同时提取抽象性和细节性的特征,之后两个通道得到的特征全连接融合为固定维数的特征,最后使用 softmax 分类器进行分类。

图1 多通道特征融合的框架图
2 动态样本权重
本文提出的动态样本权重的机制,在训练过程中,常规的损失函数为:
(1)
其中,N为样本个数,loss(•)为对单个样本求损失,xi为第i个样本。
这种损失函数是通过对所有样本损失求均值得到的,而本文设计的动态样本权重的思想是对每个样本损失进行加权求和:
式中,di为第i样本的权重系数。
此时的损失函数就不仅仅是求所有样本损失的均值了,在训练中可以针对某些易分错的样本适当地增加其di值,进而损失函数中这些样本的比重增加,使得损失函数有目的地进行训练,因而可以使网络更快地收敛。
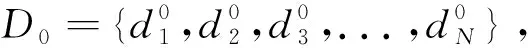

(2)用当前训练的模型计算样本的分类情况,得到错分类的样本集Xerror;
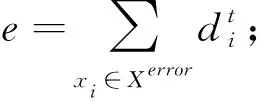
(4)如果求得的加权误差e<0.5,则继续第 5 步对样本权重进行更新,否则退出不进行此次权重更新。
本文使用动态样本权重的损失函数会使模型更快地达到收敛,本小节将用实验在MNIST数据集上证明动态样本权重的有效性。MNIST数据集是Google实验室的Corinna和纽约大学柯朗研究所的YanLeCun所创建的一个手写数字的数据集,其中包含有60000张图像的训练集和有10000张图像的测试集,每一个图像都是分辨率为28X28的灰度图,如图2为MNIST数据集的部分图片展示。由于其具有图像清晰、容易获取、易于训练等优点,MNIST数据集成为机器学习领域的入门数据集,同时也经常被用来验证算法的可行性。[3-5]

图2 MNIST数据集部分图片展示
本文设计了一个全连接的BP神经网络对MNIST数据集进行验证,由于每个图像的分辨率为28X28,即有784个像素点,因此该全连接网络的输入有784个节点。此外网络的输出有10个节点,有2个隐层,第一个隐层有392个节点,第二个隐层有196个节点。网络结构如图3所示。

图3 BP网络结构
分别使用式(3-1)和加入了动态样本权重(DynamicSampleWeight,记为DSW)机制的损失函数对网络进行训练,对于DSW损失函数,每迭代50次就对样本权重进行一次更新。训练期间测试集的识别率曲线如图4所示。
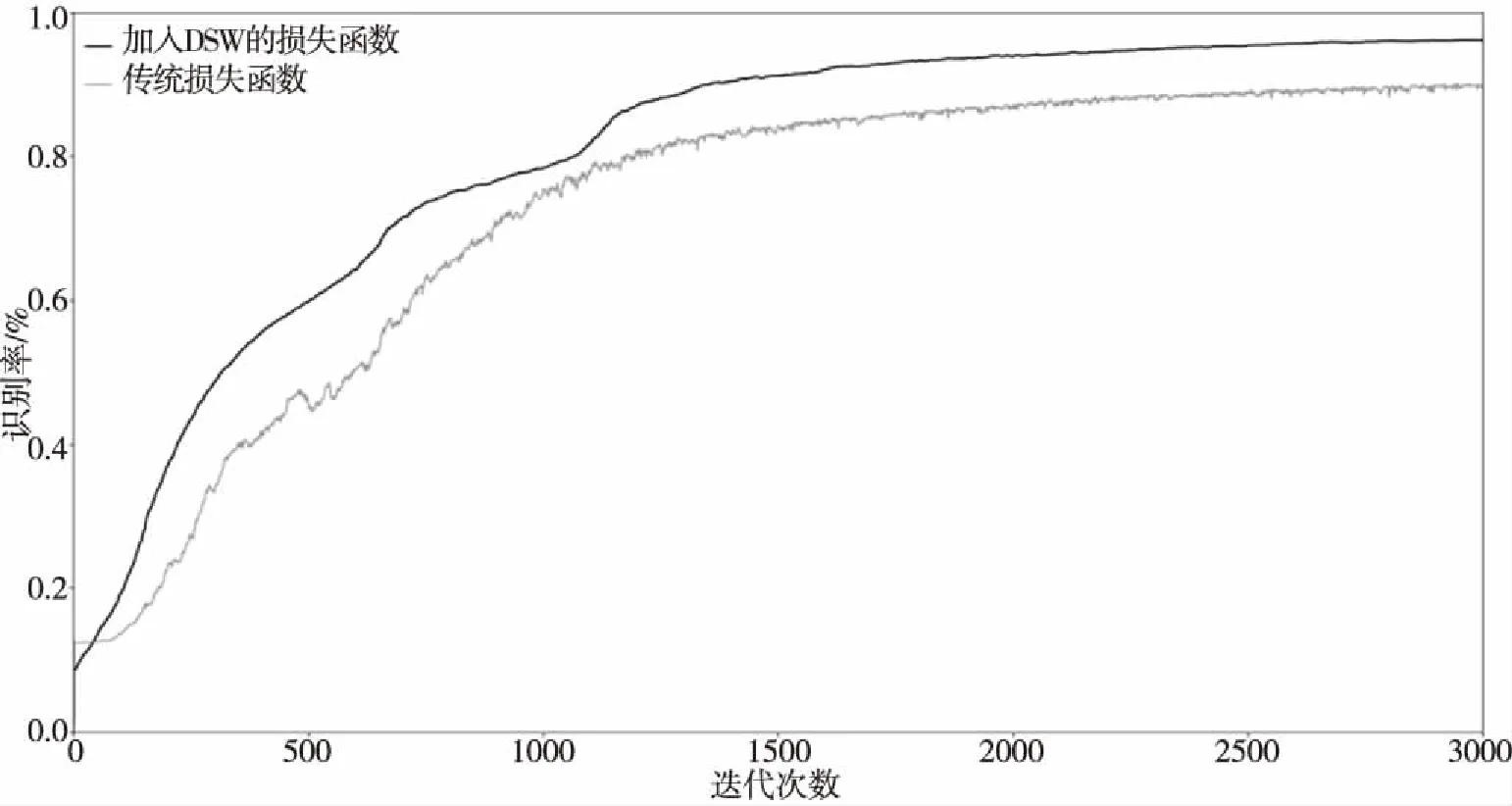
图4 训练期间识别率曲线
从图4的曲线中可以看出,在训练过程中,与传统的损失函数相比,加入了DSW机制的损失函数训练相同次数得到的网络模型,其识别率更高,说明加入了DSW机制的损失函数不仅能够加快收敛速度,还可以增加模型的准确率。从图中还可得到,加入了DSW机制的模型在训练过程中其识别率一直高于传统的方法,且加入了DSW机制的模型其识别率略微呈起伏式增长,即在某一小段训练期间识别率增长较快,而随后就增长变得缓慢一点,依次交替进行,这也可以验证前面对于加入了DSW机制的损失函数有目的进行训练的观点,即在某一段训练中,损失函数着重训练某一种错分类样本,因此该训练过程中识别率增加得较快;而当对该类型错分类训练完毕后,样本权重会随着训练次数进行更新,这一小段训练期间由于在进行样本权重的调整,因此训练过程变得缓慢,当样本权重调整适当后,损失函数开始针对另一类错分类样本进行模型训练,以此步骤循环进行,因此其识别率略微呈起伏式增长。[6-8]
3 实验与结果分析
本文经过具体的实验及分析对本文设计的多通道特征融合的有效性进行验证,同时该多通道的网络结构也在实验中确定。为了验证本文设计的MFF-DSWCNN模型在人脸识别应用上的有效性,使用了多种方法进行对比实验。
CBCL人脸数据库由麻省理工大学媒体实验室创建,包含10位志愿者的3240张不同姿态、光照和大小,分辨率为200X200的面部图像,图像背景为黑色。如图5为数据库的部分人脸图像展示。CBCL是为探究不同姿态、光照下的人脸识别研究而采集的人脸数据库,是人脸识别领域一个比较经典的数据集。

图5 CBCL数据库部分图像
由于该数据库采集的图像都很清晰,背景为纯黑色,且只有人脸面部的数据,并不包含身体、背景等无用的数据,因此不再对原始数据进行人脸检测和预处理,仅需将图像的分辨率由200X200统一调整为128X128即可。[9-10]
为了验证多通道特征融合的有效性,并确定具体的网络结构,在本小节进行了多组实验。实验中的识别率数据均是采用5折交叉验证方法获得。使用5折交叉验证方法得到不同卷积层数的CNN最终的识别率如表1所示,训练阶段在测试样本上的识别率曲线如图6所示。

表1 不同卷积层数的CNN识别率
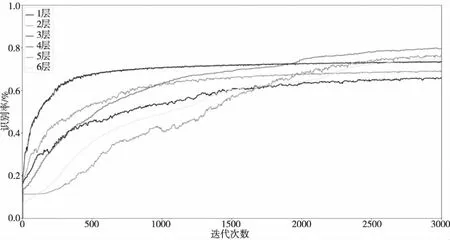
图6 训练期间的识别率曲线
从表1中可以看出,在卷积层数为1层到3层时,随着卷积层数的增加,模型在训练集和测试集上的识别能力在提升;当卷积层数达到4层以后,其识别率提升的幅度很小。图6中也有类似的现象,在层数小于4时,当训练3000次时的测试集识别率会随着层数增加而升高,而当层数为5和6时,训练3000次时的测试集识别率减少了。由于卷积层数为4层时,当前的单通道网络结构对人脸的特征提取已经达到了瓶颈,因而再增加卷积层数,识别率并不会发生明显提升,反而会因为模型参数增多导致其复杂度增大,使得模型过拟合程度越来越明显。
实验中将4层卷积层分别其它浅层卷积网络组合,将不同通道提取到的特征输入到全连接层进行全连接融合,全连接层的节点数统一取2048。在数据集上使用5折交叉验证,得到不同层数卷积层与4层卷积层组合后的识别率见表2,训练阶段在测试样本上的识别率变化过程如图7所示。

表2 不同深度的多通道网络的识别率

图7 训练期间的识别率曲线
为了验证本文设计的MFF-DSWCNN在人脸识别应用上的有效性,将MFF-DSWCNN与经典人脸识别的方法以及其它文献的方法在CBCL人脸数据库上进行训练与测试实验并对比分析了结果。分别使用LBP与栈式自编码器(StackedAuto-Encoder,SAE)结合的方法,多尺度非监督特征学习(Multi-ScaleConvolutionAuto-Encoder,MSCAE)、多尺度Gabor特征融合的方法,Eigenface方法、Fisherface方法,以及MPCNN与MFF-DSWCNN进行对比。表4为不同方法在CBCL人脸数据库上的识别率对比。

表4 不同方法在CBCL数据库上的识别率
为了测试本文MFF-DSWCNN对图像遮挡和旋转的鲁棒性,分别对测试集进行不同程度的遮挡和旋转处理,对以上方法使用没有进行遮挡和旋转处理的训练集对进行训练,再分别使用经过遮挡和旋转处理的测试集进行识别率测试。对于测试集的处理,本文采用遮挡程度从10%到50%的正方形黑块随机放置作为遮挡处理后的图像,采用进行顺逆时针10到40度处理后的图像作为旋转处理后的图像。图8为部分经过遮挡处理的测试集,该遮挡程度为40%,图9为部分经过旋转处理的测试集,该部分图像为原测试集经过绕图像中心顺时针旋转30度后的图。图10与图11分别为遮挡样本和旋转样本的识别率曲线。

图8 部分经过遮挡处理的测试样本

图9 部分经过旋转处理的测试样本
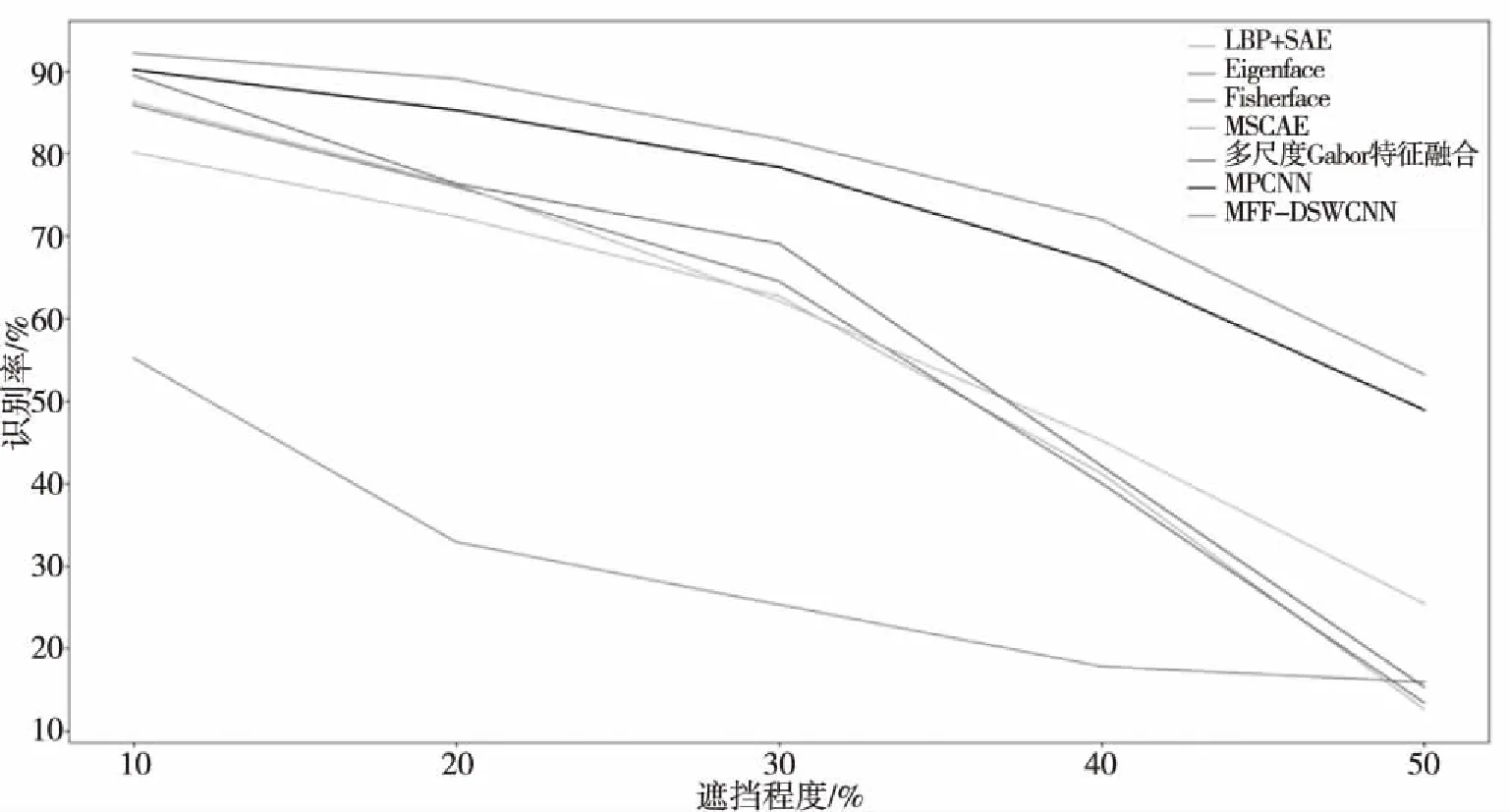
图10 遮挡样本的识别率曲线
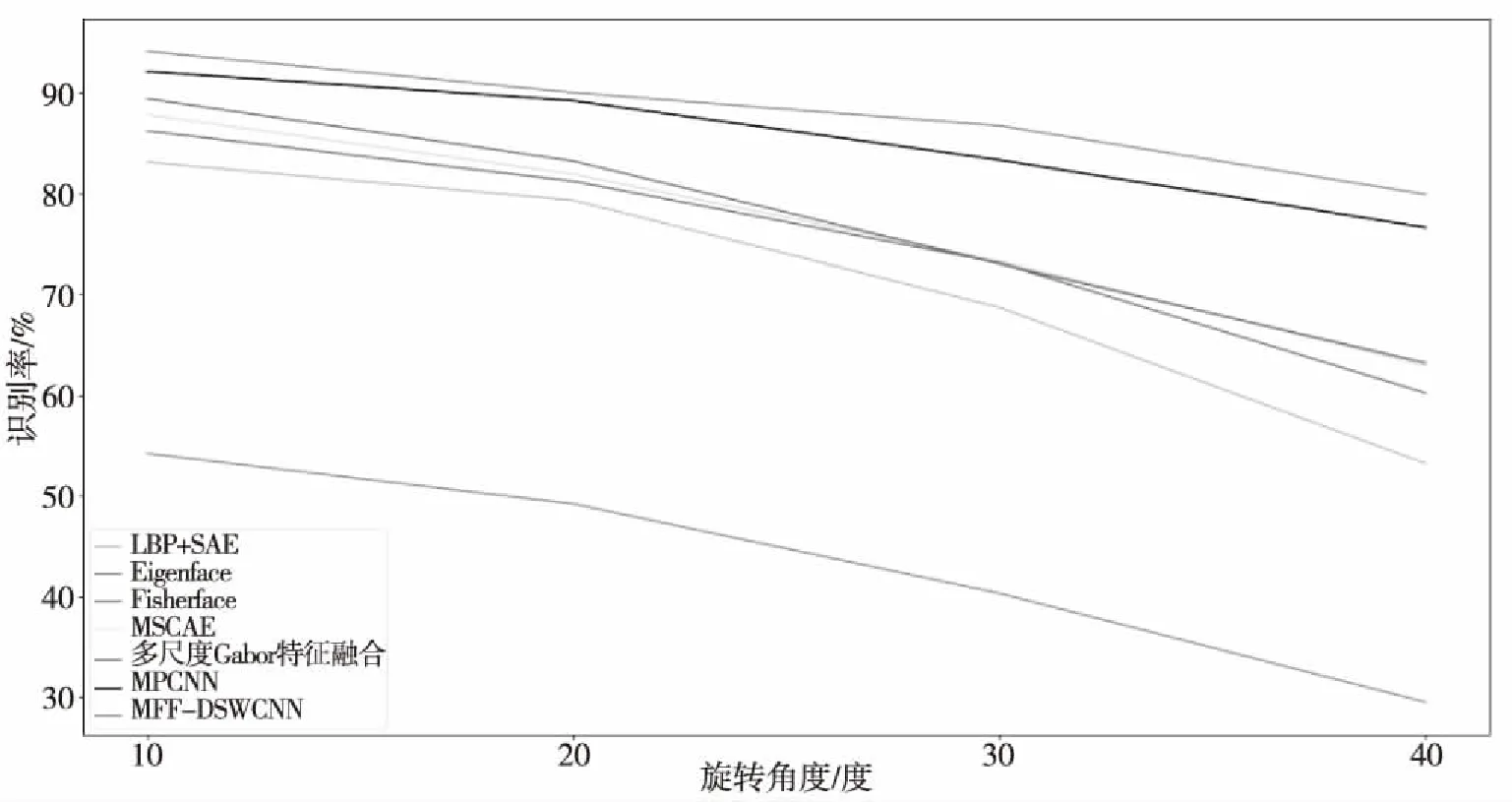
图11 旋转样本的识别曲线
由上图可以看出由于CNN对于图像遮挡和旋转具有一定程度的不变性,MPCNN和MFF-DSWCNN这两个基于CNN的模型对于遮挡和旋转的鲁棒性表现最好,而相比MPCNN而言,MFF-DSWCNN对于特征提取的更加充分,因此对于人脸图像遮挡和旋转的鲁棒性表现最好。
4 结论
针对传统门禁系统在人脸识别中对于特征提取不充分和收敛速度慢的问题,本文设计了一种基于多通道特征融合与动态样本权重的卷积神经网络,并将其应用于人脸识别中。该方法使用多个通道同时提取人脸图像抽象性和细节性的特征,解决CNN特征提取不充分的问题。经过以上多组实验的分析与对比,本文设计的方法不仅具有更高的识别率和更快的收敛速度,而且在图像遮挡和旋转方面具有较强的鲁棒性。
猜你喜欢
东北水利水电(2022年6期)2022-06-28
科学技术创新(2022年15期)2022-05-18
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
计算机工程(2020年3期)2020-03-19
电子制作(2019年11期)2019-07-04
中国听力语言康复科学杂志(2019年3期)2019-06-24
动漫星空(2018年9期)2018-10-26
中国交通信息化(2018年3期)2018-06-13
中国交通信息化(2016年2期)2016-06-06
