
基于GPU的软件雷达信号处理
2020-04-27 10:10田乾元徐朝阳
舰船电子对抗 2020年1期
田乾元,徐朝阳,赵 泉
(中国船舶重工集团公司第七二三研究所,江苏 扬州 225101)
0 引 言
雷达终端接收待处理的回波数据,通过信号处理系统这一重要环节,将庞大数量的回波数据进行脉冲压缩、杂波抑制、动目标显示(MTI)、动目标检测(MTD)、恒虚警率(CFAR)检测等处理,然后输出有用的数据或图像。最近几年,通信技术、存储技术的大力发展,使得回波数据量大大增加,数据传输速度加快,对数据处理的实时性提出了新的要求。单就MTD的仿真过程,数据吞吐量就达到了GB量级。为了满足信号处理的实时性要求,雷达信号处理的软件化十分重要,之前的主流方案一般都采用软件和硬件耦合紧密的多数字信号处理(DSP)+现场可编程门阵列(FPGA)板实现[1-3]。最近几年,基于通用计算机平台的计算机图形处理器(GPU) 运算能力的提升逐渐可为软件雷达的实现提供硬件支持[4-6]。GPU具有高并行度、多线程、高存储器带宽和强大的算术计算能力,而愈发成熟的统一计算设备架构(CUDA)将GPU传统的图形处理能力与应用广泛的C语言编程相结合,充分发掘了其强大的通用并行计算能力,非常适用于雷达信号处理过程。
1 软件雷达信号处理系统
如图1所示,基于GPU的软件雷达信号处理系统由三大模块组成:数据读取模块,是将接收机处理的基带数据读入,读取报文各标志、读取回波数据并重组,得到预处理后的回波数据;信号处理模块是信号处理系统的核心,经过预处理之后的回波数据先经过脉冲压缩(PC),得到PC数据,然后按照需要进行MTI处理或者MTD处理,在MTD结果的基础上进行CFAR处理;信号输出模块不只是CFAR结果的输出,还包括信号处理模块中间过程(类如PC结果),产生的数据可以按照实际需求进行输出并存储。
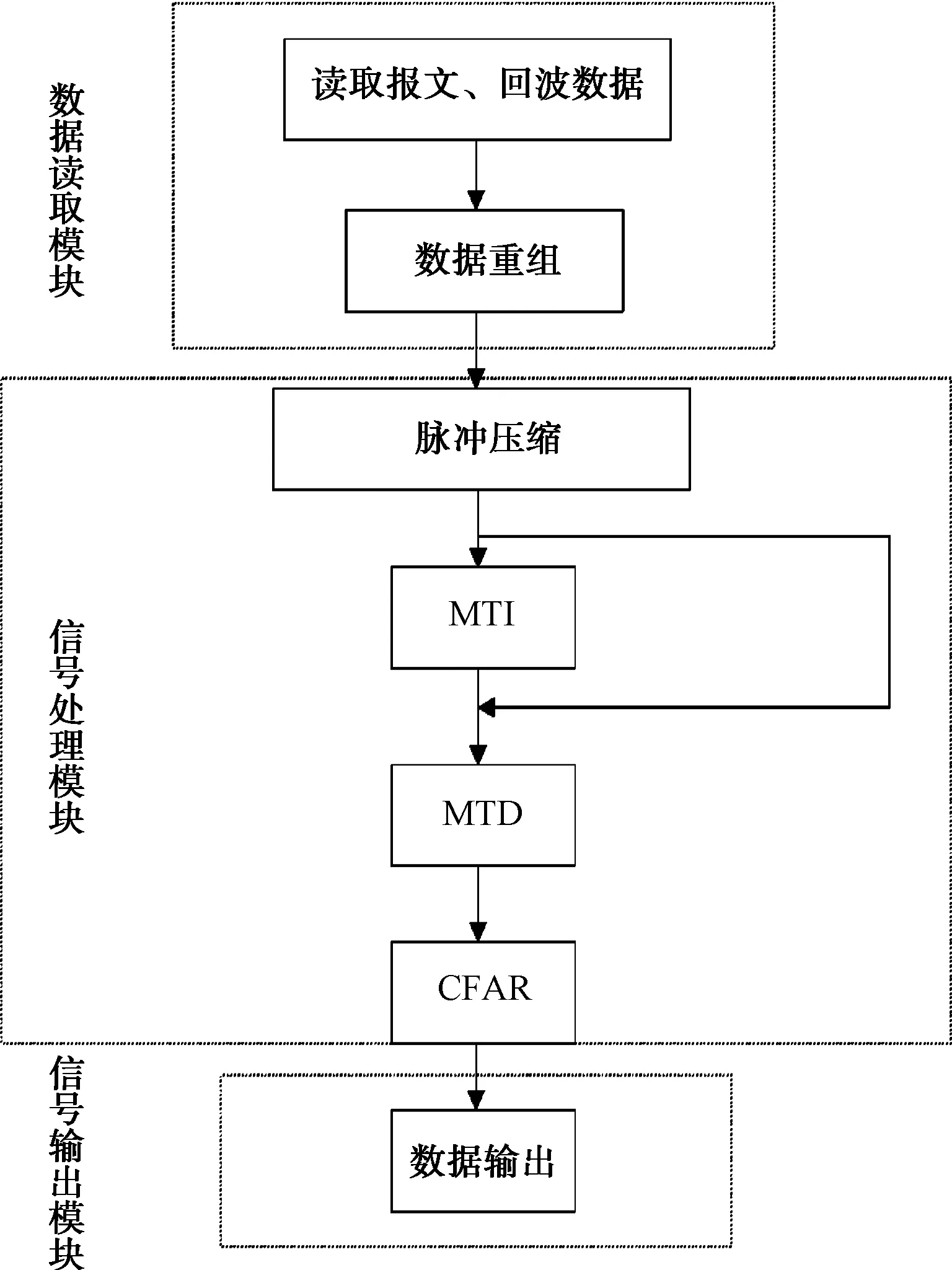
图1 基于GPU的软件雷达信号处理系统
2 基于 GPU 的雷达信号处理算法实现
对于信号处理模块,又包括脉冲压缩、MTI、MTD和CFAR几个大致处理环节。以下来说明基于GPU的各个环节的算法实现。
2.1 基于 CUDA 的GPU内存分配方法
CUDA通过核函数利用GPU资源进行计算,而核函数只能读取GPU内存中的数据,因此对于待处理数据,必须先将其读取到GPU内存中。GPU有3种常用的不同类型的内存储器:全局内存(global memory)、本地内存(local memory)、共享内存(shared menory)。shared memory位于片内,读取速度较快,另外2个为板载显存。
这里一般使用cudaMallocHost和cudaMalloc语句分别在CPU和GPU的global memory中分配内存,用cudaMemcpy语句进行CPU与GPU的数据传递,比如:
float *h_data;
cudaMallocHost((void**)&h_data,1024* sizeof(float));
float *d_data;
cudaMalloc((void**)&d_data,1024*sizeof(float));
cudaMemcpy(d_data,h_data,1024*sizeof(float),cudaMemcpyHostToDevice);
除此之外,还可用cudaMallocPitch语句以二维对齐方式分配二维内存。下文各个处理环节,包括建立窗函数等过程都要用到这里的内存分配方法。在CFAR处理中,还要用到shared memory加快处理速度。
2.2 基于GPU的脉冲压缩算法实现
脉冲压缩有时域和频域2类实现方式。时域上利用有限脉冲响应(FIR)滤波器实现时域脉冲压缩,处理方法比较直观。当距离单元数较小时,相对运算量不大,采用时域脉压处理可以满足实时性要求[7]。但是当距离单元数很大,时域卷积的运算量很大,这时宜采用频域脉冲压缩方法[8]。
本文采用频域脉压处理方法,其算法实现如图2所示。

图2 基于GPU的脉冲压缩算法
由于发射机的发射波数据和模式可以提前得到,所以提前计算出所有的脉压系数(可以在计算时进行加窗处理),组成脉压系数库(存放于dat文件中)。进行脉冲压缩时,读取预处理过的报文数据和模式标志,从脉压数据库中选择对应的系数数据,传送到GPU内存中,通过建立快速傅里叶变换(FFT) plan进行频域脉压系数计算。读取预处理过的回波数据,同样做FFT计算。然后将2个频域数据相乘,得到脉压的频域结果,之后进行快速傅里叶逆变换(IFFT)计算,得到脉冲压缩结果。一维FFT plan建立方法如下:
cufftHandle plan;
cufftPlan1d(&plan,FFT_number1,CUFFT_C2C,1);
除了一维FFT之外还可以创建二维按行或者按列FFT(2种方法计算耗时不同)的plan,调用plan时通过CUFFT_FORWARD或者CUFFT_INVERSE来确定进行FFT还是IFFT,需要注意的是,经过2次N点变换之后的数据比原数据扩大了N倍,如需输出脉压数据,需乘以1/N。
2.3 基于 GPU 的 MTI 算法实现
本文采用非递归型对消器实现MTI过程,其中,一次对消器的一般结构见图3,其差分方程为:
yn=xn-xn-1
(1)
二次对消器的一般结构见图4,其差分方程为:
yn=xn-2xn-1+xn-2
(2)

图3 一次对消器的一般结构
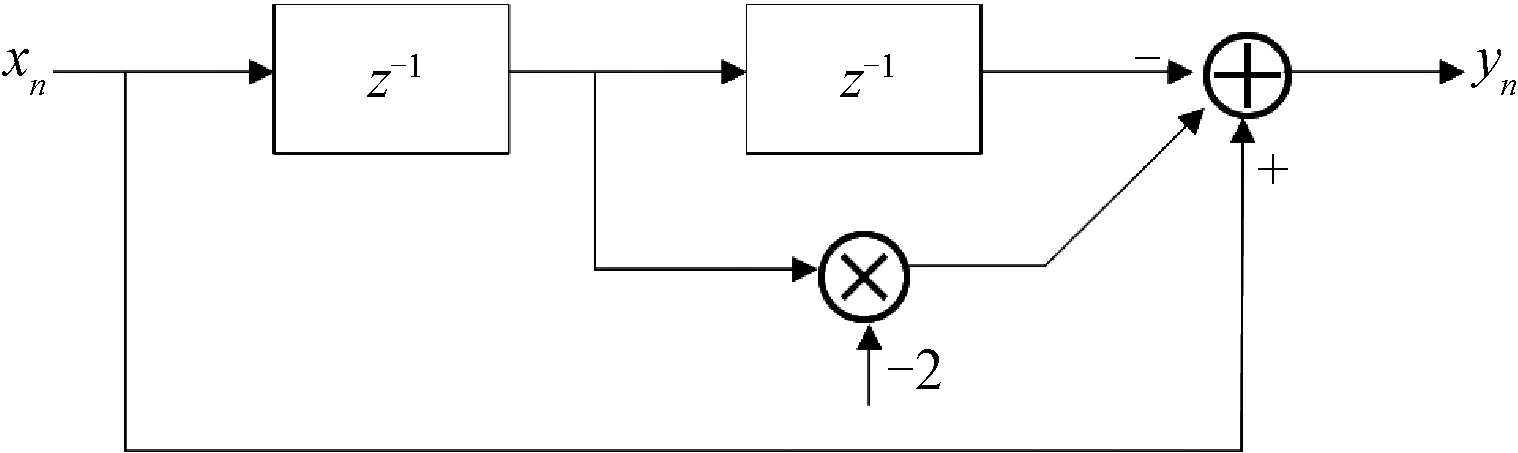
图4 二次对消器的一般结构
而基于CUDA的算法实现过程为:将脉压结果存储为二维形式(可以使用cudaMallocPitch语句),设计核函数构造一次、二次对消器等滤波器,调用核函数处理脉压数据得到MTI结果并输出。其算法过程如图5所示。

图5 基于 GPU 的 MTI 算法
2.4 基于 GPU 的 MTD 算法实现
为了提高MTD的方位精度,本文采用滑动MTD(SMTD)方法。在方位上每滑过一个脉冲,做一次M点(如16点)的MTD,新进入一个信号,丢掉一个老信号,又进行一次M点的老信号,因此每次MTD处理中均只有1个新信息,M-1个老信息。若一共有N个回波信息(脉冲压缩之后),每M个信息做一次MTD,那么SMTD之后就剩下了N-M+1个信息。对于每次MTD过程,M个脉压数据在相同距离门上(多普勒维度)进行M点的加窗FFT,得到M个通道的MTD结果。得到结果后可以对这M个通道的数据取模并取大,为CFAR提供源数据。
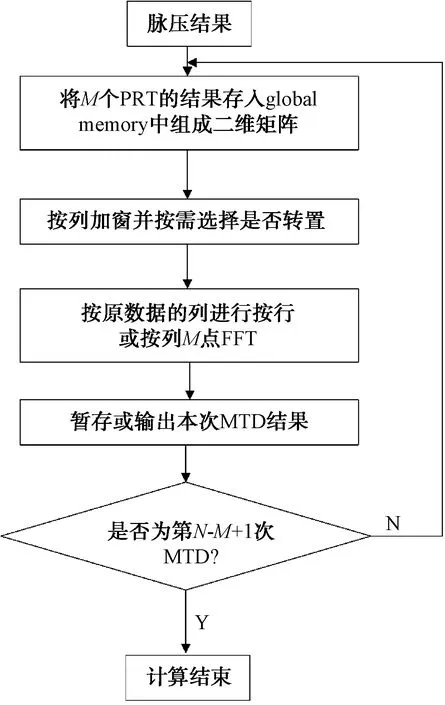
图6 基于GPU 的 SMTD 算法
图6为基于GPU的SMTD算法实现示意图,其中按行或按列进行FFT可以按照如下语句建立plan:
cufftHandle plan;
int rank=1;
int n[rank]={SampleNumber};
int inembed[1]={0};
int onembed[1]={0};
int istride=1;
int idist=SampleNumberF;
int ostride=1;
int odist=SampleNumber;
int batch=PulseNumber;
cufftPlan(&plan,rank,n,inembed,istride,idist,onembed,ostride,odist,CUFFT_C2C,batch);
理国要道,在于公平正直。从党的十八大提出“进一步深化司法体制改革”,到党的十九大要求“深化司法体制综合配套改革”,以习近平同志为核心的党中央从全面推进依法治国,实现国家治理体系和治理能力现代化的高度,擘画司法体制改革宏伟蓝图,加快建设公正高效权威的社会主义司法制度。
2.5 基于 GPU 的 CFAR 算法实现
CFAR检测器有单元平均CFAR(CA-CFAR)、单元平均取大CFAR(GO-CFAR)、单元平均取小CFAR(SO-CFAR)等类型,本文采用的是较为常见的CA-CFAR检测器。
CA-CFAR 的自适应门限值取决于杂波和目标距离门附近的噪声。待检单元(CUT)两边的N个单元组成参考窗(CFAR window cells),对其回波信号进行采样,将待检单元的输出与由参考单元输出总和所得到的自适应门限相比较并进行判决。一般将紧临 CUT 的单元设为保护单元(Guard Cells),在计算门限值时不将其列入计算之中来减小误差。CA-CFAR算法如图7所示。
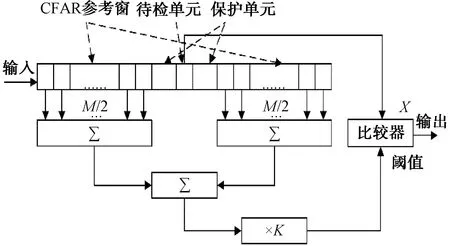
图7 CA-CFAR算法
基于GPU实现CFAR过程,在代码上是紧接着SMTD过程的。SMTD每得到1次MTD结果,取MTD结果的模值,将数据在距离门维度上取M个模的最大值,这样每M组数据结果就得到了1组数据,以此作为CFAR的源数据。
由于CFAR过程会频繁访问同一回波数据,2.1中提到的global memory访问速度较慢,计算效率较低,因此将待用数据写入到shared memory中,减小不必要的时间开销,从而提高计算效率。在计算阈值时,由于窗长取值一般为 2 的幂次,故采用归约求和算法,将求和过程变为多层多线程并行求和[9]。CFAR过程可以从GPU的内存特点和计算特性进行优化,此处不再展开。本文的基于GPU的CFAR算法过程如图8所示。
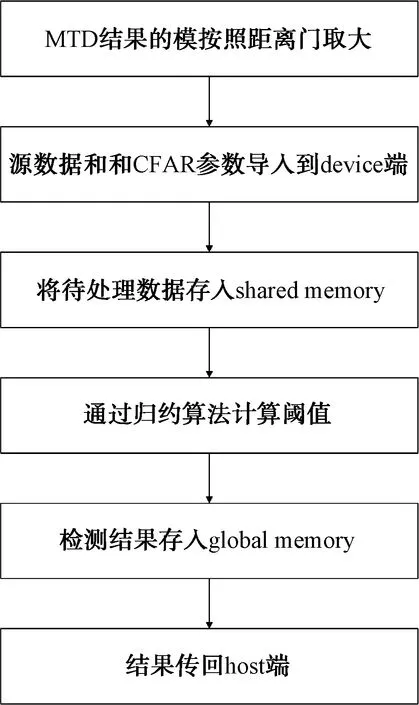
图8 基于GPU的CFAR算法
3 基于GPU与基于CPU的雷达信号处理仿真实验及结果对比分析
某警戒雷达基于传统CPU平台,其信号处理过程采用C++编程,通过调用Intel Math Kernel Library加快计算效率。本文对其与本文采用的基于GPU平台的雷达信号处理进行性能比较。
在 GPU 与 CPU 上分别实现雷达信号处理的脉冲压缩、MTI、MTD和CFAR处理过程,源数据相同,计算两者处理结果的误差,同时对比两者的计算时间,以分析 GPU 算法实现的准确度和计算效率。CPU端使用Intel(R) Math Kernel Library(Version 2017.0.31)进行计算。开发计算机采用的显卡 GPU 为 NVIDIA GeForce GTX1060,CPU 为Intel Core(TM)i5-8300H 2.30 GHz,操作系统为Deepin 15.11。
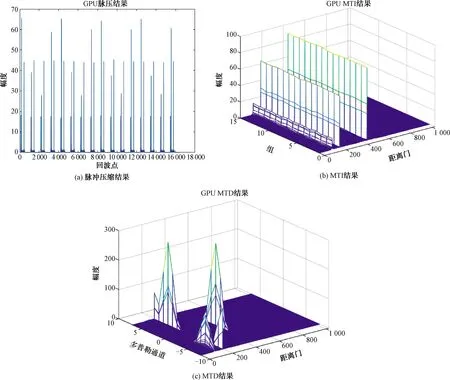
图9 基于GPU的雷达信号处理仿真实验结果
图9为同一仿真源数据GPU平台的处理结果。
分析图9可以得出结论,基于GPU的软件雷达信号处理系统在仿真实验中完成了脉冲压缩、MTI、MTD任务。实验数据也表明CFAR检测结果正确。之后将基于GPU的检测结果与基于CPU的雷达信号处理计算结果进行比较,以CPU计算结果为基准(认为是绝对真实值),绘制GPU平台下脉冲压缩、MTI、MTD的绝对误差图。
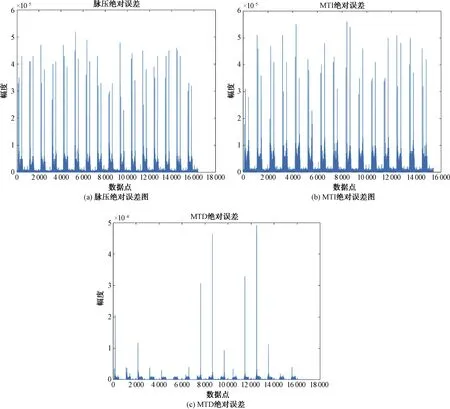
图10 基于GPU与CPU的雷达信号处理仿真实验结果误差
由图10分析可知:基于GPU的处理结果与CPU相比误差极小,脉压绝对误差小于5.5×10-5,MTI绝对误差小于6×10-5,MTD绝对误差小于5×10-4,而对于这3个过程来说,目标或者说是有用数据一般大于1,因此相对误差最大不超过上述对应数值。因此,基于GPU的软件雷达信号处理系统计算结果具有较高的准确度。
分别进行100次仿真实验,记录GPU和CPU处理实现各个功能的平均时间,得到结果如表1所示。
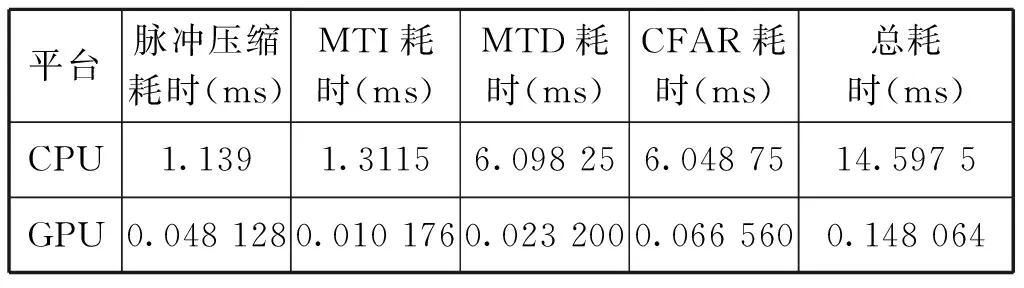
表1 基于GPU与CPU的信号处理仿真实验计算耗时
表1为2种平台下实现信号处理的计算耗时,显然基于GPU的方法计算耗时要少得多,将CPU耗时除以GPU耗时,绘制GPU算法相较于CPU算法的效率提升折线图,如图11所示。
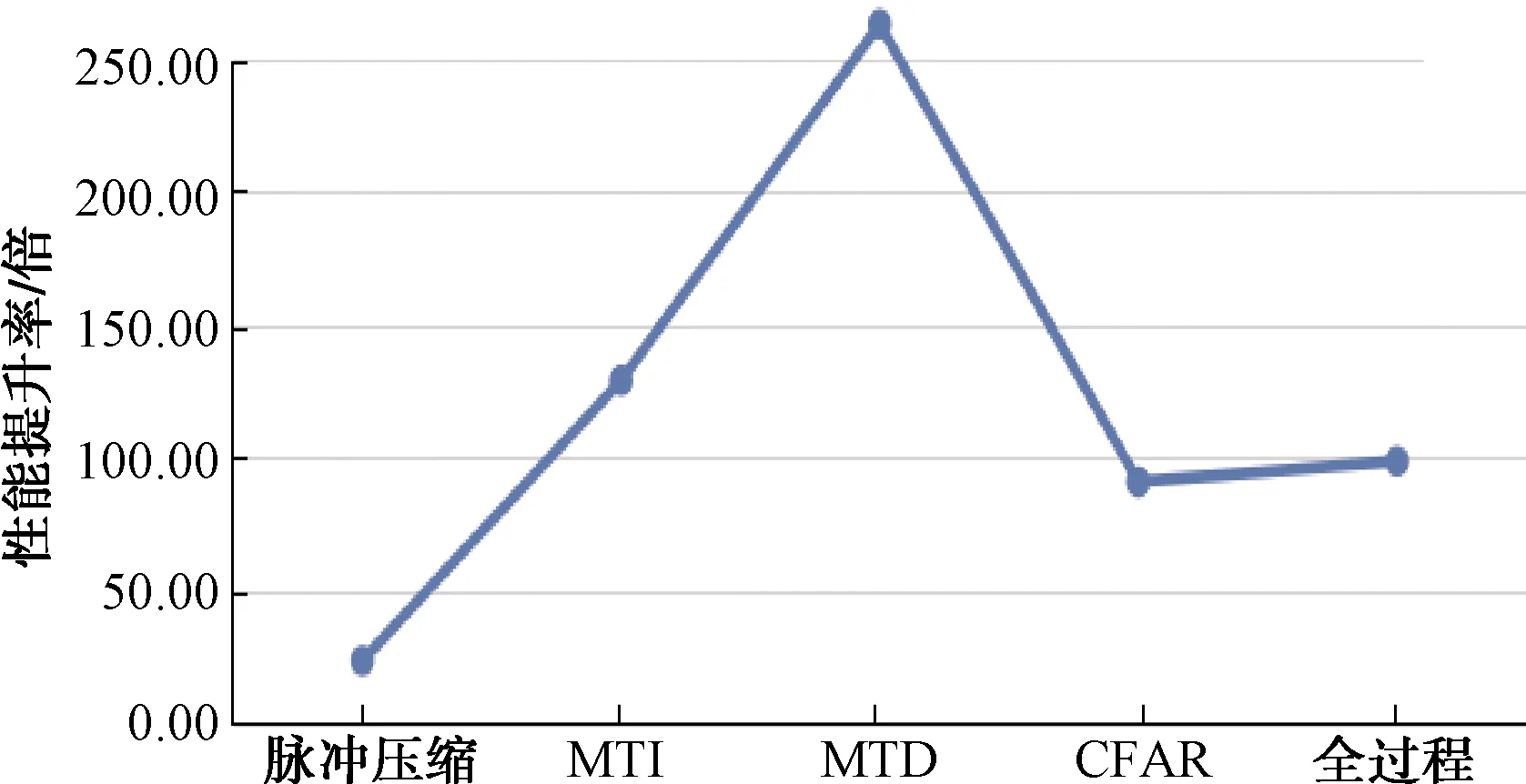
图11 基于GPU的算法对比CPU算法的计算性能提升率
图11表明基于GPU的软件雷达信号处理系统相较传统CPU平台的处理方式在计算性能上有巨大的提升,尤其是MTD模块更是达到了262倍的效率提升,总体的平均提升率也在100倍左右。而且因为本文做的是仿真实验,数据量受限,实际应用过程中的回波数量远远大于本次仿真的数据量,对于GPU的计算能力来说,仍有较大的提升空间。
4 结束语
本文阐述了基于GPU的软件雷达信号处理系统的结构以及各个信号处理模块的实现原理,通过仿真实验,对比了GPU平台(CUDA架构)和CPU平台(调用MKL库)下雷达信号处理的结果正确性、结果准确度和计算性能。结果表明:GPU平台下的雷达信号处理结果与CPU下的结果在数值上几乎完全相同;而在计算耗时方面,GPU平台下算法的计算效率是CPU平台下的100倍左右,在某些信号处理环节上计算效率更高。由于仿真实验的条件受限,数据量较小,并没有发挥出GPU的全部性能。实际应用中待处理数据(如回波采样点数、PRT数量)会更加庞大,利用GPU实现雷达信号处理将获得更大的吞吐量。因此,GPU平台下的雷达信号处理与传统雷达采用的CPU相比,计算结果准确,计算效率更高,更能满足现代雷达信号处理的大吞吐量和高实时性要求。
猜你喜欢
振动与冲击(2022年19期)2022-10-17
包装工程(2022年9期)2022-05-13
保健与生活(2021年2期)2021-02-04
老年博览·上半月(2019年5期)2019-09-10
华声文萃(2019年4期)2019-09-10
家庭科学·新健康(2018年5期)2018-06-08
晚晴(2016年11期)2016-12-20
哈尔滨理工大学学报(2014年3期)2015-01-04
