
高考语文阅读主观题评分方法对题目参数分析的影响
2020-04-25 09:52:44温红博
考试研究 2020年1期
温红博 李 峰
一、引言
主观题和客观题是教育考试中对题型的一种常见划分方式(Miller,2009;张敏强,1998)。 主观题要求学生自己写出认为正确的答案。 虽然研究表明主观题并未比客观题提供更多的学生信息, 也未涉及明显不同的考查维度(Bennett,1991),但是主观题更为广泛地被教学一线接受。
研究者也将这种题目称为建构性应答题(constructed-response items)。 这类题目要求作出具有一定发散性和多元化的回答, 能够体现学生个人思考问题的方式并得出的独特结果, 这种作答的开放性便于测量学生对知识的分析整合、应用评价等能力。因而,这类题目受到高考试题开发者的青睐,成为高考的主要题型。 同时主观题由于开放的作答需要评分人员基于专业经验主观地评分, 这为高考质量改进带来了一系列的理论和现实挑战。
主观题首先面临的问题是评分的分数意义。 主观题一般都是多级评分, 通常设置一个总分, 如6分,并根据学生的作答由评分者评分,但分数的意义可能存在多种不同的解释。 第一种分数是学生能力连续体的一个点,就像学生的身高数值一样;第二种分数反映了学生答对知识点或掌握的技能个数,如“中国古代的四大发明是什么? ”,评分为4 分;第三种分数是学生表现出来的能力等级水平。
其次是面临的问题是评分方法。 主观题通常有三种评分方法:主要特质评分法、分析评分法和整体评分法(Sax,G.,Newton,J. W.,2011)。 主要特质评分法以答案达到的特质程度评分, 整体评分法根据作答的整体水平评分。 这两种方法由于对特质和整体的描述比较空泛难以客观操作, 评分者的主观判断对评分结果的影响较大,评分者信度较低。实践中主要采用分析评分法,即所谓的“采点”评分。考试实施中一般会列出参考答案, 评分者主要根据参考答案中给出的“得分点”进行“采点”评分,学生分数随着作答得分点的增加而升高。
目前高考主观题评分同样存在这两个问题:一个是分数的意义, 将主观题得分视为等同于物理测量的等距或等比数据,主观确定题目的分值。第二是采用分析评分法, 以正确作答的数目为主要评分手段,答对一点,计1 分(或者加权后计2、3 分)。 这种评分考虑了答案的“量”,但忽视了答案的“质”,学生答对的量的变化是否意味着本质上水平的变化? 这缺乏足够的理论和实证支持。 主观题的分数属于顺序数据,本质在于反映学生表现的等级水平,但是这种等级水平不应该是简单的量上的区别, 而应该是在理论指导下对于学生表现的能力等级水平的区分。 因此,研究者提出高考应该“由采点赋分向按能力层级和采意赋分过渡”(戴家干,2006)。
对此,国务院《关于深化考试招生制度改革的实施意见》明确提出,高考需要“改进评分方式”。 如何改进主观题评分方式成为高考改革的一个核心技术问题。既然主观题的评分应该反映学生表现出的能力等级水平, 那么问题的关键在于能否构建一个科学、合理评价学生能力等级水平的理论。
研究者已经采用可观察到的学习结果的结构(structure of the observed learning outcome,简称SOLO;Biggs,1982) 针对学生思维水平的质量进行评价。 这种分类评价法将学生的作答反应从低到高分为前结构、单点结构、多点结构、关联结构和抽象拓展结构(Biggs & Collis,2010;蔡永红,2006)。 前三个层次考查学生掌握知识点的数量, 反映了学生在“量”上的差异;后两个层次则是对“质”的要求,侧重考查学生的高级思维能力。SOLO 分类评价法已经在许多学科的主观题命制和评分中展开了探索。 研究发现, 采用SOLO 分类法编制的主观题卷面成绩信度较高, 能够较好地反映学生的真实学习成绩和思维发展水平(何琼,2006)。
SOLO 分类评价法为主观题评分方式改进提供了理论和实证的支持。 但是SOLO 分类评价法能否代替传统的“采点”评分,并作为一种新的评分标准来改进高考主观题的评分质量, 还有待进一步的实证研究。语文是高考中最重要的科目之一,高考语文有大量的阅读主观题, 可以作为高考主观题评分改进的一个重要突破口来展开研究。实际上,已经有研究者探讨了SOLO 分类评价法在语言测试中的应用(任春艳,2014), 为高考语文阅读主观题采用SOLO分类评价法进行了有益的探索。
有研究者讨论了阅读能力评价中SOLO 分类评价法的应用(李英杰,2006),但是阅读能力不同于一般学科知识内容的思维加工, 是一种独特的认知能力。 认知心理学提出了关于阅读的建构整合模型(constructed-integration model, 简称为CI;Kintsch,1988)。 这个理论模型认为,阅读理解存在三个水平的记忆表征。第一是表层水平(surface level),主要是阅读者对文本字词水平的理解; 第二是文本水平(text level),主要是指阅读者在字词理解的基础上形成一系列命题;第三是情境模型水平(situation model level), 即阅读者对文本命题和背景知识进行整合,充分理解。 PISA 的阅读测试中已经通过判定学生所处的文本表征水平作为评分依据 (Rai M K et.al,2015)。
为了有效地改进高考语文主观题评分, 本研究从理论建构入手, 提出了两种新的评分方法:SOLO分类评分法和CI 模型评分法。 本研究将选取真实的学生高考试题、作答记录和实际分数,采用三种不同的评分方法,通过比较分析三种评分方法的测量学指标,探讨不同评分方法的有效性和优劣。
本研究采用项目反应理论(Item Response Theory,简称IRT)对三种评分方法进行测量学分析。 IRT是一种新兴的心理和教育测量理论, 得到国内外研究者的广泛认可(罗照盛,2012)。 同时,本研究使用估计稳定的两参数模型(two-parameter normal ogive model,简称为2PL;Lord,1952)。 研究针对具有多级评分的主观题, 选择了拓展的分部评分模型(generalized partial credit model, 简 称 为GPCM;Muraki,1992),模型公式如下:

Pjk(θ)表示能力值为θ 的学生在第j 题得到k 分的概率,j 为题目编号,k 为学生得分,aj、bj分别表示第j 题的区分度和难度,dv表示学生得到k 分时相对于得到其他分数的相对难度。
相对于2PL 模型,GPCM 模型除了能计算出每个题目的区分度a 和平均难度b 以外, 还能计算出每个题目得到每一级分数(类别)时,所对应的题目难度bj(bj=b-dv), 简单来说就是相邻得分的阈值。GPCM 模型强调每个题目相邻得分类别所对应的难度阈值。 测量中一般认为题目分值越高,难度越大,学生所需的能力值越高。因此随着分值的增高,难度阈值单调递增(即b1<b2<b3<……<bj),步长值呈现依次增大的现象。
研究者一般建议项目反应理论的测验质量分析需要考虑区分度、步长值(难度)、测验信息量等三个方面(戴海崎,2006)。本研究将根据学生的同一作答反应,分别计算和比较这些指标,从而判断三种不同评分方法的优劣。 简而言之,三种评分方法中,每个题目的区分度越合理、步长值(难度)越恰当、测验信息量越大,评分方法越合理。
二、研究方法
1. 研究对象
本研究采用完全随机的方式, 从高考语文成绩数据库中抽取了1019 名学生, 并提取了每道题目(共27 题)的实际得分,以及阅读主观题的实际作答图片。 研究所选择的阅读部分包括一篇散文及基于此文本的三道主观题。 数据提取时删除了学生所有的个人信息。
2. 三种评分标准制定
第一种评分标准采用了真实的高考语文主观题的参考答案和评分方法。SOLO 评分标准由2 名语文老师、2 名语文课程专家和1 名SOLO 研究人员组成专家小组, 根据SOLO 分类评价理论和学生作答样例制定评分标准。每道题的评分准则为五级,评分依次为0-4 分,即前结构0 分,抽象拓展结构4 分。 CI评分标准由2 名语文老师、2 名语文课程专家和1名阅读认知研究人员组成专家小组, 根据情景整合模型(CI)和学生作答样例制定评分标准。 每道题的评分准则为三级,评分依次为0-2 分,即基于字词的理解记为0 分,基于文本水平的理解记为1 分,基于情境模型的理解记为2 分。
3. 研究过程
研究采用了与高考阅卷流程完全相同的流程,三种评分方法都采用了“2+1”的评分流程。每道主观题均由两个评分员根据评分标准独立评分, 两者的分差为0 时,评分结束,记录为学生最后得分。 如果两者分差不为0,则由第三个评分员独立评分,三位评分员中有两个一致的评分结果,则评分结束,记录相一致的分数为学生的最后得分; 如果三人的结果都不一致,则上交专家小组仲裁。
具体操作中, 由于已经有了学生的真实高考数据, 基于高考评分标准的评分方法实际上是采用了“1+1”评分流程,即一评后,对比真实成绩,如果分差为0,则结束评分;如果分差不是0,则二评。
评分员由一线语文教师和语文教学方向的研究生组成,基本与高考选拨标准一致。三种评分方法的评分小组由9-11 人组成。 评分员独立评分,并不事先通知其评阅的属于第几评,全部随机发放,电脑自动分发作答、记录、对比评分结果。 原始评分法的评分者一致性在0.65-0.69 之间,SOLO 评分法的在0.71-0.74 之间,CI 评分法的在0.78-0.81 之间,三种方法均有较高的评分者一致性。
4. 数据分析
本研究使用R 软件进行相关的数据分析。
三、研究结果
1. 三种评分方法的基本结果
三道主观题的原始总分分别为6 分、6 分和4分;采用SOLO 评分方法后,总分统一为4 分;采用CI 评分方法后,总分统一为2 分。三种评分方法的基本情况如表1 所示。
每种评分方法中, 三道主观题都表现出了题目之间中低程度的相关, 原始评分法中三道题目的相关在0.35-0.38 之间,SOLO 评分法三道题目的相关在0.38-0.45 之间,CI 评分方法三道题的相关在0.39-0.54 之间。 每道题自身采用不同的评分方法之间的相关要显著高于题目之间的相关。 第1 题三种评分方法的相关在0.58-0.84 之间,第2 题三种评分方法的相关在0.56-0.72 之间,第3 题三种评分方法的相关在0.55-0.89 之间。SOLO 评分与CI 评分之间相关最高,达到了高相关的程度(0.72-0.89),原始评分法与SOLO 评分法、CI 评分法的相关略低,但也达到了中等相关的程度(0.55-0.63),表明三种评分方法存在某种内在的关联。

表1 三道主观题三种评分方法相关及基本情况
2. 模型拟合程度
三种评分方法的模型拟合指数如表2 所示。结果显示,三种评分标准下的全卷拟合均较好,可以对数据做进一步的分析。 三个模型的AIC 和BIC指标随着评分方法的改变逐步降低, 表明模型拟合越来越好, 原始评分模型完全可以接受,SOLO评分模型拟合进一步提升,CI 评分的模型拟合程度最高。 三种评分方式下,IRT 分析中测验的整体EAP 信度依次提高, 测验具有较高的信度(Wu,2005)。
本研究的主要目的是探究三种不同的评分方法对阅读主观题题目参数的影响。 IRT 可以分析每道题目的拟合程度, 作为题目质量评估的一个基本指标。三道题目的三种评分方法拟合指标如表3 所示。数据显示,拟合值都在1 附近,P 值都不显著,三道题目采用不同的评分方法都能够较好地拟合, 说明三种评分方法都具有一定的合理性。

表2 三种评分方法下的模型拟合指数
3. 题目参数分析结果
采用IRT 两参数模型, 分析了三种评分方法对题目参数估计的影响。 表4 是题目区分度参数的分析结果。结果表明,三个题目的区分度随着评分方法的变化有所变化。原始评分方法的题目区分度最低,第一题仅0.313。 SOLO 评分方法比原始评分的区分度有所增加,但是第一题仍然仅有0.363。 CI 评分方法的题目区分度最高,第一题区分度接近合格线。新的评分方法有效地改进了题目的区分度参数属性,提高了评分的有效性。
题目难度参数分析结果如表5 所示, 第三列是三种评分方法下三道题目的整体难度。 可以看出,SOLO 评分和CI 评分都导致了题目难度参数降低,其中CI 评分的难度最低。 表5 中还呈现了三种评分方法下三道主观每一个等级得分的难度阈限。 一般而言,随着分值的增加,学生得分的难度应该依次增加。 数据表明只有CI 评分方法符合这种假设。 原始评分中三道题目都出现了得到1 分的难度超过2 分的现象;SOLO 评分中两道题目出现了得到3 分比得到2 分更容易的现象。
研究计算了同一题目中所有得分所对应的难度值到均值的距离,结果如表6 所示。 结果表明,原始评分下三道题目的步长都有部分异常现象, 主要表现在高分段值突然增加。 SOLO 评分下,第一道题目步长正常,第二道和第三道题目的步长异常,主要表现与原始评分结果相同;CI 计分下,三道题目的步长都正常,基于CI 的主观题评估更符合高分对应高能力的理论假设和实际情况。

表3 三种评分方法下的主观题题目拟合指标

表4 三道主观题三种评分方法的题目区分度
4. 测验信息量
在ITR 理论中, 信息量是衡量测量误差的一个重要指标。一个测验所包含的信息量越大,测验的误差相对来说就越小。 三种不同评分方式下的测验信息量如图1 所示。其中,传统评分法在被试能力值为25 时,信息量最大,为1.8;SOLO 评分法在被试能力值为41 时,信息量最大,为3.1;CI 评分法在被试能力值为42 时,信息量最大,为5.6。总的来说,三种评分方法都在能力值为24-42 之间的信息量最高,其中CI 评分法的测验信息量最大。
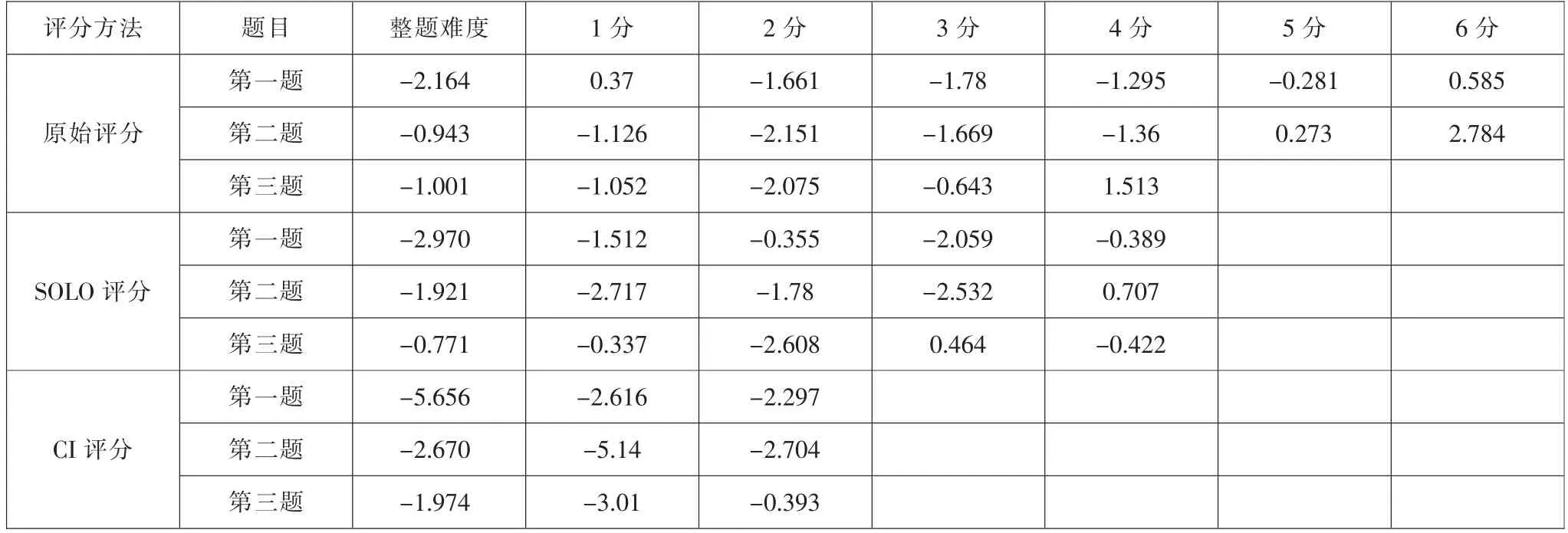
表5 三种评分方式下三道主观题的难度参数估计

表6 三种评分方法三道题目得分之间步长

图1 三种评分方法下三道主观题的测验信息量
四、讨论
高考是我国的基本教育制度, 受到全社会的高度关注,为此《国家中长期教育改革和发展规划纲要(2010-2020 年)》明确提出“完善高等学校考试招生制度……保证国家考试的科学性、导向性和规范性”(国务院,2010)。高考主观题评分目前采用的是基于专家经验判断的以参考答案为基础的评分方法。 一般而言,学生答对参考答案的点越多,得分就越高,表明学生能力就越高。鉴于传统评分的不足,本研究基于学生思维发展的SOLO 学习分类理论和阅读认知过程的CI 理论,设计了两种新的评分方法,试图从实证角度比较三种评分方法对阅读主观题题目质量的影响。
虽然高考主观题的原始评分方法受到了一定的质疑和批评,但是这种基于专家判断的评分方法是我国教育工作者多年的经验总结,表现出了较为良好的测量学指标。 研究发现,三种评分方法之间具有较高的相关(相关在0.55-0.89 之间)。 采用原始评分法,整体测验具有较好的拟合指标,EAP 信度达到了0.827,基本达到了对这种高利害学业测试的要求。主观题原始评分的IRT 题目拟合良好,题目的区分度有两道题达到了区分度的基本要求, 每道题的每个得分的阈限大多数依次增加, 题目不同分值之间的步长大多数正常。整体而言,高考语文阅读主观题采用原始评分法表现出了较好的测量学指标,说明高考语文主观题原始评分具有一定的科学性和规范性。
另一方面, 高考主观题原始评分法依靠专家小组经验, 这种方法缺乏具体而明确的理论建构和指导,导致科学性不足,导向性不清晰,评分标准主观性较强, 评分员评分主观而僵化, 评分的规范性不强。为了克服原始评分方法缺乏理论指导的不足,本研究总结了两种可用于高考语文阅读主观题评分的理论,并以此设计了新的评分方法。一是反映学生认知发展水平的可观察学习结果的结构, 即SOLO 评分法; 一是反映学生阅读形成的认知表征水平的整合情景模型,即CI 评分法。 这两种评分方法根据相关理论能够清晰、明确地阐释阅读认知发展的层级。这两种评分方法都在一定程度上超越了内容, 重在评估学生的认知思维水平, 符合培养学生独立思考和解决复杂问题能力的核心素养要求。
研究结果表明, 两种新的评分法具有更为优异的测量学指标。 SOLO 评分法和CI 评分法主观题得分之间的相关显著提高。原始评分法中相关在0.35-0.38 之间,SOLO 评分法相关在0.38-0.45 之间,CI评分方法相关在0.39-0.54 之间。题目之间的相关增加表明,采用了新的评分方法后,对学生表现的评价一致性在增加。同样可以看到,CI 评分法提升的程度明显高于SOLO 评分法。 整个测验的模型拟合中,SOLO 评分法和CI 评分法都能够表现出与原始评分相似的拟合指标, 但SOLO 评分法和CI 评分法模型拟合优于原始评分法。 三个评分方法模型的AIC、BIC 依次降低, 原始评分法最大,CI 评分法最小,EAP 信度也具有相同的表现, 原始评分法最小0.827,CI 评分法最大0.844。 三个模型都可以接受,都具有良好的结构效度和测试信度, 同时模型拟合误差最小、测试结果最稳定的是CI 评分法。 三种评分方法在题目拟合上都表现良好, 所有方法的所有计分点都具有完全可以接受的模型拟合分析结果,在题目拟合分析中,三种方法并没有明显的差异。
题目区分度的分析具有与测验整体拟合结果相同的特点。 新的评分方法都显著提升了题目的区分度表现, 第二题的区分度从0.574 提高了1.469,CI评分法比SOLO 评分法提升的程度更高。 但是有一个题目使用了CI 评分法, 题目的区分度仍然小于0.5,这可能与题目本身有更大的关系。
两种新的评分方法引起最直接的变化是题目满分的不同。 三道主观题原始评分法满分为6 分、6 分和4 分;采用SOLO 评分方法后,满分统一为4 分,采用CI 评分方法后,满分统一为2 分。 在经典测量理论中, 主观题这种多级计分的分值之间差异被题目整体表现所掩盖。 本研究采用项目反应理论分析主观题分值之间的变化和差异, 来验证主观题评分标准和等级的科学性与合理性。 所有评分方法的一个基本假设是得到更高分数的学生应该具有更高的能力, 反之也是成立的。 虽然采用了不同的评分法后,题目的整体难度参数都有所下降,但这并不是研究关注的问题。研究关注的是不同评分方法下,每个题目的每个分值的难度阈限,以及题目之间的步长。研究发现,只有在CI 评分法下,三个主观题分值的阈限值和步长的变化符合这个假设,低分的阈限低,高分的阈限高,从低分到高分阈限之间的值在减小。原始评分和SOLO 评分中分值的变化都出现了违背这个假设的现象, 例如原始评分法第二题1 分的阈限值为-1.126,2 分的阈限值降低到-2.151, 这就意味着学生得到1 分的难度大于得到2 分的难度,这就违背了之前的假设, 实际上该题在原始评分中得到3 分和4 分的难度都比1 分的难度小。SOLO 评分法较好地改善了这个现象:同样是第二题,采用SOLO 评分,1 分的阈限值是-2.717,2 分的值是-1.78,得到1 分的难度小,2 分的难度大, 但是这时得到3分的难度又降到-2.532,得到3 分变得容易了,依然违背了前述的假设。 三个主观题的分值步长上具有与此基本相同的表现。 题目难度参数的分析和比较表明,SOLO 评分法比原始评分法具有更科学、 合理的等级划分,但是仍然存在缺陷,本研究的结果发现CI 评分法区分的学生表现等级得到了支持, 各个等级水平之间是清晰而明确的。
项目反应理论的最大特点之一是可以计算每个题目的信息量和测验的信息量。 本研究直接比较了三个题目采用不同评分后测验信息量的变化。 信息量越大表明测验误差越小,测验具有更高的信效度。这个结果与之前都是一致的, 原始评分法信息量总和最小,SOLO 评分法显著地提高了测验的信息量,但最大信息量是CI 评分法带来的,三个题目的信息量达到了5.6。
SOLO 评分是一种基于认知发展水平理论的评分方法, 研究者广泛地将该理论应用到各个学科的主观题评分中,取得了大量的研究成果(冯翠典、高凌飚,2009)。 基于SOLO 理论的评分方法可靠、有效地提升了高考语文主观题的评分质量。 但是SOLO适用于一般的认知过程, 特别是涉及到具体学习内容的课程。语文学习更多地涉及读写认知加工过程,这种认知加工过程有其自身的特点。 建构整合模型(CI) 是阅读认知研究普遍认可的理论模型(Kintsch& Walter,2018;Ferstl & Evelyn,2019),CI 评分法相比SOLO 评分法可能更适合阅读主观题的评分。 研究中发现CI 评分法优于SOLO 评分法,还有一个可能的原因是分数的范围和等级不同,CI 评分法将学生分为三类,SOLO 评分法将学生分为五类, 分类等级较少时,评分者更容易掌握评分标准,区分学生的阅读能力层级更加准确。
本研究的结果支持了基于理论的评分方法优于基于经验的评分方法,SOLO 评分和CI 评分都优于原始评分方法,但是本研究还存在一些不足。 首先,研究的理论建构上, 本研究提出的两种评分理论还需要进一步验证, 为阅读主观题评分建立一个更为明确的理论框架。其次,研究仅涉及了现代文阅读模块的主观题。高考语文中还包括古诗文阅读鉴赏、语言运用和写作等不同类型的主观题。 这些主观题的评分方式还有待进一步研究。最后,本研究的评分方法并未涉及分数加权的问题, 由于高考需要对不同的题目进行加权合成一个固定分值。 本研究的评分方法不同,题目满分也不同,在实际应用中该如何加权,也需要进一步探讨。
五、结论
本研究结论如下:
首先, 三种评分方法都具有较为良好的测量学特征,能够基本可靠、有效地评价学生的学业表现。
其次, 基于理论的主观题评分方法优于基于经验的评分方法。
第三,CI 评分法优于SOLO 评分法。 CI 评分法可能是高考语文阅读主观题评分一个更为合理的基础理论和技术路线。
猜你喜欢
考试与招生(2022年10期)2022-11-17 08:59:04
井冈教育(2022年2期)2022-10-14 03:11:28
中学生数理化(高中版.高考数学)(2022年6期)2022-07-02 03:36:26
甘肃教育(2021年10期)2021-11-02 06:14:28
中国校外教育(2019年12期)2019-04-15 11:14:34
西南交通大学学报(2018年5期)2018-11-08 10:59:16
江淮论坛(2018年4期)2018-08-24 01:22:30
福建中学数学(2016年5期)2016-11-29 02:45:52
新闻传播(2016年11期)2016-07-10 12:04:01
心理学探新(2015年3期)2015-12-27 06:25:14
